semantico? teoria (regole) vs pratica (applicazione) come l’elettrotecnica, l’inglese, il javascript… ma è particolarmente noioso • Terza via: comprendere le ragioni soddisfazione e utilità si assimilano e si ricordano meglio le regole
• Trovabilità ⇔ Possesso: non trovare è come non avere, trovare è possedere? • Rendere trovabile: punto di vista “professionale” • Accessibilità e Ricerca: dipende da accessibilità e si ottiene con una ricerca (navigazione o “motore”)
in tempo utile • Progresso: conoscenza sempre più accessibile dal Nome della rosa al web… sommerso? • Società: accessibilità della conoscenza modella la società e viceversa (tutto o niente, specializzazione, un po’ di tutto per tutti: abbiamo visto cose...)
per scoperta (noto non significa necessariamente conosciuto) • Dove si colloca? non c’è soluzione di continuità: in qualche punto della scala • Più ricerche in parallelo: non siamo macchine sempre diversi interessi oltre al focus del momento => serendipity
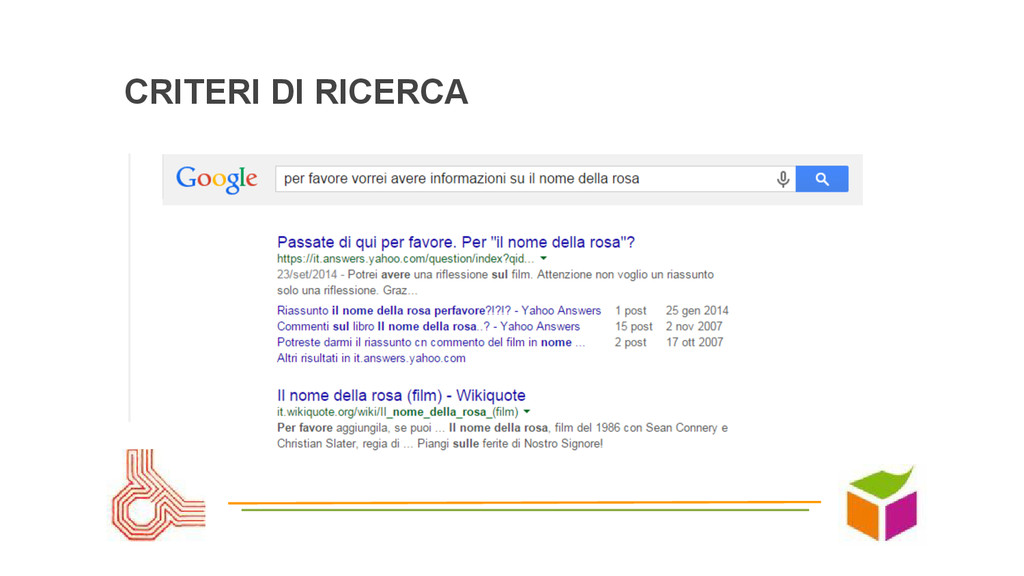
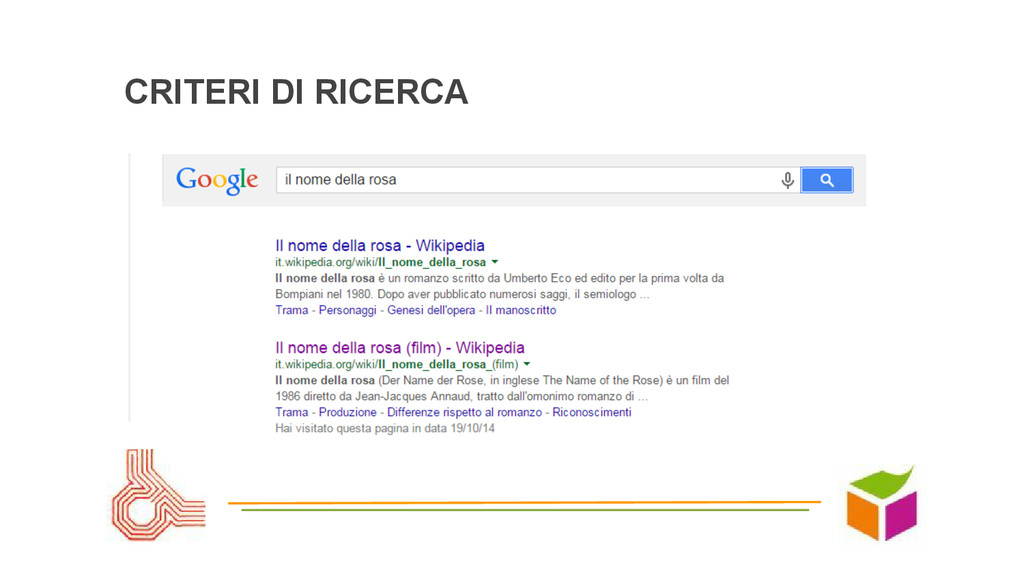
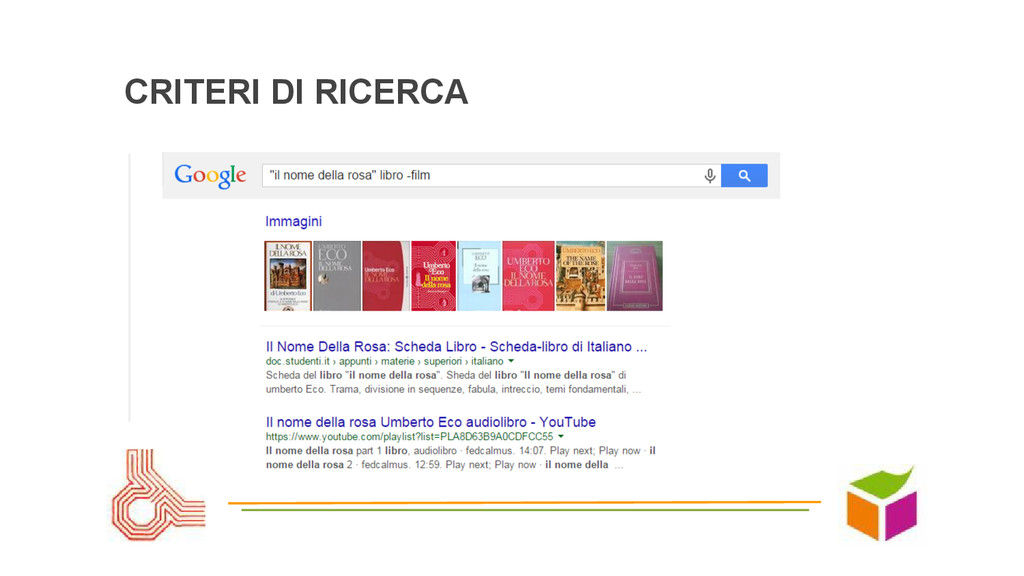
un’altra lingua, in un linguaggio formale: renderli espliciti... • Linguaggi formali vs. linguaggio “naturale”: rigidità ma controllo vs. semplicità “naturale” compreso o tollerato? • Interattività: autocomplete guida criteri e aiuta ricerca • Criteri scriteriati: soggettivi o errati (fraintendimenti, incoerenze, errori di ortografia)
chiamano gianni in ordine alfabetico SQL SELECT cognome FROM utenti WHERE nome=’gianni’ ORDER BY cognome ASC Solr /utenti/select?fl=cognome&q=gianni&sort=cognome asc MongoDB db.utenti.find({nome: 'gianni'}, {cognome: 1}).sort({cognome: 1})
e soli gli elementi pertinenti/rilevanti rispetto ai criteri • Valutazione: automatica e oggettiva è un paradosso • Ordinamento: la rilevanza non è assoluta score, fattore di pertinenza • Precisione o Recupero? ricerca o scoperta
centrale o solo utile (numero verde o assistenza a pagamento) • Più accessi, meno rimbalzi: sempre (da valutare se/come sfruttare le ricerche parallele fuori focus) • Più conversioni: una ricerca (interna o esterna) efficiente può essere il fine o il mezzo o addirittura controproducente (navigazione per simili, “taroccamenti”)
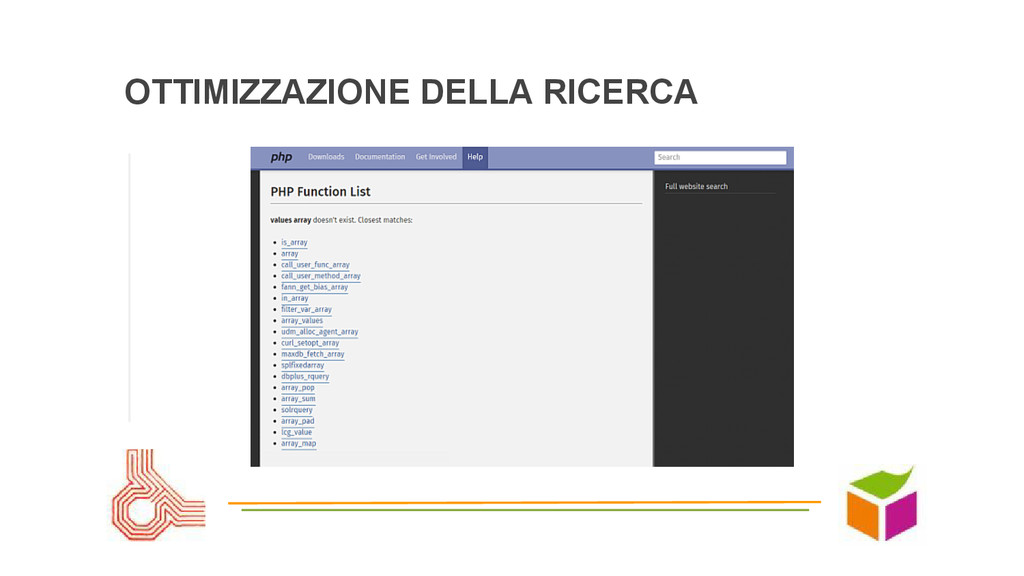
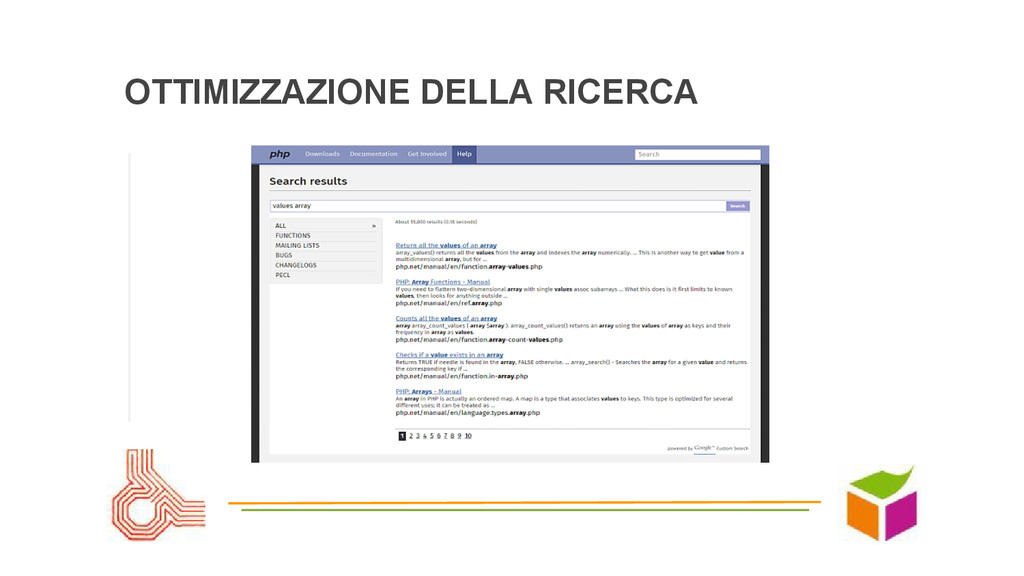
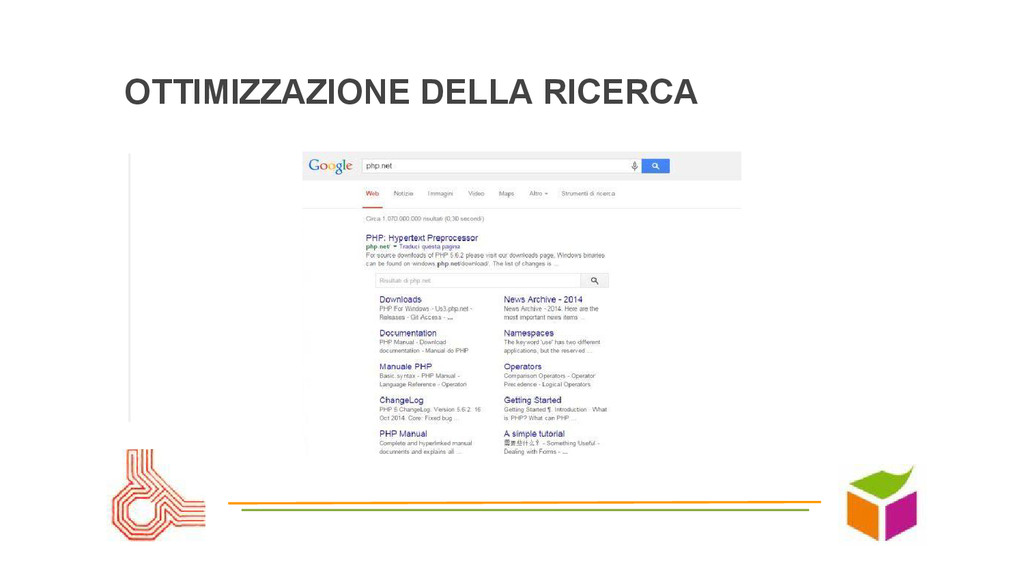
nel sito bravi come Google senza Google? Google vs. le ricerche interne: sembra facile ma è una sfida impossibile • SEO: far trovare il sito, far trovare i contenuti, seguire le regole... come e quali?
con i criteri di ricerca • Marcare i documenti già controllati stop se/quando trovato o tutti controllati; facile? • Ordinamento: riduzione tempi da N a log2N ma dispendioso, non esiste sempre ordinamento totale, solo per un criterio
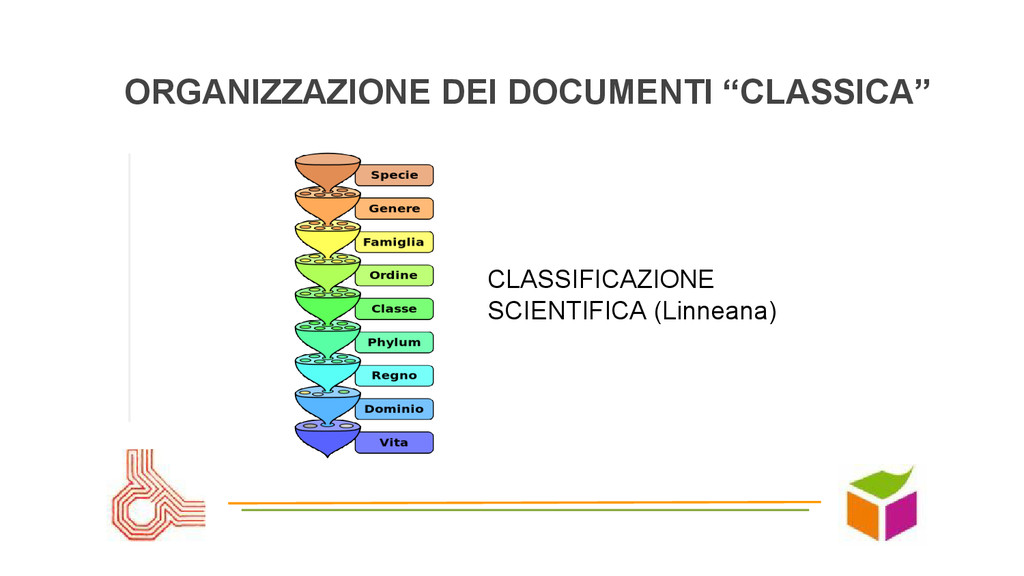
sottoclassi un solo posto per ogni cosa, predefinita da esperti, rigida e limitata (Google su Yahoo) • Composizione: mix di ordinamenti e classificazioni siti, librerie, videoteche: dipende da numero di elementi e priorità, ma il mix è l’unica strada
(blog, e- commerce, classified) • Faccette: caratteristiche e valori pre-conteggio risultati (e-commerce, classified) • Tag: folksonomie vs. tassonomie social, dal basso, destrutturazione e libertà, nuvole e elementi simili per calcolo pertinenza organizzare contenuti e risultati, da usare in modo proprio, sono diversi!
rilevanti precalcolate, puntamento all’ origine (indirizzo) • Cache: memoria parallela velocità ma disallineamento (invalidazione, refresh) • Ề indispensabile in molti contesti altrimenti tempi di risposta improponibili
esprime pertinenza per ordinamento dei risultati in base alla rilevanza • tf-idf: formula di base dalla teoria dell’information retrieval dipende dal contenuto informativo del termine = quanto è interessante (inverso della frequenza), distribuzione informatività (legge di zipf) f = c/i
(non solo quantità) idf interesse, quantità di informazione del termine = quanto è raro/significativo tf - idf term frequency – inverse document frequency
di importanza per facilitazione e miglioramento ricerca definibili se si ha controllo/gestione dei dati (ambito locale) • SEO: funziona se collaborazione interessata per avere strutturazione e riassunti nei documenti web (meta nascoste, quasi nascoste, markup… si può barare?)
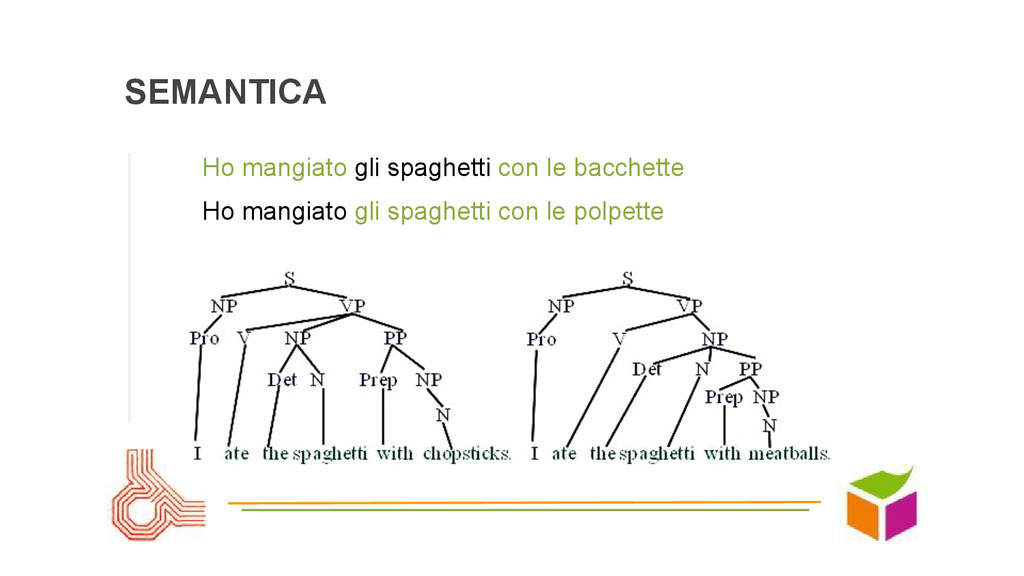
punteggi delle componenti in base all’ importanza (titolo vs testo...) • Conoscenza linguistica trattamento sinonimi e polisemia, stemming e declinazioni, stopwords ad hoc in base alla struttura • Semantica: struttura delle frasi per comprendere importanza dei termini (per favore vorrei trovare l’ultimo libro di…)
descrivere relazioni tra entità e le loro proprietà facilmente elaborabili • Ontologie: tassonomia delle entità rappresentabili e delle loro propretà definita a monte metadati => ontologia • Do ut des: l’autore ha l’onere di specificare i “giusti” metadati in cambio? • VS SEO: migliore contenuto informativo basta compromessi (es. h1)
proprietari (og:type, og:url) con valori specifici e predefiniti serve “per far capire a FaceBook” cosa si sta commentando/like • Grafo delle relazioni rappresenta le relazioni sociali inserite direttamente dagli utenti (piace, commenta, amico di) e ne può comprendere molte altre (leggo, visito, cucino)
e il più complesso • Documenti esterni alle pagine web quindi “scomodo” • Scritti in XML estensibile uso di namespaces • Asserzioni (statement) su risorse (entità) proprietà e valori di proprietà Resource Description Framework
web nei normali tag html • Usa attributi proprietari (typeof, property) con valori specifici e predefiniti definiti nei namespaces • Molto estensibile forse troppo... ma utilizzato e adottato Resource Description Framework in Attribute
come programmatore in Bakeca. </div> <div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Person"> Mi chiamo <span property="v:name">Flavio Portis</span>, lavoro come <span property="v:title">programmatore</span> in <span property="v:affiliation">Bakeca.it</span>. </div>
come programmatore in Bakeca.it. </div> <div class="vcard"> Mi chiamo <span class="fn">Flavio Portis</span>, lavoro come <span class="title">programmatore</span> in <span class="org">Bakeca.it</span>. </div>
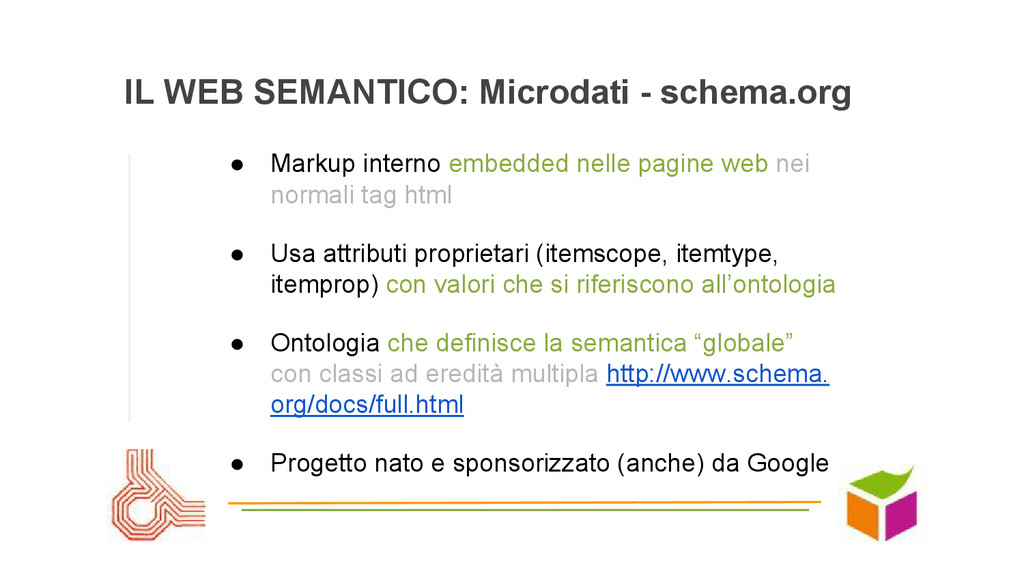
nelle pagine web nei normali tag html • Usa attributi proprietari (itemscope, itemtype, itemprop) con valori che si riferiscono all’ontologia • Ontologia che definisce la semantica “globale” con classi ad eredità multipla http://www.schema. org/docs/full.html • Progetto nato e sponsorizzato (anche) da Google
Portis, lavoro come programmatore in Bakeca.it. </div> <div itemscope itemtype="http://schema.org/Person"> Mi chiamo <span itemprop="name">Flavio Portis</span>, lavoro come <span itemprop="title">programmatore</span> in <span itemprop="affiliation">Bakeca.it</span>. </div>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected]](https://files.speakerdeck.com/presentations/e413e310463f013234d17a3f7c519e69/slide_49.jpg){kind=link}