Spark é 100x mais rápido comparado com Hadoop, para o processamento de dados em larga escala; ‣ Facilidade de uso: disponibiliza API (Application Programming Interface) para operar grandes datasets; ‣ Análises sofisticadas: inclui suporte a consulta SQL (Structured Query Language), data streaming, Machine Learning e processamento de grafos;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
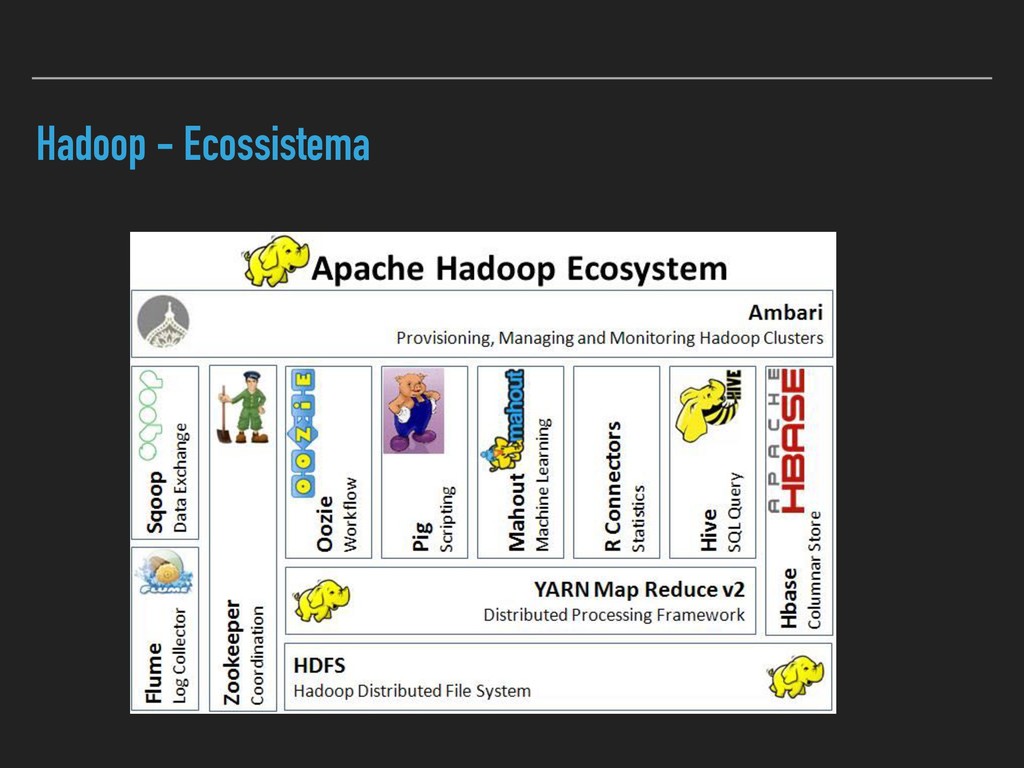{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}