と語りました。 Jensen Huang says Nvidia engineers should use AI tokens worth half their annual salary every year to be fully productive — compares not using AI to using paper and pencil for designing chips https://www.tomshardware.com/tech-industry/artificial-intelligence/jensen-huang-says-nvidia-engineers-should-use-ai-tokens-worth-half-their-ann ual-salary-every-year-to-be-fully-productive-compares-not-using-ai-to-using-paper-and-pencil-for-designing-chips
に難しいのです。」 Uber's COO says it's getting harder to justify the money spent on AI tokenmaxxing https://www.businessinsider.com/uber-coo-andrew-macdonald-ai-token-spending-harder-justify-2026-5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
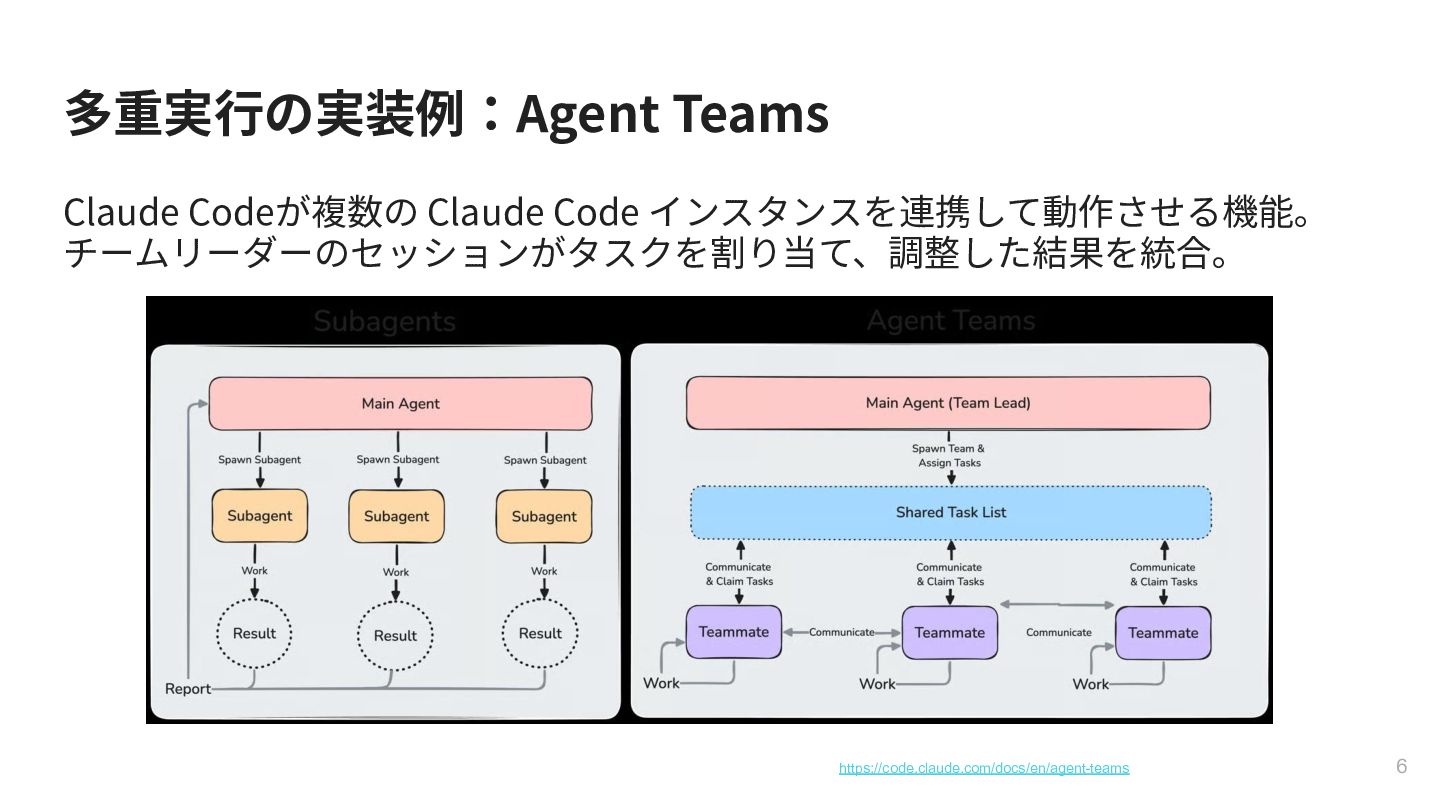{kind=link}
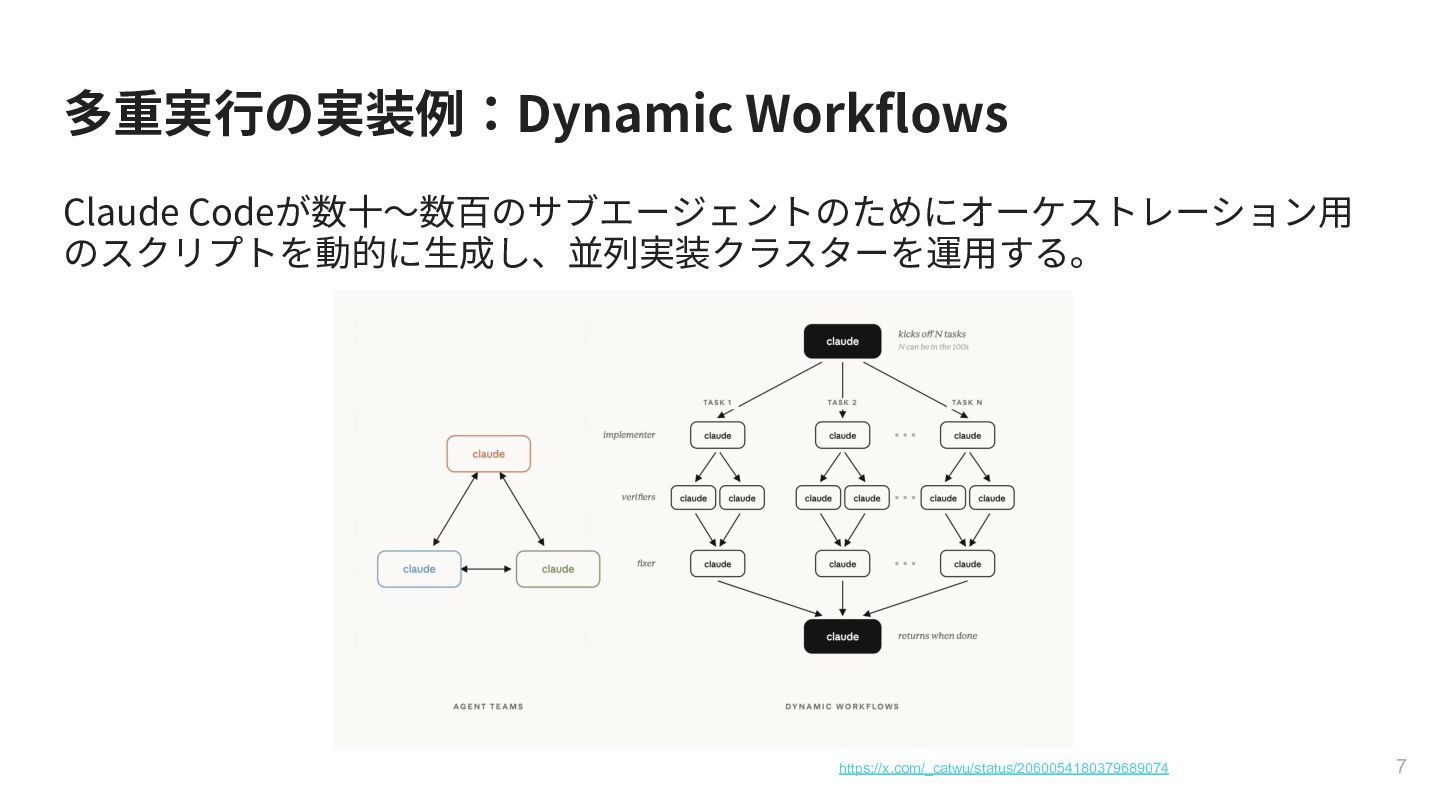{kind=link}
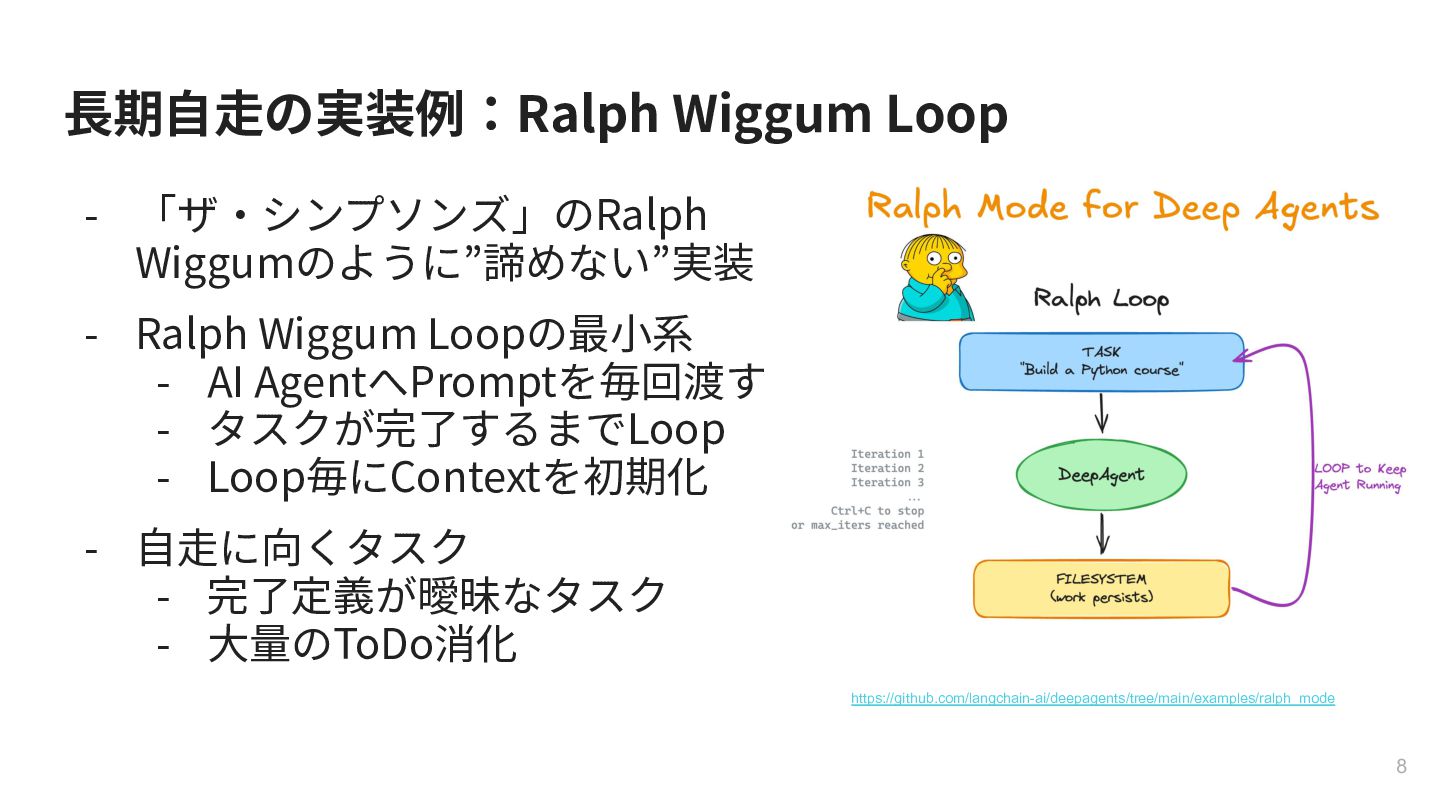{kind=link}
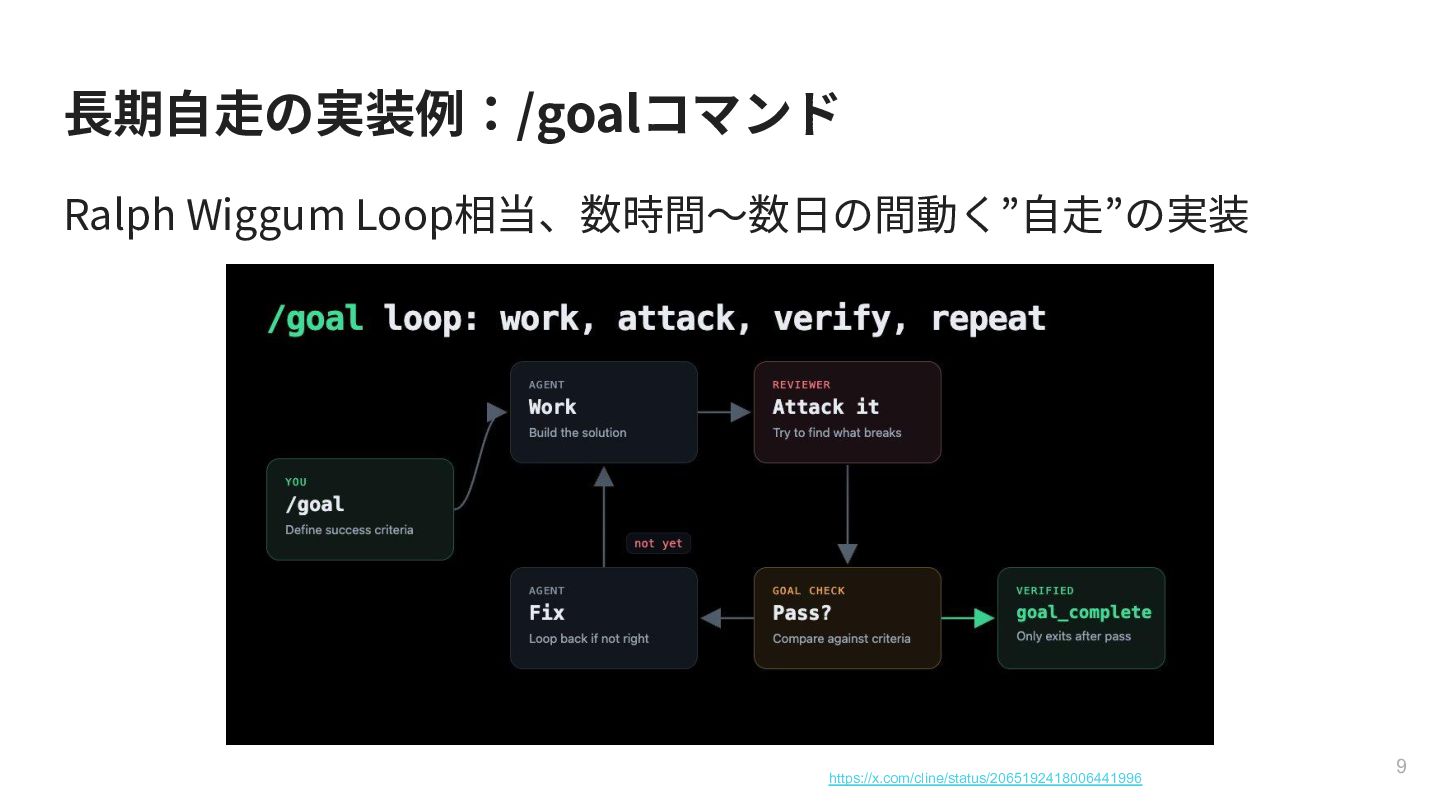{kind=link}
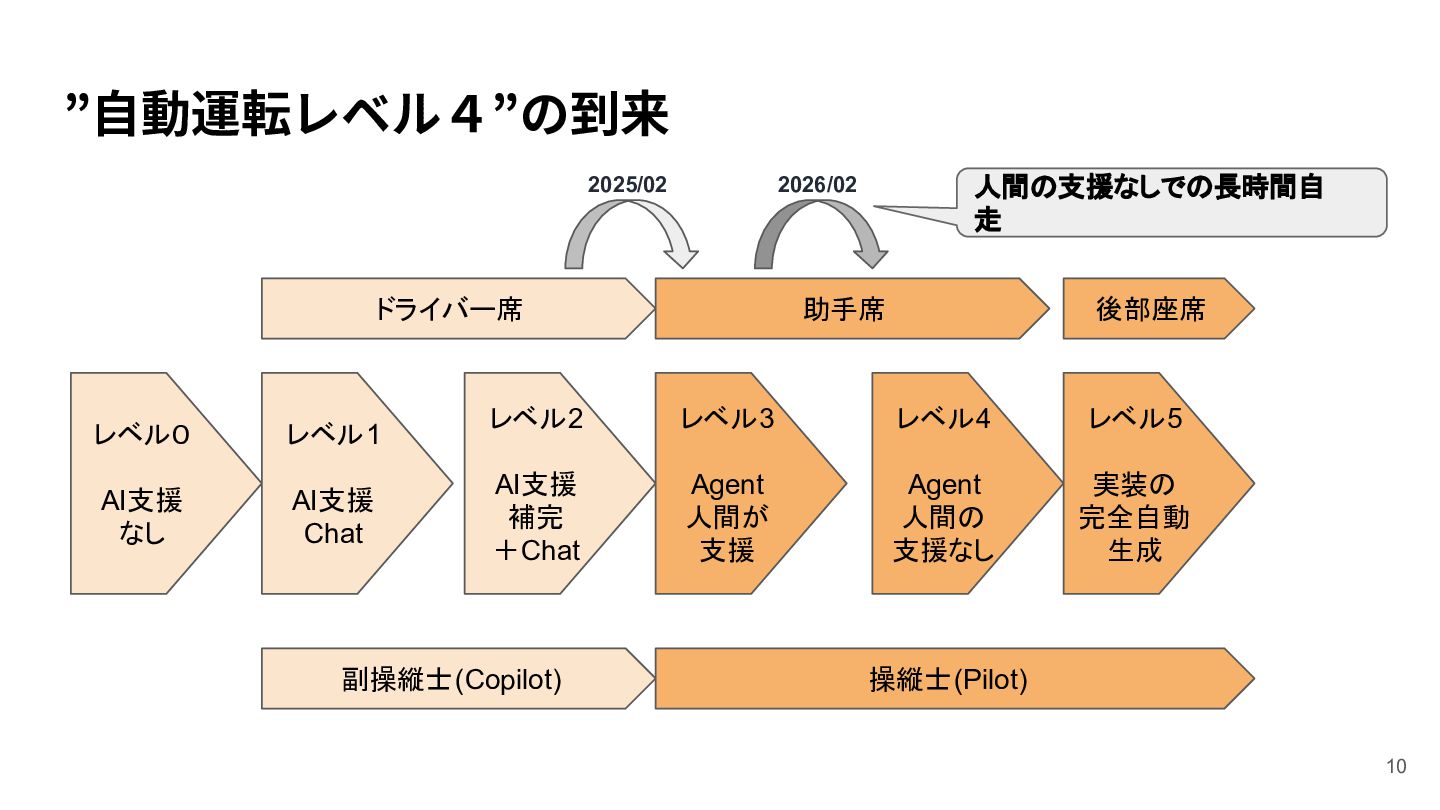{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
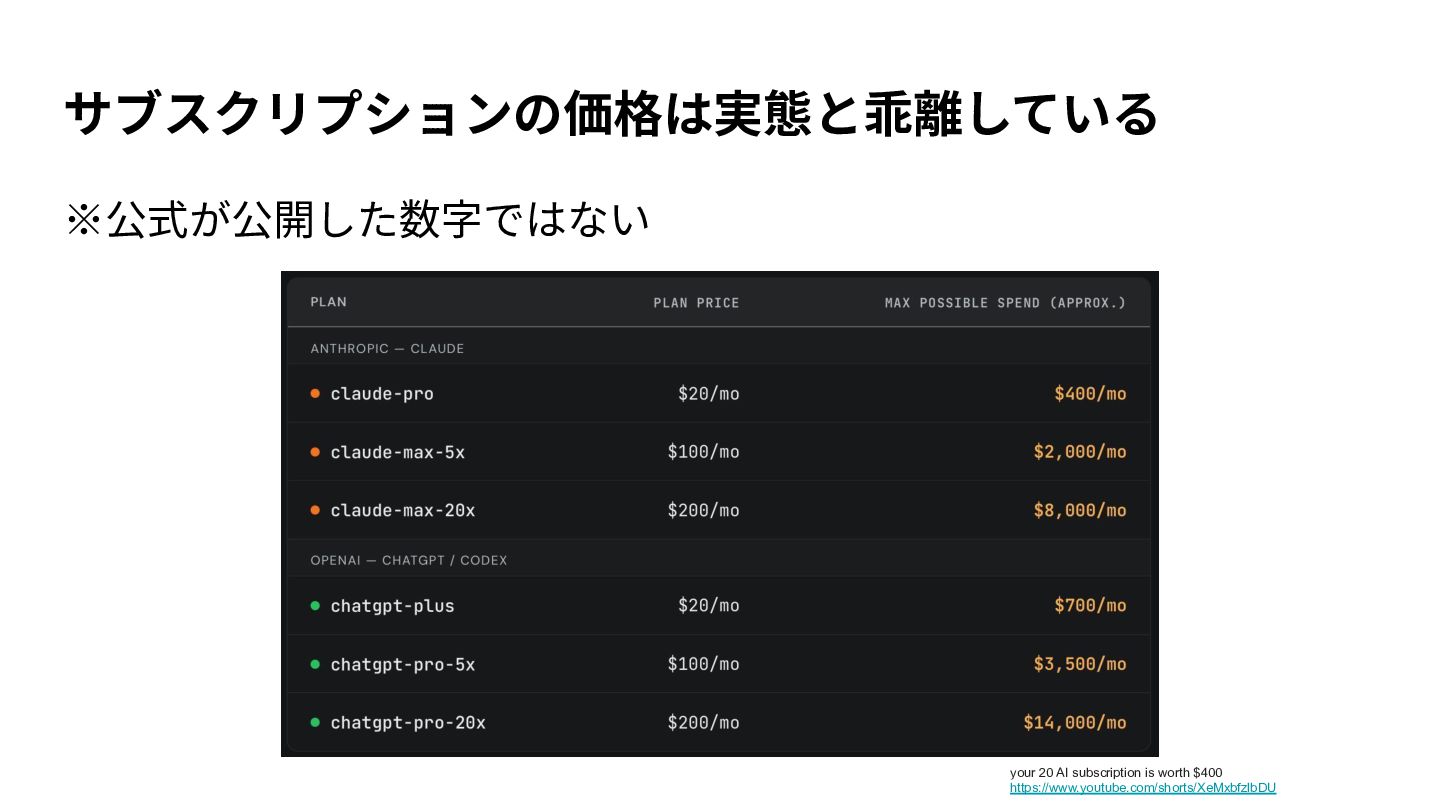{kind=link}
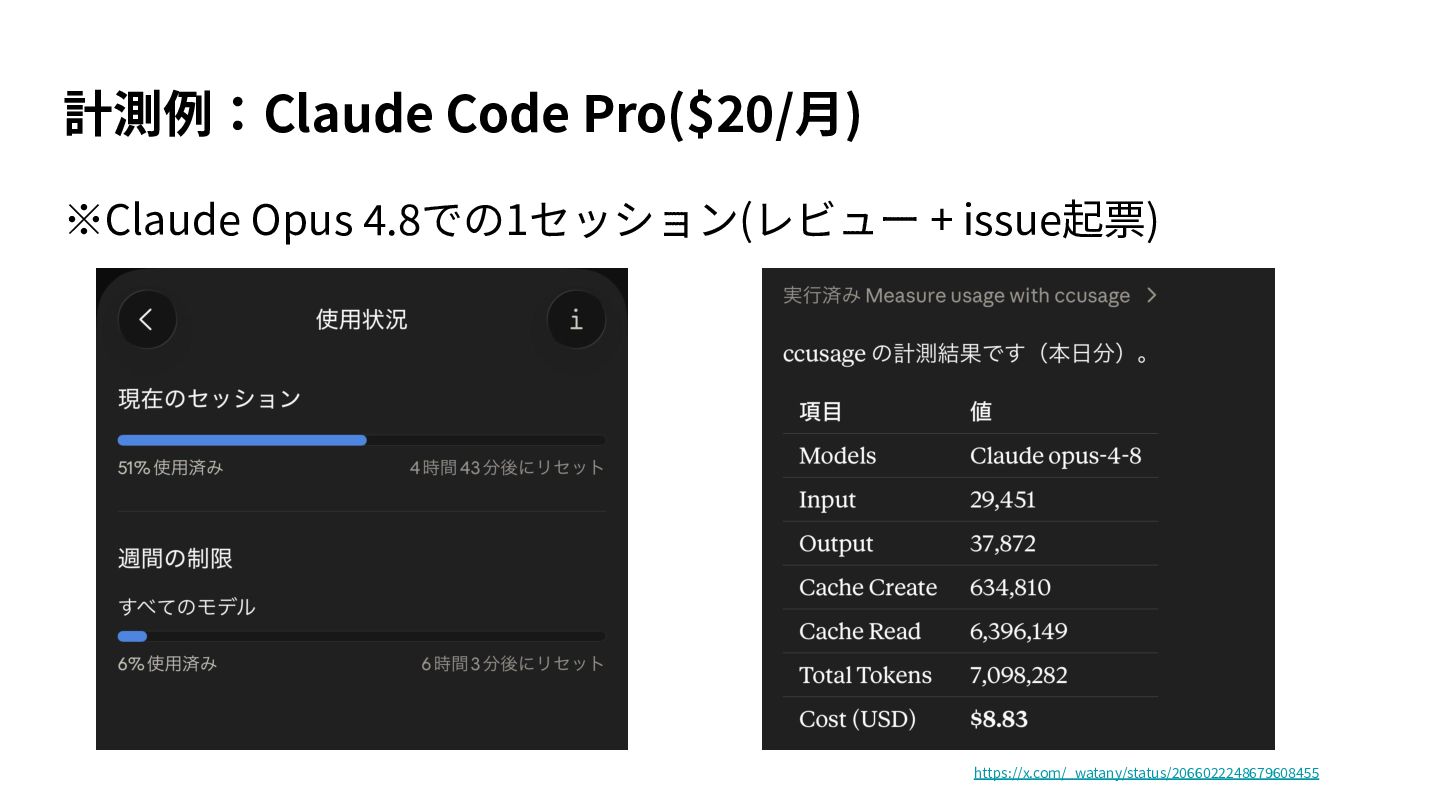{kind=link}
{kind=link}
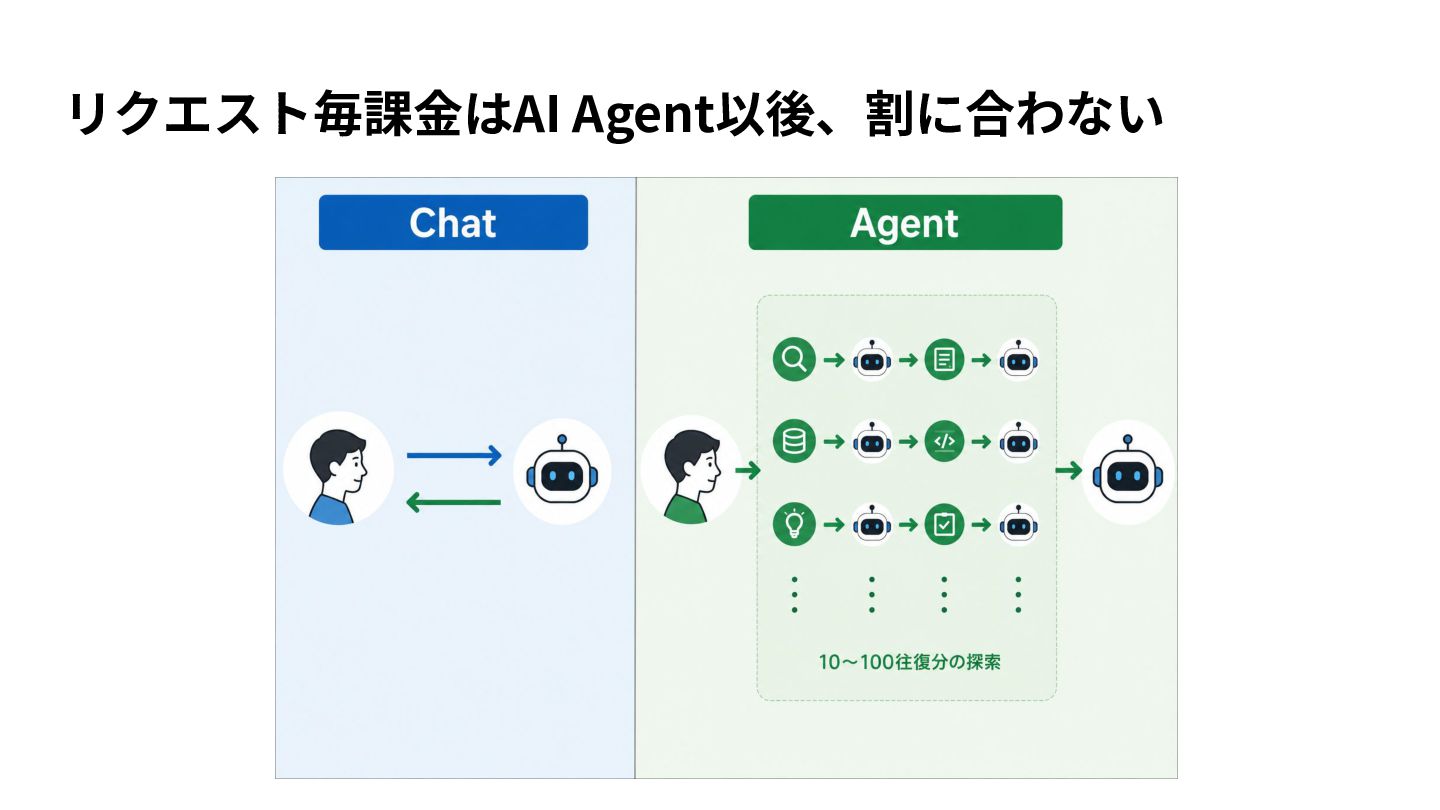{kind=link}
{kind=link}
{kind=link}
{kind=link}
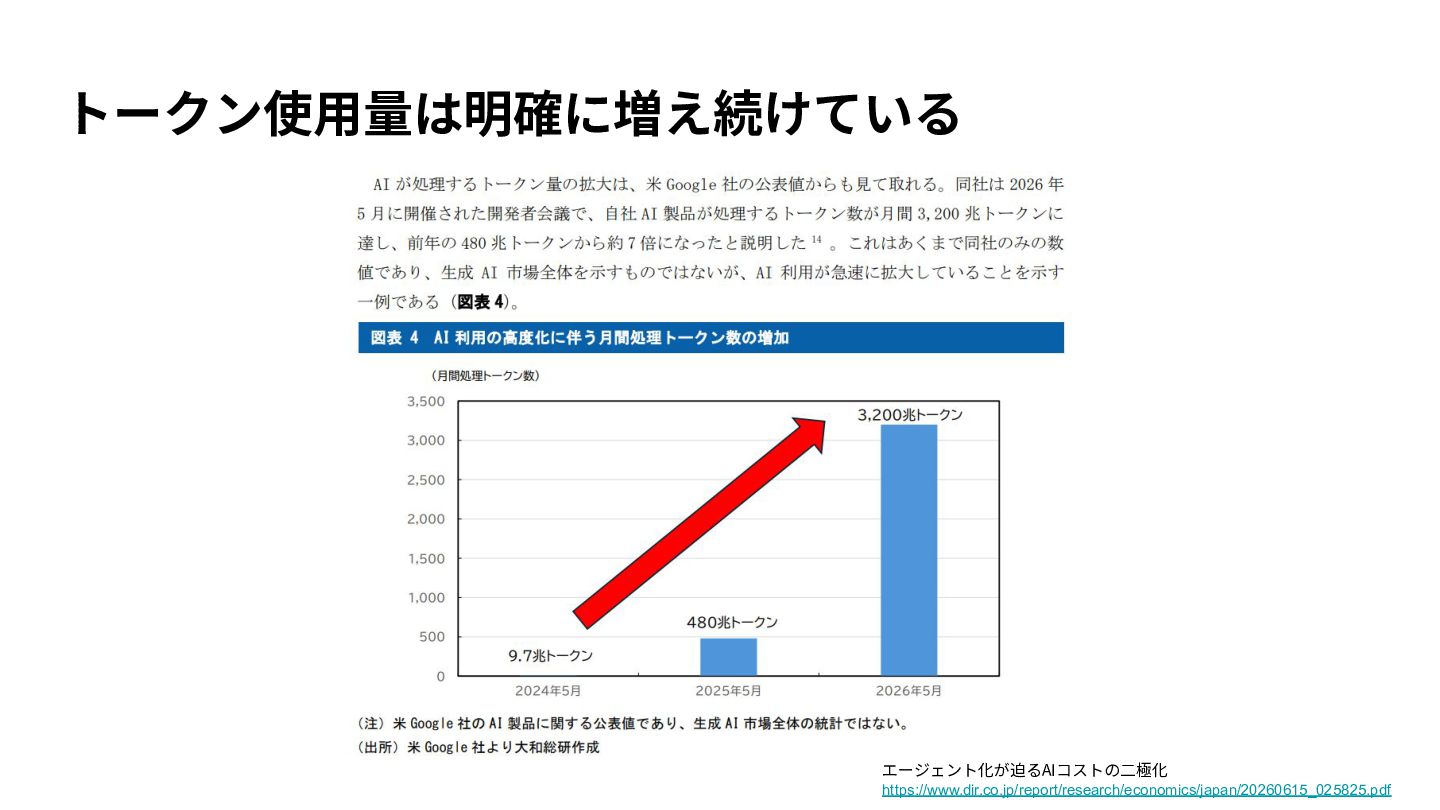{kind=link}
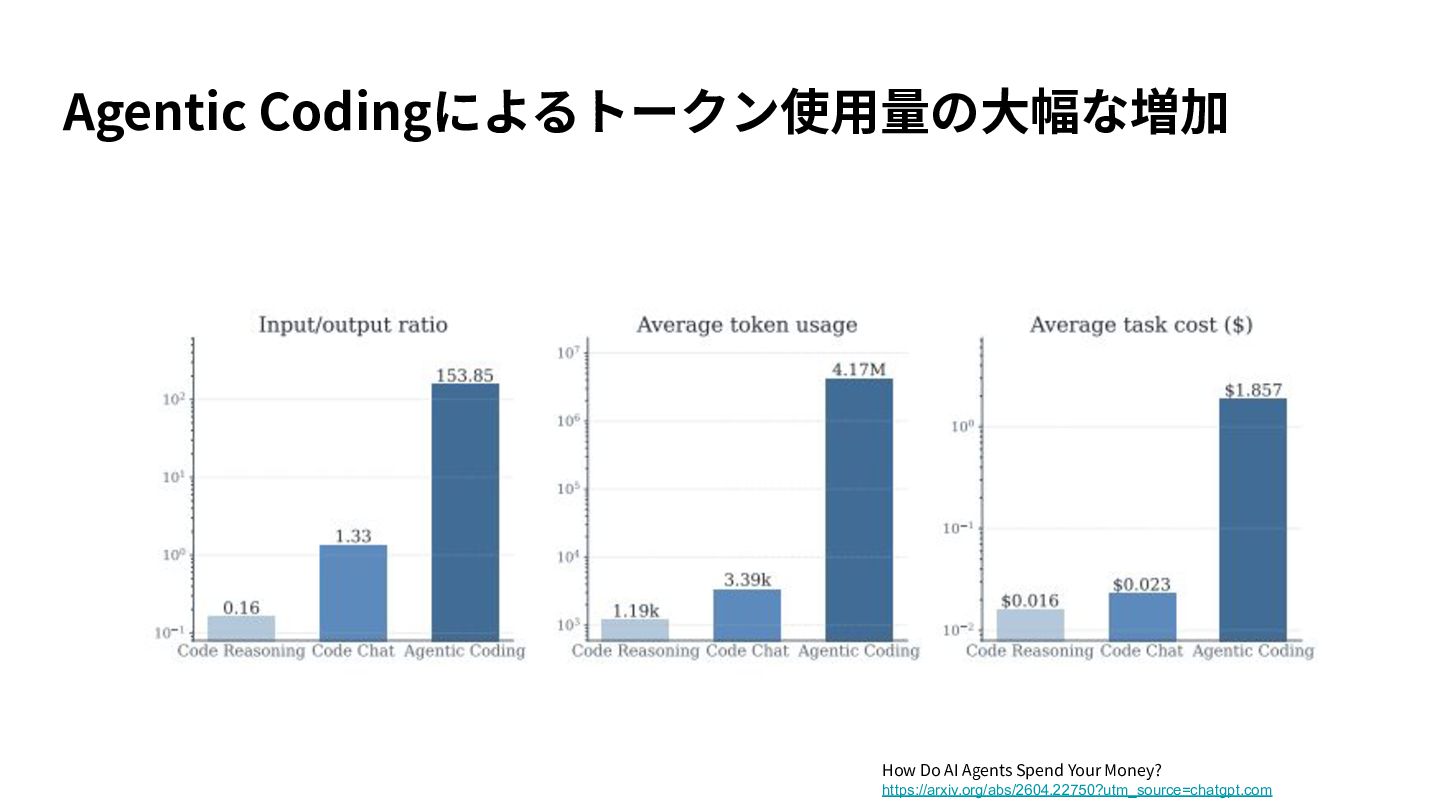{kind=link}
{kind=link}
{kind=link}
{kind=link}
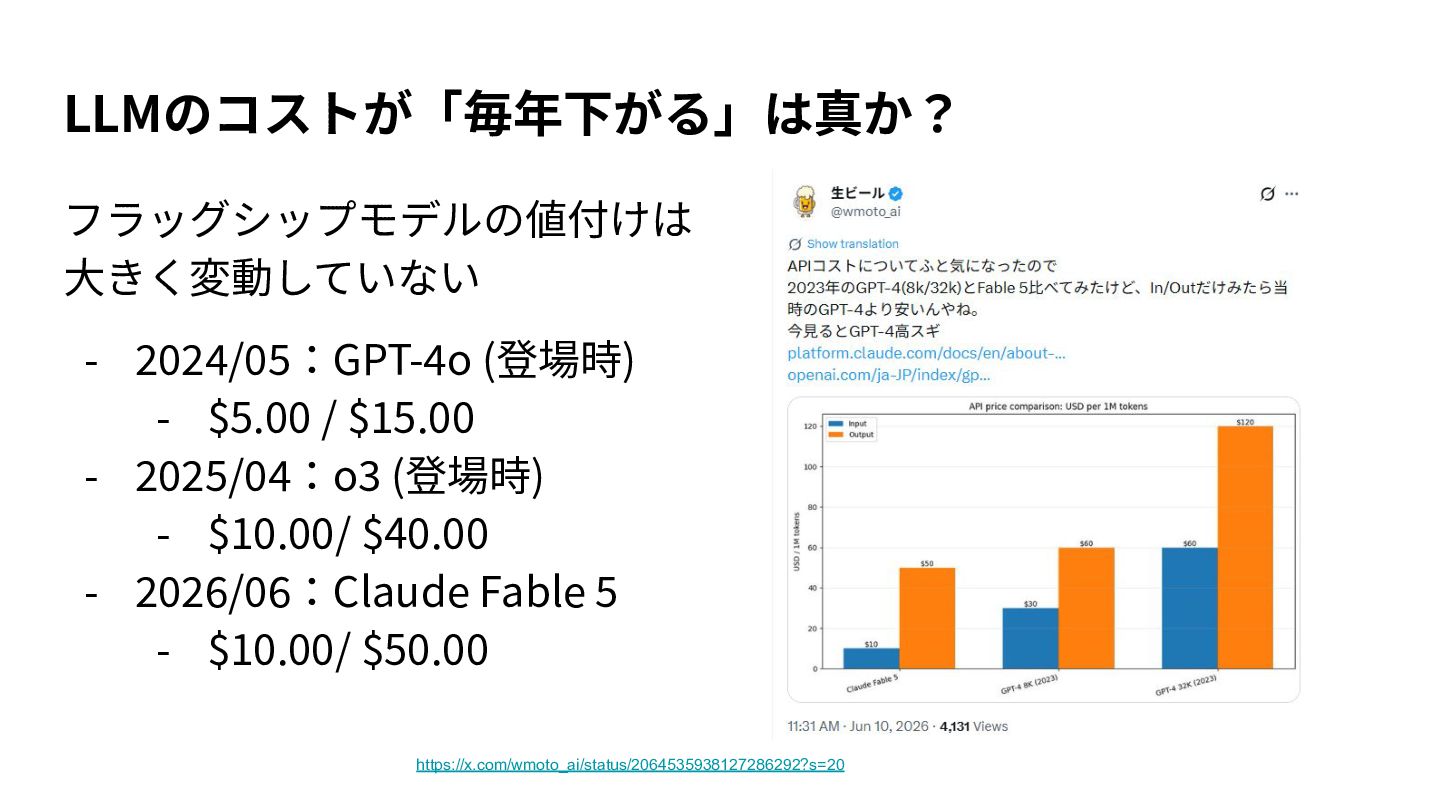{kind=link}
{kind=link}
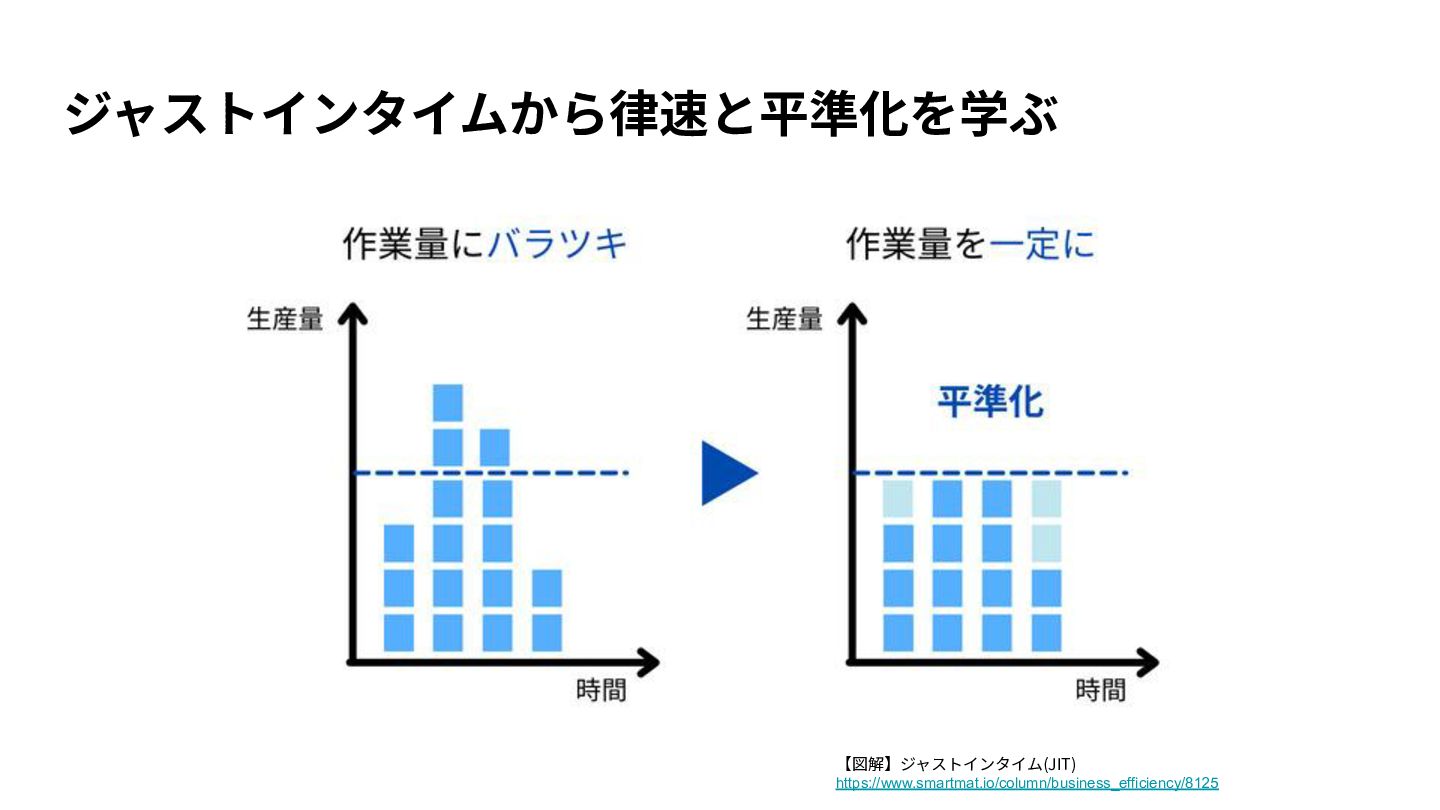{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
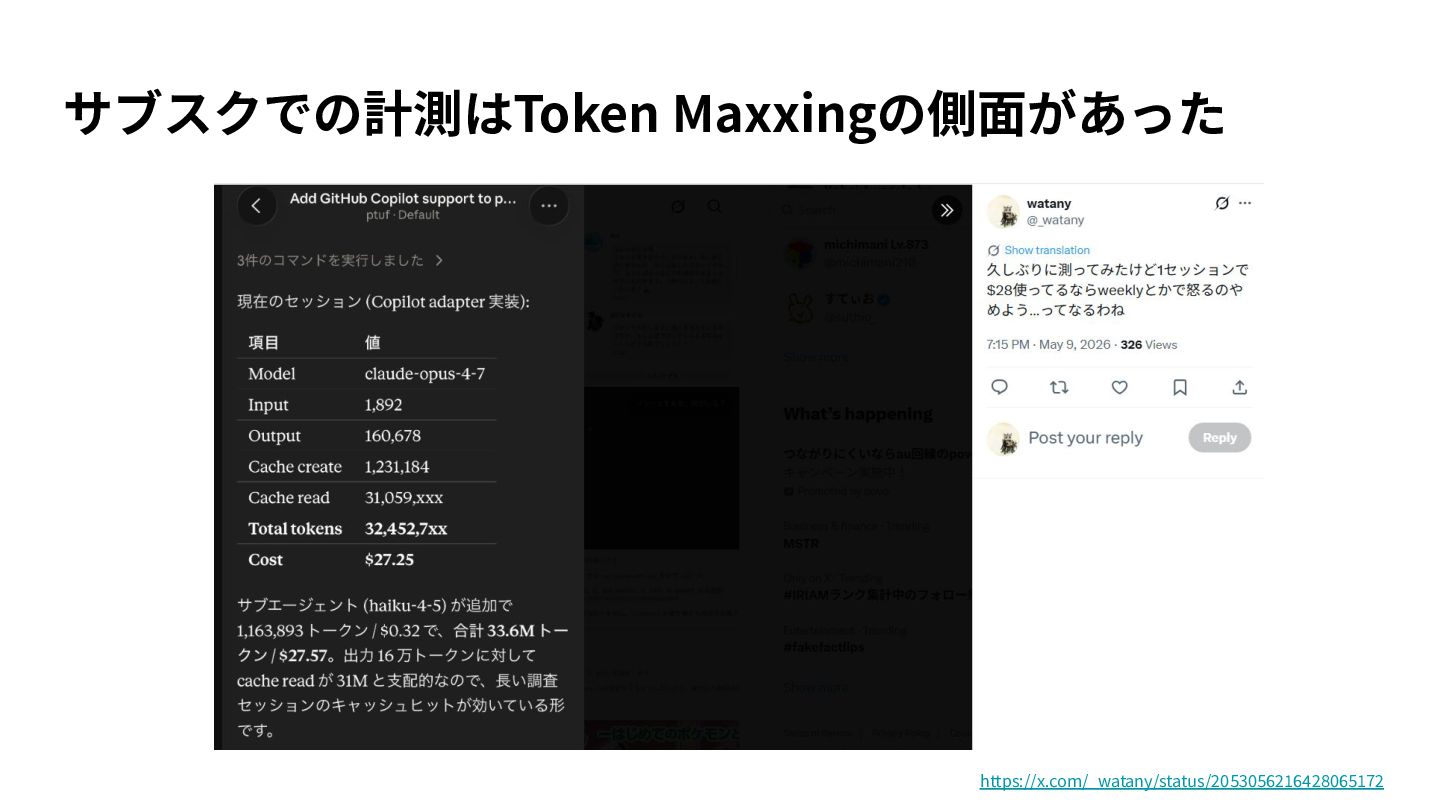{kind=link}
{kind=link}
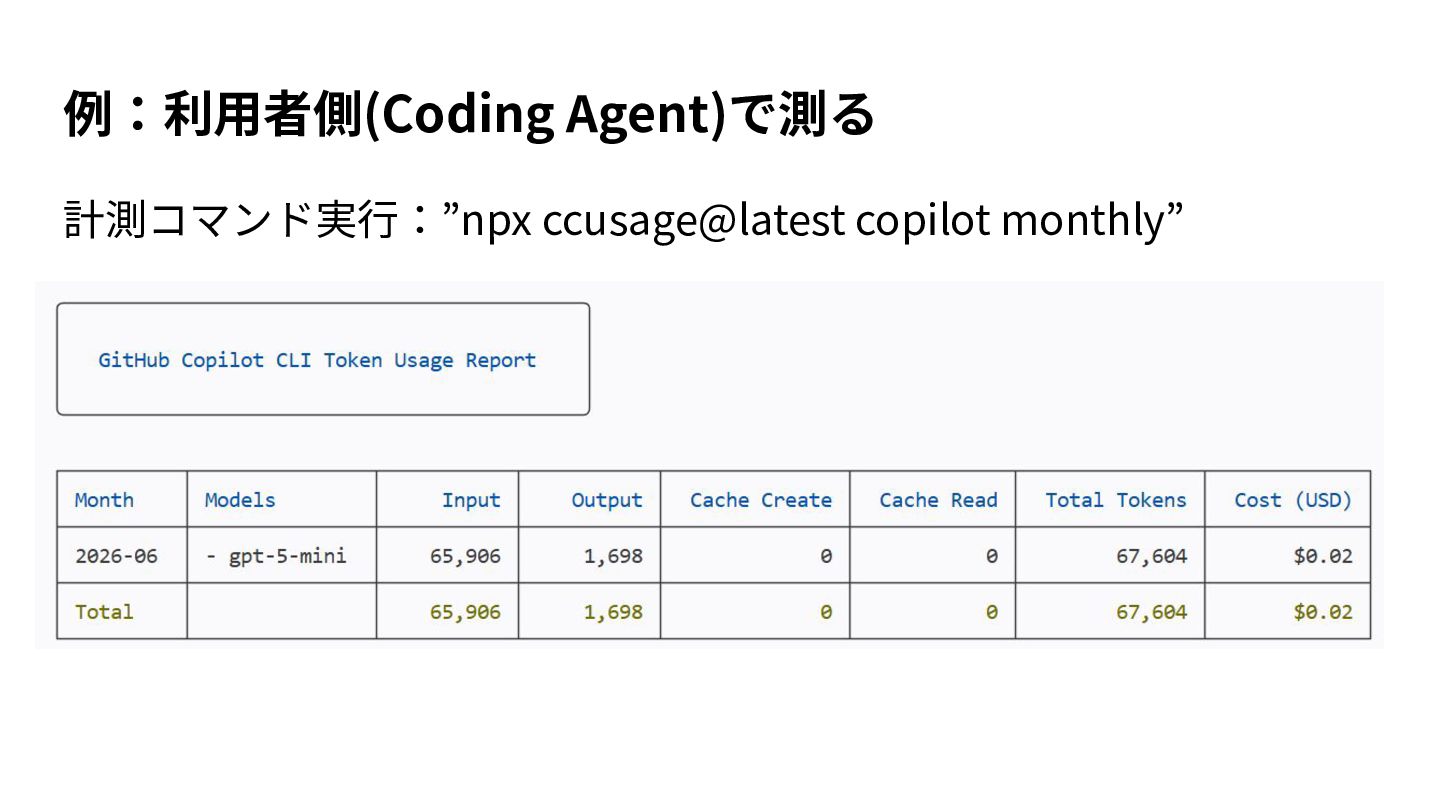{kind=link}
{kind=link}
{kind=link}
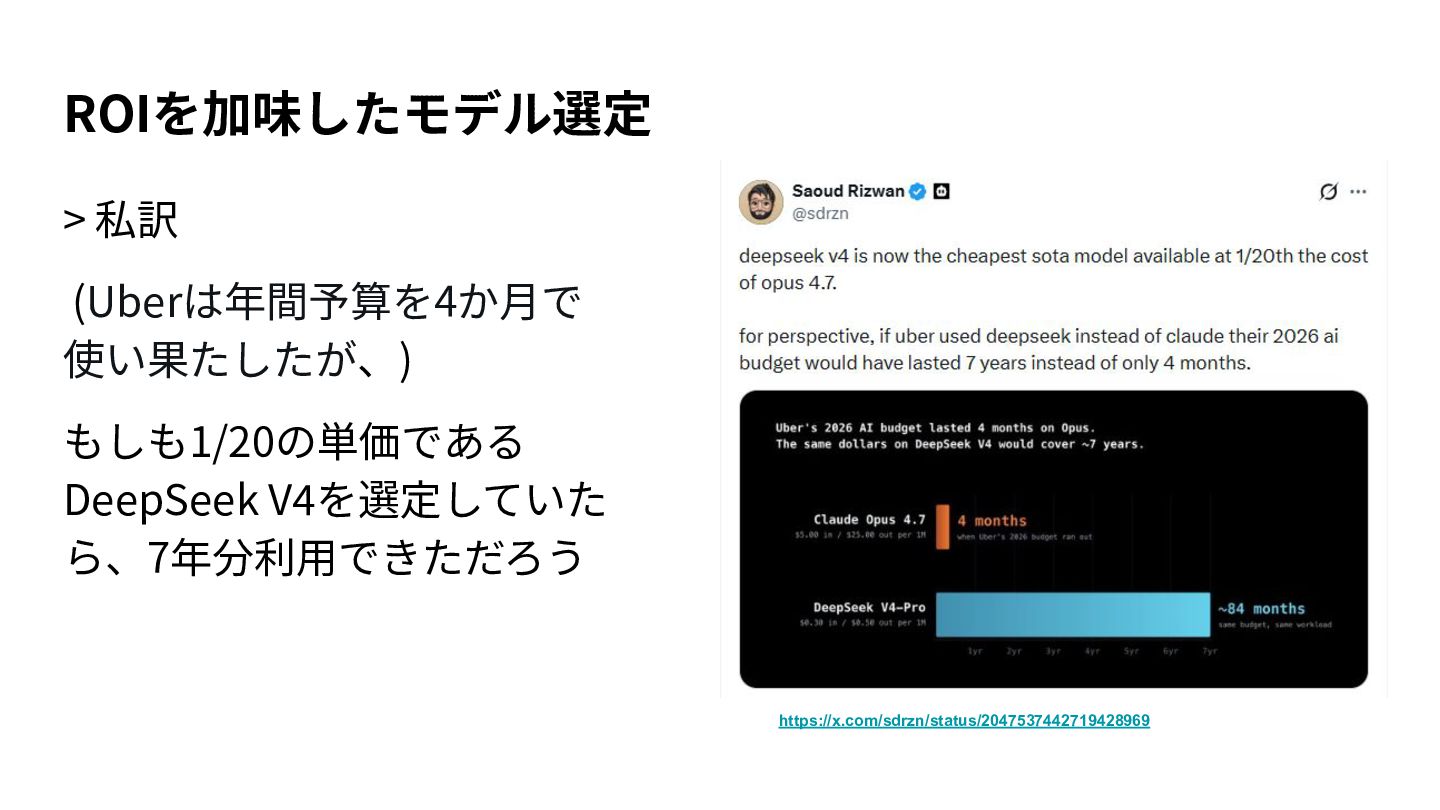{kind=link}
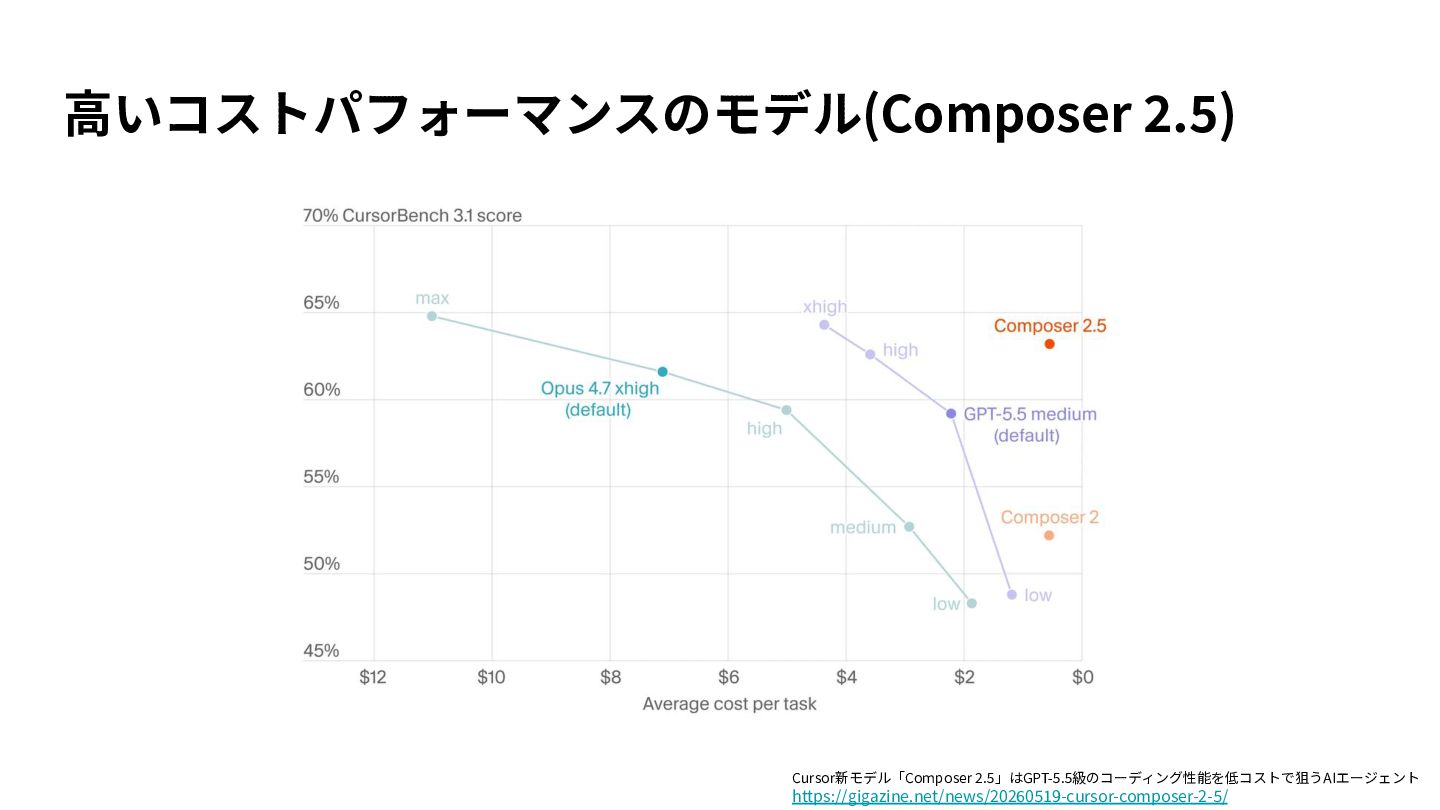{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}