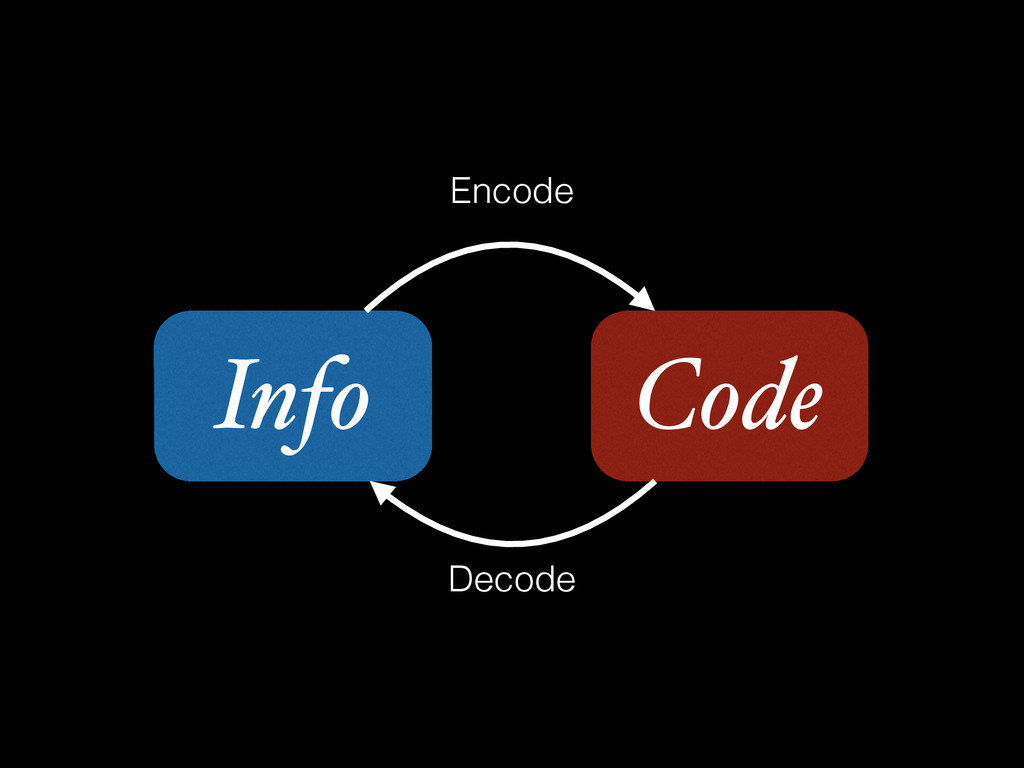
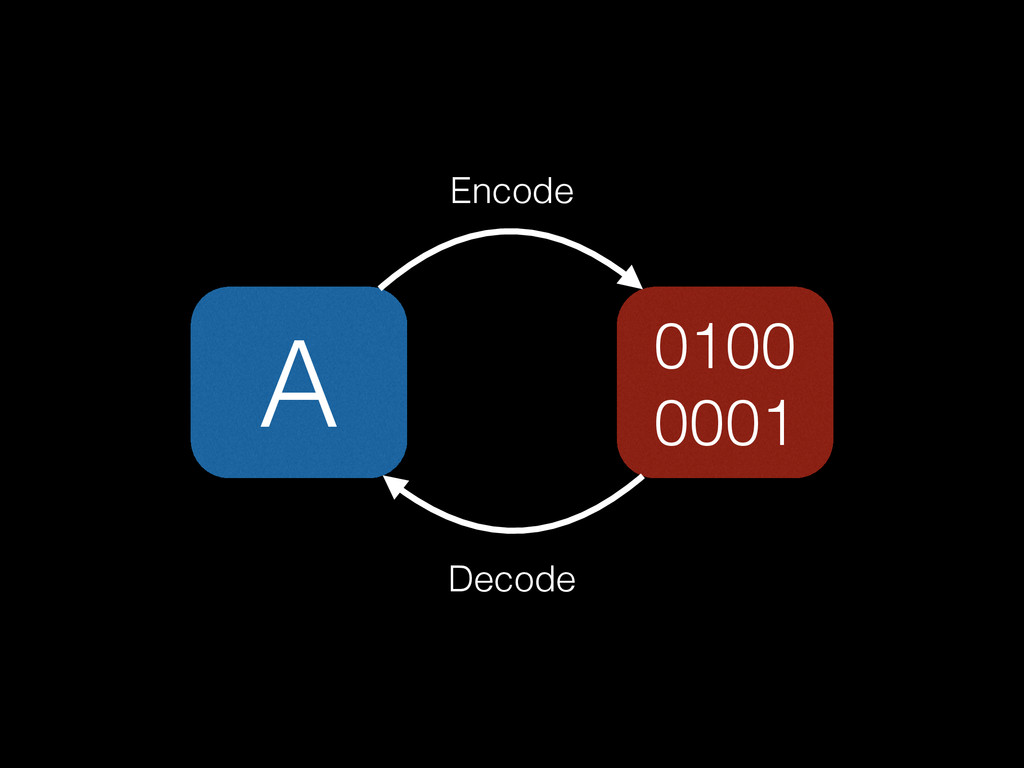
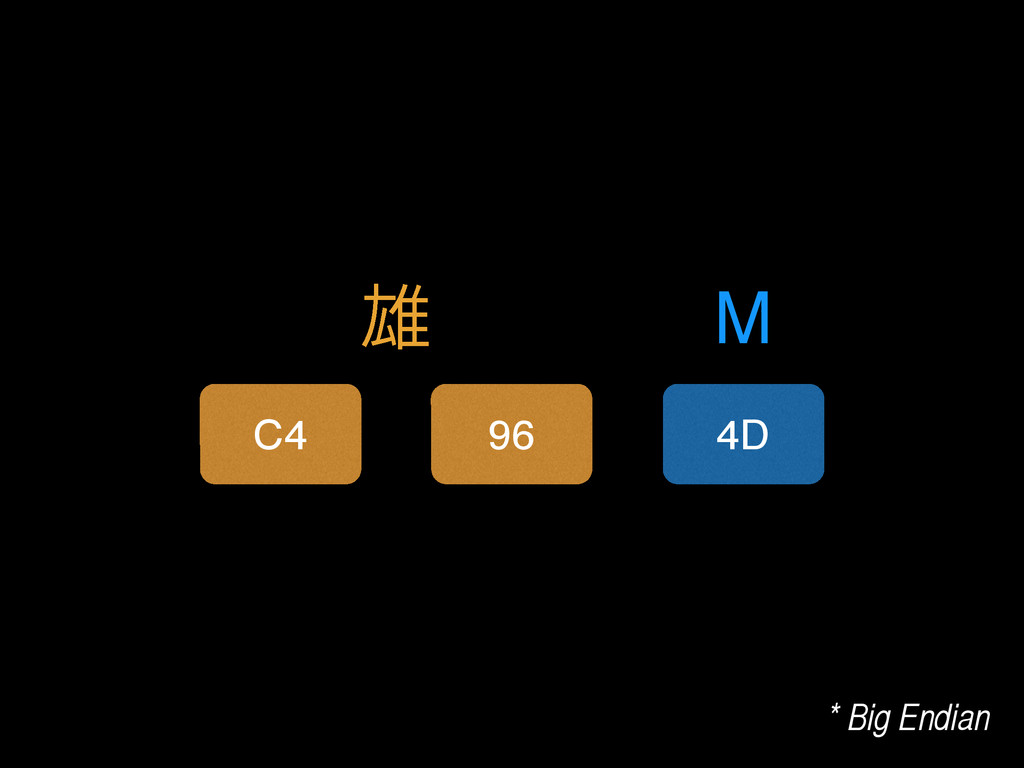
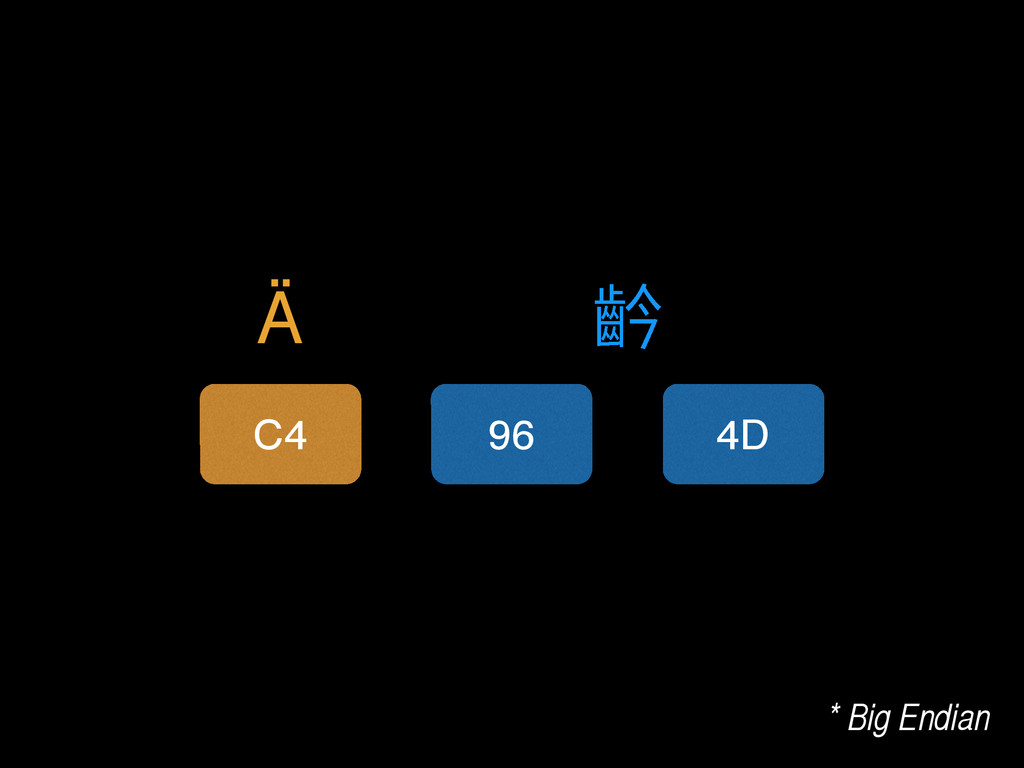
Does your app contain text? I bet it does. But can it handle them correctly? I bet it can’t! Your app is not handling text correctly. “Wait,” I hear you say, “our app is fine. It uses Unicode.” Right. Except you don't really understand Unicode, and as a consequence your code doesn't really handle it. Here I’ll tell you what Unicode really is, and how you really should handle it in your next app. Correctly.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
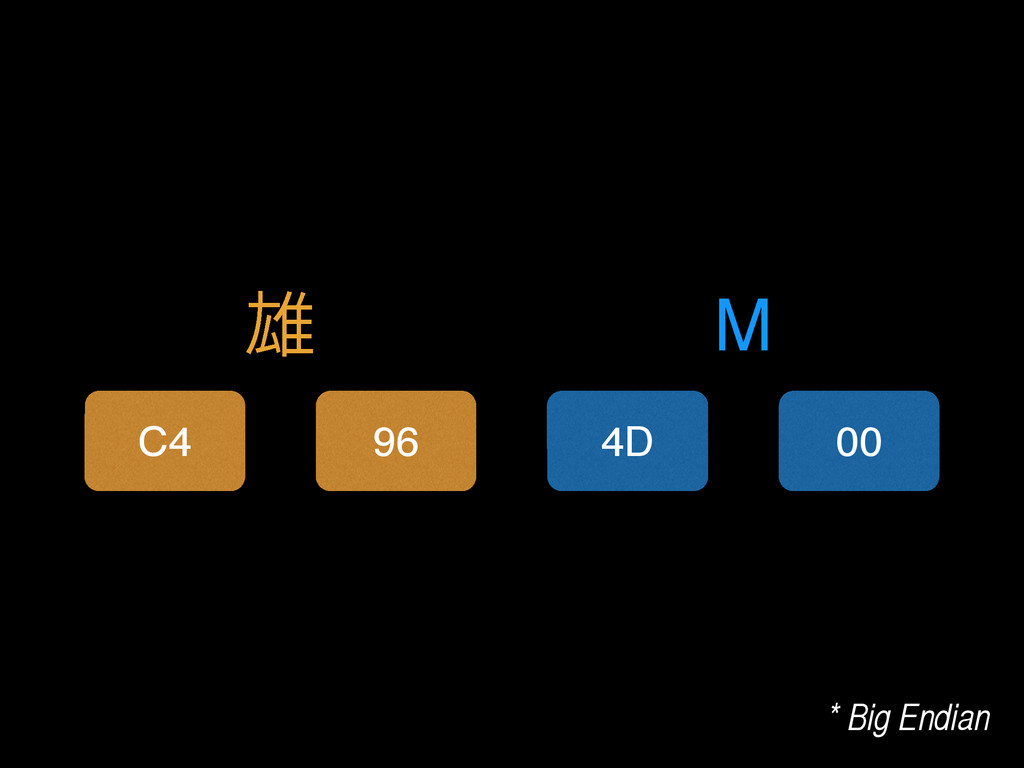{kind=link}
{kind=link}
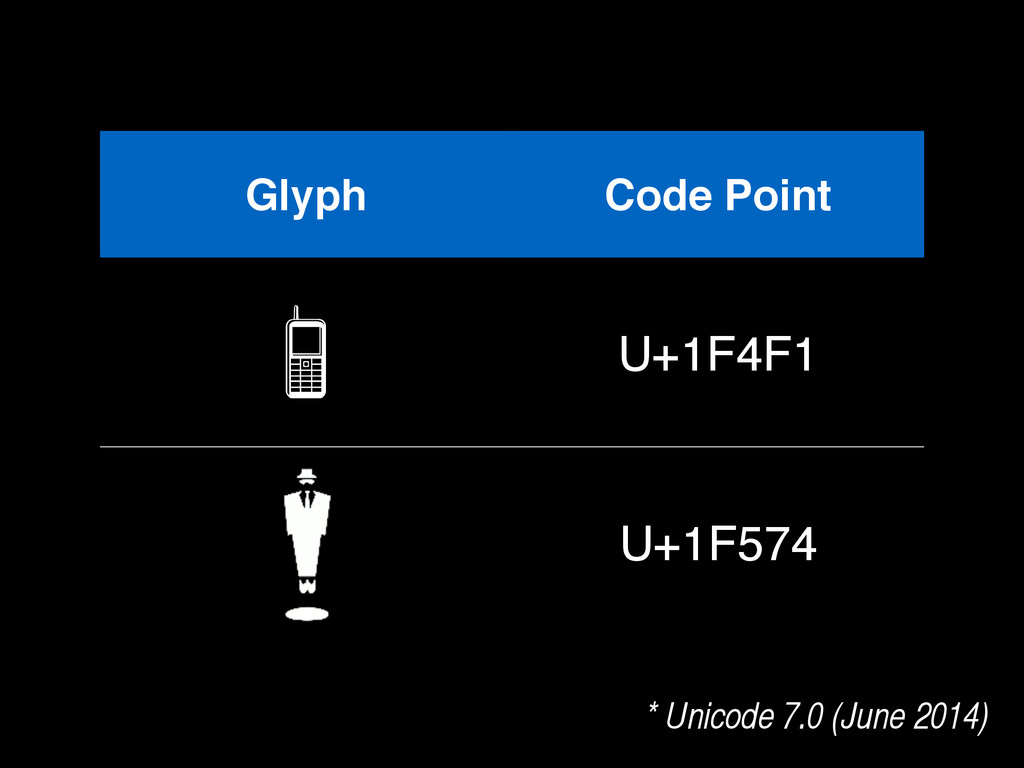{kind=link}
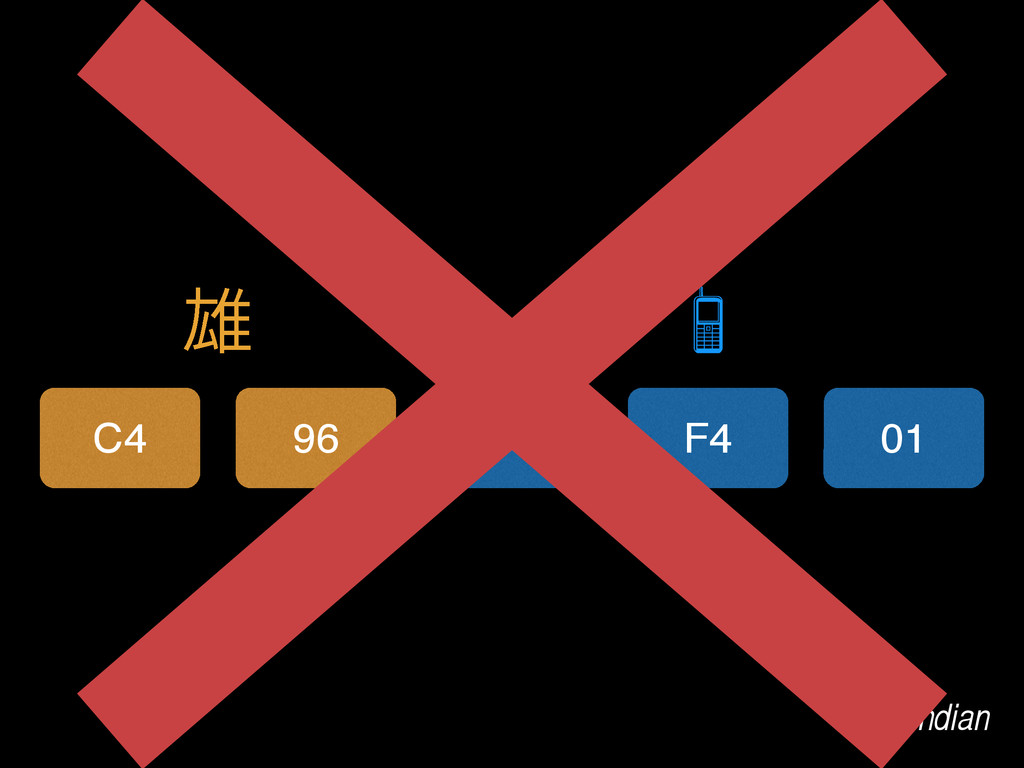{kind=link}
{kind=link}
{kind=link}
{kind=link}
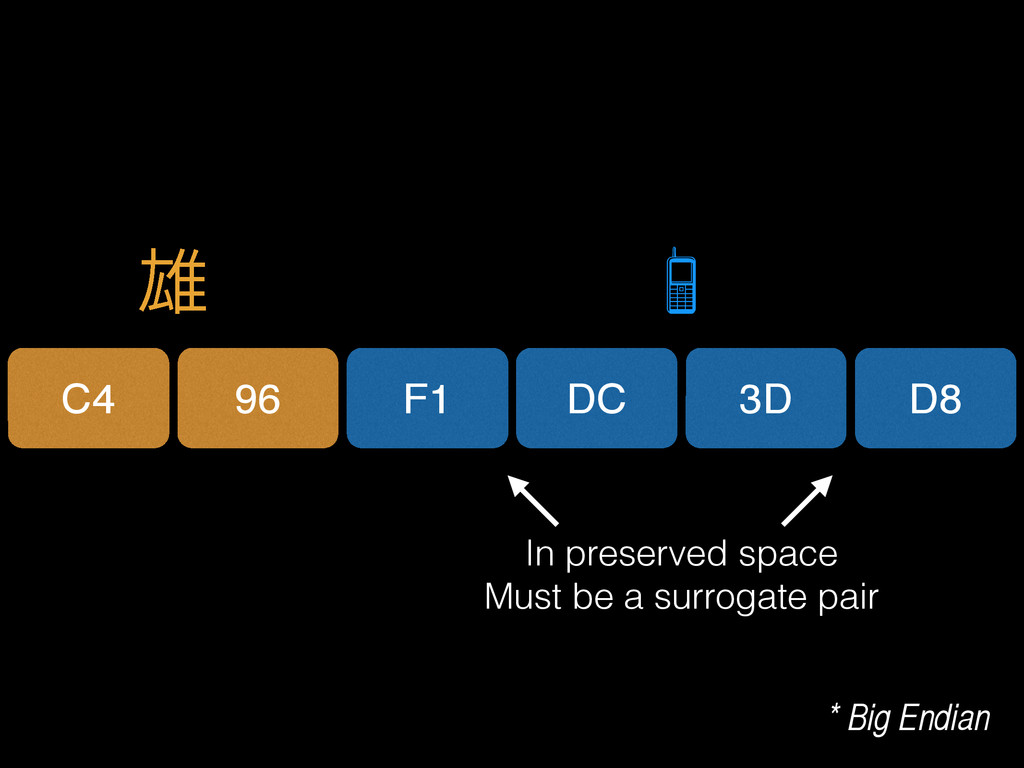{kind=link}
{kind=link}
{kind=link}
![F1 s = DC * Big Endian 3D D8 s[0]](https://files.speakerdeck.com/presentations/49ace4203e430132341052932d7daf42/slide_32.jpg){kind=link}
![s = "MOPCON" print s[0]](https://files.speakerdeck.com/presentations/49ace4203e430132341052932d7daf42/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
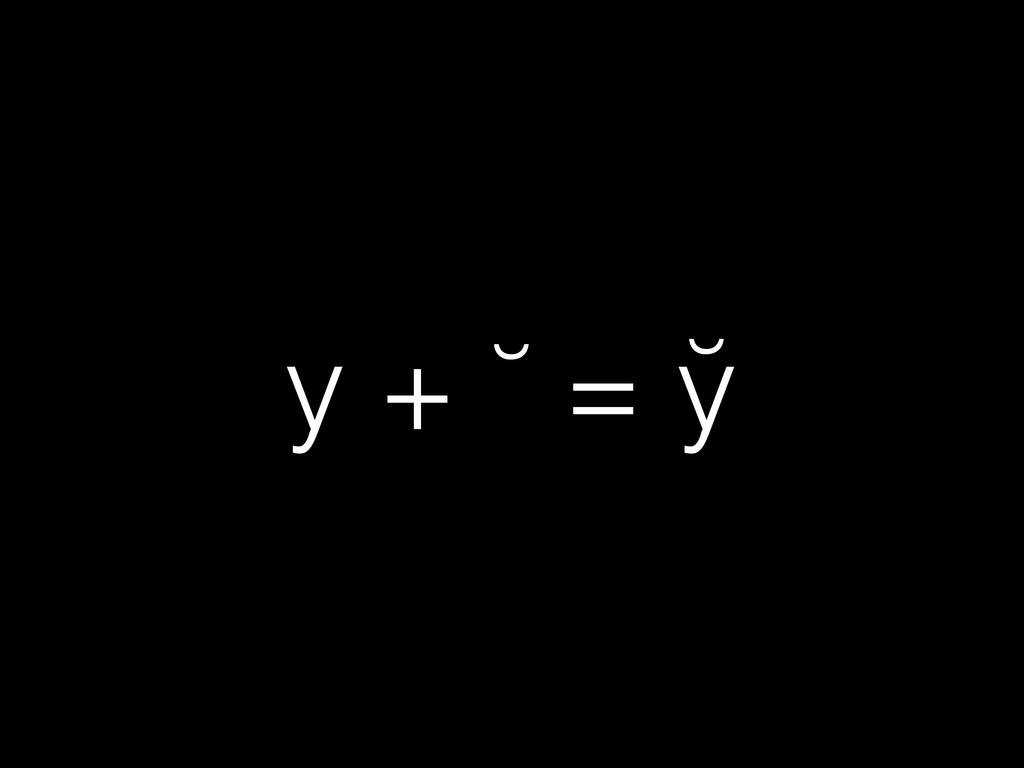{kind=link}
{kind=link}
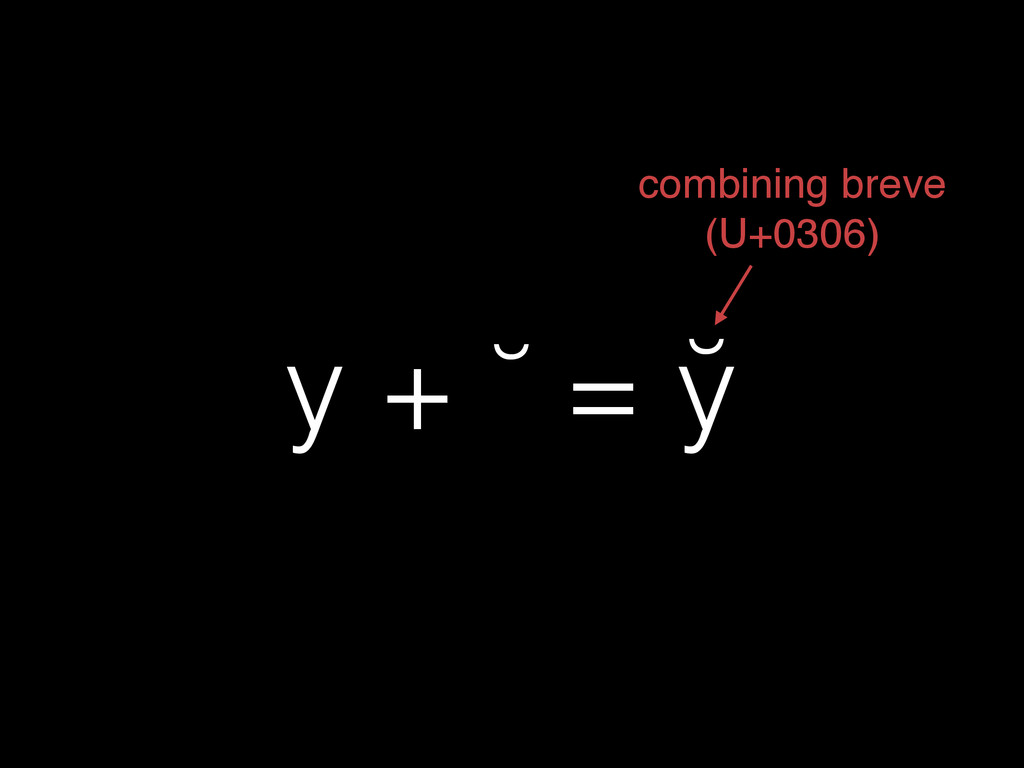{kind=link}
{kind=link}
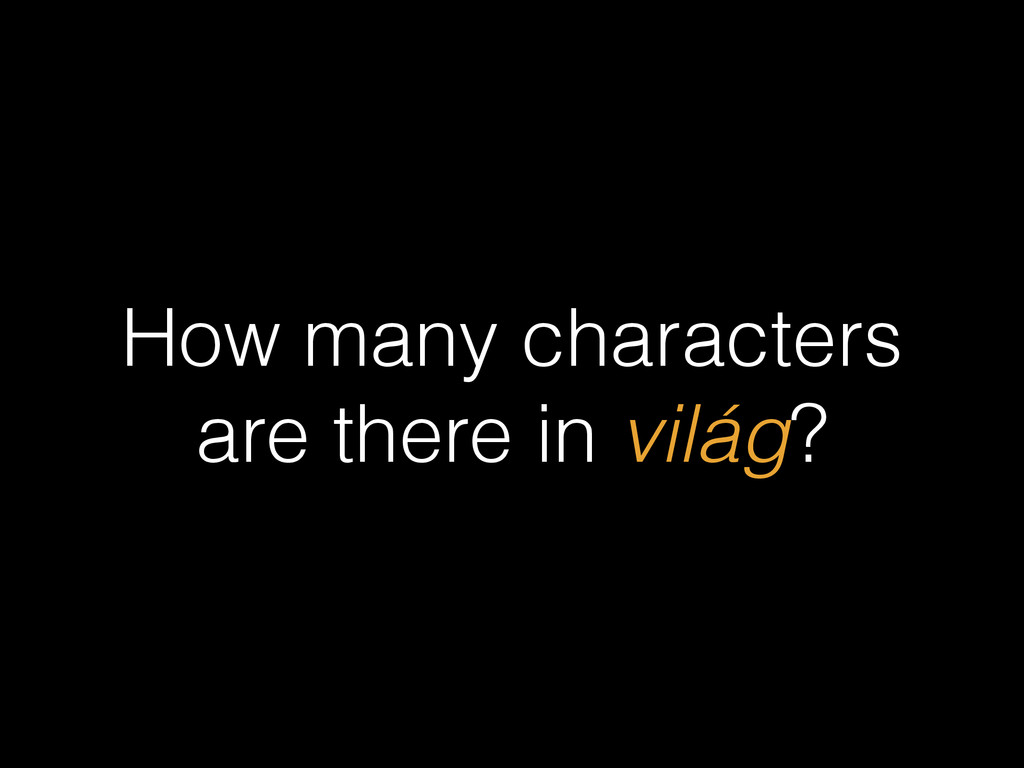{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
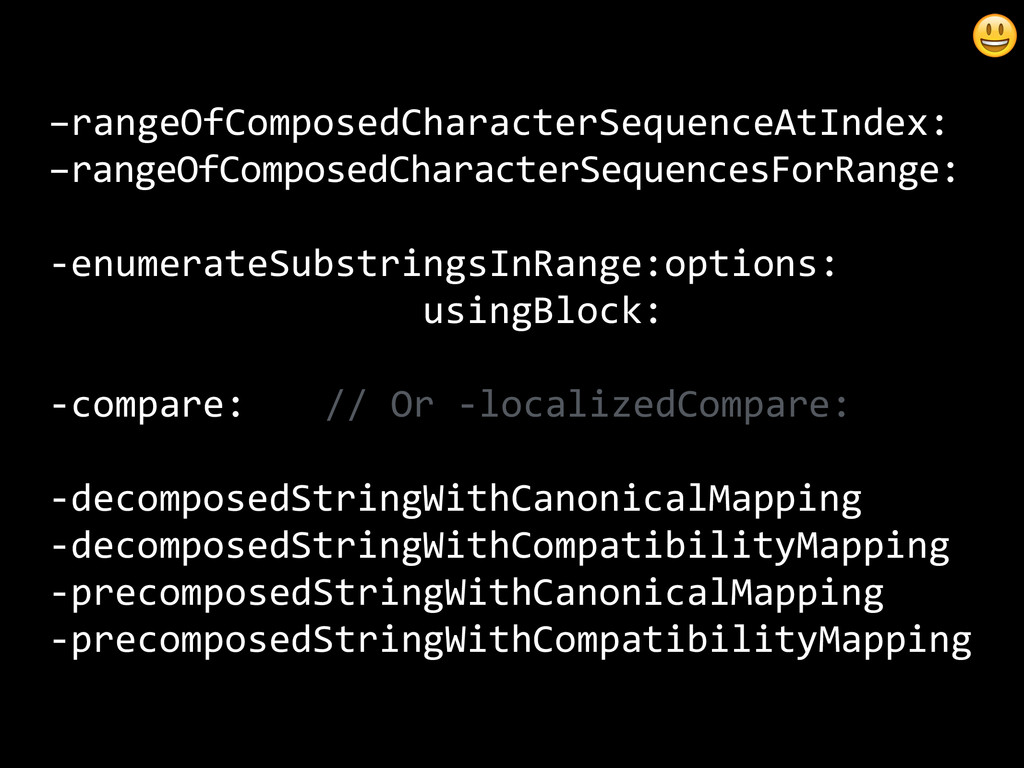{kind=link}
{kind=link}
![But. // String(seq:Array("")[0..<2]) // "".substringWithRange(](https://files.speakerdeck.com/presentations/49ace4203e430132341052932d7daf42/slide_50.jpg){kind=link}
{kind=link}
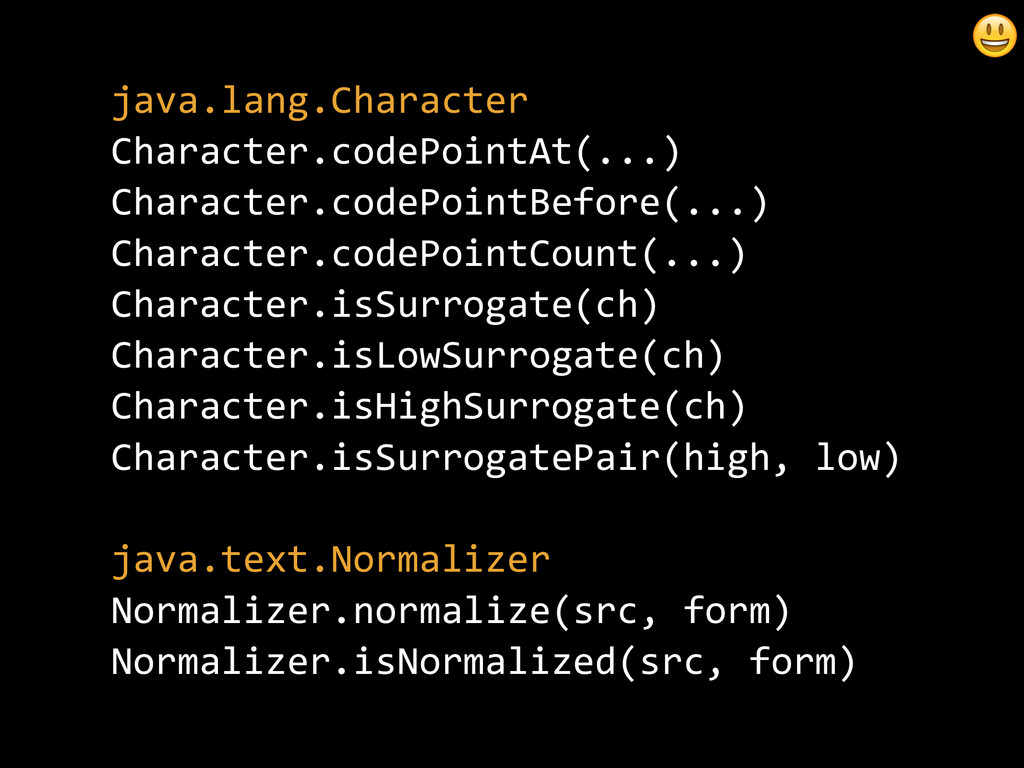{kind=link}
{kind=link}
{kind=link}
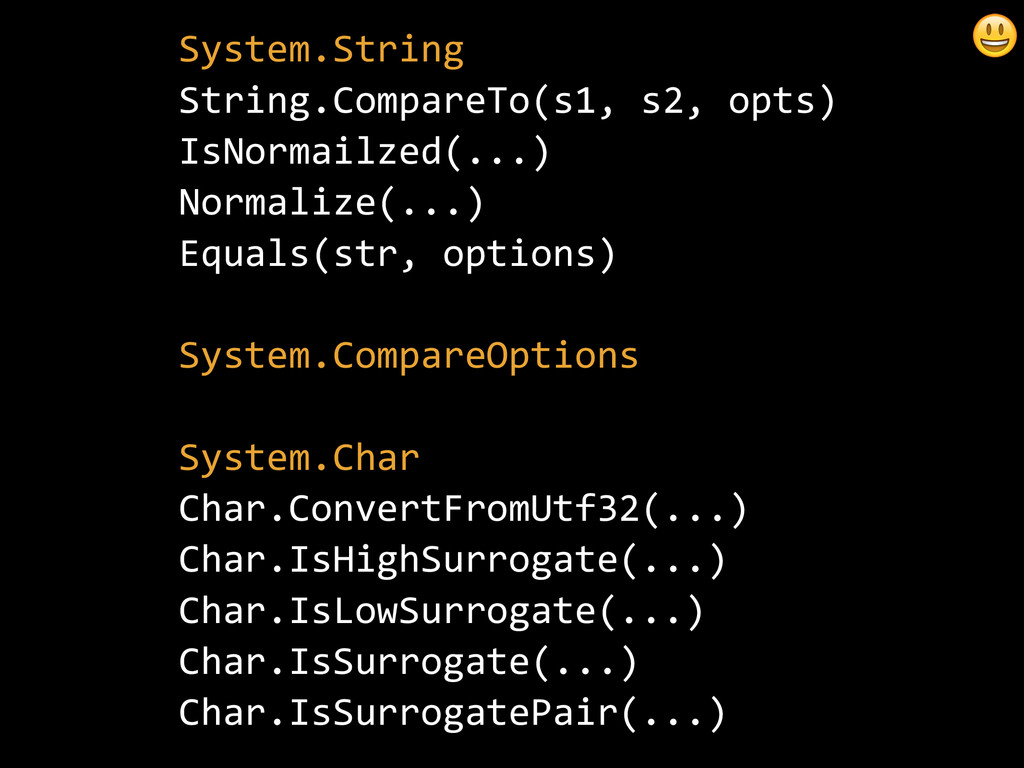{kind=link}
{kind=link}
{kind=link}