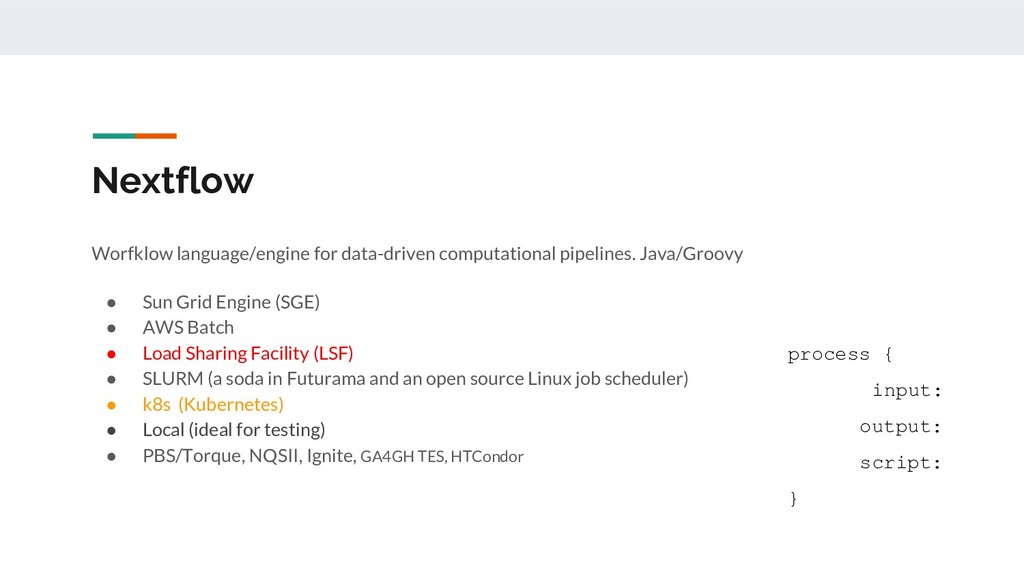
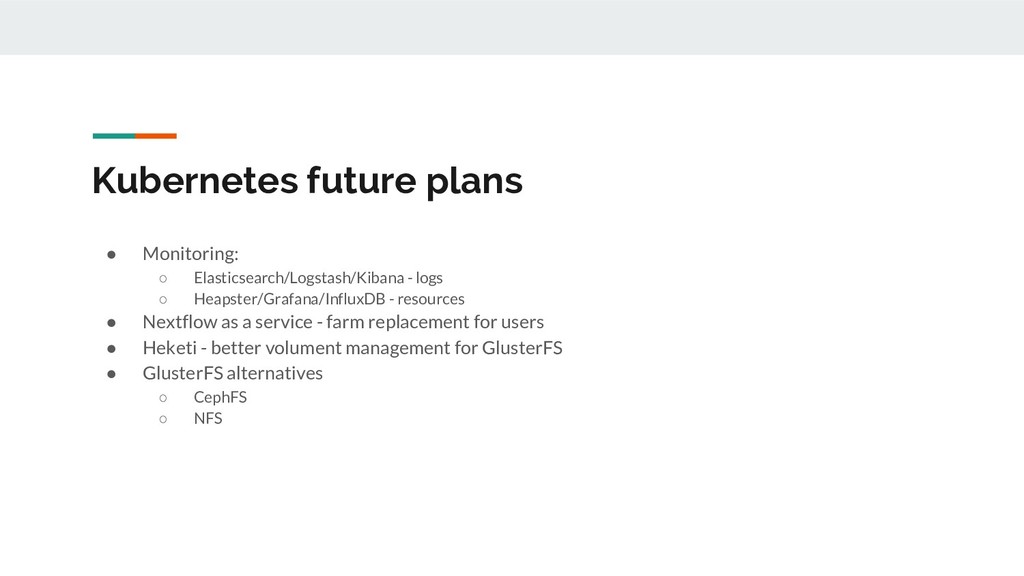
Grid Engine (SGE) • AWS Batch • Load Sharing Facility (LSF) • SLURM (a soda in Futurama and an open source Linux job scheduler) • k8s (Kubernetes) • Local (ideal for testing) • PBS/Torque, NQSII, Ignite, GA4GH TES, HTCondor process { input: output: script: }
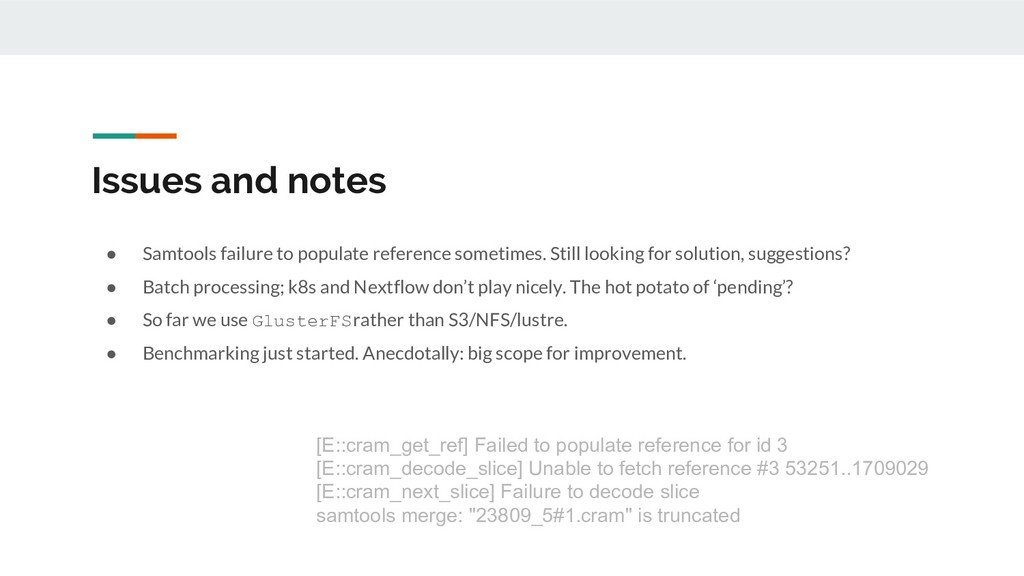
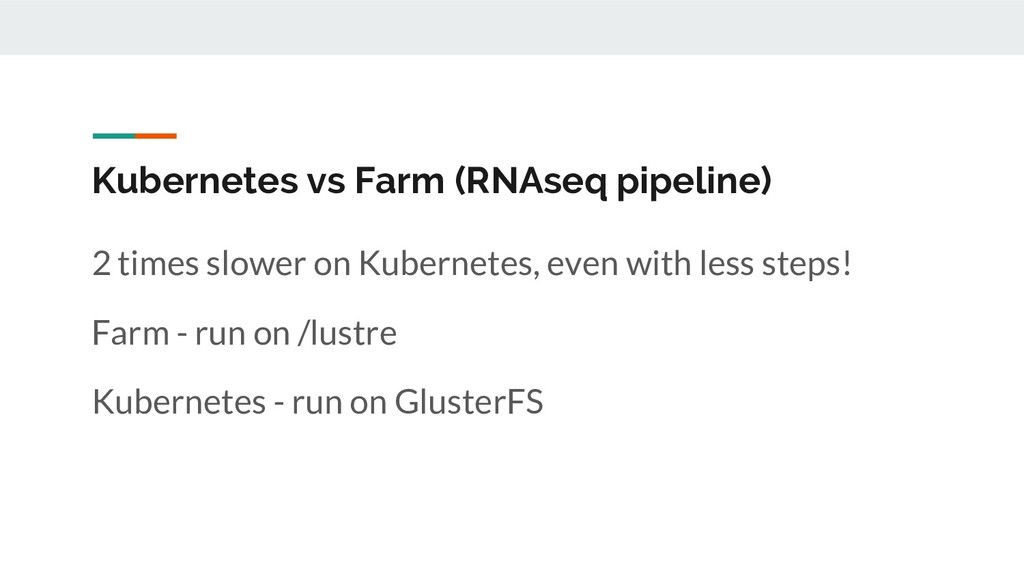
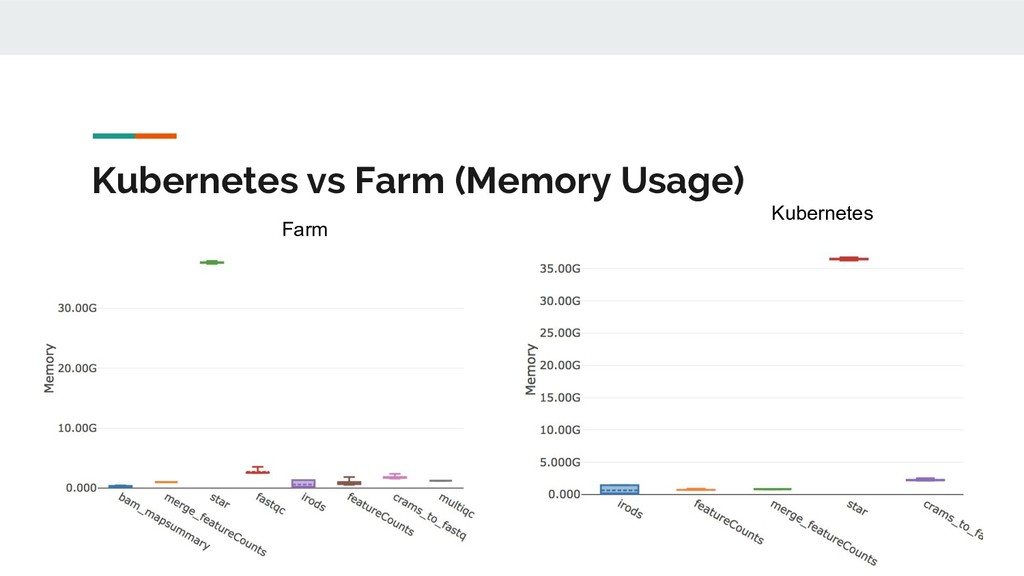
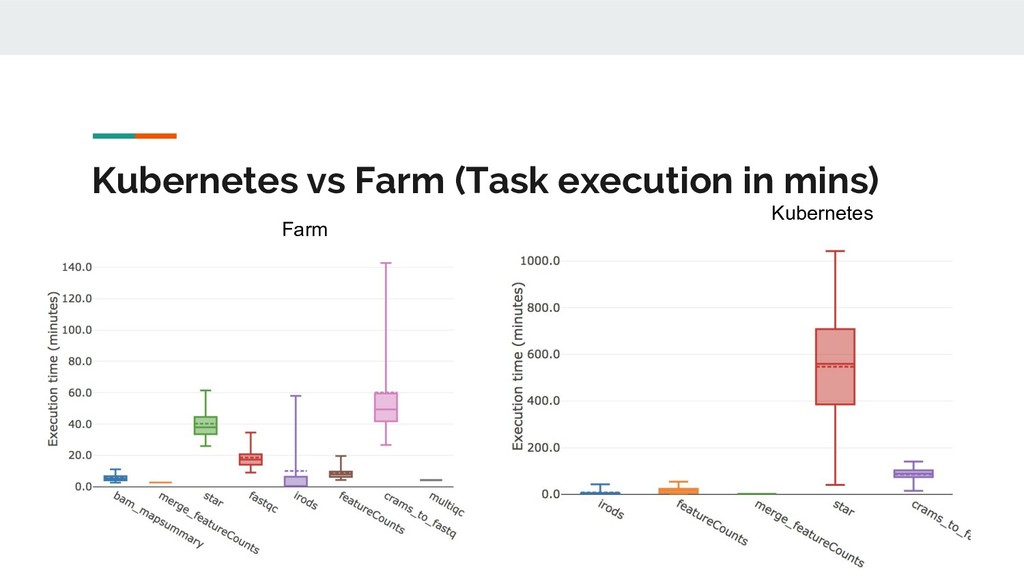
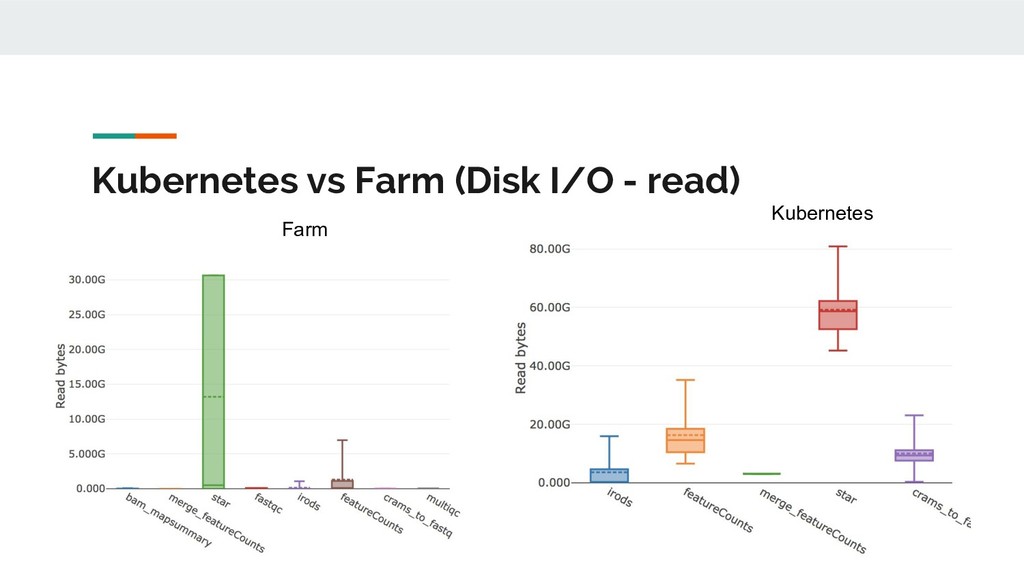
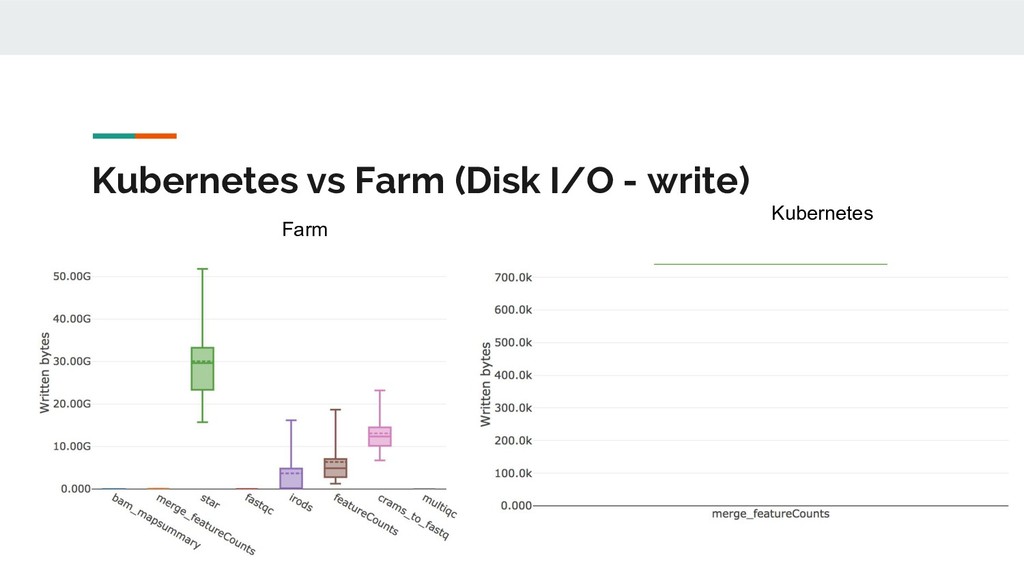
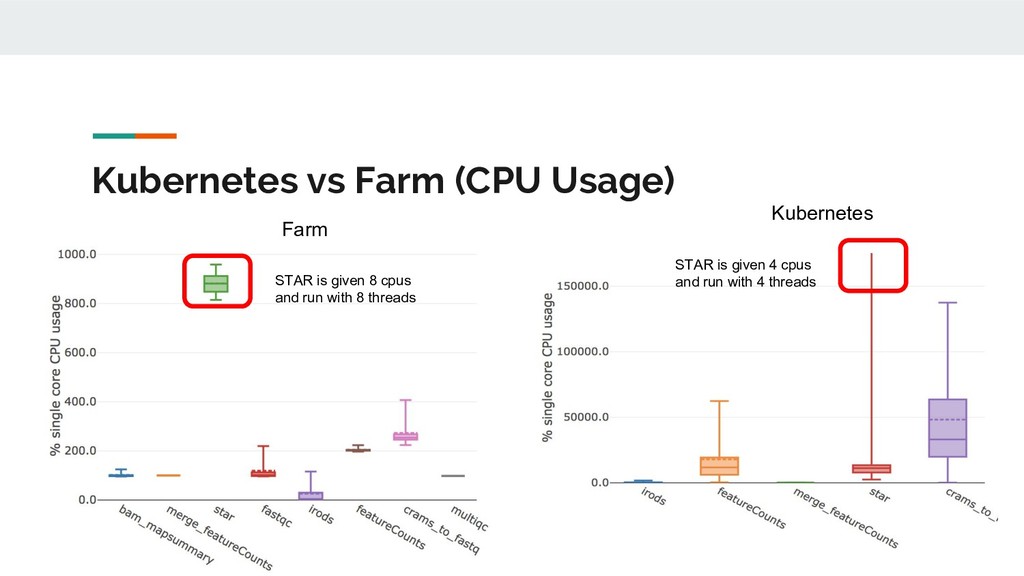
Still looking for solution, suggestions? • Batch processing; k8s and Nextflow don’t play nicely. The hot potato of ‘pending’? • So far we use GlusterFS rather than S3/NFS/lustre. • Benchmarking just started. Anecdotally: big scope for improvement. [E::cram_get_ref] Failed to populate reference for id 3 [E::cram_decode_slice] Unable to fetch reference #3 53251..1709029 [E::cram_next_slice] Failure to decode slice samtools merge: "23809_5#1.cram" is truncated
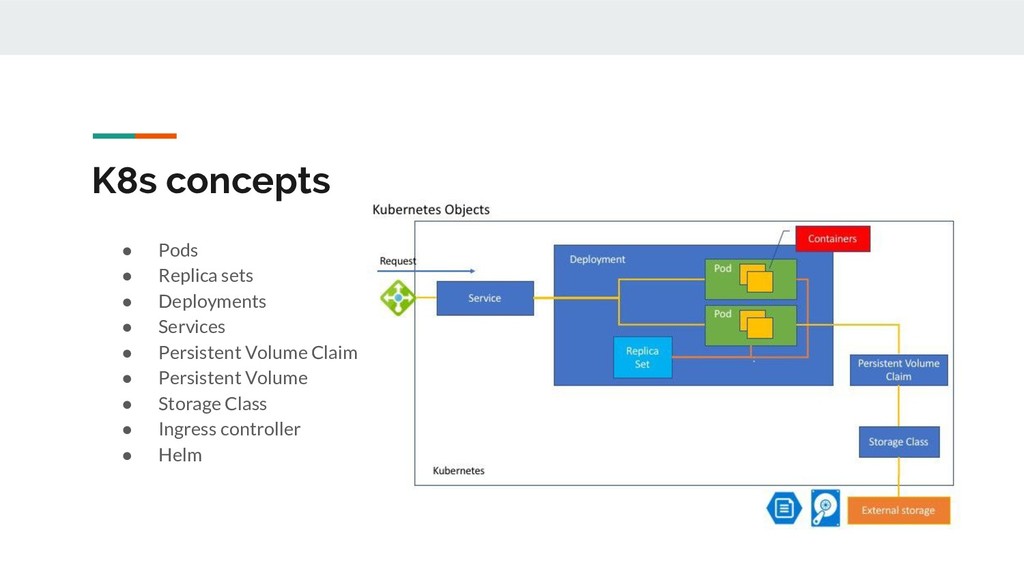
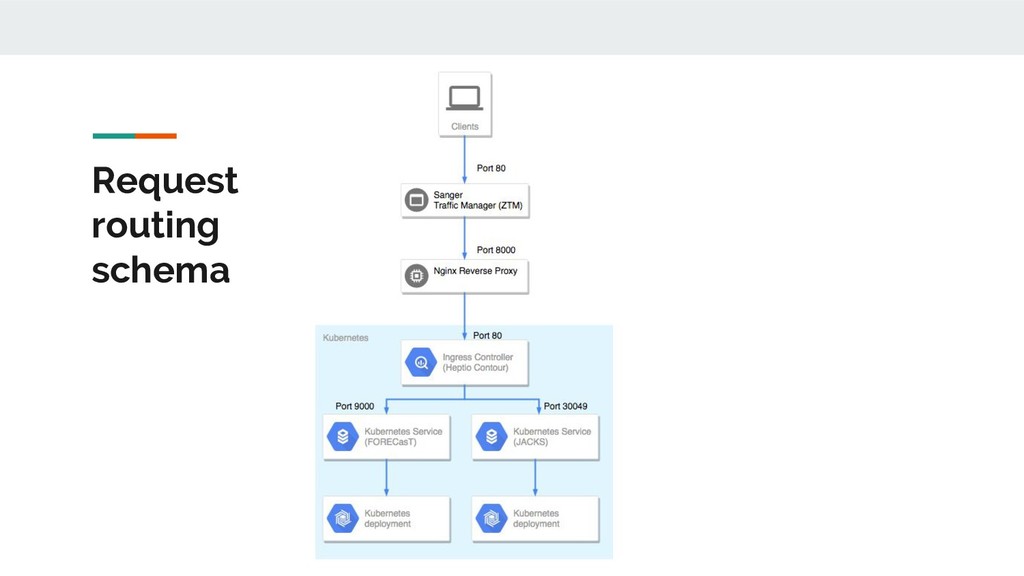
▪ Deployment ▪ Service ▪ Persistent Volume Claims ▪ Persistent Volumes 3. Create Ingress record 4. Create Nginx record 5. Create Infoblox DNS record 6. [for public access] Web team approval
auto scaling • Cloud provider independent • Resources efficiently utilized • Complex projects are easy to share and get running (via helm charts) • Vast community and knowledge base Cons: • Fresh cluster setup long and expertise demanding // we’ve been there for you, now you can run it on FCE in 20 min: https://github.com/cellgeni/kubespray • Significant learning curve • Limited SSL and Ingress management
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}