A continuing series of talks presented by VM Farms, Tales from the Ops Side serves to educate developers on operational best practices for maintaining application performance, stability, and system security, as well as to share frontline stories from the battlefield.
In this special FITC instalment, Hany Fahim, founder and CEO of VM Farms, discusses the impact celebrity influence can have on web traffic, and the devastating effects this can have on sites and applications. Using real world examples, Hany discusses the best methods to safe guard and protect against these spikes, while keeping online properties performant and available throughout.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
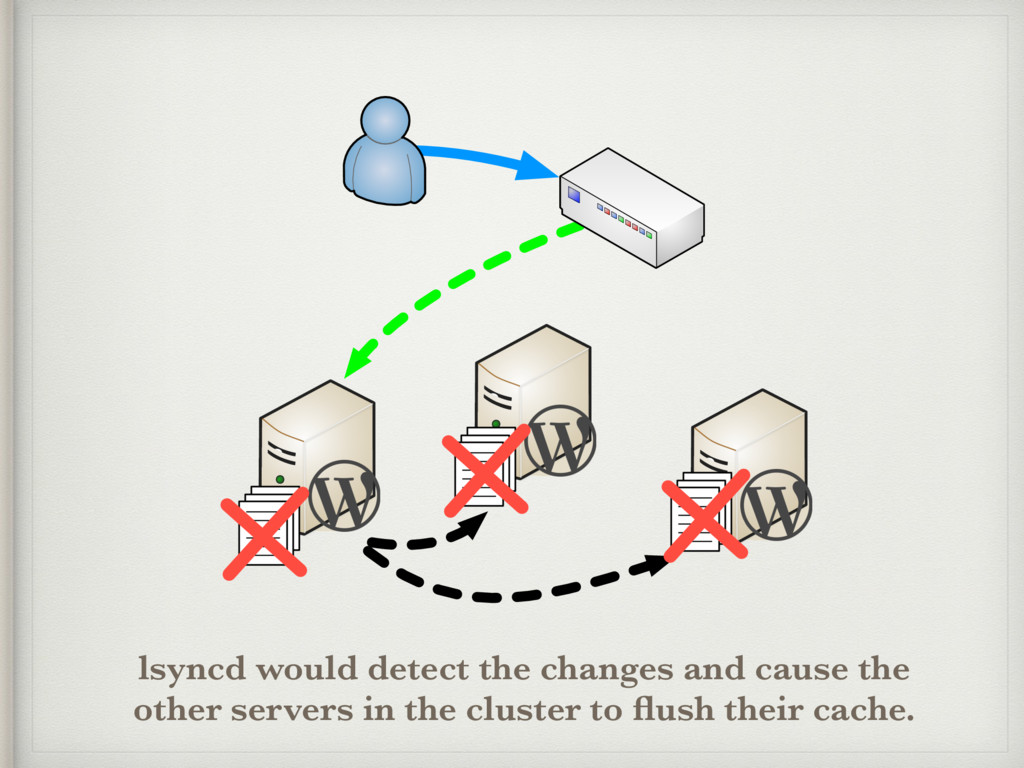{kind=link}
{kind=link}
{kind=link}
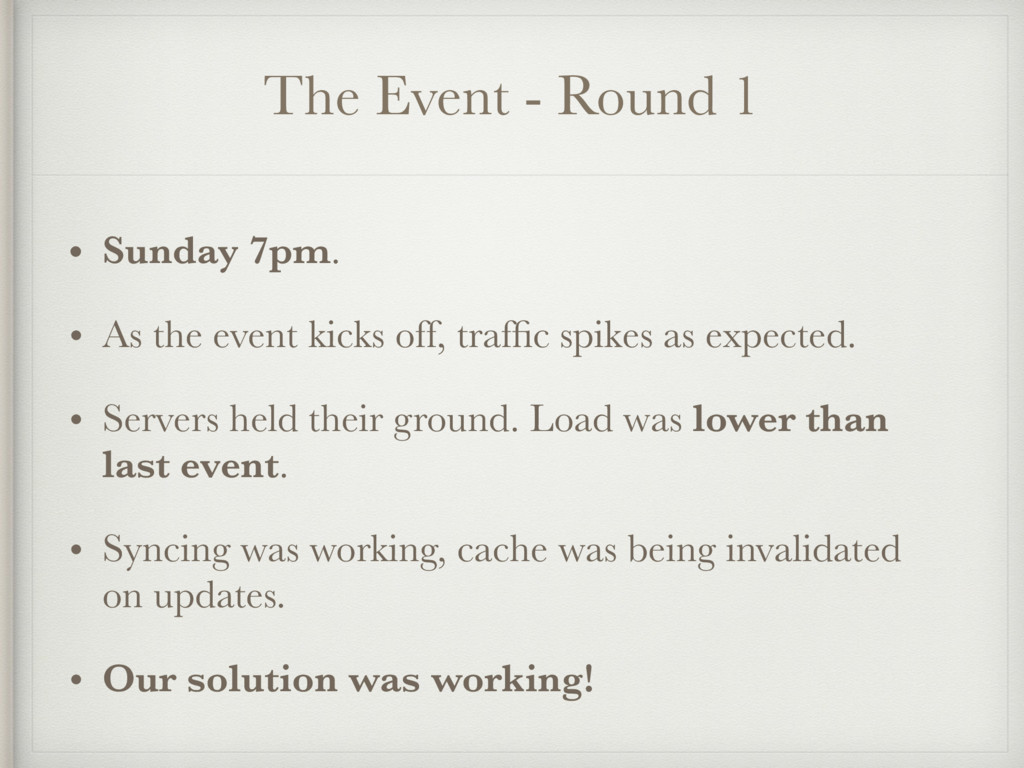{kind=link}
{kind=link}
{kind=link}
{kind=link}
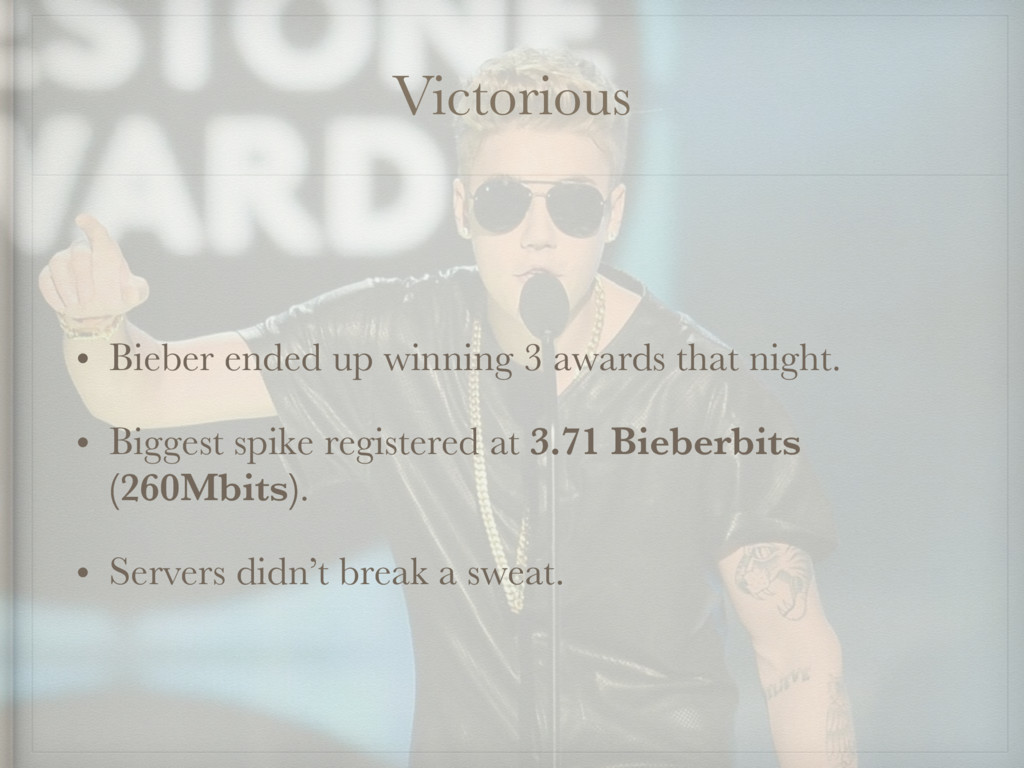{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}