Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NLTK Intro for PUGS
Search
Victor Neo
March 27, 2012
Programming
600
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NLTK Intro for PUGS
Slides for the NLTK talk given on March 2012 for Python User Group SG Meetup.
Victor Neo
March 27, 2012
More Decks by Victor Neo
See All by Victor Neo
Django - The Next Steps
victorneo
5
700
DevOps: Python tools to get started
victorneo
9
13k
Git and Python workshop
victorneo
2
820
Other Decks in Programming
See All in Programming
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.7k
AIエージェントで 変わるAndroid開発環境
takahirom
2
680
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.5k
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
act2-costs.pdf
sumedhbala
0
110
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
210
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
460
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
240
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
240
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
360
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
200
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
980
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
290
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
How to make the Groovebox
asonas
2
2.3k
How GitHub (no longer) Works
holman
316
150k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Transcript
Natural Language Toolkit @victorneo
Natural Language Processing
"the process of a computer extracting meaningful information from natural
language input and/or producing natural language output"
None
Getting started with NLTK
Open source Python modules, linguistic data and documentation for research
and development in natural language processing and text analytics, with distributions for Windows, Mac OSX and Linux. NLTK
None
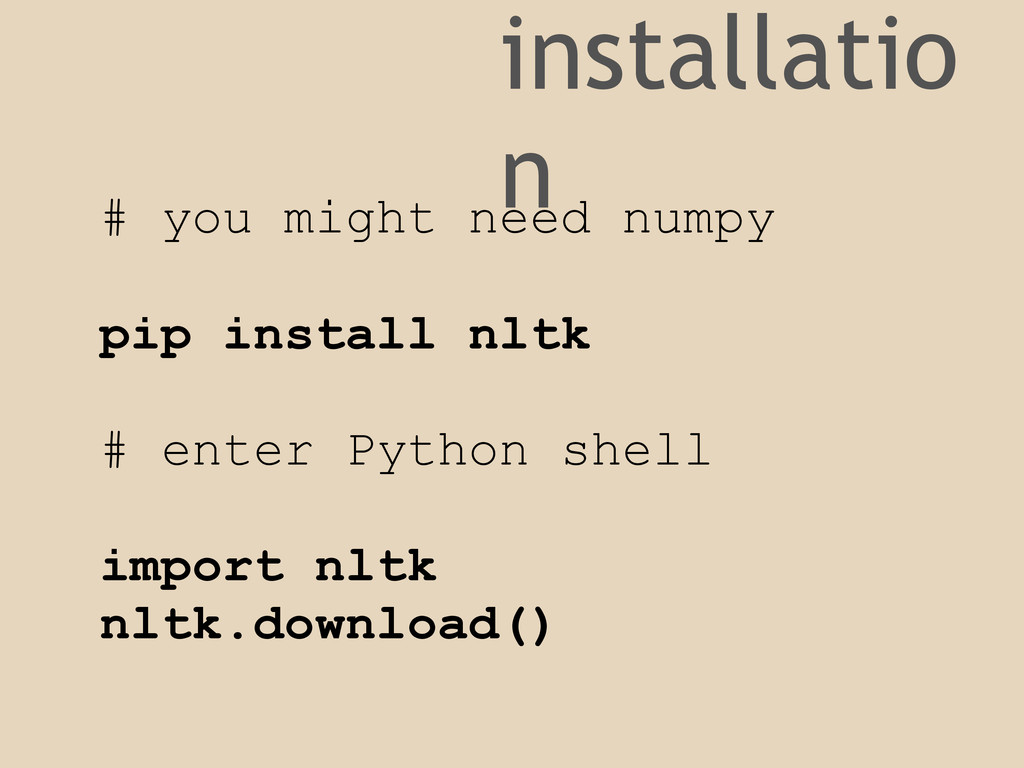
installatio n # you might need numpy pip install nltk
# enter Python shell import nltk nltk.download()
None
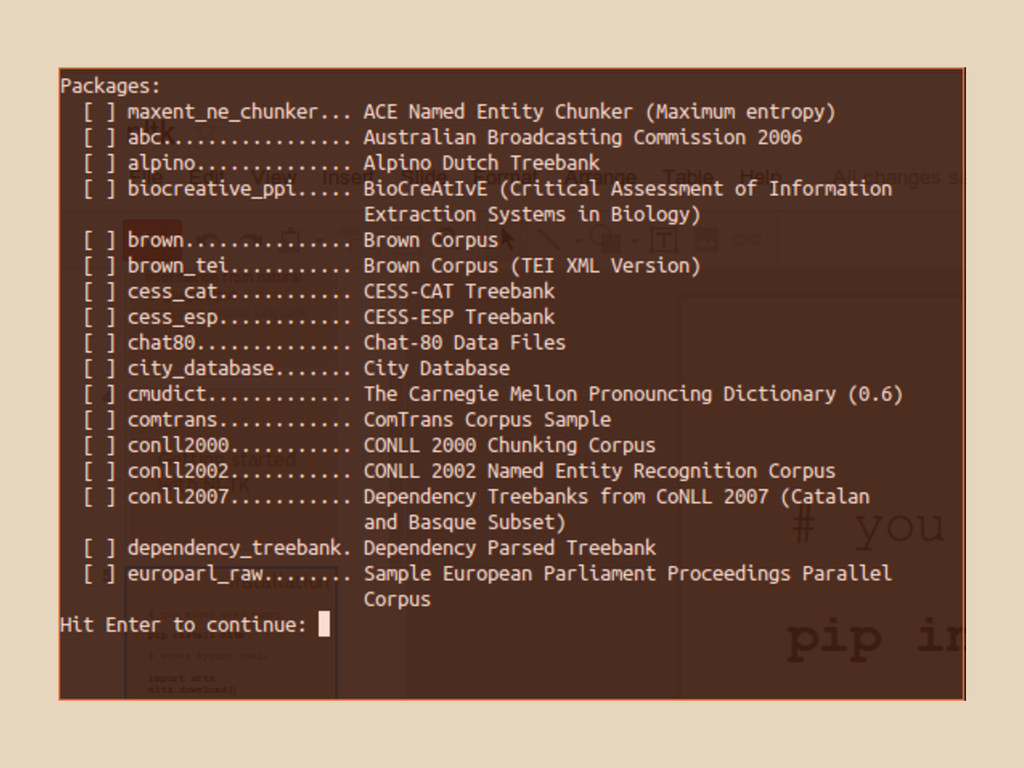
packages # For Part of Speech tagging maxent_treebank_pos_tagger # Get
a list of stopwords stopwords # Brown corpus to play around brown
Preparing data / corpus
tokens NLTK works on Tokens, for example, "Hello World!" will
be tokenized to: ['Hello', 'World', '!'] The built-in tokenizer for most use cases: nltk.word_tokenize("Hello World!")
text processing HTML text: raw = nltk.clean_html(html_text) tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens) Use BeautifulSoup for preprocessing of the HTML text to discard unnecessary data.
Part-of-speech tagging
pos tagging text = "Run away!" nltk.word_tokenize(text) nltk.pos_tag(tokens) [('Run', 'NNP'),
('away', 'RB'), ('!', '.')]
pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper
Noun, Singular RB : Adverb http://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos. html
pos tagging "The sailor dogs the barmaid." [('The', 'DT'), ('sailor',
'NN'), ('dogs', 'NNS'), ('the', 'DT'), ('barmaid', 'NN'), ('.', '.')]
Sentiment Analysis Code: http://bit.ly/GLu2Q9
Differentiate between "happy" and "sad" tweets. Teach the classifier the
"features" of happy & sad tweets and test how good it is.
Happy: "Looking through old pics and realizing everything happens for
a reason. So happy with where I am right now" Sad: "So sad I have 8 AM class tomorrow"
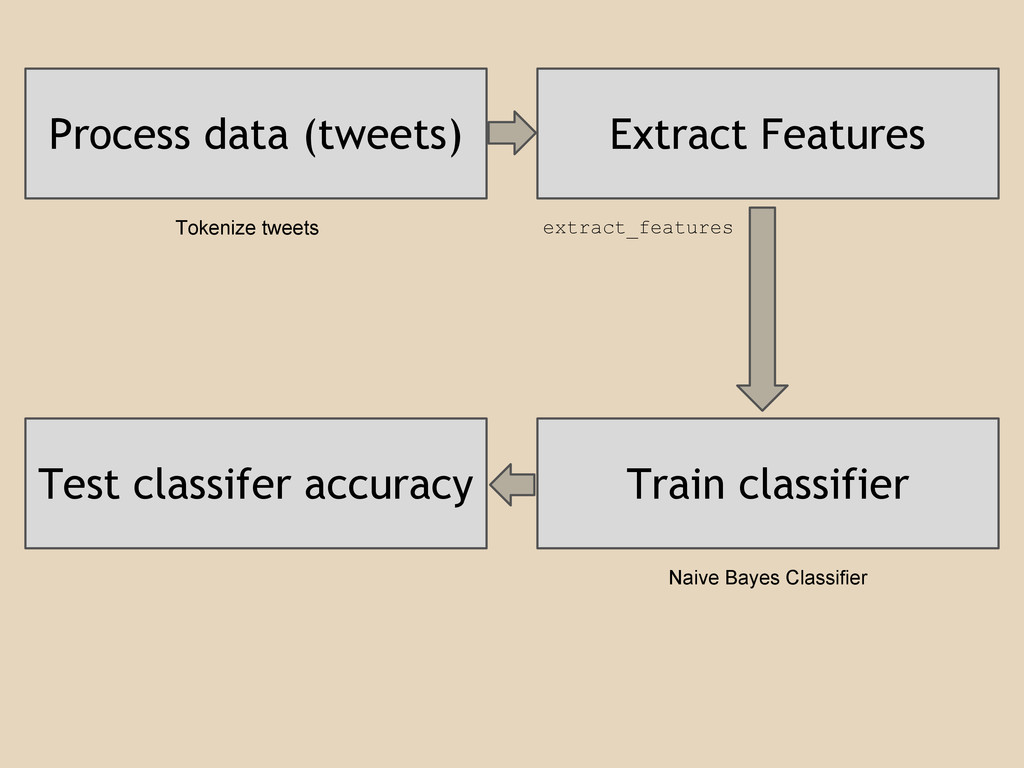
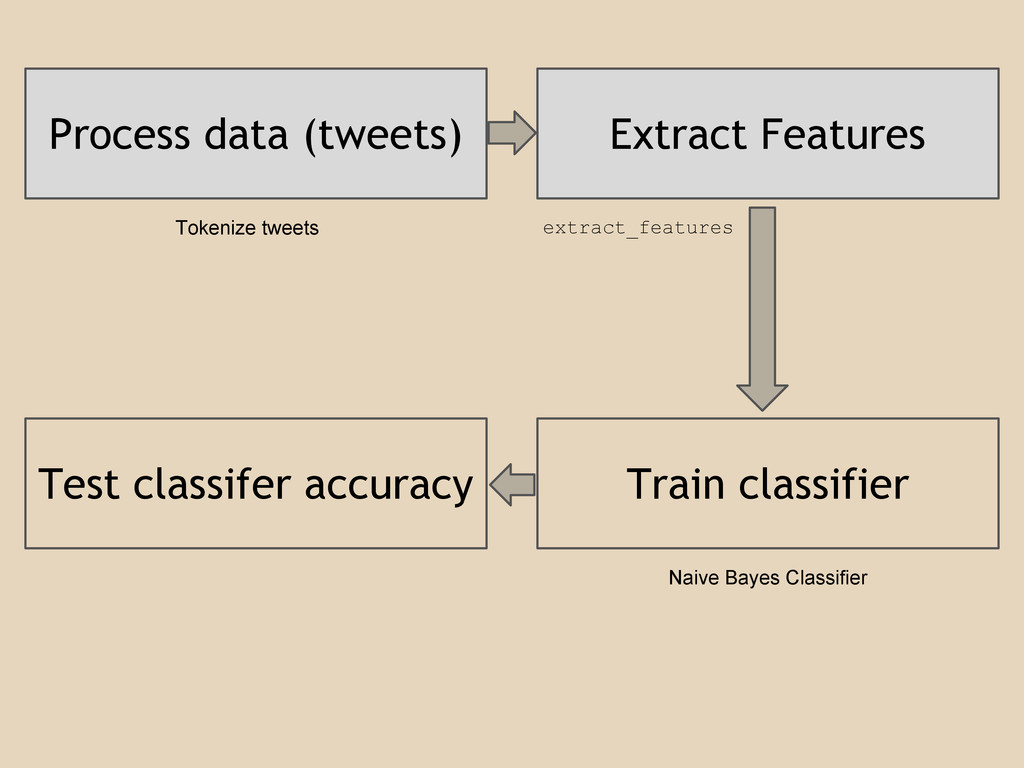
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
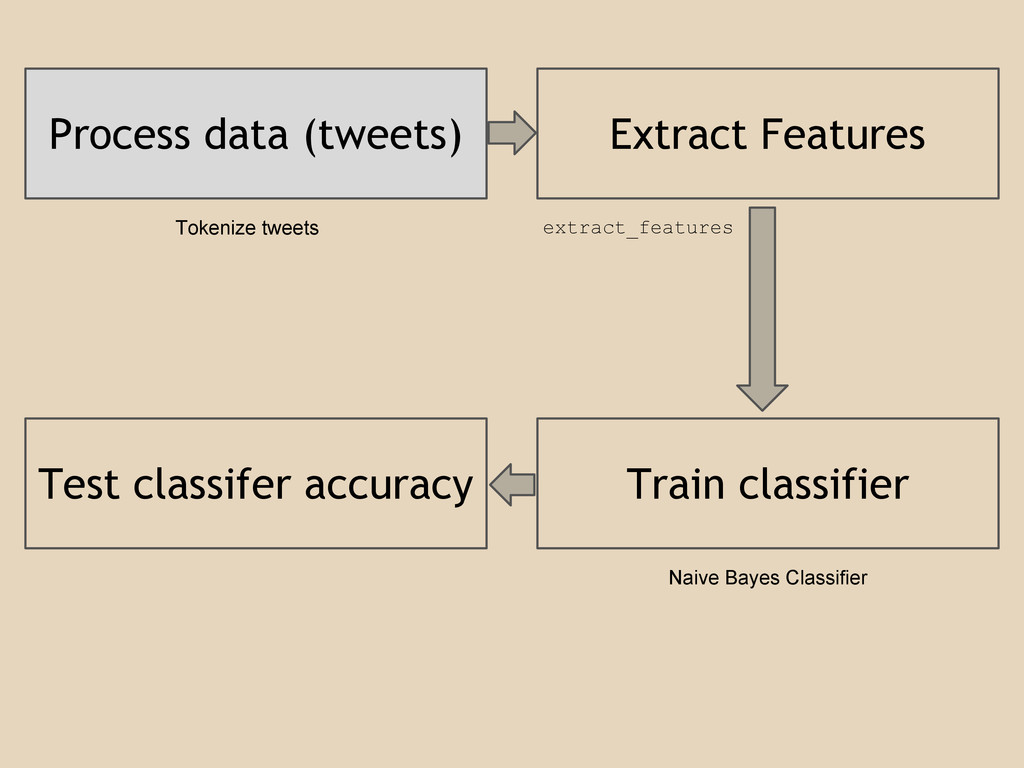
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
happy.txt sad.txt happy_test.txt sad_test.txt } training data } testing data
Tweets obtained from Twitter Search API
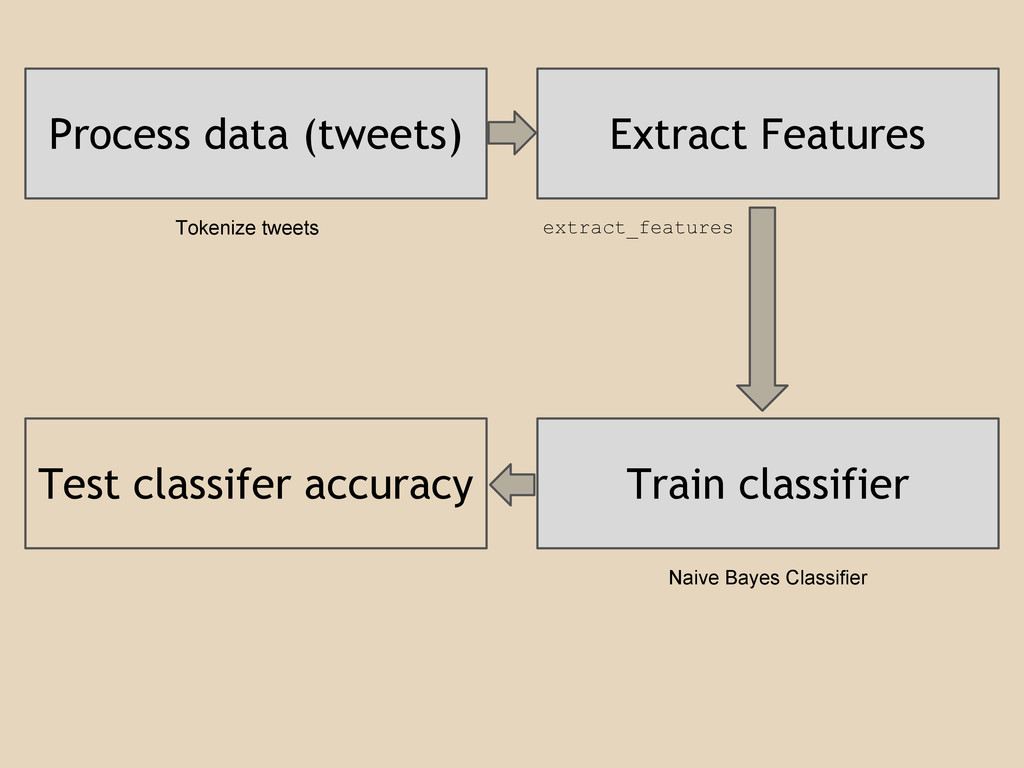
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
Happy tweets usually contain the following words: "am happy", "great
day" etc. Sad tweets usually contain the following: "not happy", "am sad" etc. features
{'contains(not)': False, 'contains(view)': False, 'contains(best)': False, 'contains(excited)': False, 'contains(morning)': False,
'contains(about)': False, 'contains(horrible)': True, 'contains(like)': False, ... } output of extract_features()
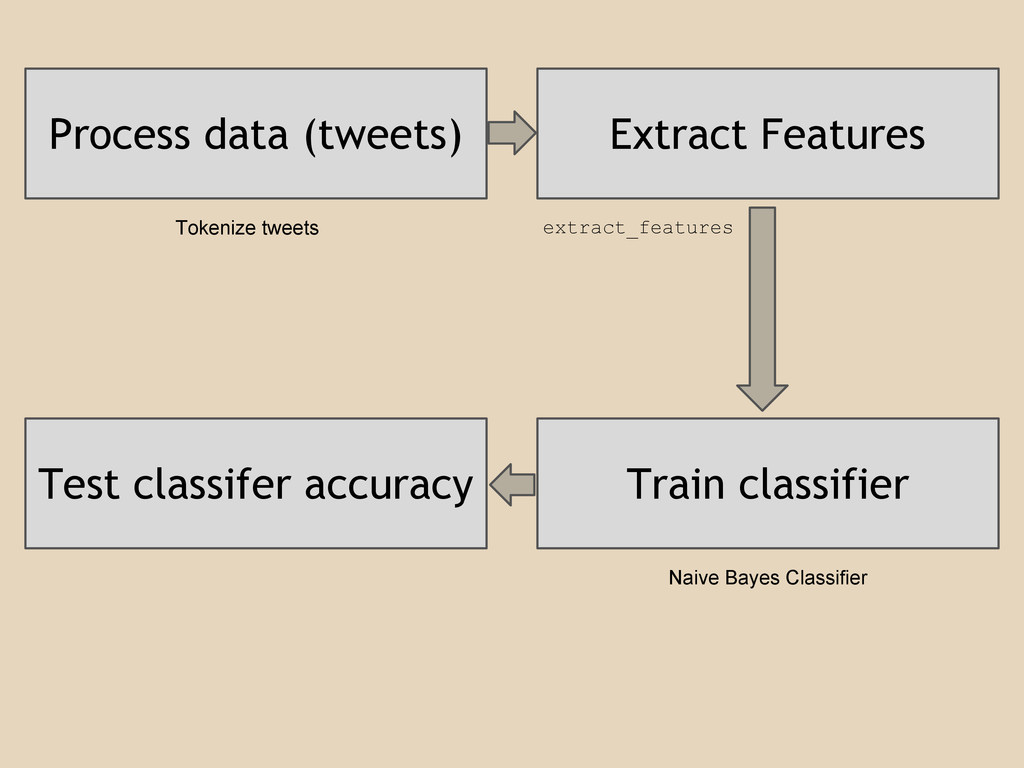
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
training_set = \ nltk.classify.util.\ apply_features(extract_features, tweets) classifier = \ NaiveBayesClassifier.train
(training_set) training the classifer training classifer
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
def classify_tweet(tweet): return \ classifier.classify(extract_features (tweet)) testing classifer
$ python classification.py Total accuracy: 90.00% (18/20) 18 tweets got
classified correctly.
Where to go from here.
http://www.nltk.org/book
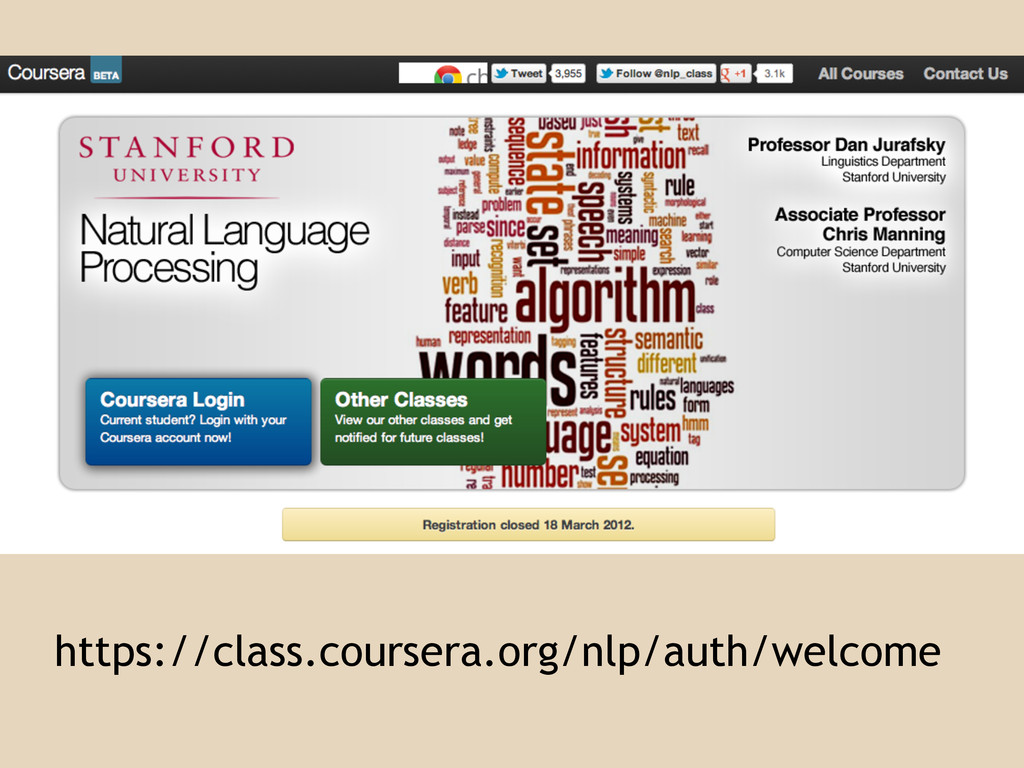
https://class.coursera.org/nlp/auth/welcome
http://www.slideshare.net/shanbady/nltk-boston-text-analytics
[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_35.jpg){kind=link}