performance, but tedious development cycle (the assembly language of Hadoop). 2.! Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3.! Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google’s FlumeJava) 4.! Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5.! Hive: A SQL interpreter out of Facebook, also includes a meta- store mapping files to their schemas and associated SerDes. 6.! Oozie: A PDL XML workflow engine that enables creating a workflow of jobs composed of any of the above.
flexibility and performance, but tedious development cycle (the assembly language of Hadoop). 2.! Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3.! Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google’s FlumeJava) 4.! Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5.! Hive: A SQL interpreter out of Facebook, also includes a meta- store mapping files to their schemas and associated SerDes. 6.! Oozie: A PDL XML workflow engine that enables creating a workflow of jobs composed of any of the above.
flexibility and performance, but tedious development cycle (the assembly language of Hadoop). 2.! Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3.! Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google’s FlumeJava) 4.! Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5.! Hive: A SQL interpreter out of Facebook, also includes a meta- store mapping files to their schemas and associated SerDes. 6.! Oozie: A PDL XML workflow engine that enables creating a workflow of jobs composed of any of the above.
flexibility and performance, but tedious development cycle (the assembly language of Hadoop). 2.! Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3.! Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google’s FlumeJava) 4.! Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5.! Hive: A SQL interpreter out of Facebook, also includes a meta- store mapping files to their schemas and associated SerDes. 6.! Oozie: A PDL XML workflow engine that enables creating a workflow of jobs composed of any of the above.
1.! Java MapReduce: Most flexibility and performance, but tedious development cycle (the assembly language of Hadoop). 2.! Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3.! Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google’s FlumeJava) 4.! Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5.! Hive: A SQL interpreter out of Facebook, also includes a meta- store mapping files to their schemas and associated SerDes. 6.! Oozie: A PDL XML workflow engine that enables creating a workflow of jobs composed of any of the above.
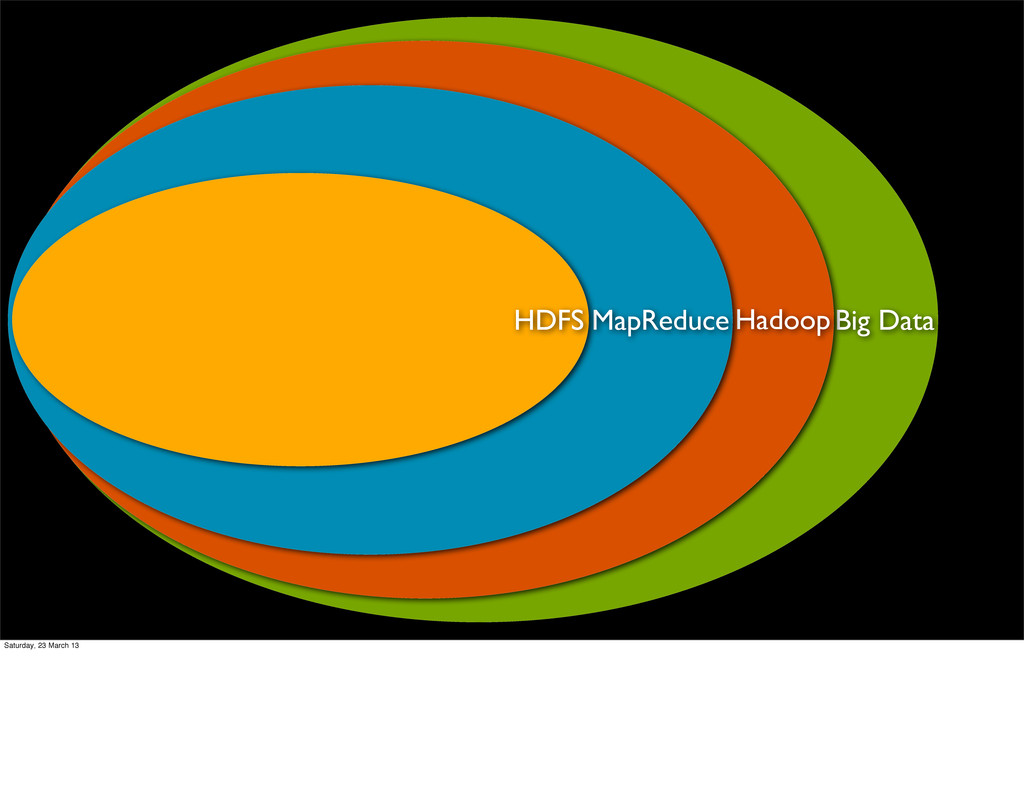
An expertise? A trend? A cliché? It’s a buzz word, but generally associated with the problem of data sets too big to manage with traditional SQL databases. A parallel development has been the NoSQL movement that is good at handling semistructured data, scaling, etc.!Flexible infrastructure for large scale computation & data processing on a network of commodity hardware !Completely written in java !Open source & distributed under Apache license !Hadoop Common, HDFS & MapReduce
of data? An industry? An expertise? A trend? A cliché? It’s a buzz word, but generally associated with the problem of data sets too big to manage with traditional SQL databases. A parallel development has been the NoSQL movement that is good at handling semistructured data, scaling, etc.!Flexible infrastructure for large scale computation & data processing on a network of commodity hardware !Completely written in java !Open source & distributed under Apache license !Hadoop Common, HDFS & MapReduce
to describe data sets so large and complex that they become awkward to work with using on-hand database management tools. en.wikipedia.org/wiki/Big_data “ ” Saturday, 23 March 13
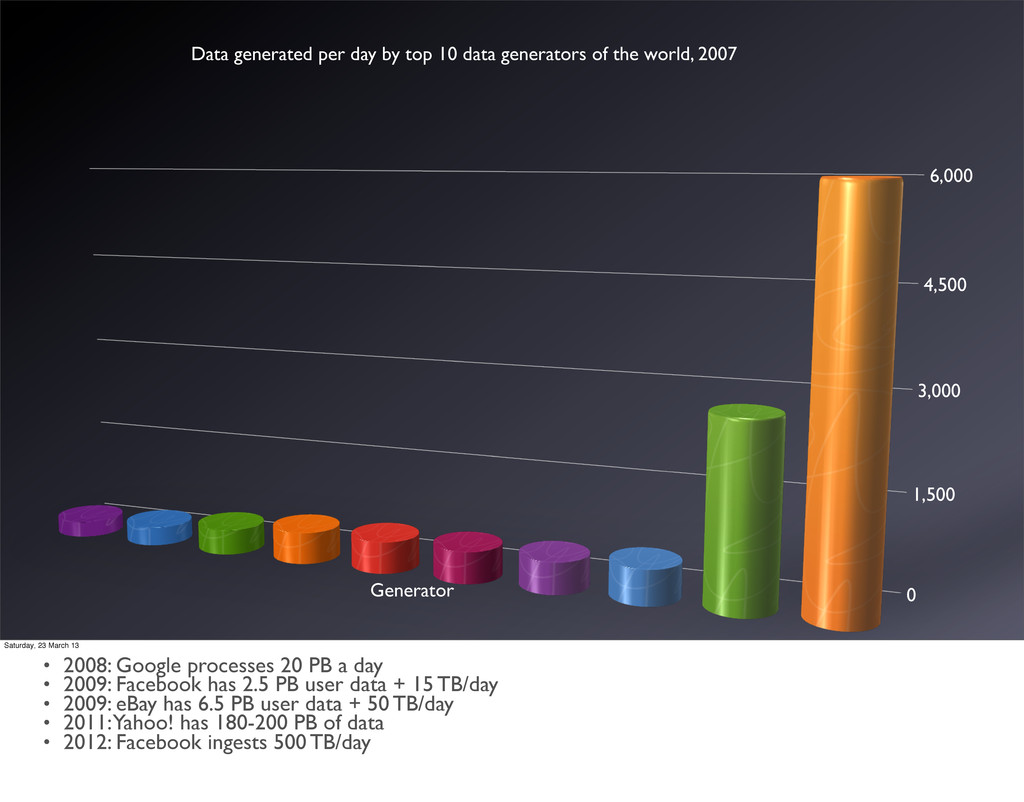
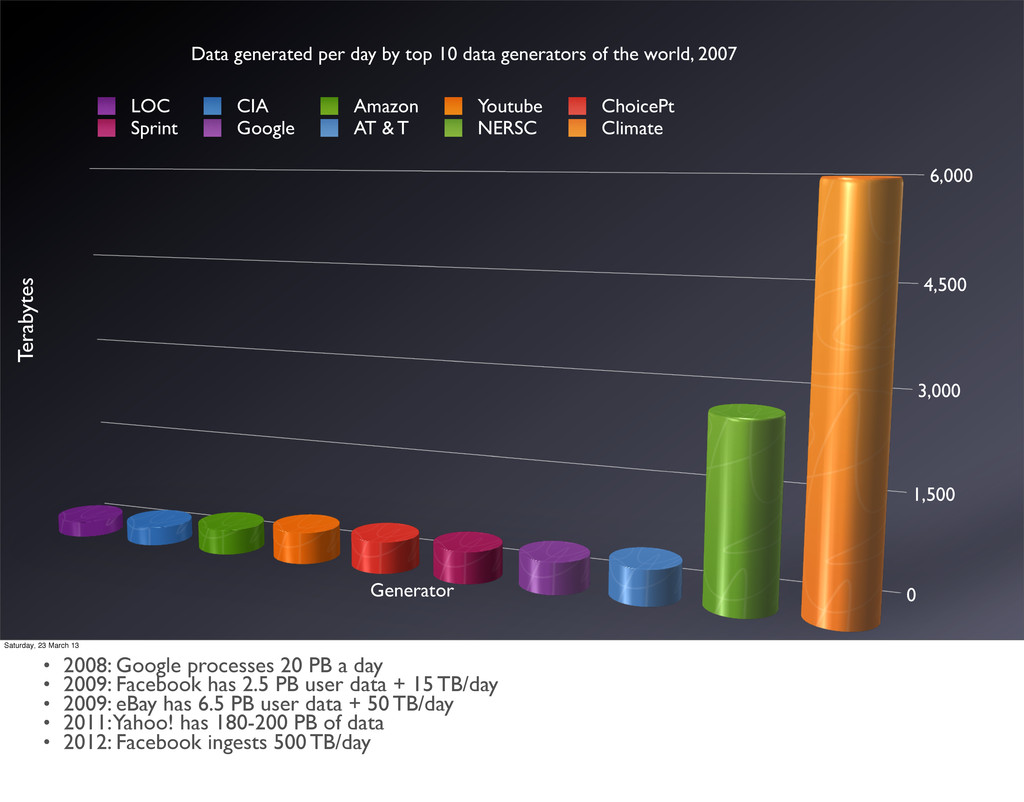
a day • 2009: Facebook has 2.5 PB user data + 15 TB/day • 2009: eBay has 6.5 PB user data + 50 TB/day • 2011: Yahoo! has 180-200 PB of data • 2012: Facebook ingests 500 TB/day
by top 10 data generators of the world, 2007 Saturday, 23 March 13 • 2008: Google processes 20 PB a day • 2009: Facebook has 2.5 PB user data + 15 TB/day • 2009: eBay has 6.5 PB user data + 50 TB/day • 2011: Yahoo! has 180-200 PB of data • 2012: Facebook ingests 500 TB/day
by top 10 data generators of the world, 2007 LOC CIA Amazon Youtube ChoicePt Sprint Google AT & T NERSC Climate Terabytes Saturday, 23 March 13 • 2008: Google processes 20 PB a day • 2009: Facebook has 2.5 PB user data + 15 TB/day • 2009: eBay has 6.5 PB user data + 50 TB/day • 2011: Yahoo! has 180-200 PB of data • 2012: Facebook ingests 500 TB/day
base pairs in a human genome to huge number of sequences of proteins and the analysis of their behaviors The internet: web logs, facebook, twitter, maps, blogs, etc.: Analyze … Financial applications: that analyses volumes of data for trends and other deeper knowledge Health Care: huge amount of patient data, drug and treatment data The universe: The Hubble ultra deep telescope shows 100s of galaxies each with billions of stars;
from about 3.3 billion base pairs in a human genome to huge number of sequences of proteins and the analysis of their behaviors The internet: web logs, facebook, twitter, maps, blogs, etc.: Analyze … Financial applications: that analyses volumes of data for trends and other deeper knowledge Health Care: huge amount of patient data, drug and treatment data The universe: The Hubble ultra deep telescope shows 100s of galaxies each with billions of stars;
March 13 Bioinformatics data: from about 3.3 billion base pairs in a human genome to huge number of sequences of proteins and the analysis of their behaviors The internet: web logs, facebook, twitter, maps, blogs, etc.: Analyze … Financial applications: that analyses volumes of data for trends and other deeper knowledge Health Care: huge amount of patient data, drug and treatment data The universe: The Hubble ultra deep telescope shows 100s of galaxies each with billions of stars;
20~ PB/day) Saturday, 23 March 13 Bioinformatics data: from about 3.3 billion base pairs in a human genome to huge number of sequences of proteins and the analysis of their behaviors The internet: web logs, facebook, twitter, maps, blogs, etc.: Analyze … Financial applications: that analyses volumes of data for trends and other deeper knowledge Health Care: huge amount of patient data, drug and treatment data The universe: The Hubble ultra deep telescope shows 100s of galaxies each with billions of stars;
•Facebook (over 10~ TB/day) •Google (over 20~ PB/day) Saturday, 23 March 13 Bioinformatics data: from about 3.3 billion base pairs in a human genome to huge number of sequences of proteins and the analysis of their behaviors The internet: web logs, facebook, twitter, maps, blogs, etc.: Analyze … Financial applications: that analyses volumes of data for trends and other deeper knowledge Health Care: huge amount of patient data, drug and treatment data The universe: The Hubble ultra deep telescope shows 100s of galaxies each with billions of stars;
do we assign tasks to workers? • What if we have more tasks than slots? • What happens when tasks fail? • How do you handle distributed synchronization?
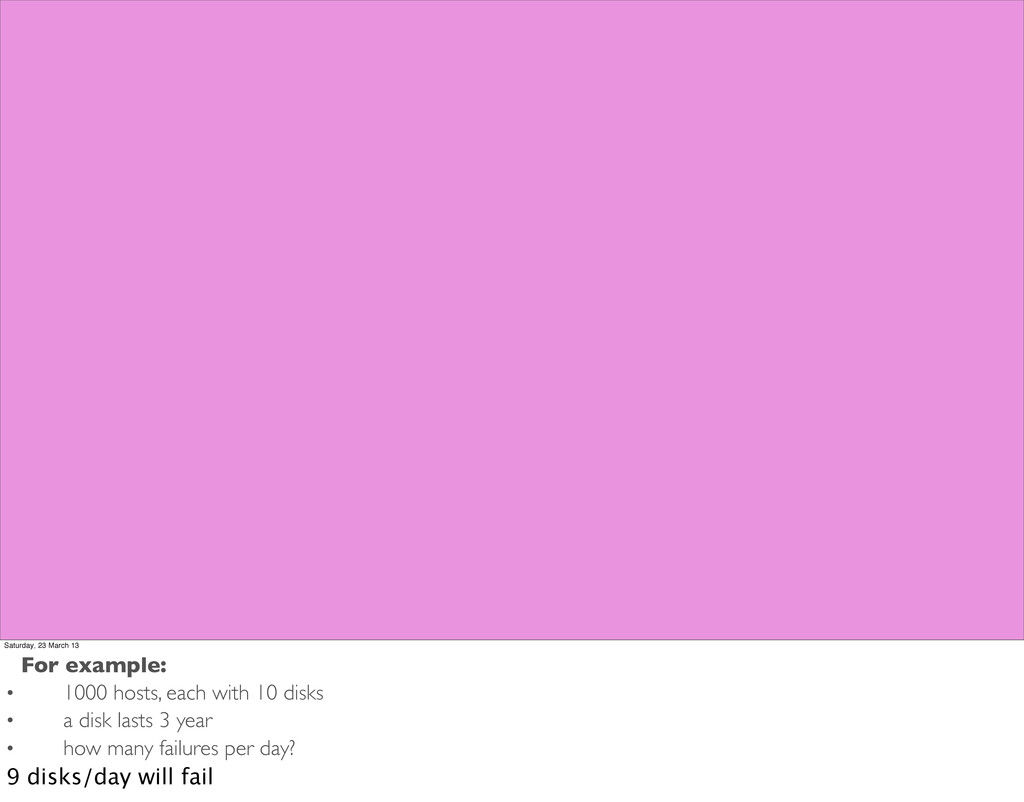
PB’s of data is challenging Saturday, 23 March 13 For example: • 1000 hosts, each with 10 disks • a disk lasts 3 year • how many failures per day? 9 disks/day will fail
PB’s of data is challenging disk/hardware/ network failures Saturday, 23 March 13 For example: • 1000 hosts, each with 10 disks • a disk lasts 3 year • how many failures per day? 9 disks/day will fail
PB’s of data is challenging disk/hardware/ network failures with number of machines, probability of failure also increases Saturday, 23 March 13 For example: • 1000 hosts, each with 10 disks • a disk lasts 3 year • how many failures per day? 9 disks/day will fail
Saturday, 23 March 13 Hadoop was created by Doug Cutting and Michael J. Cafarella. Doug, who was working at Yahoo at the time, named it after his son's toy elephant.It was originally developed to support distribution for the Nutch search engine project. Hadoop consists of the Hadoop Common which provides access to the filesystems supported by Hadoop. The Hadoop Common package contains the necessary JAR files and scripts needed to start Hadoop. The package also provides source code, documentation, and a contribution section which includes projects from the Hadoop Community. For effective scheduling of work, every Hadoop-compatible filesystem should provide location awareness: the name of the rack (more precisely, of the network switch) where a worker node is. Hadoop applications can use this information to run work on the node where the data is, and, failing that, on the same rack/switch, reducing backbone traffic. The Hadoop Distributed File System (HDFS) uses this when replicating data, to try to keep different copies of the data on different racks. The goal is to
Parallel computation framework • Job coordination Rather than banging away at one, huge block of data with a single machine, Hadoop breaks up Big Data into multiple parts so each part can be processed and analyzed in parallel.
Parallel computation framework • Job coordination Rather than banging away at one, huge block of data with a single machine, Hadoop breaks up Big Data into multiple parts so each part can be processed and analyzed in parallel.
fault-tolerant data storage • Parallel computation framework • Job coordination Rather than banging away at one, huge block of data with a single machine, Hadoop breaks up Big Data into multiple parts so each part can be processed and analyzed in parallel.
from Google Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. (2003) The Google File System Jeffrey Dean and Sanjay Ghemawat. (2004) MapReduce: Simplified Data Processing on Large Clusters. OSDI 2004 Saturday, 23 March 13
distributed database modeled after Google's BigTable and is written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data. HBase features compression, in-memory operation, and Bloom filters on a per-column basis as outlined in the original BigTable paper.[2] Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop, and may be accessed through the Java API [3] but also through REST, Avro or Thrift gateway APIs. HBase is not a direct replacement for a classic SQL database, although recently its performance has improved, and it is now serving several data-driven websites,[4][5] including Facebook's Messaging Platform
source, non-relational, distributed database modeled after Google's BigTable and is written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data. HBase features compression, in-memory operation, and Bloom filters on a per-column basis as outlined in the original BigTable paper.[2] Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop, and may be accessed through the Java API [3] but also through REST, Avro or Thrift gateway APIs. HBase is not a direct replacement for a classic SQL database, although recently its performance has improved, and it is now serving several data-driven websites,[4][5] including Facebook's Messaging Platform
(Hadoop Distributed File System) Cascading (Java) HBase (Columnar Database) hadoop stack Saturday, 23 March 13 HBase is an open source, non-relational, distributed database modeled after Google's BigTable and is written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data. HBase features compression, in-memory operation, and Bloom filters on a per-column basis as outlined in the original BigTable paper.[2] Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop, and may be accessed through the Java API [3] but also through REST, Avro or Thrift gateway APIs. HBase is not a direct replacement for a classic SQL database, although recently its performance has improved, and it is now serving several data-driven websites,[4][5] including Facebook's Messaging Platform
portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
to reliably store data using commodity hardware Saturday, 23 March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
to reliably store data using commodity hardware • Designed to expect hardware failures Saturday, 23 March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
to reliably store data using commodity hardware • Designed to expect hardware failures • Intended for large files Saturday, 23 March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
to reliably store data using commodity hardware • Designed to expect hardware failures • Intended for large files • Designed for batch inserts Saturday, 23 March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
to reliably store data using commodity hardware • Designed to expect hardware failures • Intended for large files • Designed for batch inserts • The Hadoop Distributed File System Saturday, 23 March 13 HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework. Each node in a Hadoop instance typically has a single namenode; a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The filesystem uses the TCP/IP layer for communication; clients use RPC to communicate between each other. HDFS stores large files (an ideal file size is a multiple of 64 MB[11]), across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence does not require RAID storage on hosts. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX compliant because the requirements for a POSIX filesystem differ from the target goals for a Hadoop application. The tradeoff of not having a fully POSIX compliant filesystem is increased performance for data throughput. HDFS was designed to handle very large files.
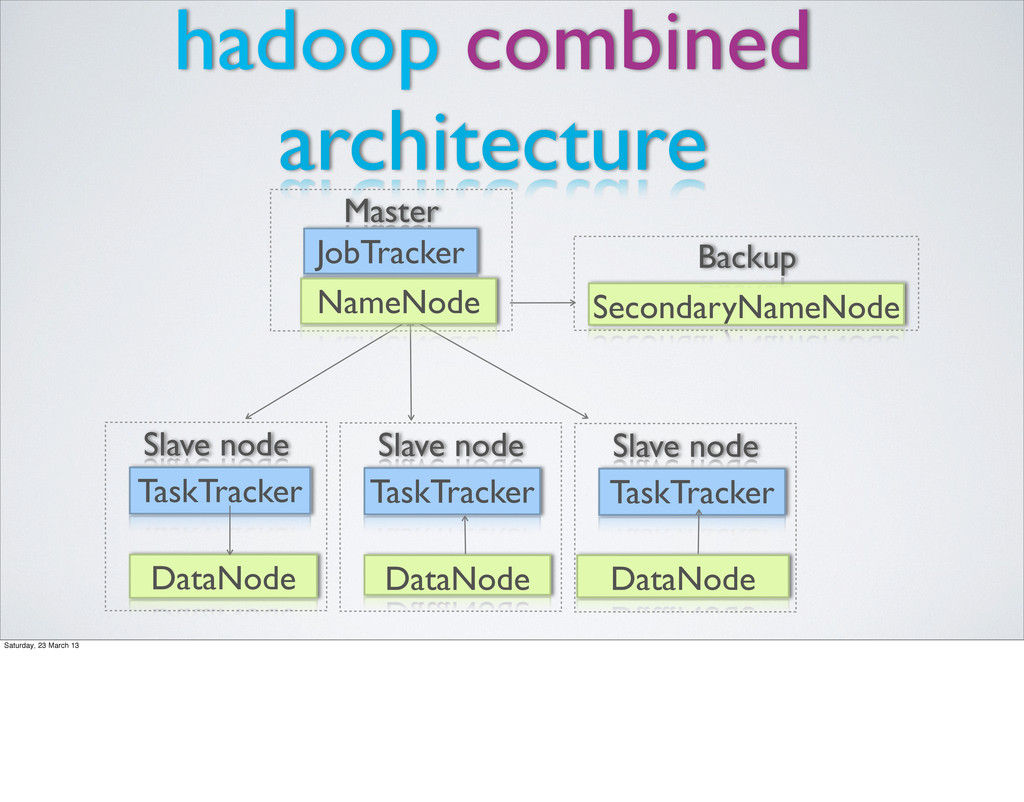
collection of blocks • Blocks are 64 MB chunks of a file (configurable) • Blocks are replicated on 3 nodes (configurable) • The NameNode (NN) manages metadata about files and blocks • The SecondaryNameNode (SNN) holds a backup of the NN data • DataNodes (DN) store and serve blocks
stored as a collection of blocks • Blocks are 64 MB chunks of a file (configurable) • Blocks are replicated on 3 nodes (configurable) • The NameNode (NN) manages metadata about files and blocks • The SecondaryNameNode (SNN) holds a backup of the NN data • DataNodes (DN) store and serve blocks
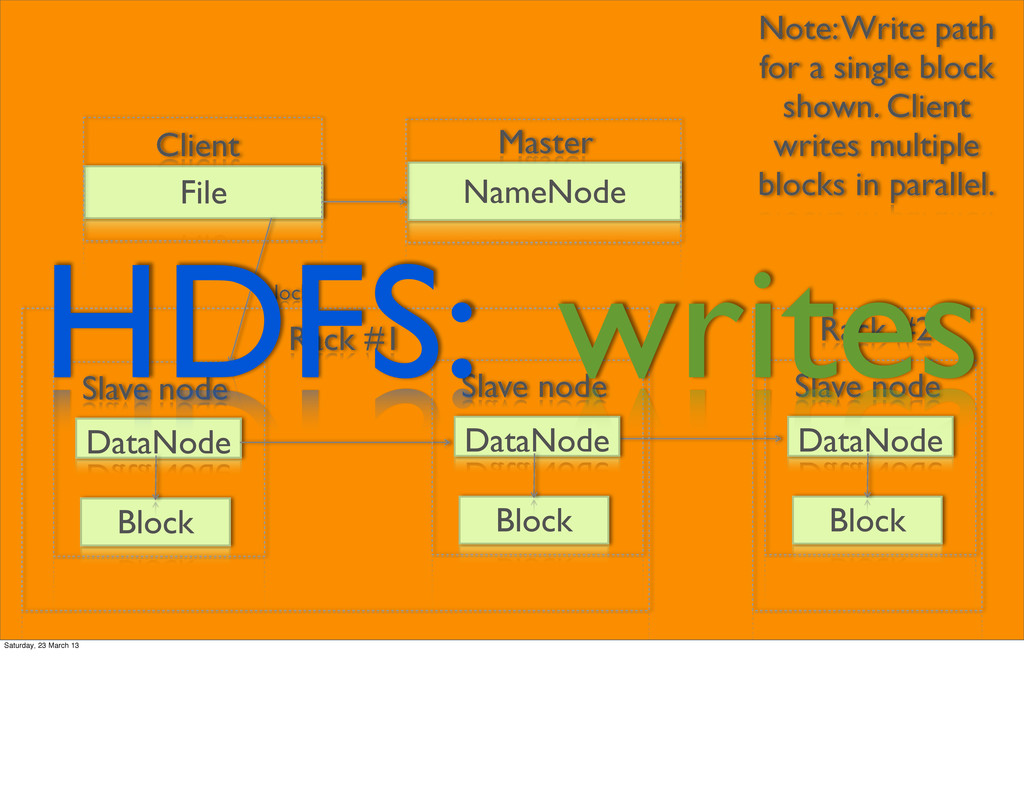
• Copy #1 on another node on same rack • Copy #2 on another node on different rack Saturday, 23 March 13 Designed for system-to-system interaction, and not for user-to-system interaction. The chunk servers replicate the data automatically.
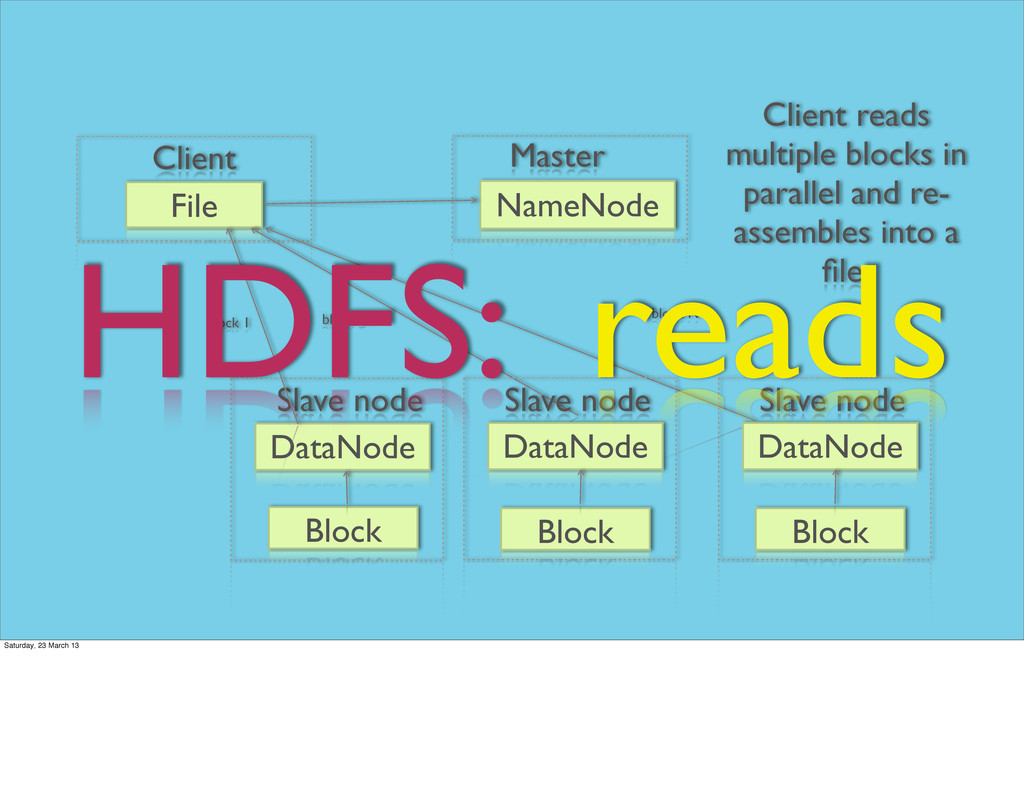
multiple blocks in parallel and re- assembles into a file. block 1 block 2 block N DataNode Block Slave node DataNode Block Slave node HDFS: reads Saturday, 23 March 13
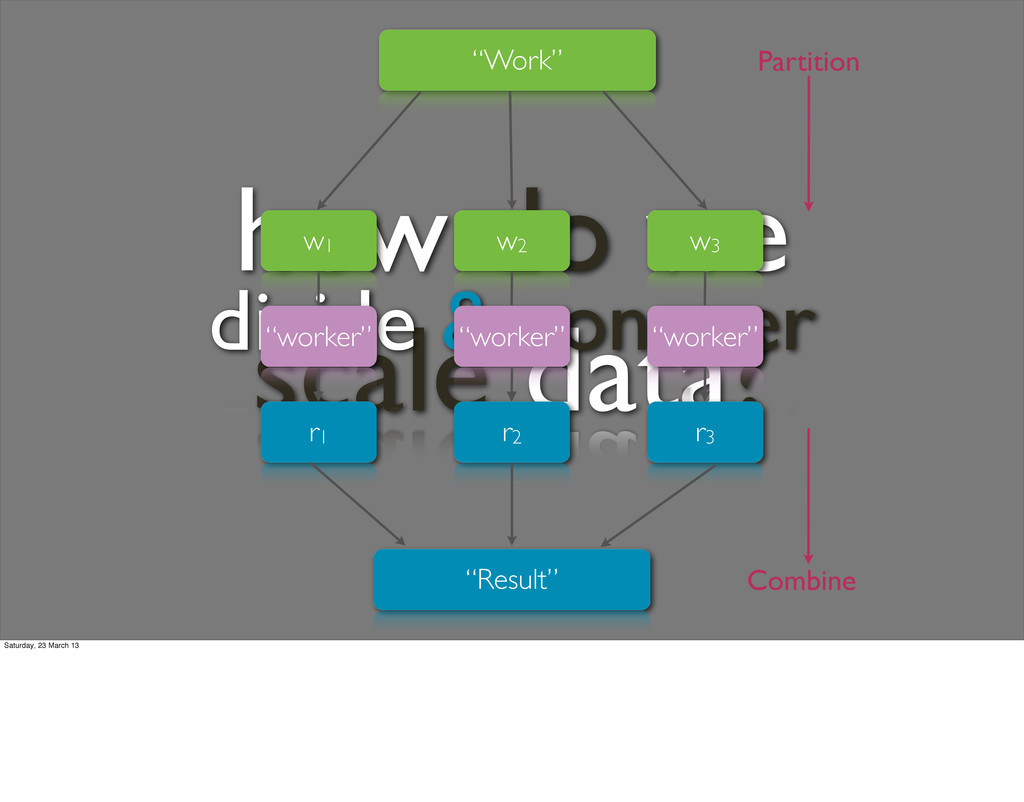
into smaller sub-problems, and distributes them to worker nodes. A worker node may do this again in turn, leading to a multi- level tree structure. The worker node processes the smaller problem, and passes the answer back to its master node. "Reduce" step: The master node then collects the answers to all the sub-problems and combines them in some way to form the output – the answer to the problem it was originally trying to solve. Saturday, 23 March 13 MapReduce is a programming model for processing large data sets, and the name of an implementation of the model by Google. MapReduce is typically used to do distributed computing on clusters of computers.[1] The model is inspired by the map and reduce functions commonly used in functional programming,[2] although their purpose in the MapReduce framework is not the same as their original forms.[3] MapReduce libraries have been written in many programming languages. A popular free implementation is Apache Hadoop.
it into smaller sub-problems, and distributes them to worker nodes. A worker node may do this again in turn, leading to a multi- level tree structure. The worker node processes the smaller problem, and passes the answer back to its master node. "Reduce" step: The master node then collects the answers to all the sub-problems and combines them in some way to form the output – the answer to the problem it was originally trying to solve. Saturday, 23 March 13 MapReduce is a programming model for processing large data sets, and the name of an implementation of the model by Google. MapReduce is typically used to do distributed computing on clusters of computers.[1] The model is inspired by the map and reduce functions commonly used in functional programming,[2] although their purpose in the MapReduce framework is not the same as their original forms.[3] MapReduce libraries have been written in many programming languages. A popular free implementation is Apache Hadoop.
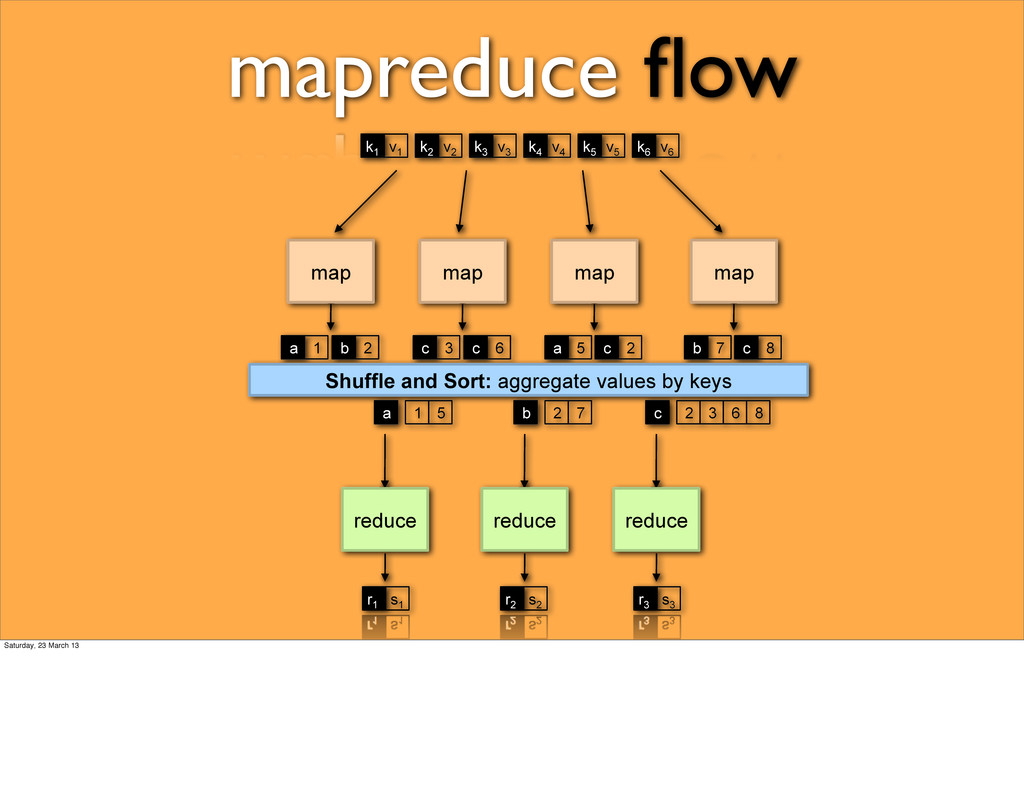
a large number of records • Extract something of interest from each • Shuffle and sort intermediate results • Aggregate intermediate results • Generate final output typical large data problem Saturday, 23 March 13
keys reduce reduce reduce k 1 k 2 k 3 k 4 k 5 k 6 v 1 v 2 v 3 v 4 v 5 v 6 b a 1 2 c c 3 6 a c 5 2 b c 7 8 a 1 5 b 2 7 c 2 3 6 8 r 1 s 1 r 2 s 2 r 3 s 3 mapreduce flow Saturday, 23 March 13
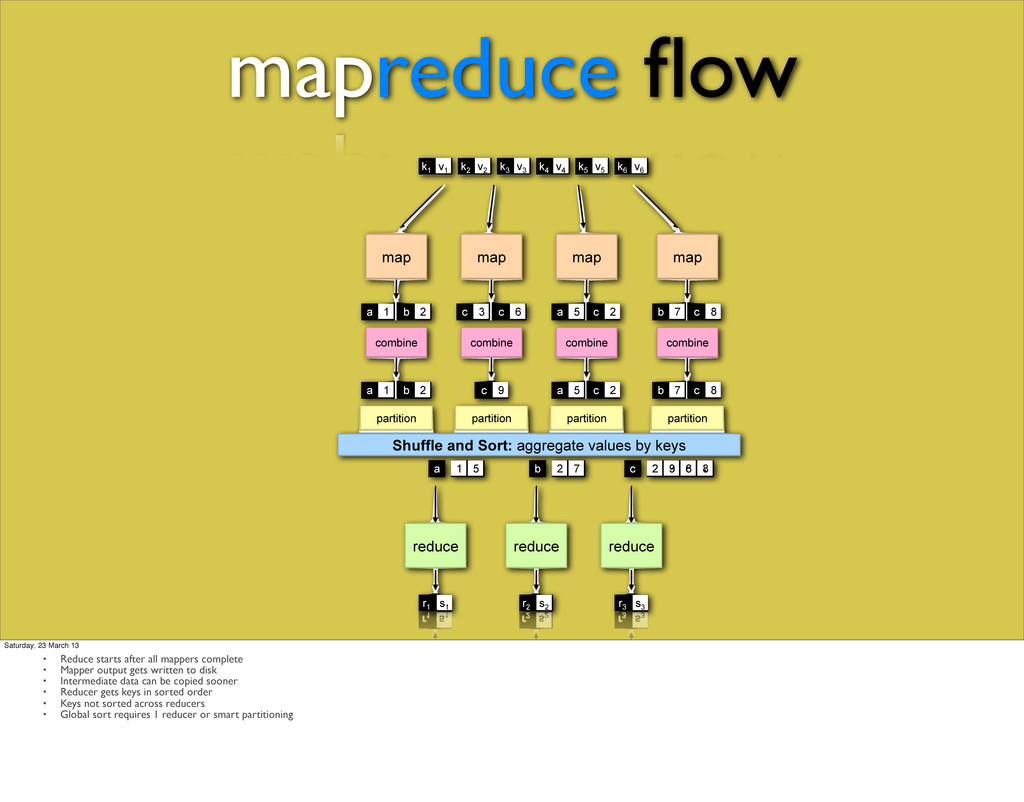
key goes to what reducer partition(k’, numPartitions) -> partNumber Divides key space into parallel reducers chunks Default is hash-based • Combiners can combine Mapper output before sending to reducer Reduce(k2, list(v2)) -> list(v3) Saturday, 23 March 13
complete • Mapper output gets written to disk • Intermediate data can be copied sooner • Reducer gets keys in sorted order • Keys not sorted across reducers • Global sort requires 1 reducer or smart partitioning
all mappers complete • Mapper output gets written to disk • Intermediate data can be copied sooner • Reducer gets keys in sorted order • Keys not sorted across reducers • Global sort requires 1 reducer or smart partitioning
a c 5 2 b c 7 8 partition partition partition partition map map map map k1 k2 k3 k4 k5 k6 v1 v2 v3 v4 v5 v6 b a 1 2 c c 3 6 a c 5 2 b c 7 8 Shuffle and Sort: aggregate values by keys reduce reduce reduce a 1 5 b 2 7 c 2 9 8 r1 s1 r2 s2 r3 s3 c 2 3 6 8 mapreduce flow Saturday, 23 March 13 • Reduce starts after all mappers complete • Mapper output gets written to disk • Intermediate data can be copied sooner • Reducer gets keys in sorted order • Keys not sorted across reducers • Global sort requires 1 reducer or smart partitioning
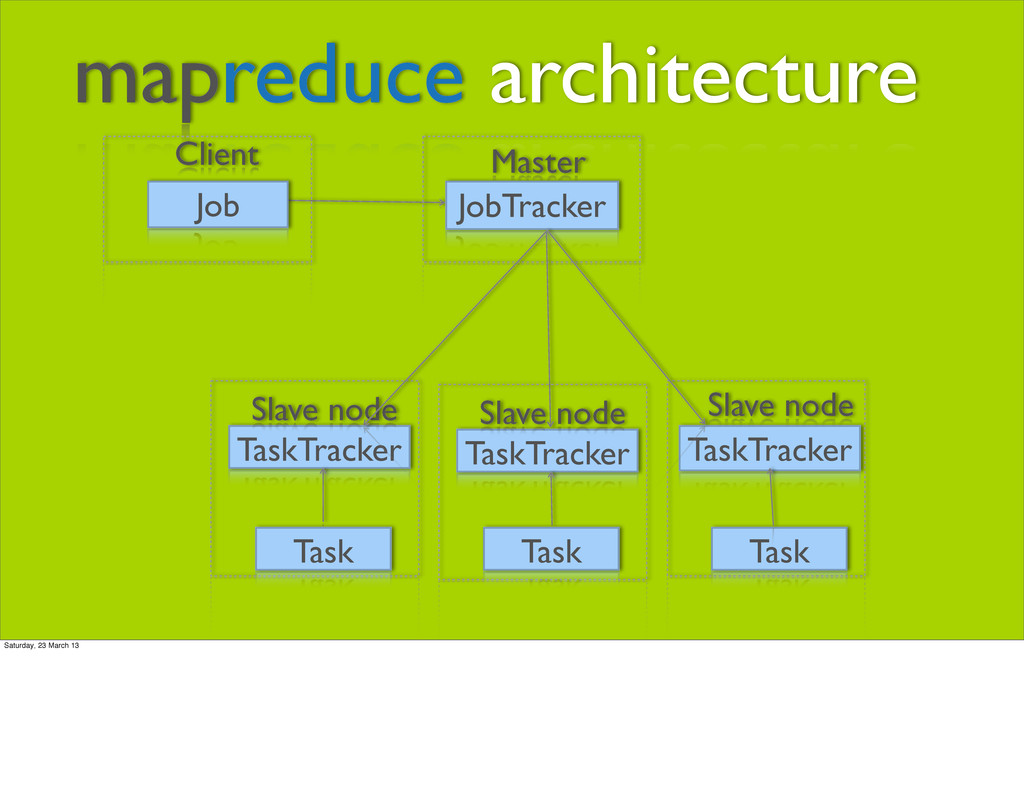
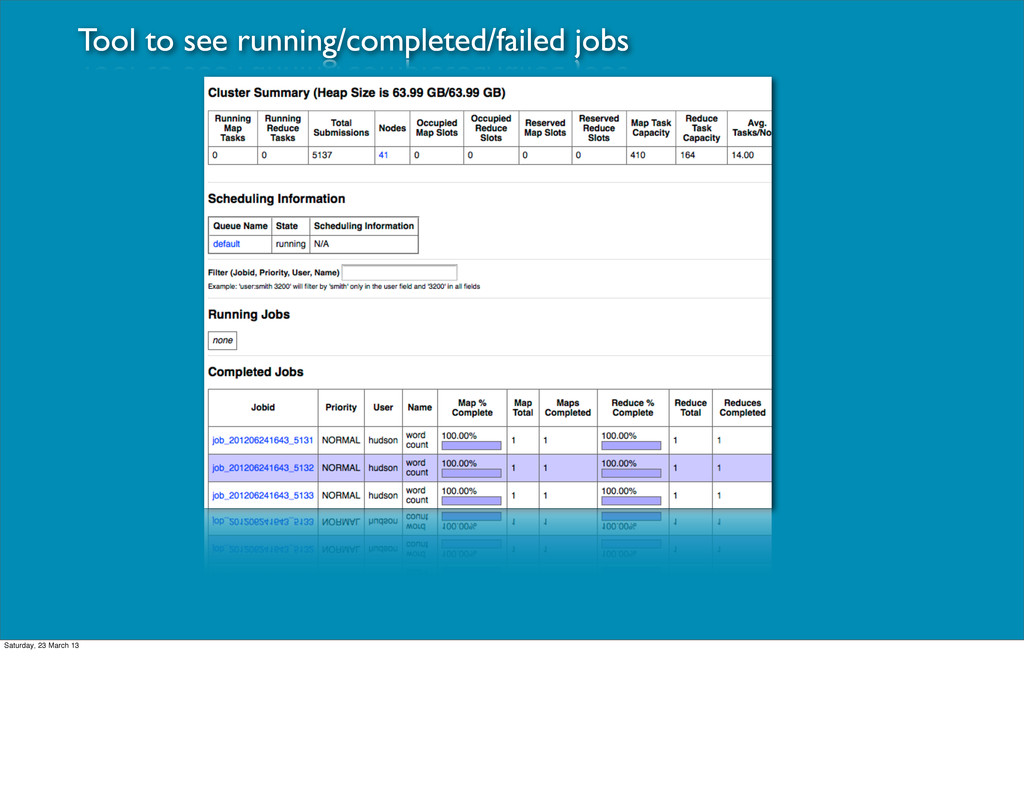
to a data set • Task: a single mapper or reducer task • Failed tasks get retried automatically • Tasks run local to their data, ideally Saturday, 23 March 13
to a data set • Task: a single mapper or reducer task • Failed tasks get retried automatically • Tasks run local to their data, ideally • JobTracker (JT) manages job submission and task delegation Saturday, 23 March 13
to a data set • Task: a single mapper or reducer task • Failed tasks get retried automatically • Tasks run local to their data, ideally • JobTracker (JT) manages job submission and task delegation • TaskTrackers (TT) ask for work and execute tasks Saturday, 23 March 13
failed tasks up to N attempts After N failed attempts for a task, job fails Some tasks are slower than other Speculative execution is JT starting up multiple of the same task First one to complete wins, other is killed
JT will retry failed tasks up to N attempts After N failed attempts for a task, job fails Some tasks are slower than other Speculative execution is JT starting up multiple of the same task First one to complete wins, other is killed
to the data • Moving data between nodes has a cost • MapReduce tries to schedule tasks on nodes with the data • When not possible TT has to fetch data from DN
state/coordination • Tasks are shared-nothing • Shared-state requires scalable state store • Low-latency jobs • Jobs on small datasets • Finding individual records Saturday, 23 March 13
pre-loaded • Great tool for learning Hadoop • Eases the pain of downloading/installing • Pre-loaded with sample data and jobs • Documented tutorials • VM: https://ccp.cloudera.com/display/SUPPORT/Cloudera's+Hadoop+Demo+VM+for+CDH4 • Tutorial: https://ccp.cloudera.com/display/SUPPORT/Hadoop+Tutorial Saturday, 23 March 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}