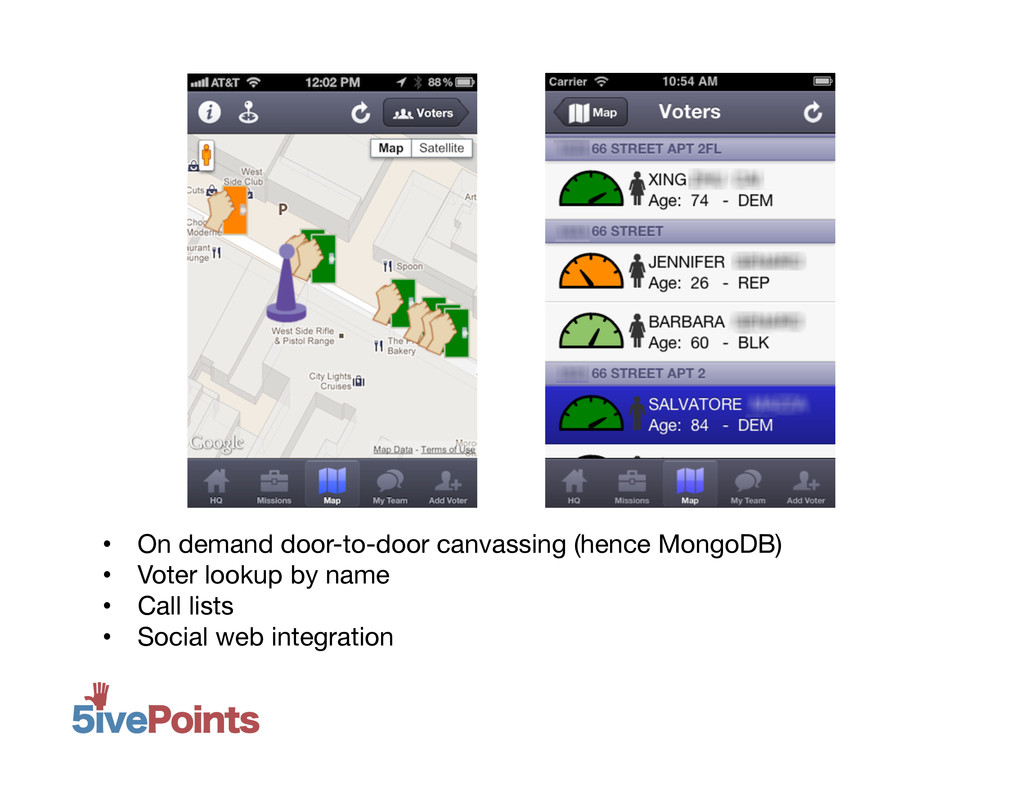
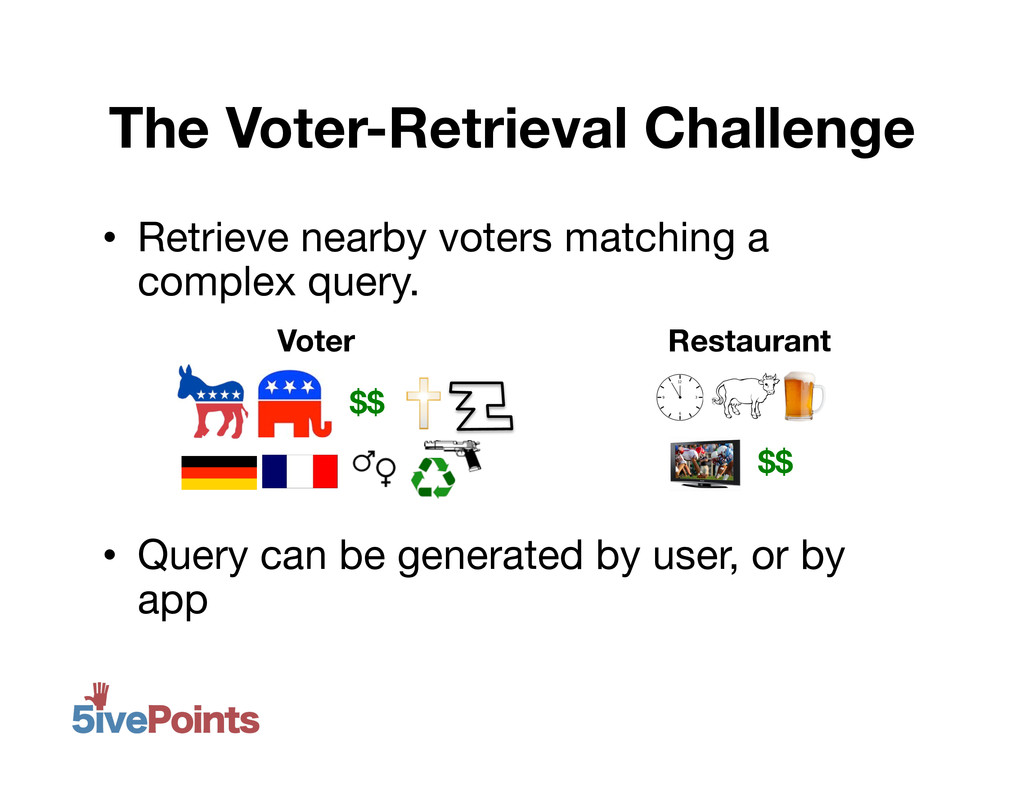
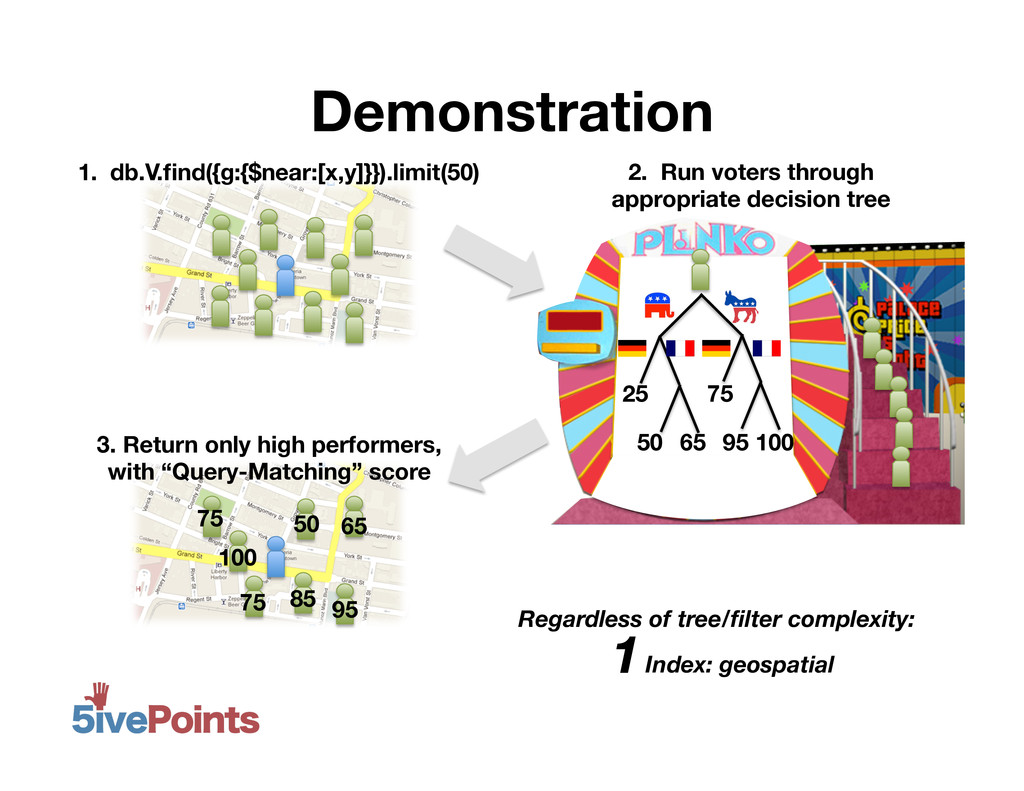
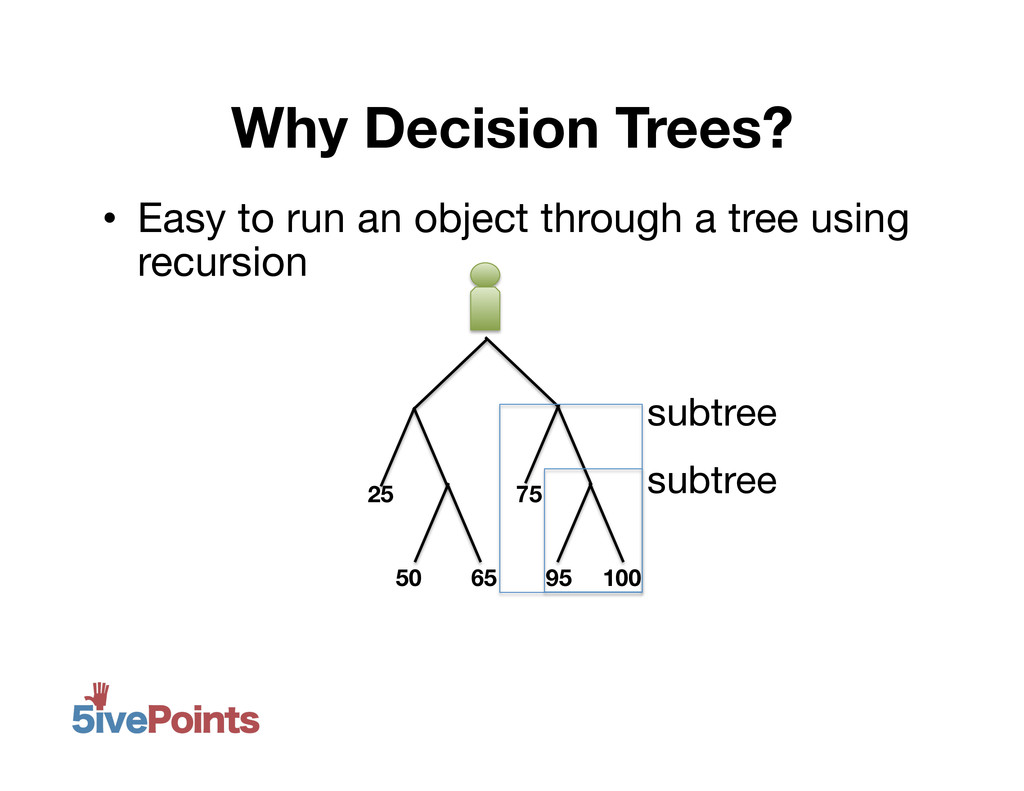
MongoDB NYC 2012: 80 Million Voters and Counting, Daniel Weitzenfeld, 5ivePoints. At 5ivePoints, we have a MongoDB database with 85+million US voters, every one of them geocoded. Our application allows supporters of political campaigns across the country to pull up nearby voters on their mobile phone to canvas. Moreover, campaigns can create custom filters using any combination of voter attributes, and we provide data-driven filters that update in near real-time based on campaign results. But with a collection of this size, each index is on the order of GBs, and un-indexed queries aren't feasible. I'll discuss how we are able to support flexible user queries - integrating both geo-spatial and other attributes - with only 4 indexes, minimizing page faults caused by pulling rarely-used indexes into memory.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}