834604261, win 4117, options [nop,nop,TS val 230425600 ecr 4106181590], length 432
[email protected][email protected].............. .....[.GET / HTTP/1.1 Host: brokensite.net Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/ *;q=0.8,application/signed-exchange;v=b3 Accept-Encoding: gzip, deflate Accept-Language: en-US,en;q=0.9,gl;q=0.8 ^C 1 packets captured 3 packets received by filter 0 packets dropped by kernel On the proxy… $ tcpdump -A -s 0 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)' -i eth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes 14:02:02.779102 IP y.y.y.y.47553 > x.x.x.x.80: Flags [P.], seq 3426796935:3426797367, ack 834604261, win 4117, options [nop,nop,TS val 230425600 ecr 4106181590], length 432
[email protected][email protected].............. .....[.GET / HTTP/1.1 Host: brokensite.net Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/ *;q=0.8,application/signed-exchange;v=b3 Accept-Encoding: gzip, deflate Accept-Language: en-US,en;q=0.9,gl;q=0.8 ^C 1 packets captured 3 packets received by filter 0 packets dropped by kernel Fancy way to sniff traffic and get full
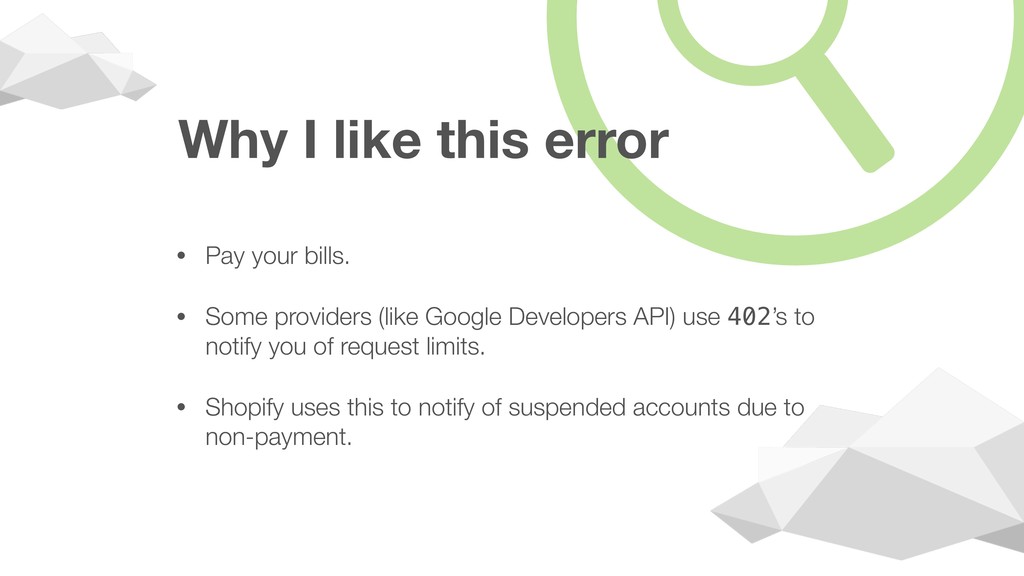
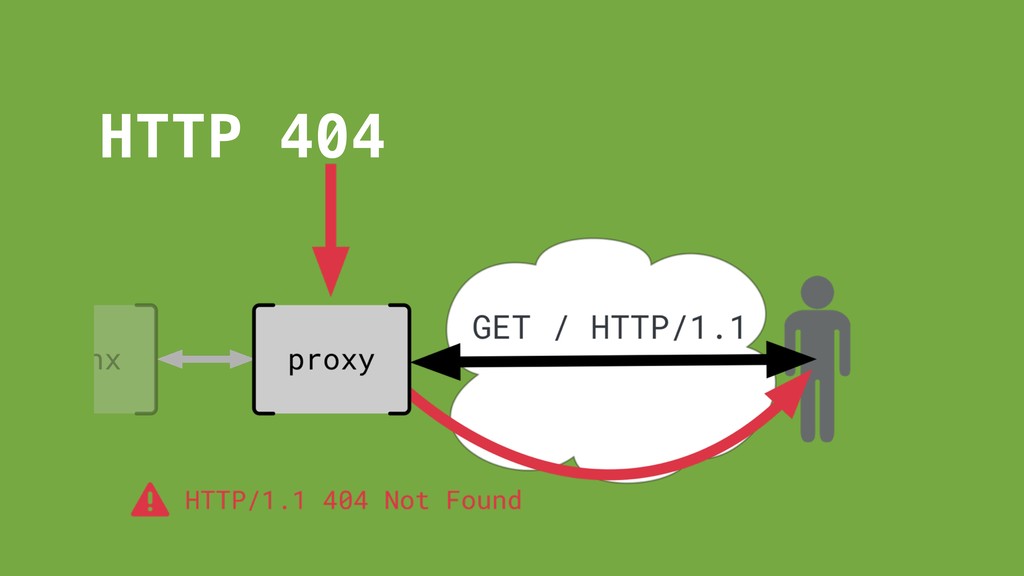
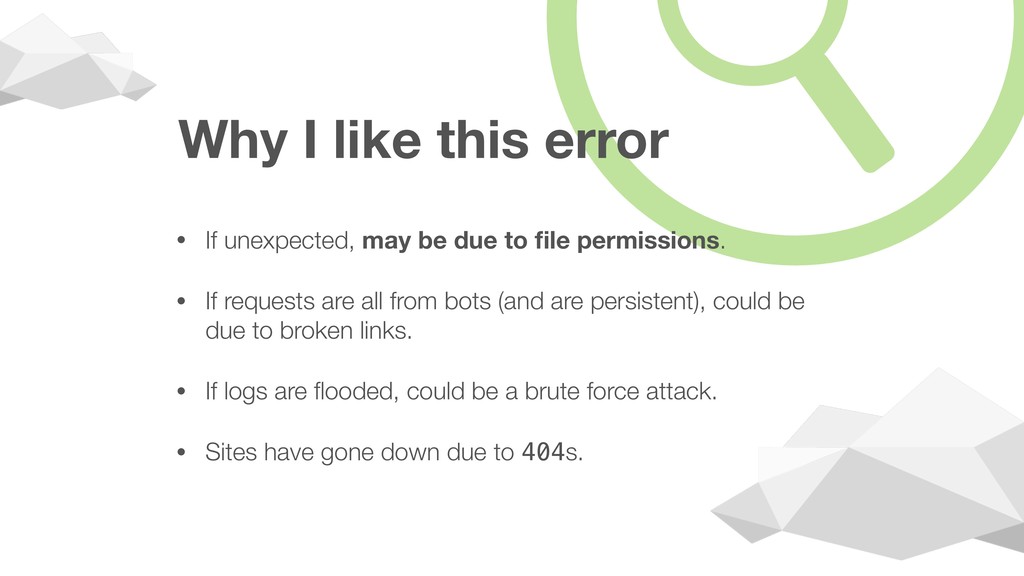
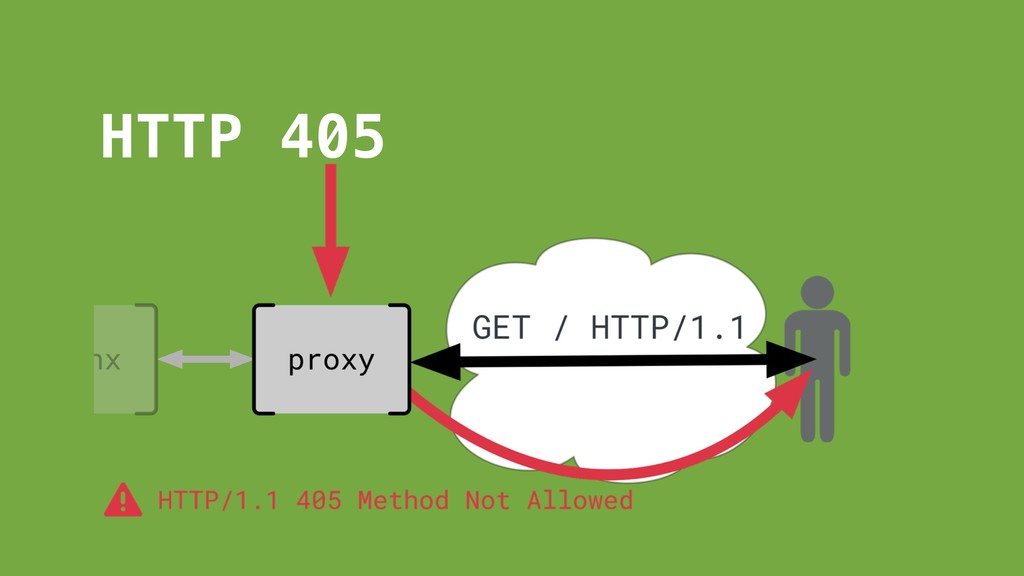
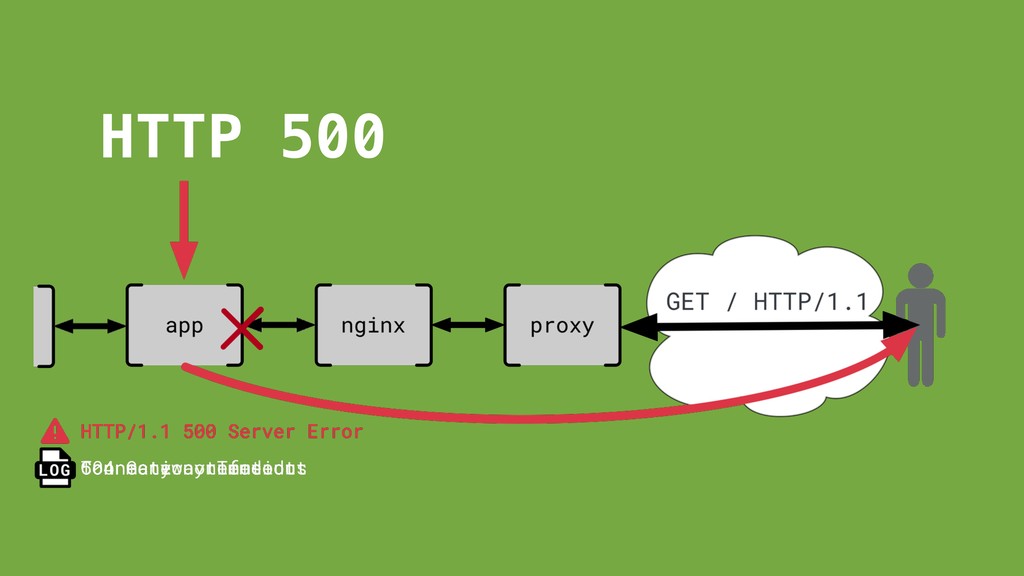
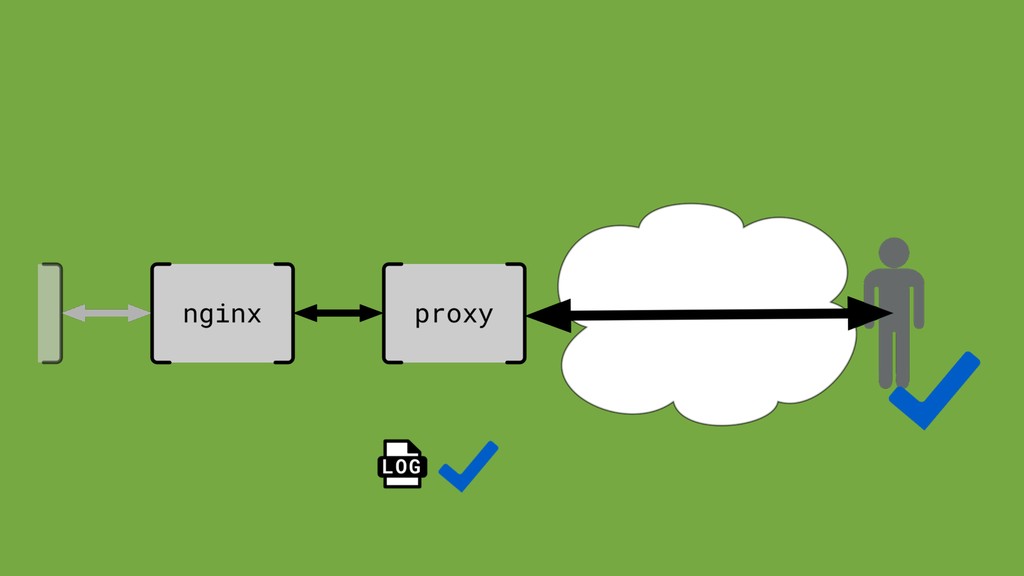
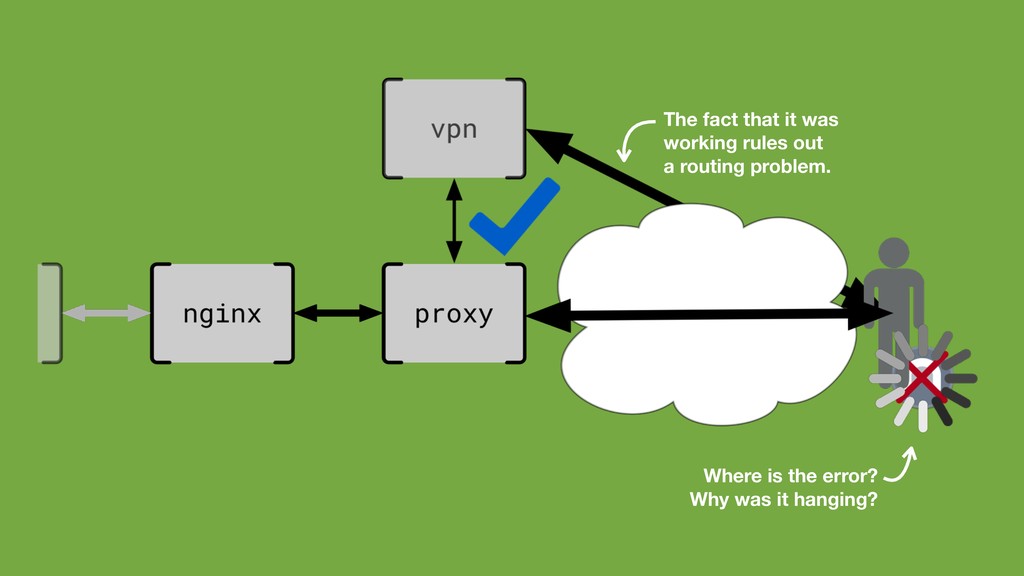
request/response cycle. Normal request coming through. Absolutely nothing came through.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14:02:02.779102 IP y.y.y.y.47553 > x.x.x.x.80: Flags [P.], seq 3426796935:3426797367, ack](https://files.speakerdeck.com/presentations/2d6eac514f144265a75b4bd3001c101c/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}