Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Paper Introduction] Meta-trained agents implem...
Search
Naoto Yoshida
June 13, 2025
110
0
Share
[Paper Introduction] Meta-trained agents implement Bayes-optimal agents
2025/06/13
Paper introduction@TanichuLab
https://sites.google.com/view/tanichu-lab-ku/
Naoto Yoshida
June 13, 2025
More Decks by Naoto Yoshida
See All by Naoto Yoshida
Emergence Language Reading Group #1 @ Symbol Emergence Systems Group
ugonama
0
76
Featured
See All Featured
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
270
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
1
530
The browser strikes back
jonoalderson
0
980
Documentation Writing (for coders)
carmenintech
77
5.3k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
0
270
Embracing the Ebb and Flow
colly
88
5k
RailsConf 2023
tenderlove
30
1.4k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
110k
Thoughts on Productivity
jonyablonski
76
5.1k
The Spectacular Lies of Maps
axbom
PRO
1
710
How to make the Groovebox
asonas
2
2.1k
Believing is Seeing
oripsolob
1
110
Transcript
Meta-trained agents implement Bayes-optimal agents Symbol Emergence System Lab. Naoto
Yoshida 1 Journal Club Calendar, June 13, 2025
Paper Informa,on タイトル:Meta-trained agents implement Bayes-optimal agents 著者:Vladimir Mikulik, Grégoire
Delétang, Tom McGrath, Tim Genewein, Miljan Martic, Shane Legg, Pedro Ortega 公開:Advances in Neural Information Processing Systems 33 (NeurIPS 2020) リンク:https://proceedings.neurips.cc/paper/2020/hash/d902c3ce47124c66ce615d5ad9ba304f- Abstract.html 2
概要 問い:メモリベースのメタ(強化)学習はベイズ最適なモデルと同等の⾏動・構 造を実現するか? ※ 理論的にはその可能性が⽰唆(Ortega et al. 2019) à 計算機実験で実証
ざっくり解説 • (メモリベース)メタ学習:多様なタスクを学習することで、新たなタスクに対 してもパラメータを固定したままで学習能⼒を持つ現象・問題系 • 今で⾔うLLMのin-context learning そのもの • メタ強化学習:メタ学習を強化学習問題に適⽤したケース 3 Ortega, Pedro A., et al. "Meta-learning of sequential strategies." arXiv preprint arXiv:1905.03030 (2019).
Background:メタ強化学習 • Wang et al. のパラダイム • RNN に学習時系列を⼊⼒として多様 な環境で最適化することで、ネット
ワークが内部のメモリを使って適⽤ 能⼒を獲得 4 Wang, Jane X., et al. "Learning to reinforcement learn." arXiv preprint arXiv:1611.05763 (2016). Wang, Jane X., et al. "Prefrontal cortex as a meta-reinforcement learning system." Nature neuroscience 21.6 (2018): 860-868. Two-arm bandit でのメタ強化学習結果の適応⾏動 テスト環境での振る舞い メタ強化学習アーキテクチャ 訓練環境(多様な環境) テスト環境 (パラメータ固定) Meta-RLの観測
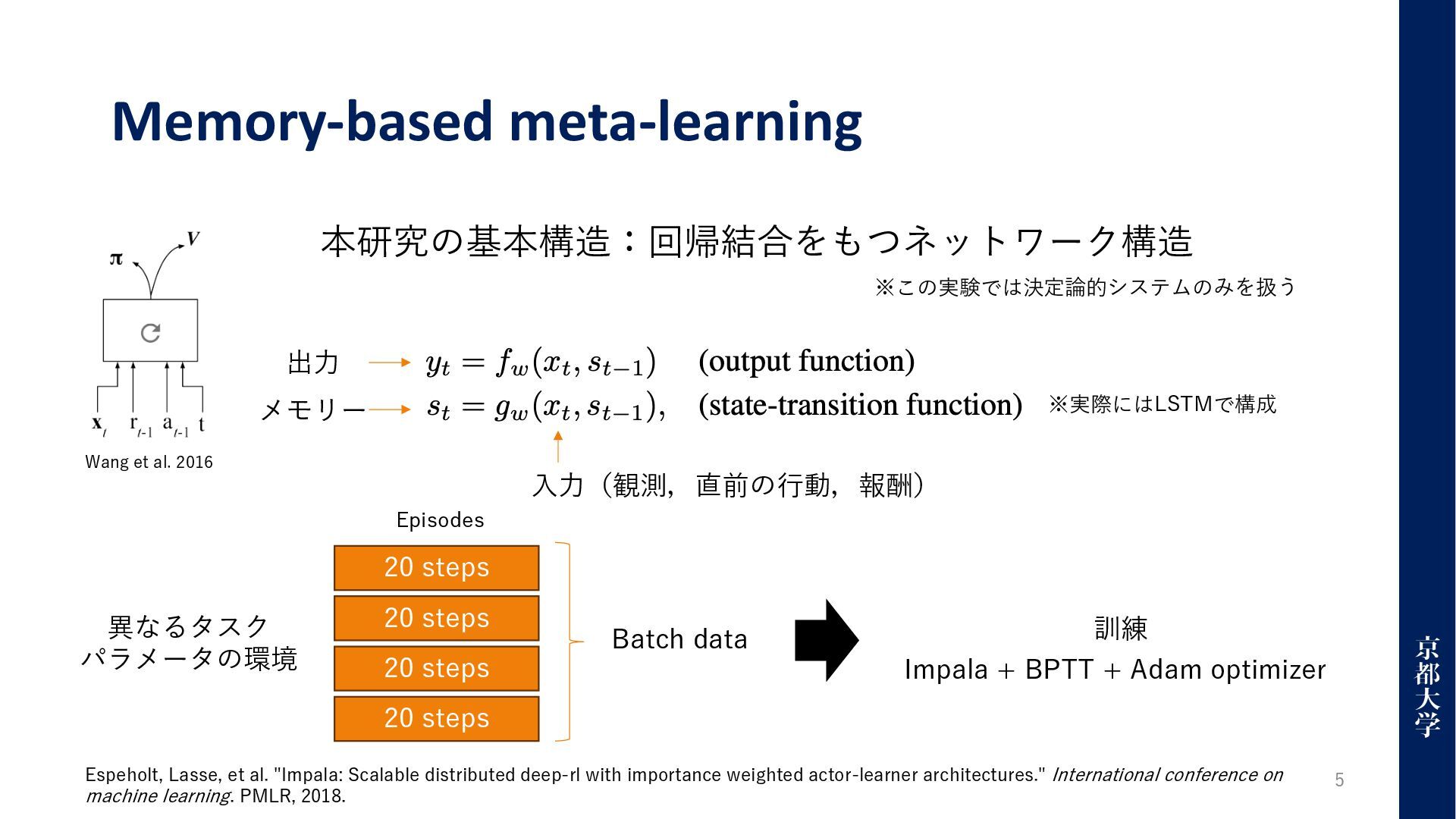
Memory-based meta-learning 5 本研究の基本構造:回帰結合をもつネットワーク構造 ※実際にはLSTMで構成 Wang et al. 2016 出⼒
メモリー Espeholt, Lasse, et al. "Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures." International conference on machine learning. PMLR, 2018. ⼊⼒(観測,直前の⾏動,報酬) ※この実験では決定論的システムのみを扱う 20 steps 20 steps 20 steps 20 steps Episodes Batch data Impala + BPTT + Adam optimizer 訓練 異なるタスク パラメータの環境
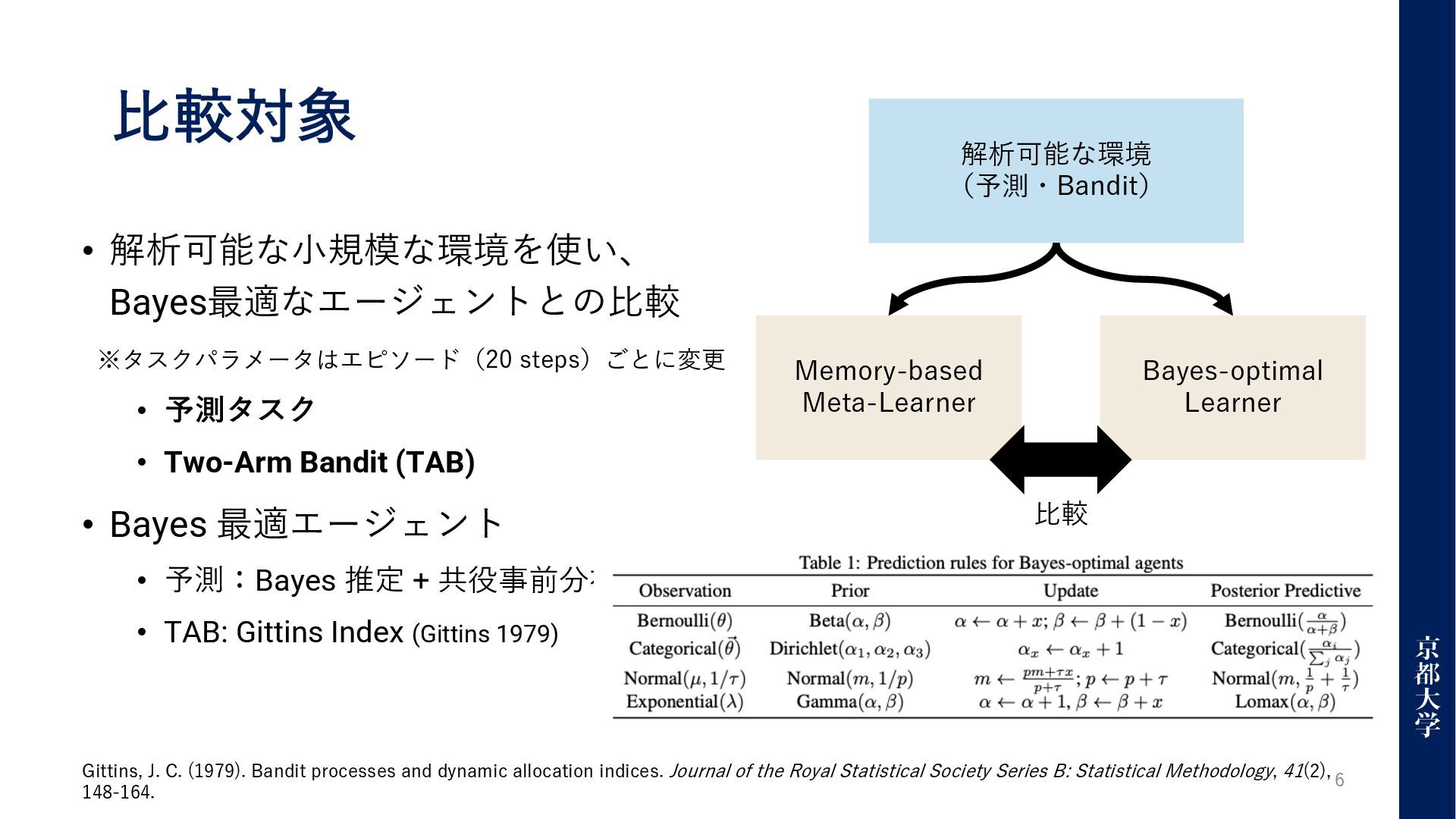
⽐較対象 • 解析可能な⼩規模な環境を使い、 Bayes最適なエージェントとの⽐較 • 予測タスク • Two-Arm Bandit (TAB)
• Bayes 最適エージェント • 予測:Bayes 推定 + 共役事前分布 • TAB: Gittins Index (Gittins 1979) 6 解析可能な環境 (予測・Bandit) Memory-based Meta-Learner Bayes-optimal Learner ⽐較 Gittins, J. C. (1979). Bandit processes and dynamic allocation indices. Journal of the Royal Statistical Society Series B: Statistical Methodology, 41(2), 148-164. ※タスクパラメータはエピソード(20 steps)ごとに変更
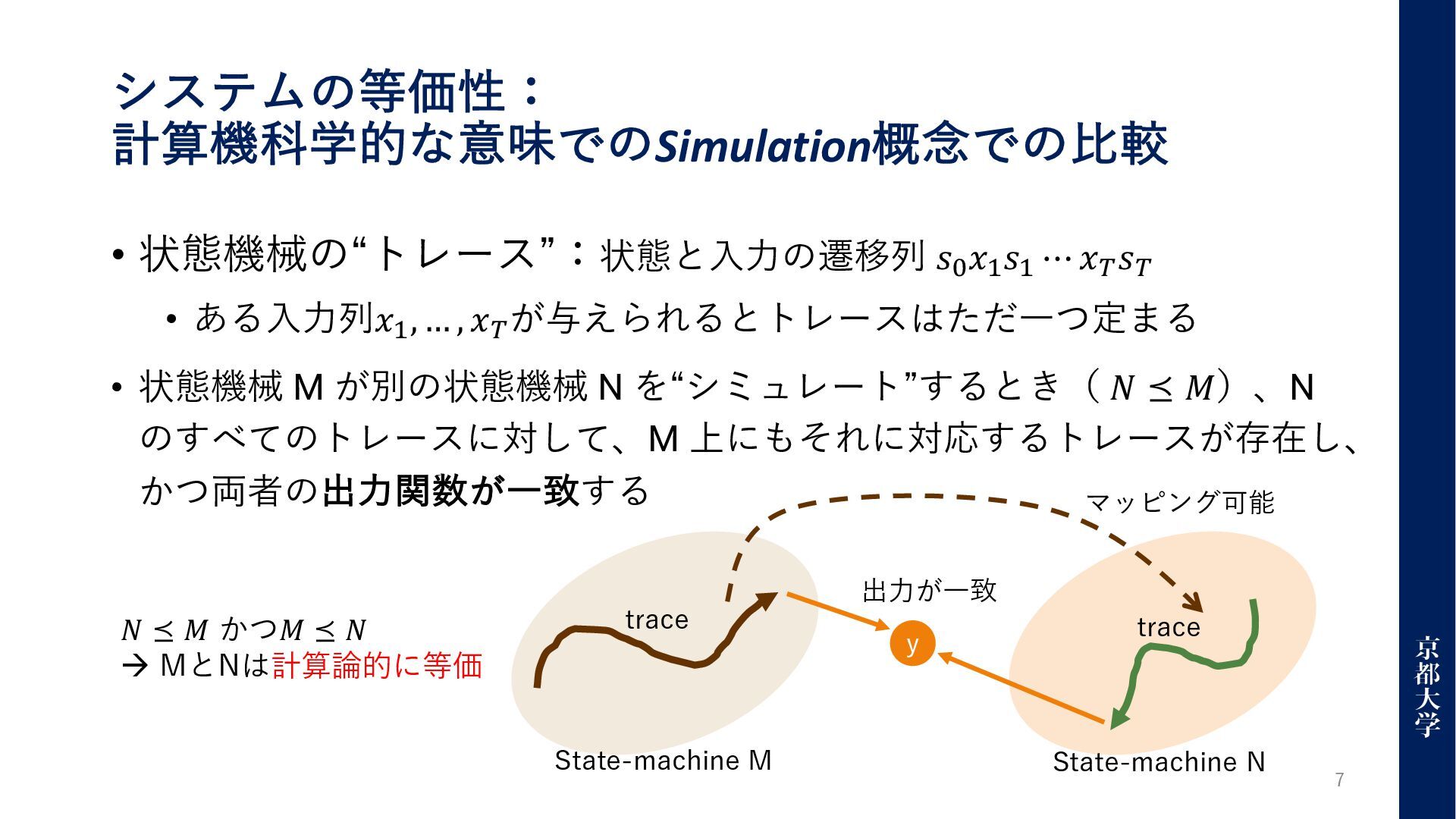
システムの等価性: 計算機科学的な意味でのSimulation概念での⽐較 • 状態機械の“トレース”:状態と⼊⼒の遷移列 𝑠!𝑥"𝑠" ⋯ 𝑥#𝑠# • ある⼊⼒列𝑥", …
, 𝑥# が与えられるとトレースはただ⼀つ定まる • 状態機械 M が別の状態機械 N を“シミュレート”するとき( 𝑁 ⪯ 𝑀)、N のすべてのトレースに対して、M 上にもそれに対応するトレースが存在し、 かつ両者の出⼒関数が⼀致する 7 State-machine M State-machine N y 出⼒が⼀致 trace trace マッピング可能 𝑁 ⪯ 𝑀 かつ𝑀 ⪯ 𝑁 à MとNは計算論的に等価
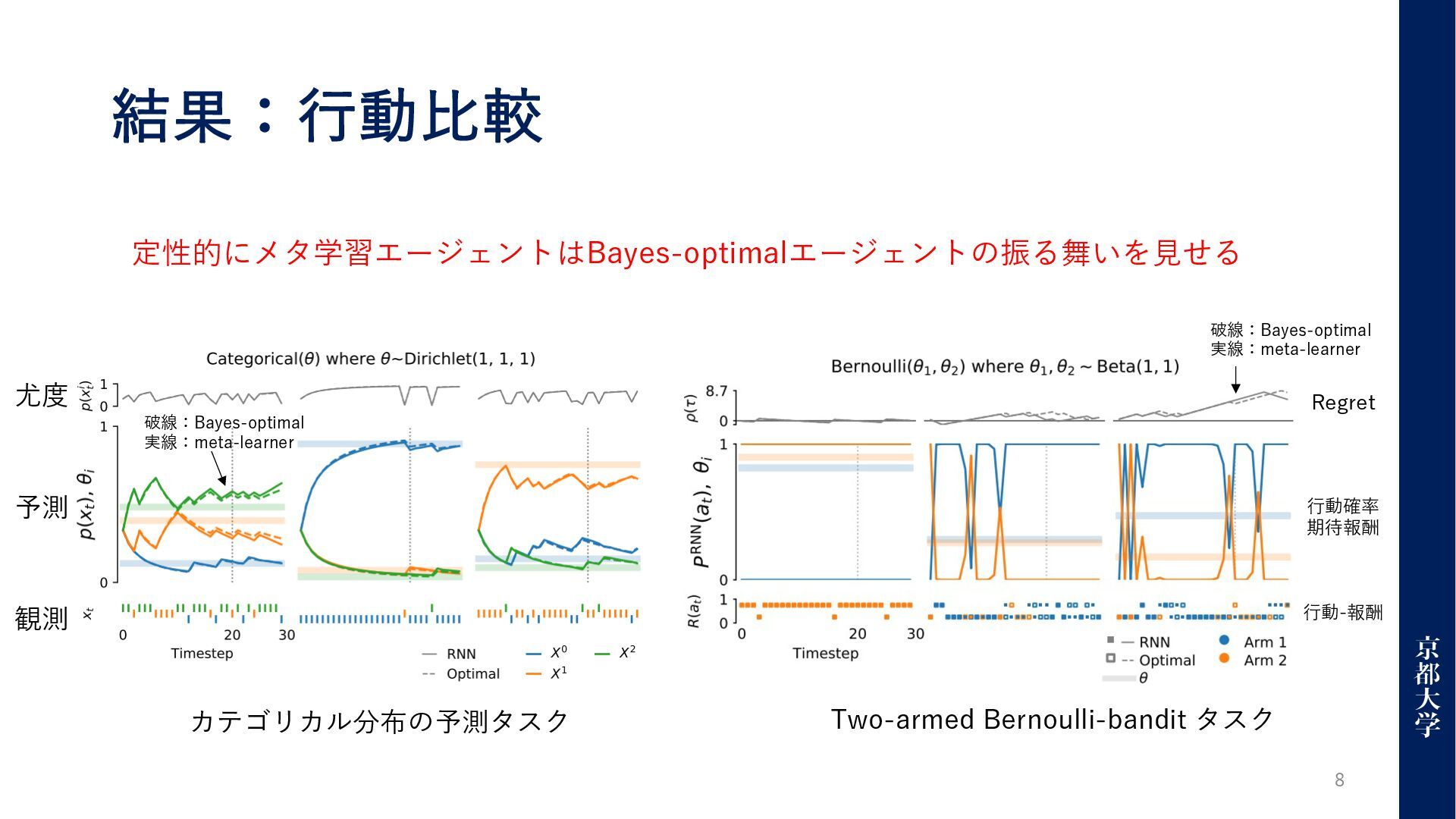
結果:⾏動⽐較 8 カテゴリカル分布の予測タスク Two-armed Bernoulli-bandit タスク 定性的にメタ学習エージェントはBayes-optimalエージェントの振る舞いを⾒せる 破線:Bayes-optimal 実線:meta-learner 観測
予測 尤度 ⾏動-報酬 ⾏動確率 期待報酬 Regret 破線:Bayes-optimal 実線:meta-learner
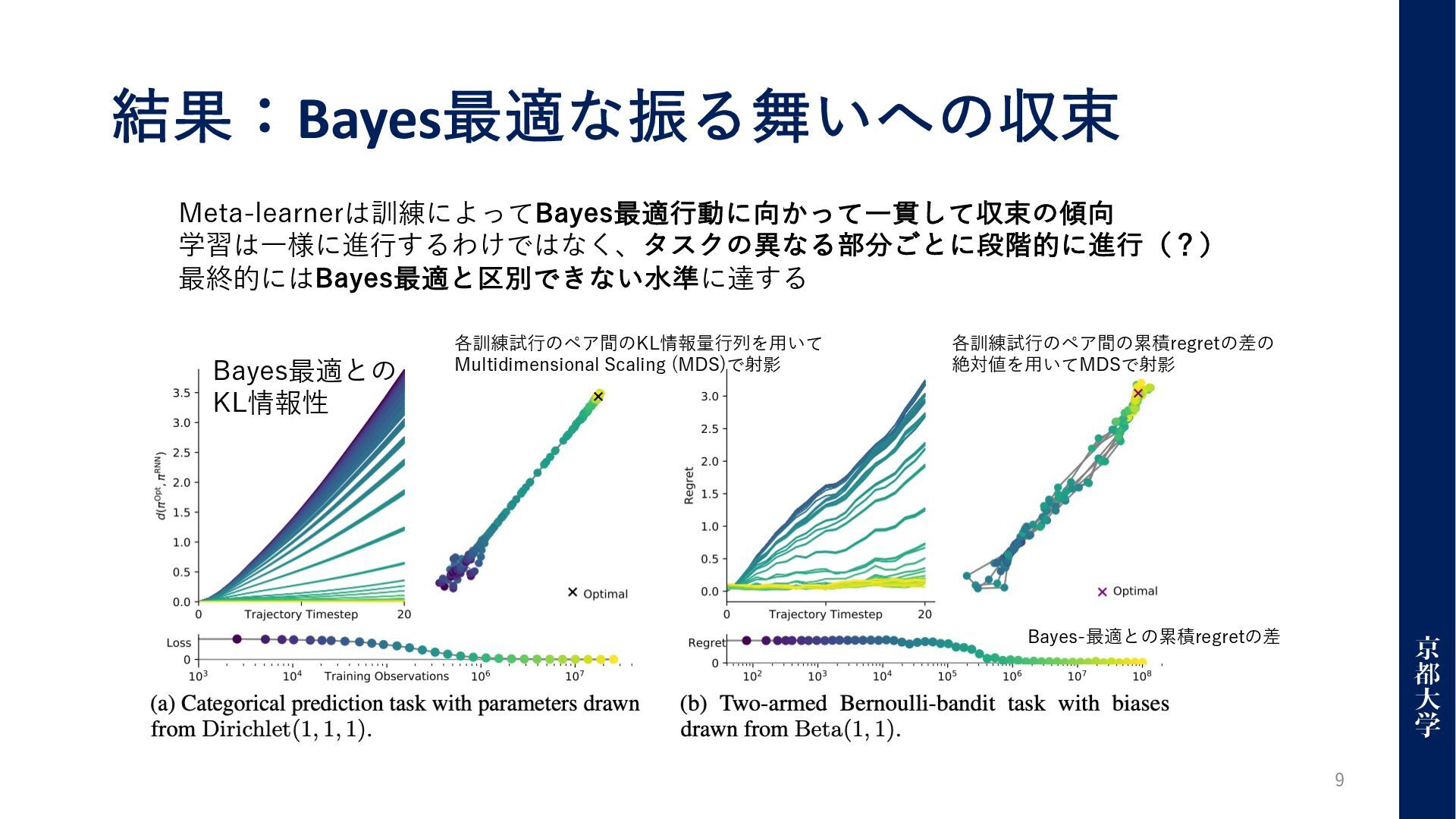
結果:Bayes最適な振る舞いへの収束 9 Meta-learnerは訓練によってBayes最適⾏動に向かって⼀貫して収束の傾向 学習は⼀様に進⾏するわけではなく、タスクの異なる部分ごとに段階的に進⾏(?) 最終的にはBayes最適と区別できない⽔準に達する Bayes最適との KL情報性 各訓練試⾏のペア間のKL情報量⾏列を⽤いて Multidimensional Scaling
(MDS)で射影 各訓練試⾏のペア間の累積regretの差の 絶対値を⽤いてMDSで射影 Bayes-最適との累積regretの差
結果:構造⽐較(埋め込み) 10 Categorical prediction Two-armed bandit 対応する予測(⾊) 対応する⾏動(⾊) LSTMの状態とBayes-optimalエージェントの⼗分統計量をPCAで次元削減 双⽅向の埋め込み関数(MLP)を学習(RNN
→ Bayes-optimal, Bayes-optimal → RNN) 同じ試⾏の軌道 (⽩線) Meta-learnerの内部表現は、Bayes-optimalな計算構造を構成している
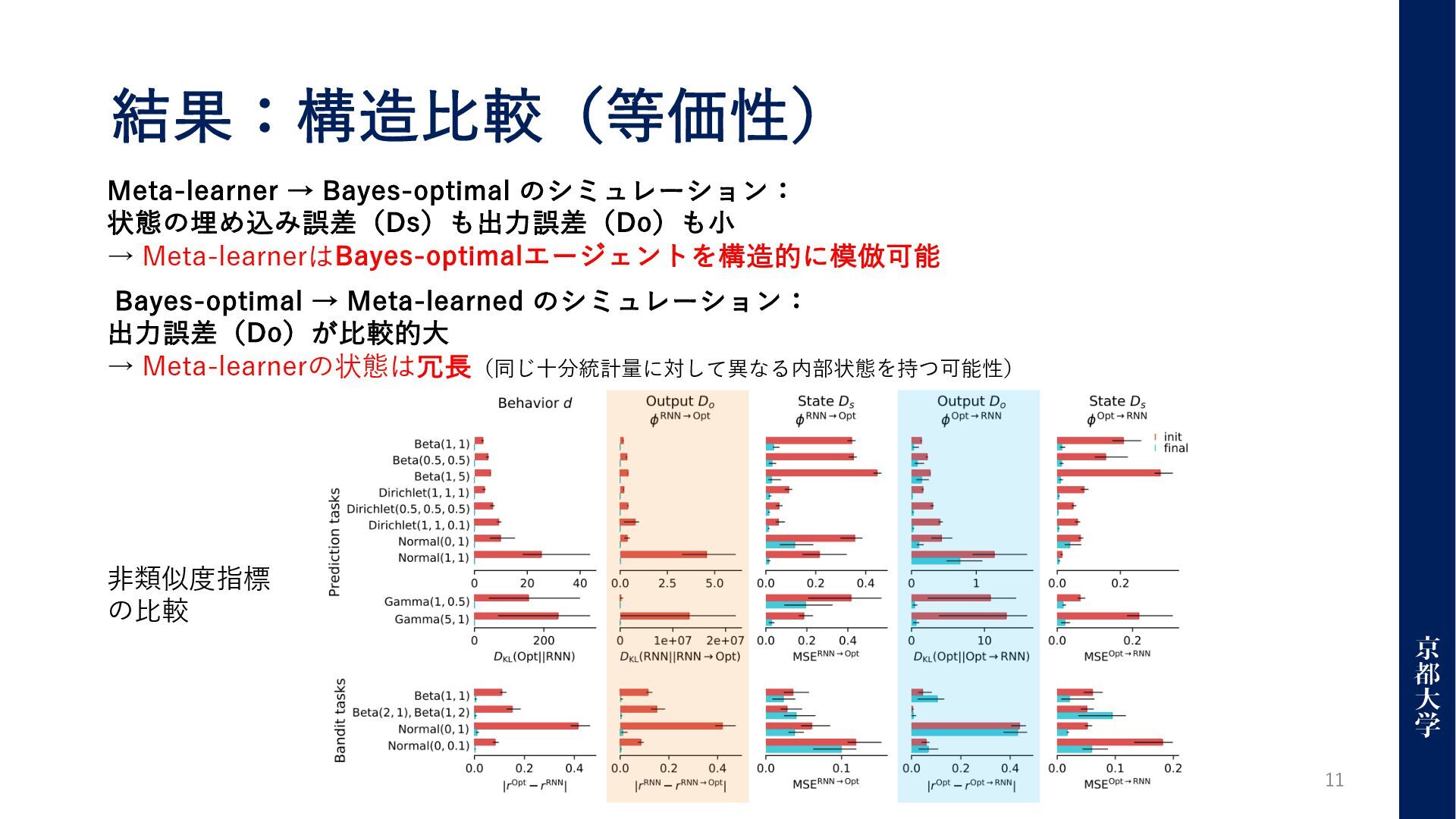
結果:構造⽐較(等価性) 11 Meta-learner → Bayes-optimal のシミュレーション: 状態の埋め込み誤差(Ds)も出⼒誤差(Do)も⼩ → Meta-learnerはBayes-optimalエージェントを構造的に模倣可能 Bayes-optimal
→ Meta-learned のシミュレーション: 出⼒誤差(Do)が⽐較的⼤ → Meta-learnerの状態は冗⻑(同じ⼗分統計量に対して異なる内部状態を持つ可能性) ⾮類似度指標 の⽐較
結論 • Meta-learnerは、最終的にBayes最適な⾏動をとるよう学習し、⾏動的にも構造的にも区 別がつかない • Meta-learnerの状態空間はBayes最適なエージェントのトレースをシミュレートできるが、 その逆(Bayes→Meta)は完全ではない Limitation • 解析解のある単純なタスクに限定されており、複雑な問題にはそのまま拡張できない可能性
12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}