We present the motivation behind building an open-source data context service in the big data ecosystem and discuss our initial work on the Ground project at U.C. Berkeley.
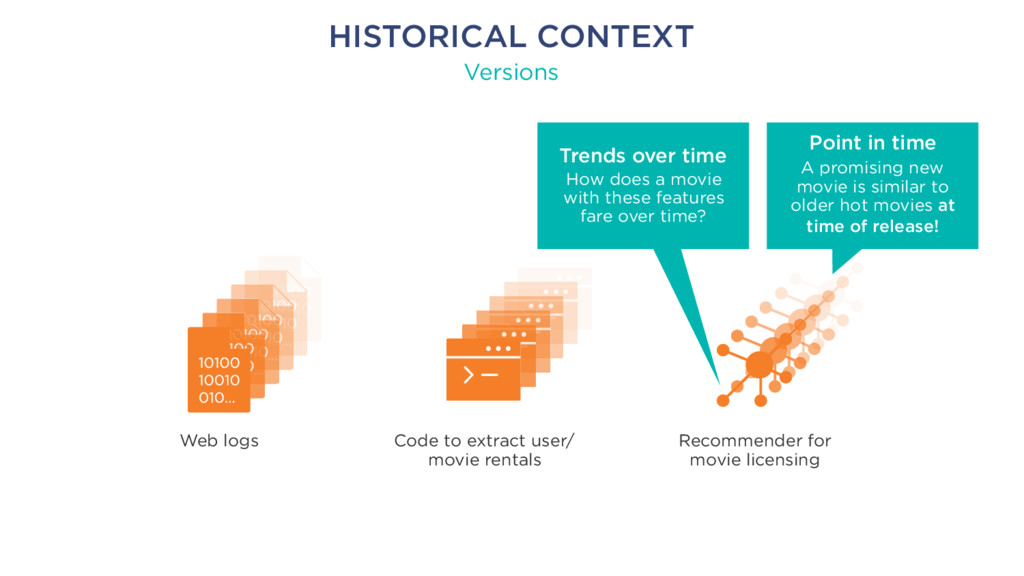
rentals Recommender for movie licensing Point in time A promising new movie is similar to older hot movies at time of release! Trends over time How does a movie with these features fare over time?
Data Science Recommenders “You should compare with book sales from last year.” Curation Tips “Logistics staff checks weather data the 1st Monday of every month.” Proactive Impact Analysis “The Twitter analysis script changed. You should check the boss’ dashboard!”
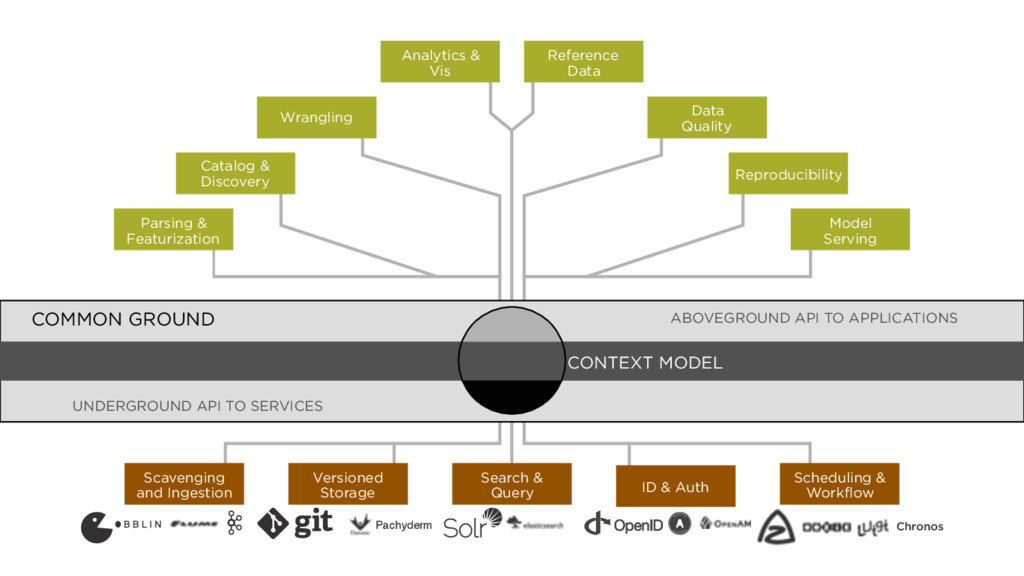
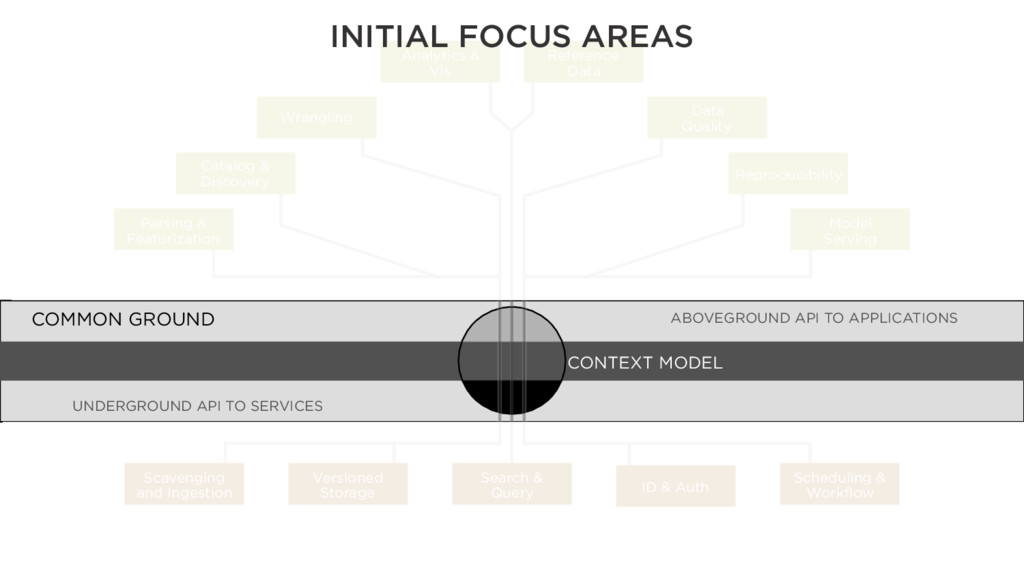
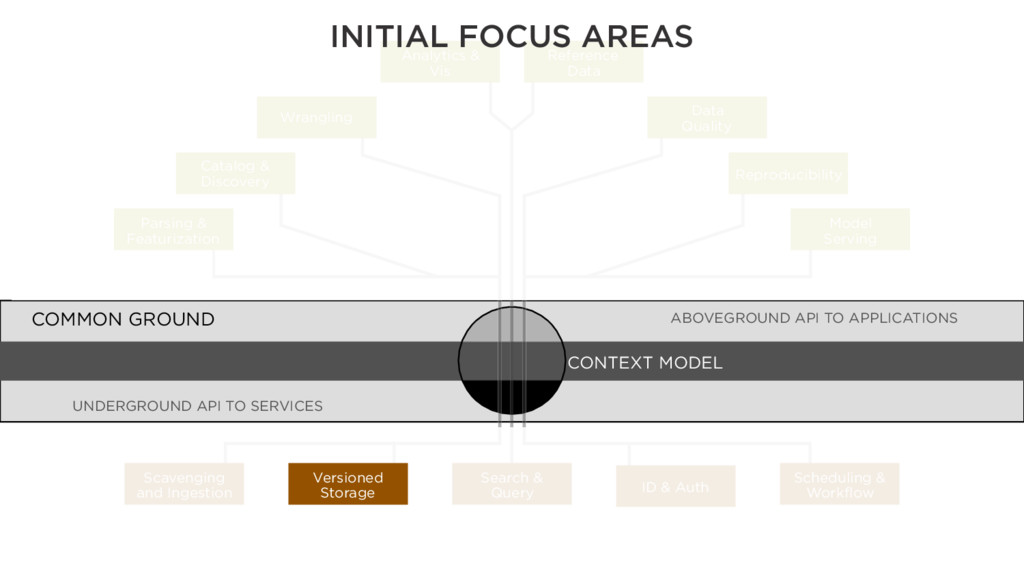
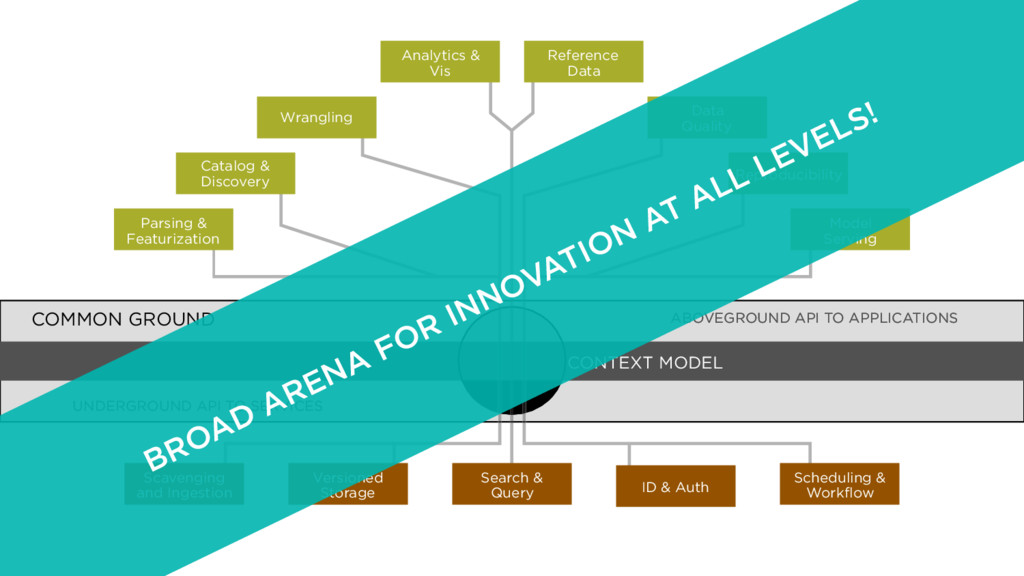
COMMON GROUND Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Reproducibility Model Serving Scavenging and Ingestion Search & Query Scheduling & Workflow Versioned Storage ID & Auth
Storage ID & Auth COMMON GROUND CONTEXT MODEL Pachyderm Chronos Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Reproducibility Model Serving ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES CONTEXT MODEL COMMON GROUND
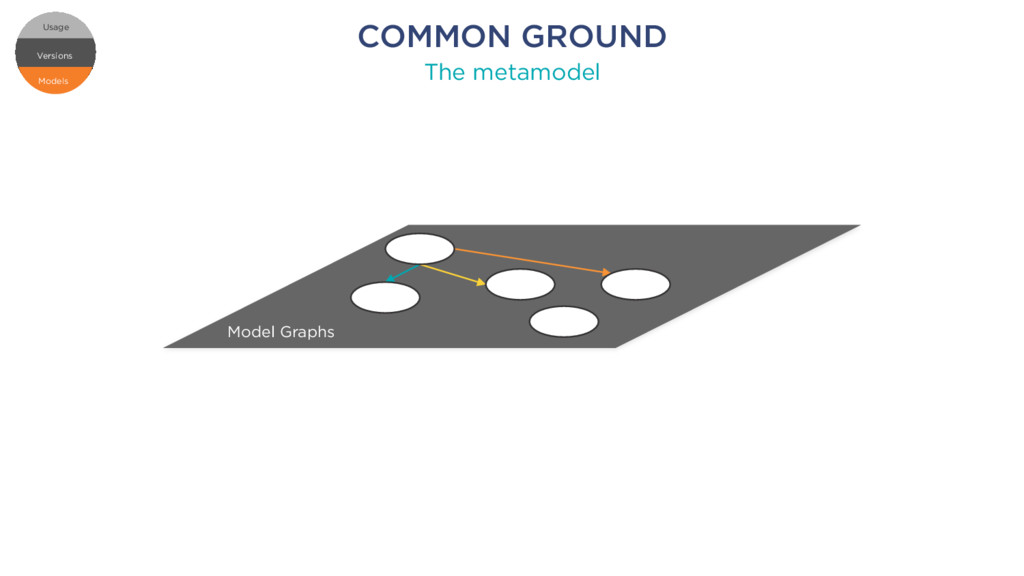
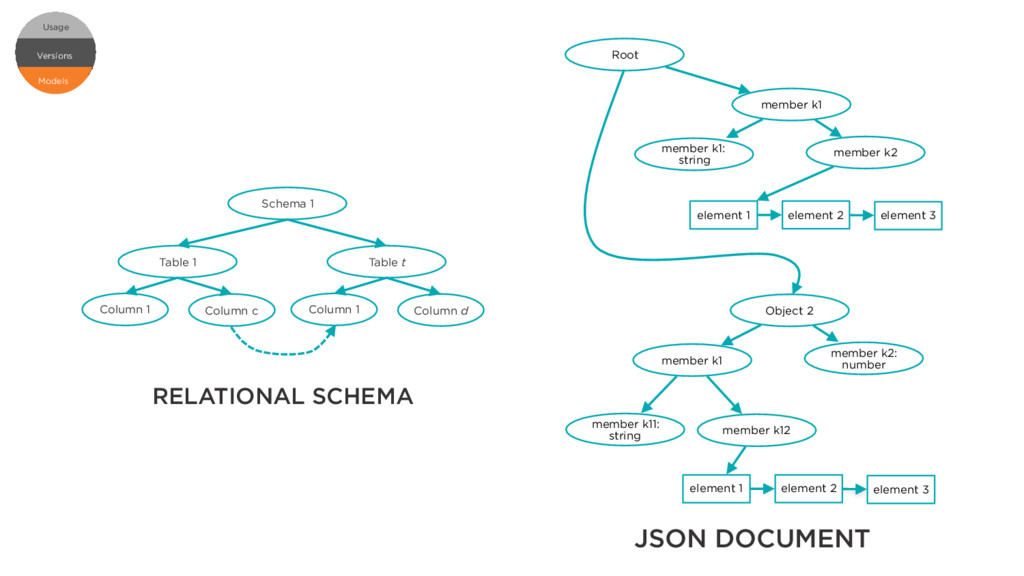
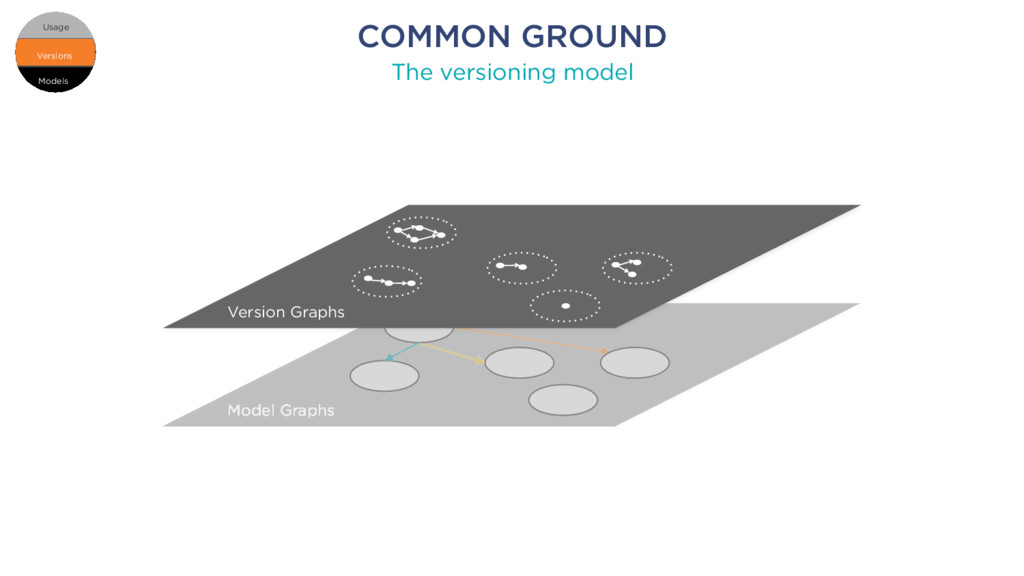
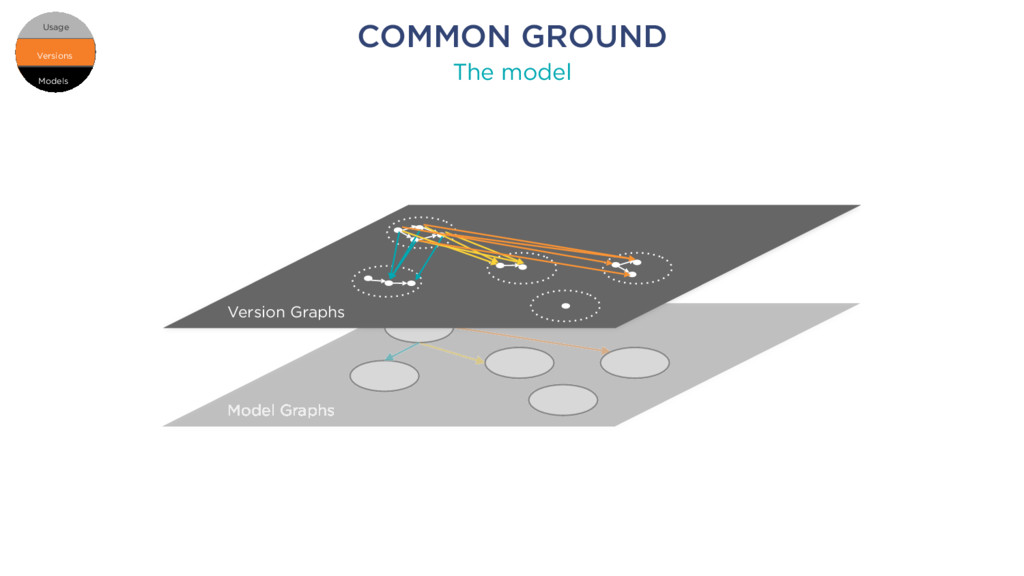
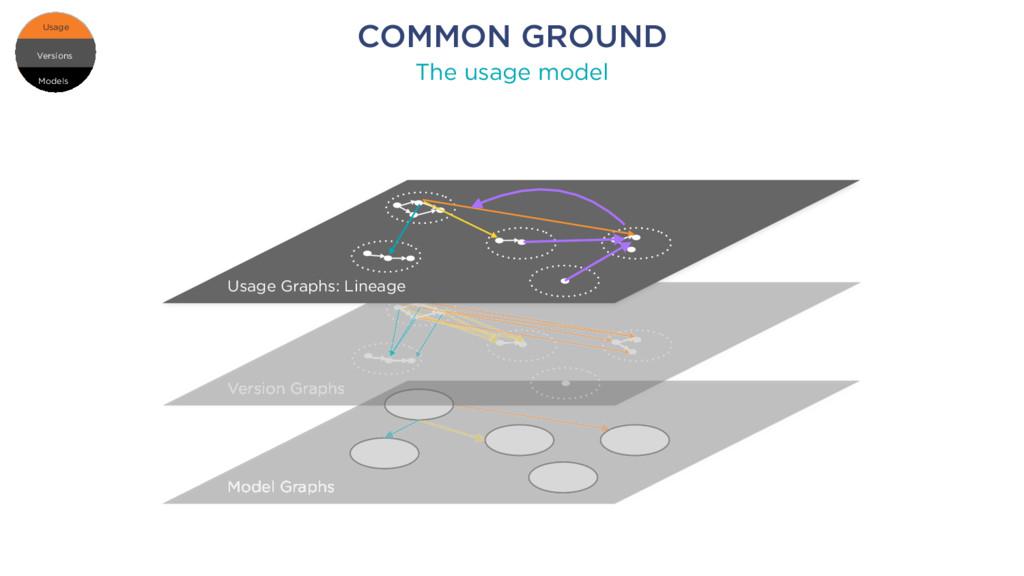
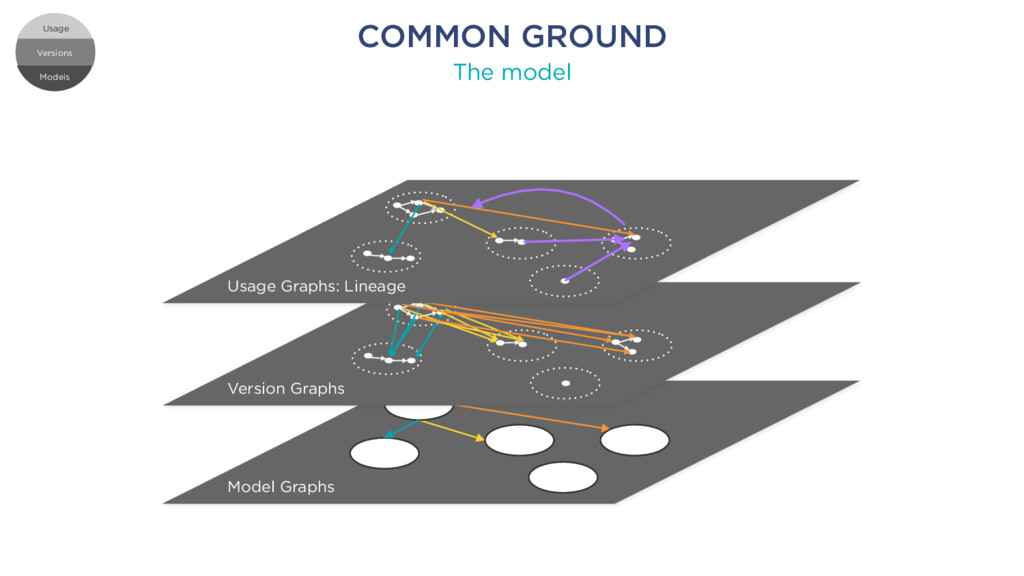
k1 member k2: number member k11: string member k12 element 1 element 2 element 3 element 1 element 2 element 3 Root RELATIONAL SCHEMA JSON DOCUMENT Schema 1 Table 1 Column 1 Column c Table t Column 1 Column d foreign key Models Versions Usage Versions Usage Models
• GitHub’s Webhooks API! • Reports back to Ground on every push. Unfortunately, some wrinkles here • Webhooks API doesn’t report the full version lineage • So can’t rely on GitHub. Track the git repo ourselves. • A topic for future collaboration perhaps. (FWIW, Google Docs is even messier!) gr
1 Column c Table t Column 1 Column d foreign key Apiary Ground as the backing store for Hive Metastore Relational catalog a design pattern above our basic context model Hive Metastore the de facto catalog for structured big data
COMMON GROUND Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Reproducibility Model Serving Scavenging and Ingestion Search & Query Scheduling & Workflow Versioned Storage ID & Auth INITIAL FOCUS AREAS
COMMON GROUND Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Scavenging and Ingestion Search & Query Scheduling & Workflow Versioned Storage ID & Auth INITIAL FOCUS AREAS Parsing & Featurization Model Serving Reproducibility
COMMON GROUND Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Reproducibility Model Serving Scavenging and Ingestion Search & Query Scheduling & Workflow ID & Auth INITIAL FOCUS AREAS Versioned Storage
COMMON GROUND Parsing & Featurization Catalog & Discovery Wrangling Analytics & Vis Reference Data Data Quality Reproducibility Model Serving Scavenging and Ingestion Search & Query Scheduling & Workflow Versioned Storage ID & Auth ABOVEGROUND API TO APPLICATIONS UNDERGROUND API TO SERVICES BROAD ARENA FOR INNOVATION AT ALL LEVELS!
Historical context Because things change Behavioral context Because behavior determines meaning Application context Because truth is subjective GROUNDING BIG DATA WITH CONTEXT SERVICES
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}