to the entry in the vocabulary and don't depend on the token's context. doc = nlp( ) ( , [token.i token doc]) ( , [token.text token doc]) ( , [token.is_alpha token doc]) ( , [token.is_punct token doc]) ( , [token.like_num token doc]) "It costs $5." "Index: " "Text: " "is_alpha:" "is_punct:" "like_num:" print print print print print for in for in for in for in for in Lexical Attributes Index: [0, 1, 2, 3, 4]
Text: ['It', 'costs', '$', '5', '.']
is_alpha: [True, True, False, False, False]
is_punct: [False, False, False, False, True]
like_num: [False, False, False, True, False] Output
{kind=link}
{kind=link}
{kind=link}
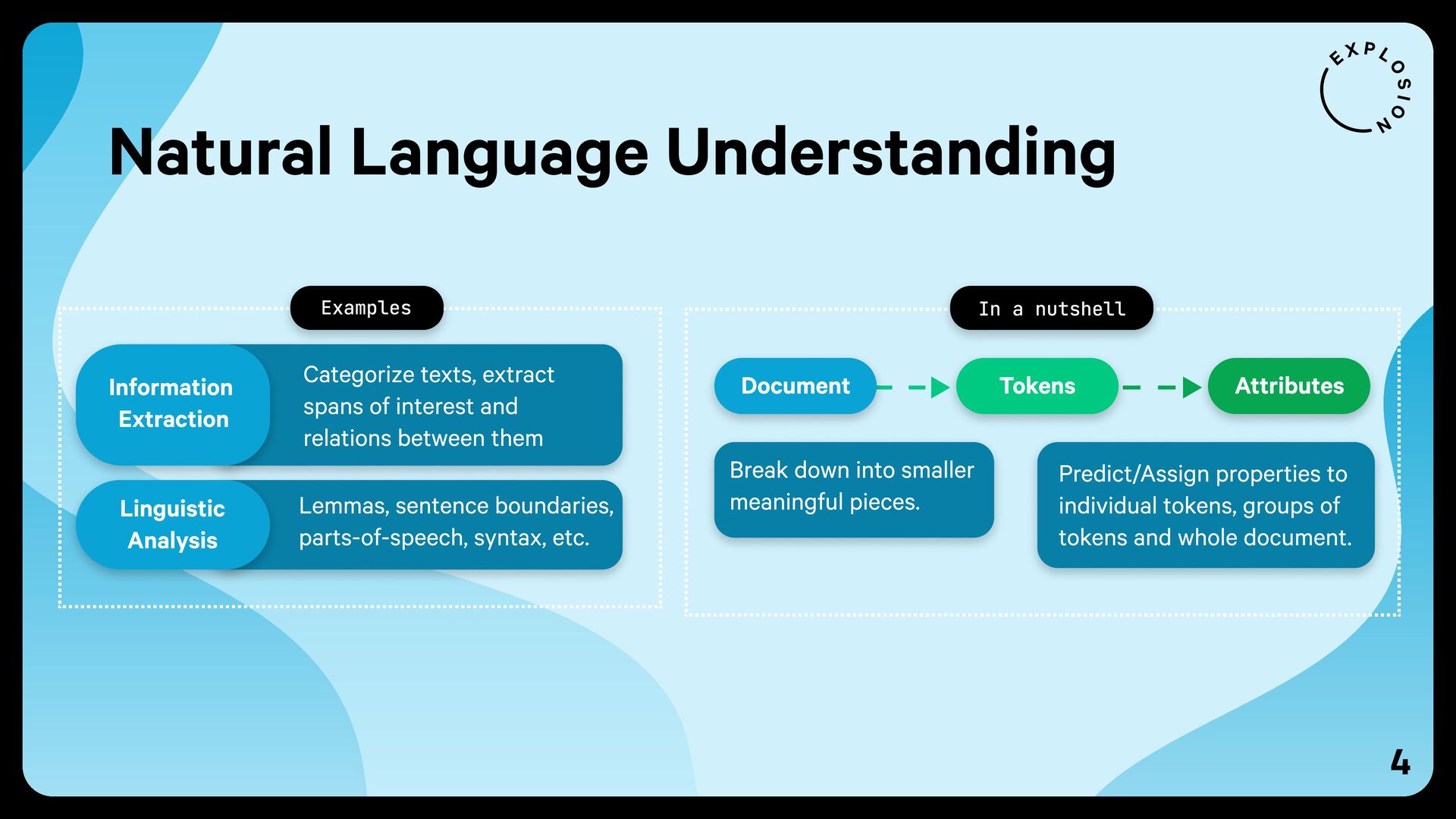{kind=link}
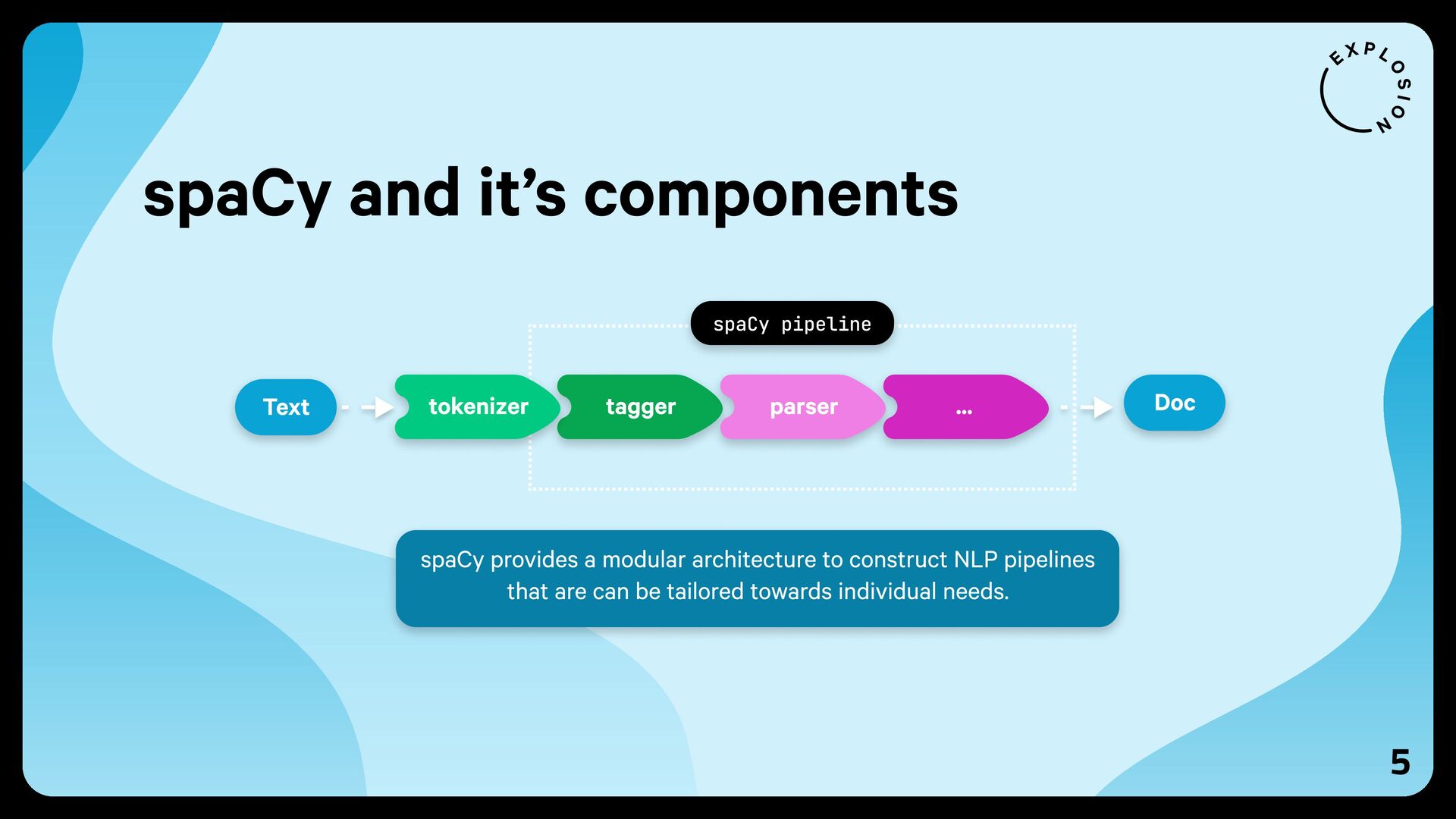{kind=link}
{kind=link}
{kind=link}
{kind=link}
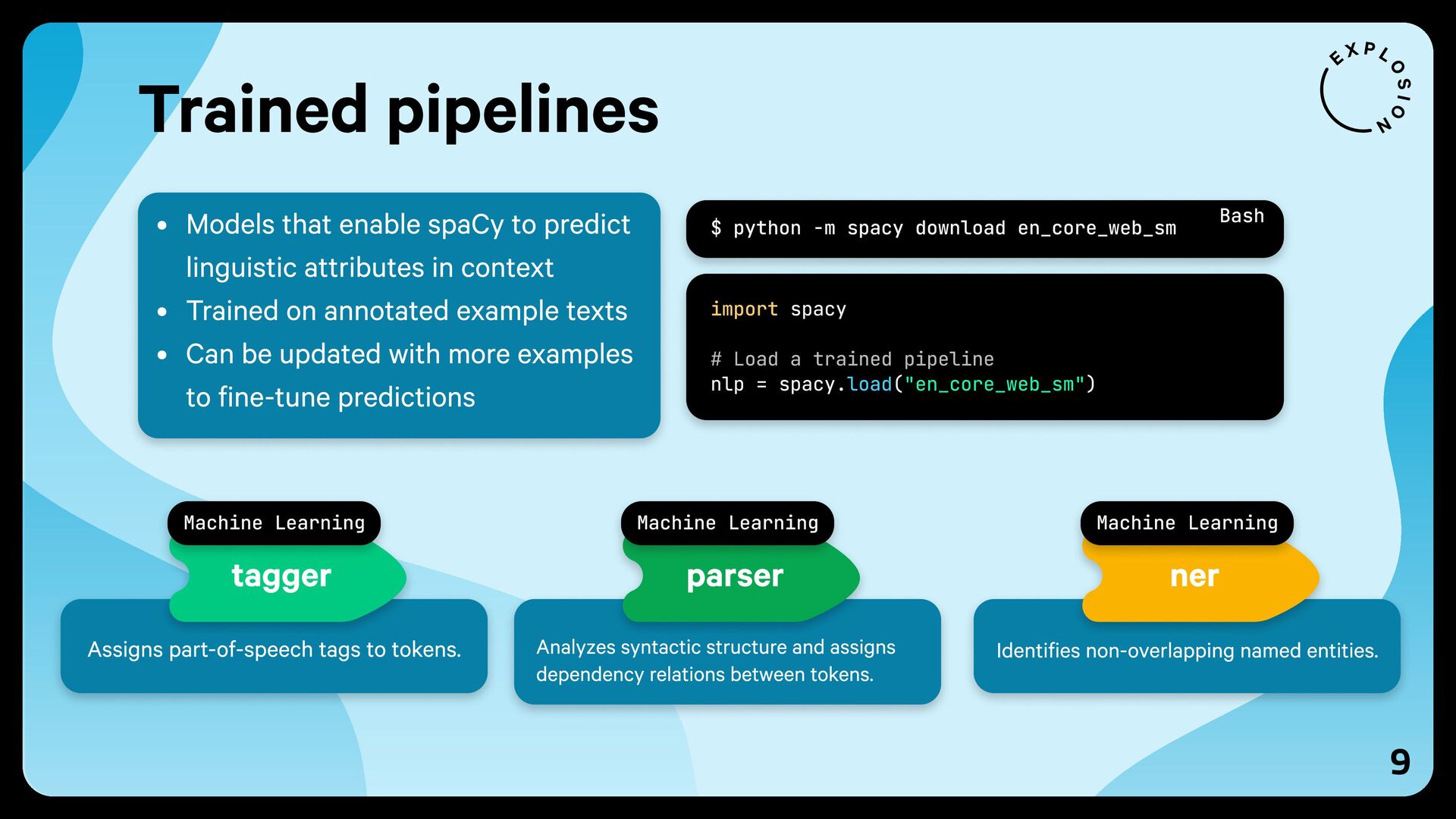{kind=link}
{kind=link}
{kind=link}
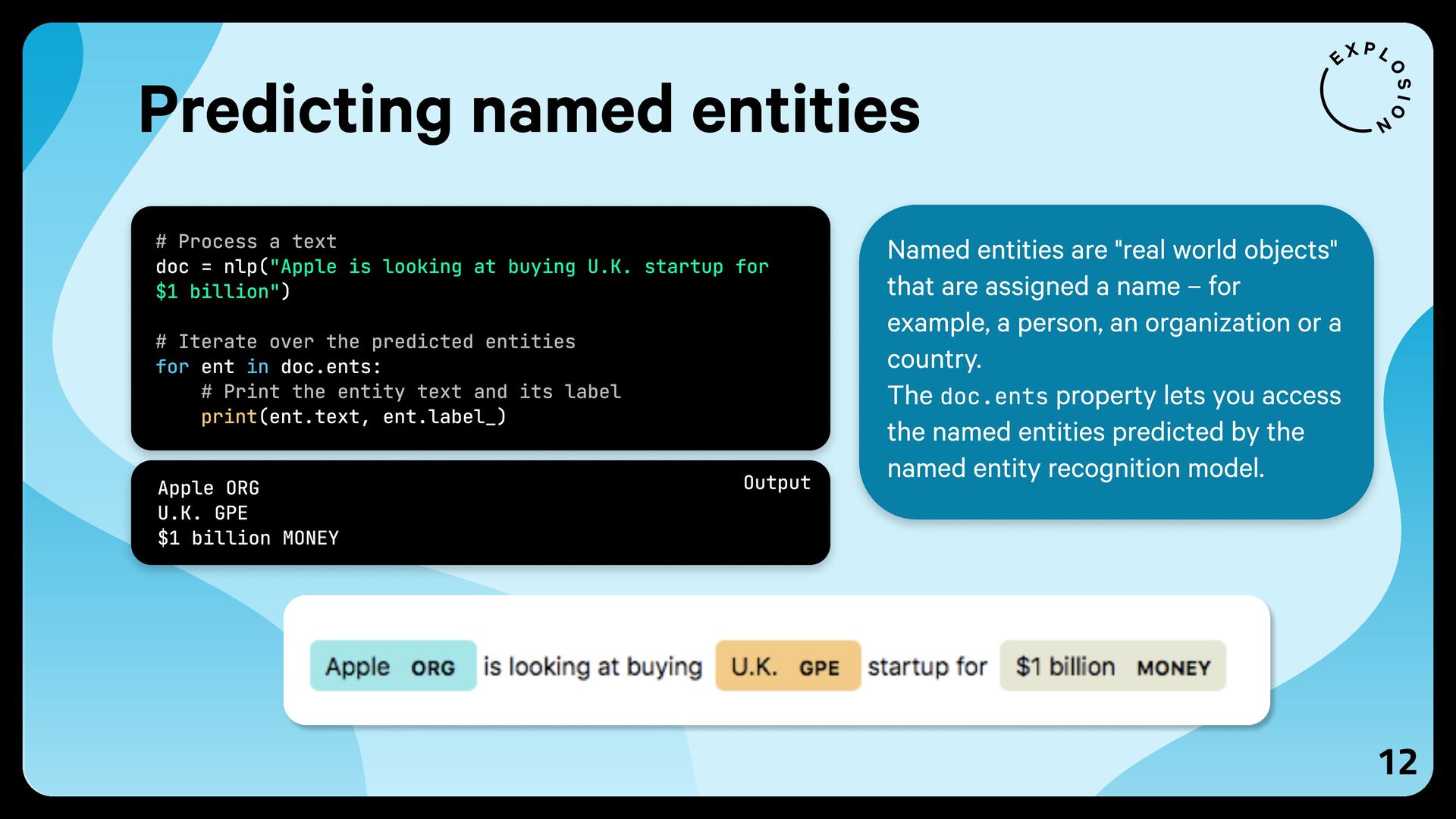{kind=link}
{kind=link}
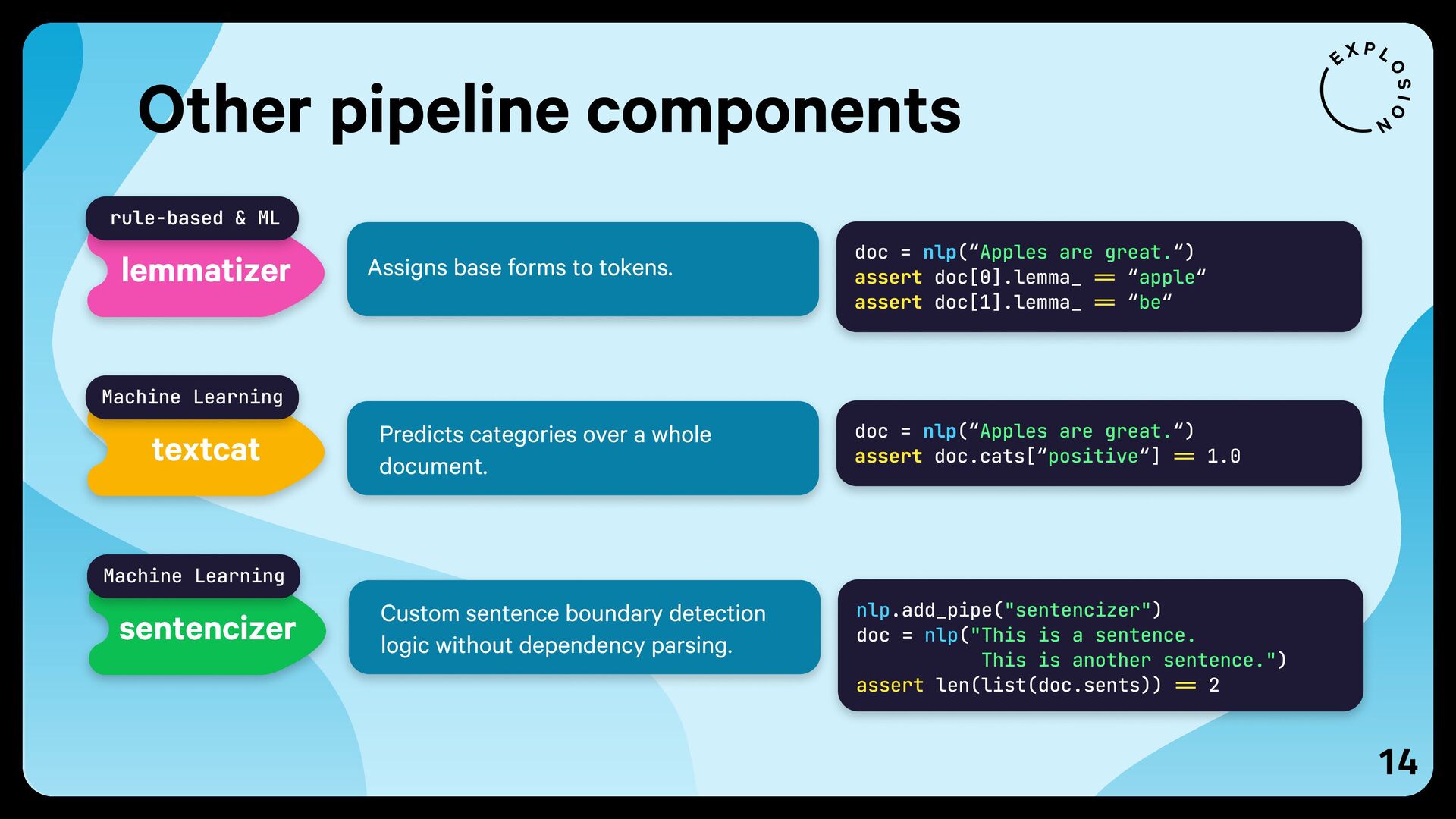{kind=link}
{kind=link}
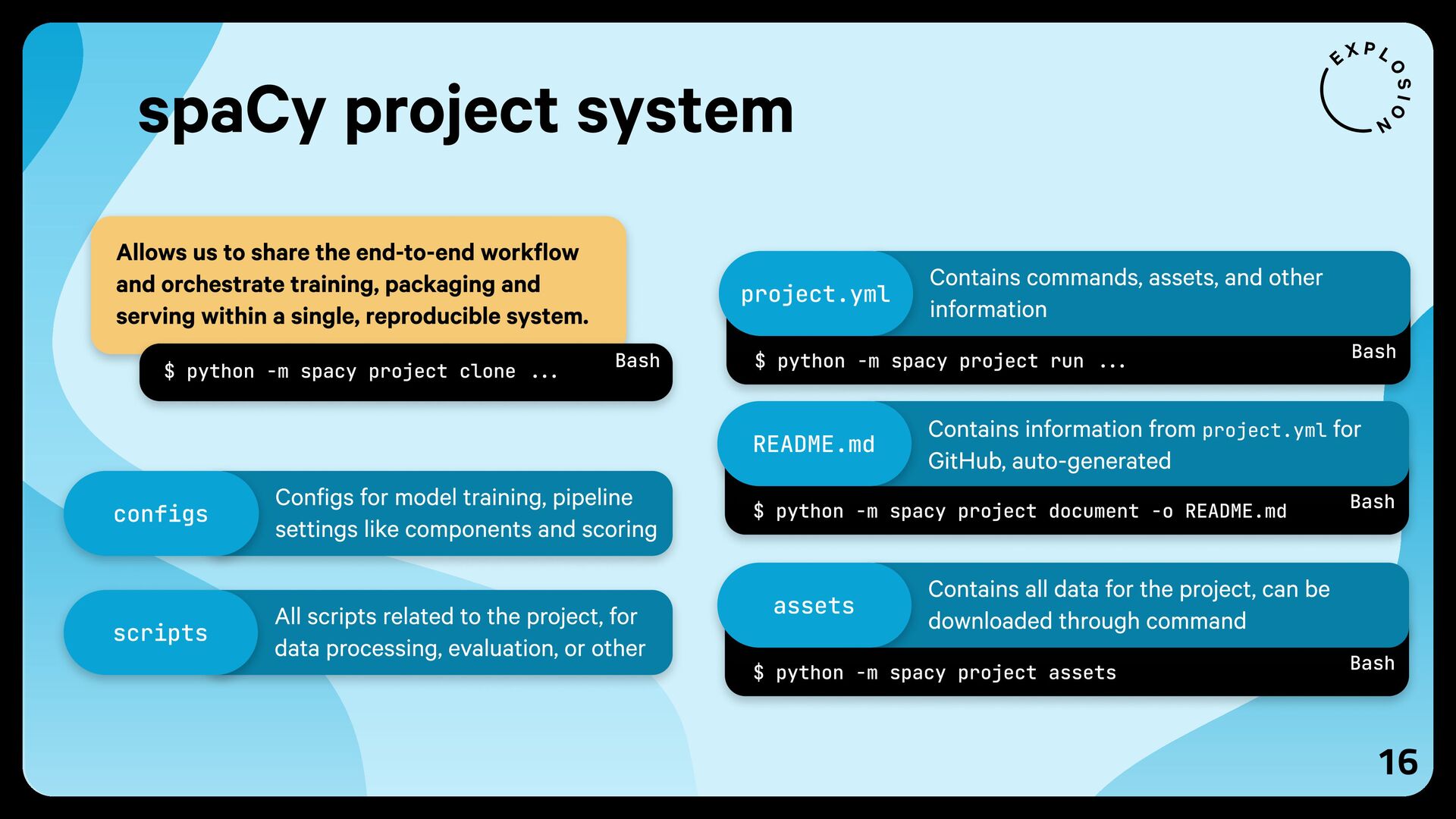{kind=link}
{kind=link}
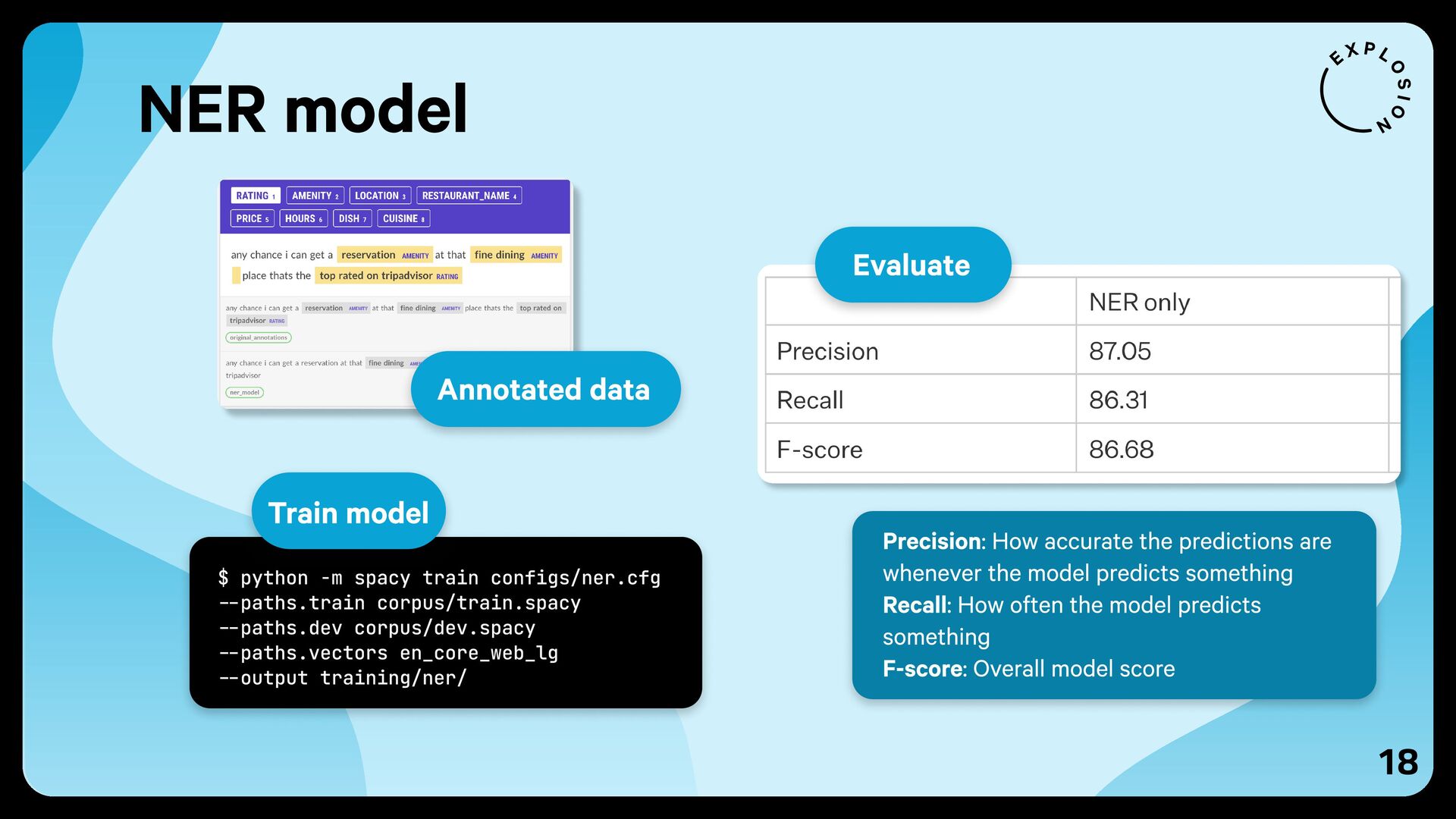{kind=link}
{kind=link}
{kind=link}
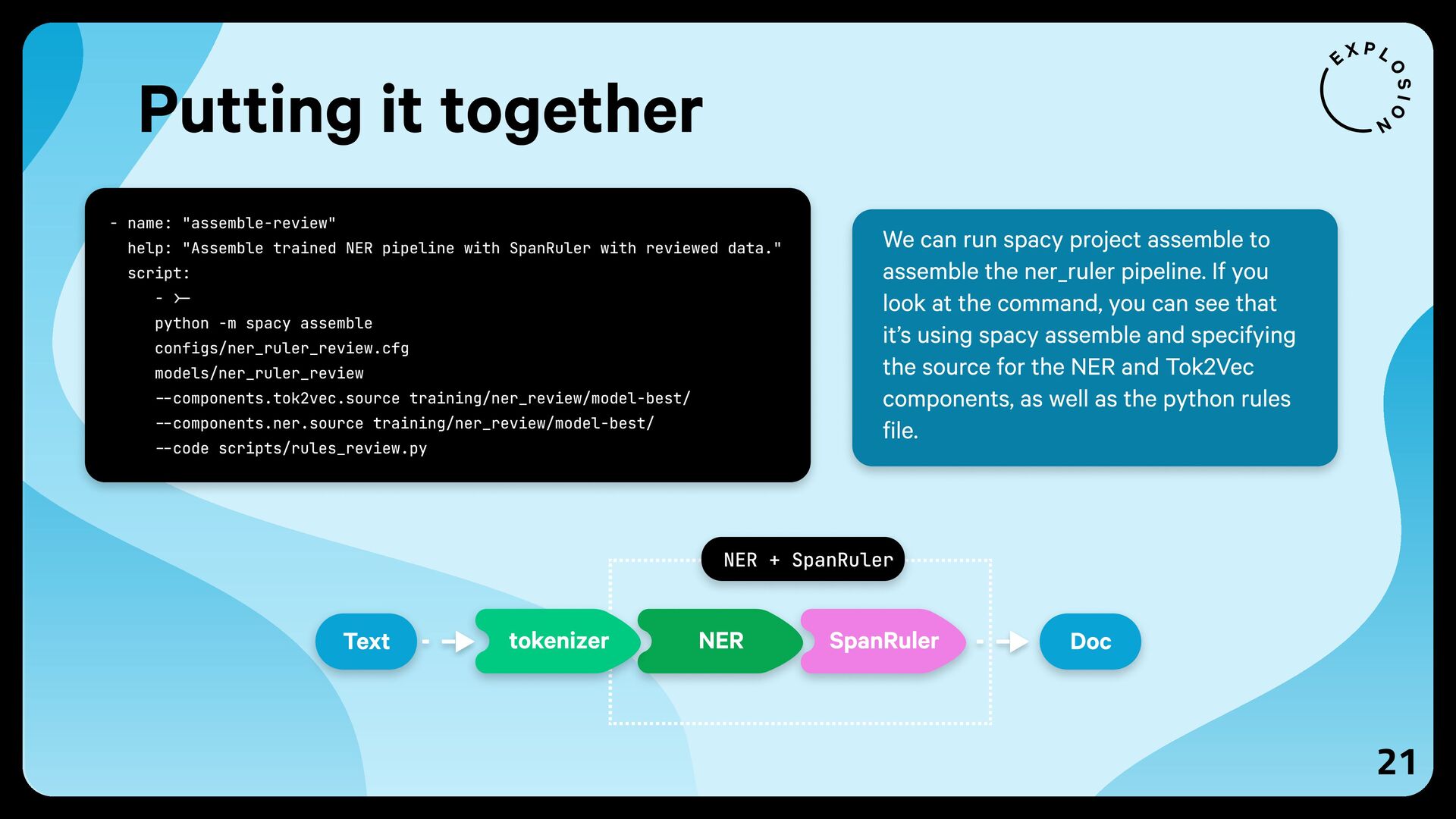{kind=link}
{kind=link}
{kind=link}