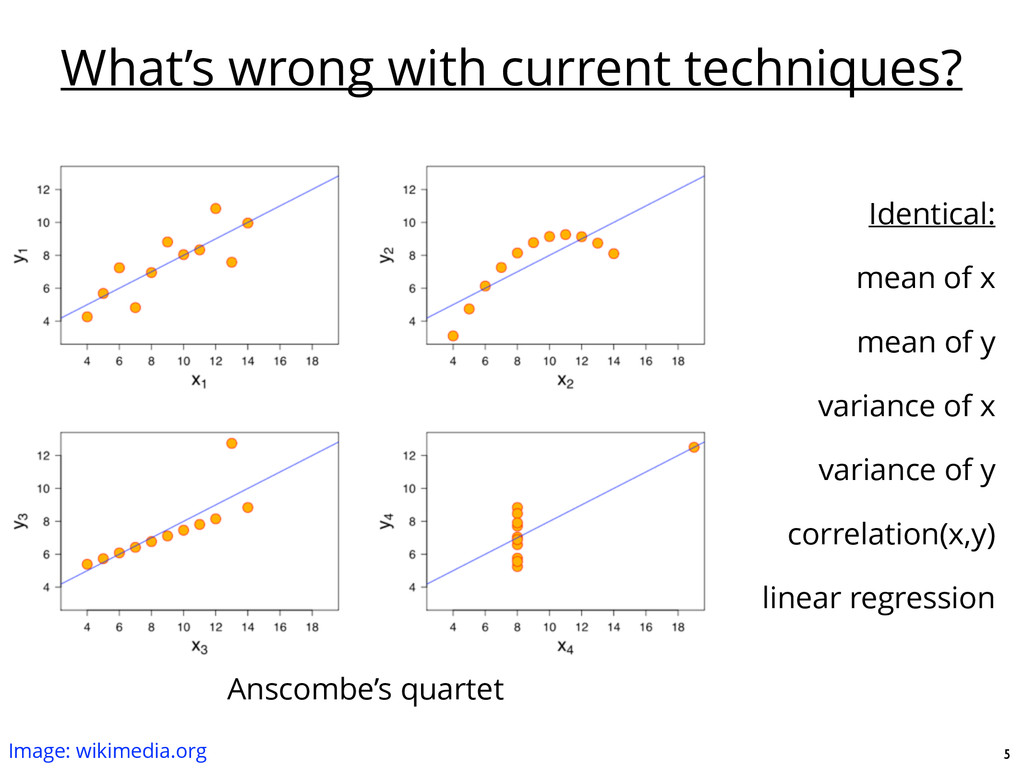
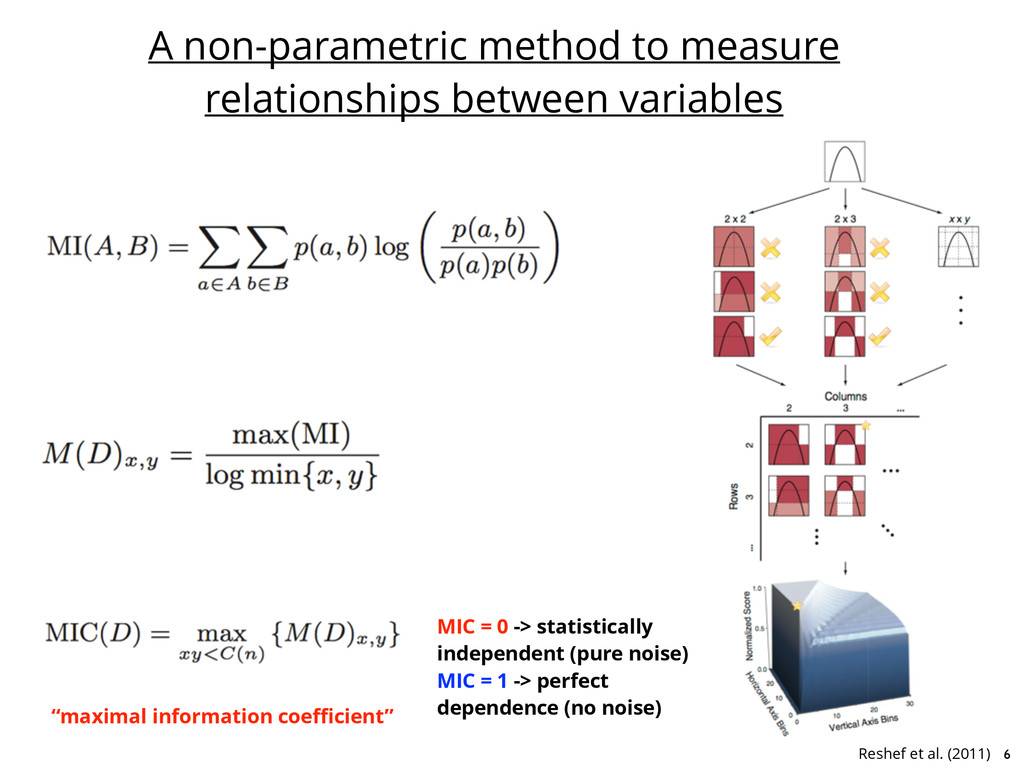
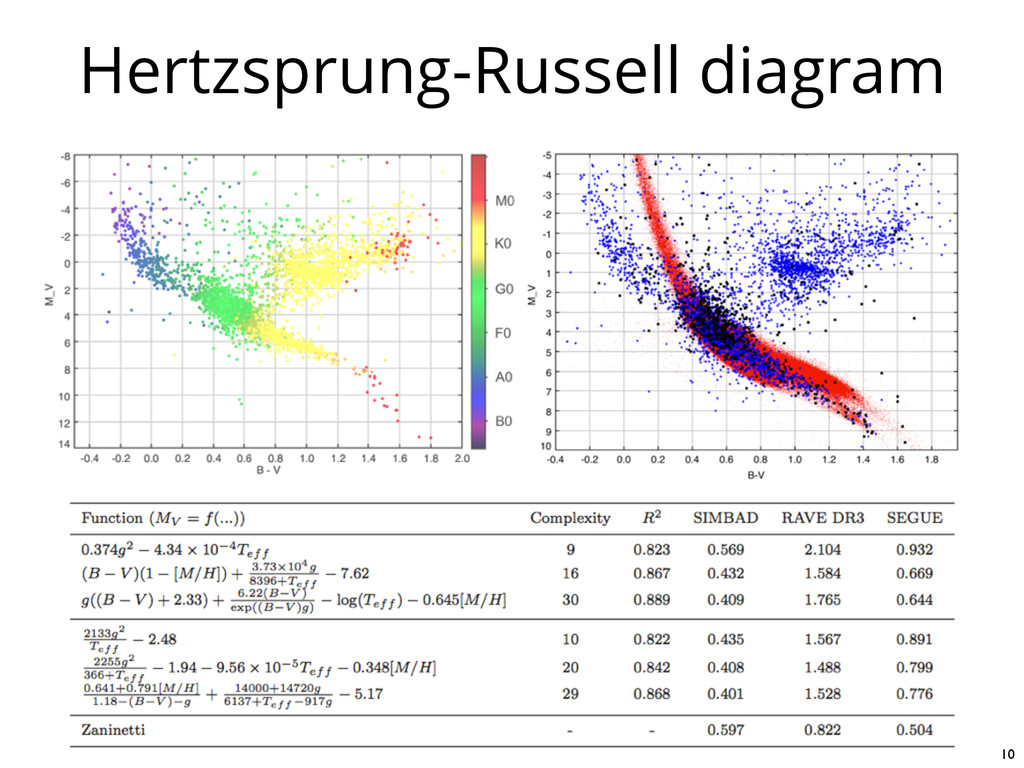
datasets is non-trivial • New algorithms and software have now successfully reproduced known astronomical results • Interpretation and evaluation of physical significance are still roles for human scientists 3
be producing data with: • many thousands of parameters per object • millions to billions of objects • time-domain observations • tens of TB of data NIGHTLY • Discovering the full set of physical relationships in such large catalogs are not possible for humans alone - we need help. 4
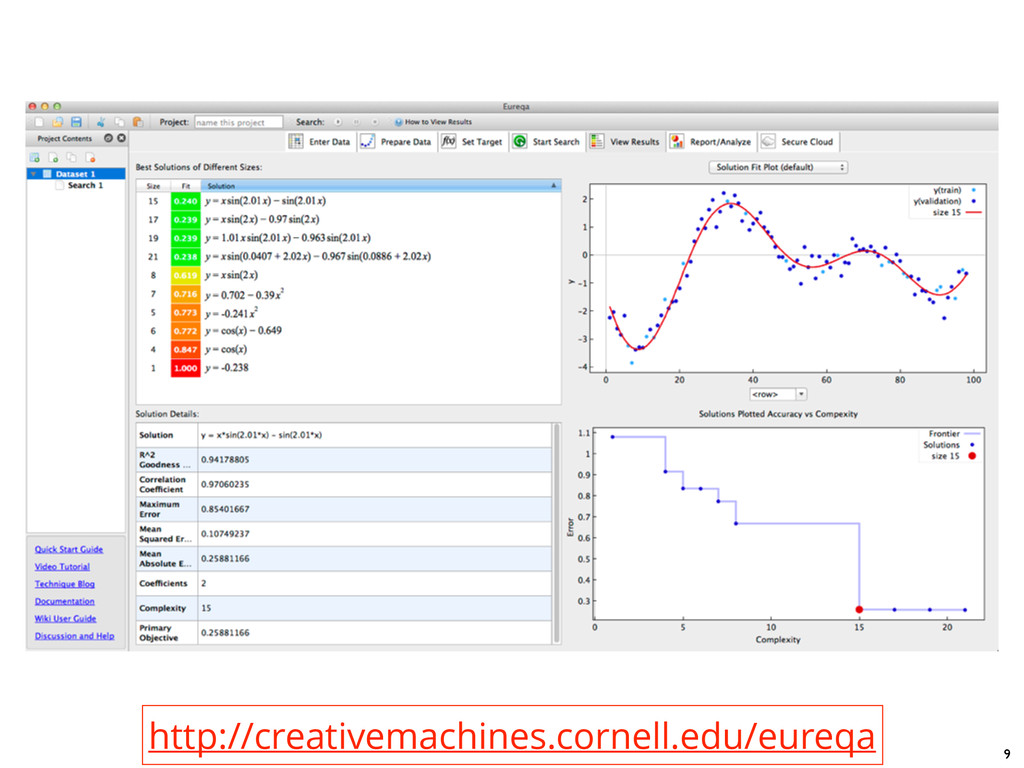
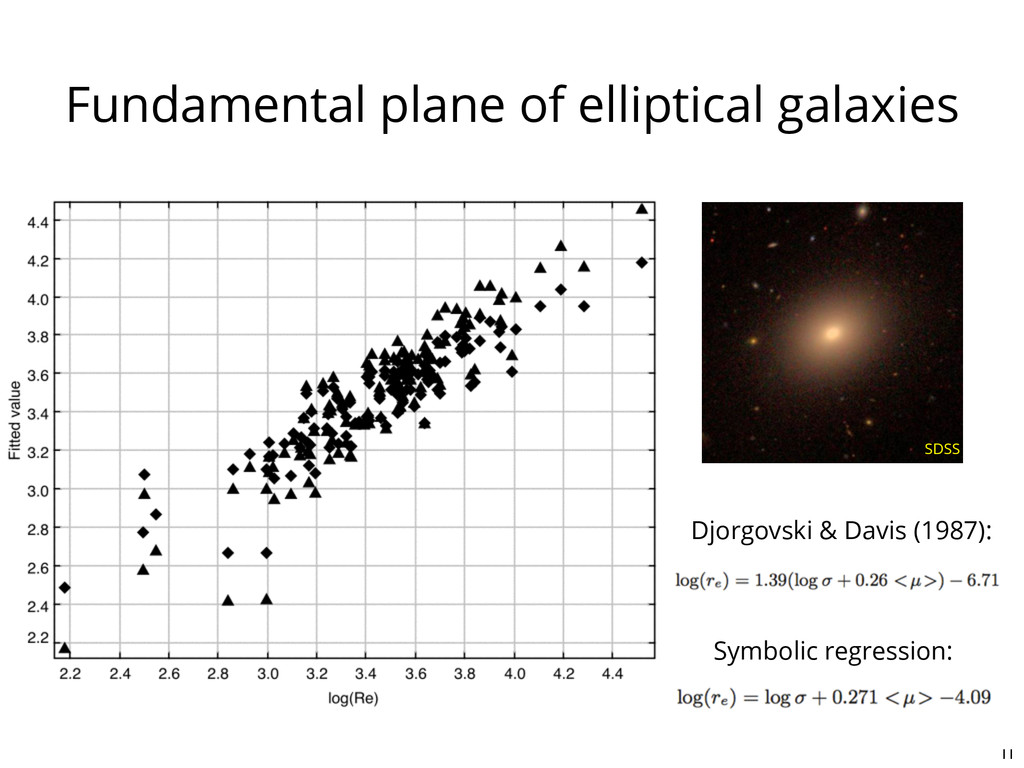
1.Load a data set 2.Choose the functional form of the relationship to model 3.Select possible mathematical building blocks 4.Use genetic algorithms to explore the metric space and find invariant quantities 5.Output a list of potential fits, ranked according to both accuracy and complexity +-, */, sin(), log(), etc. z = f(x,y) split into “training” and “validation” subsets
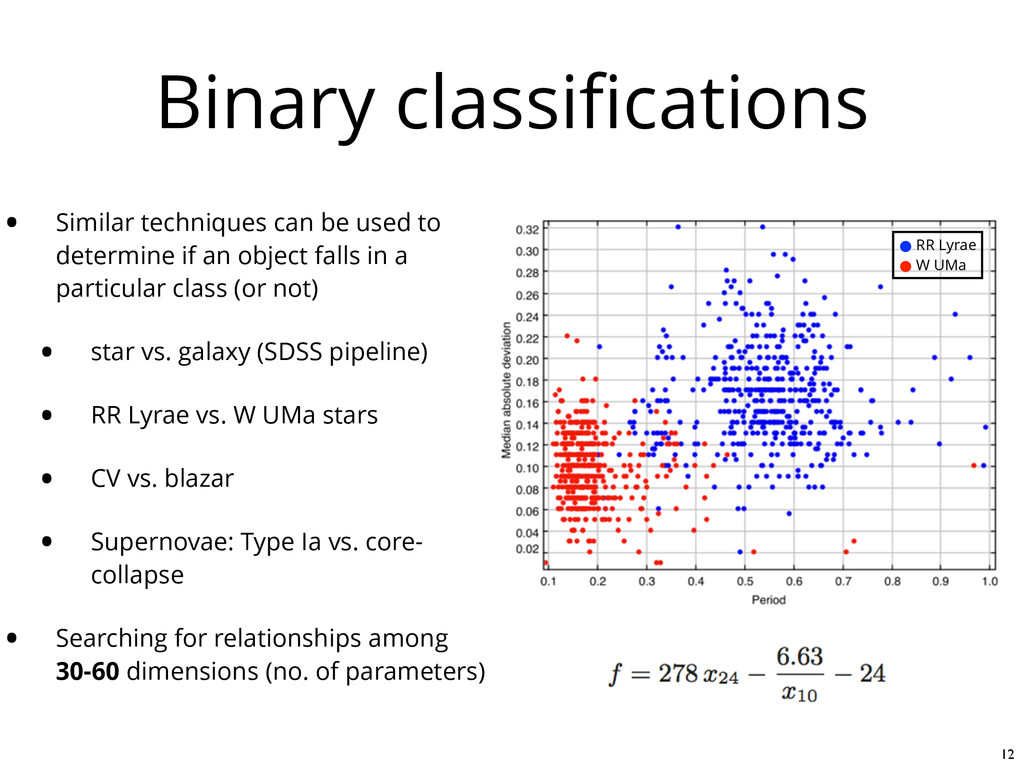
if an object falls in a particular class (or not) • star vs. galaxy (SDSS pipeline) • RR Lyrae vs. W UMa stars • CV vs. blazar • Supernovae: Type Ia vs. core- collapse • Searching for relationships among 30-60 dimensions (no. of parameters) 12 RR Lyrae W UMa
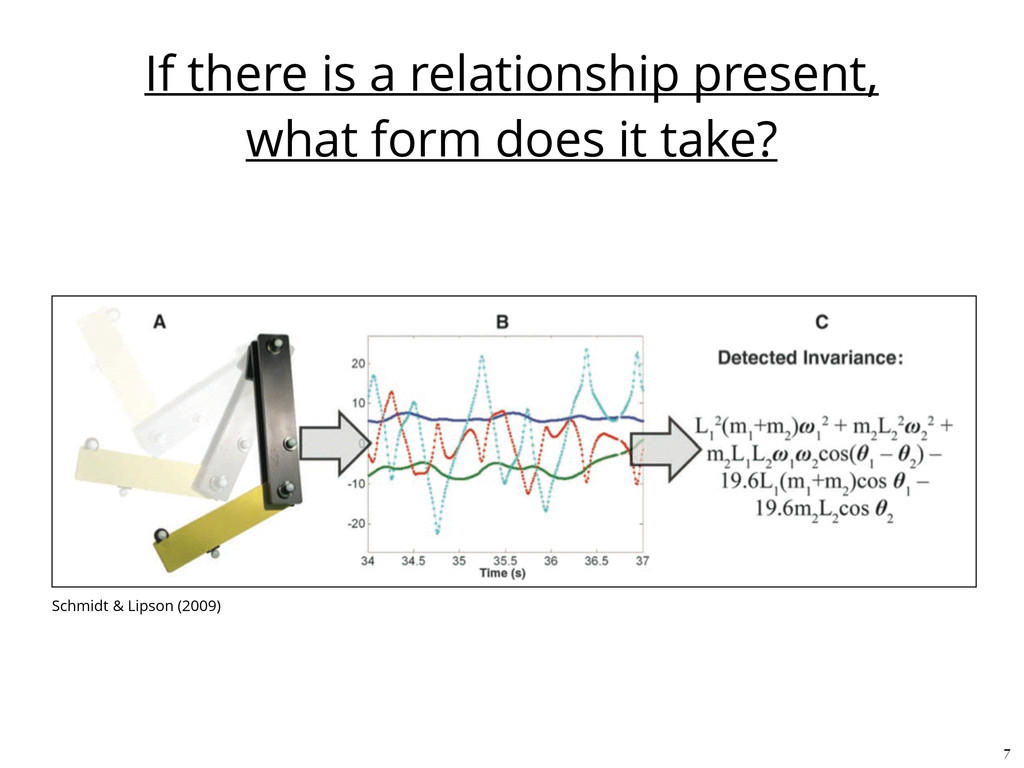
different results for the same input. • Efficient discovery requires prepared datasets, choices of variables, weighting, and fit metrics, and guesses to functional forms • Methods only apply for invariant quantities expressible as partial differential equations. Will not work for: • fractal behavior • chaotic or stochastic activity • Current statistics are still limited to bivariate relationships 13
datasets is non-trivial • These tools will be necessary to fully analyze the data from LSST and SKA • New algorithms and software have now successfully reproduced known astronomical results • MIC: identifying non-parametric measure of dependence for pairs of variables • Symbolic regression: rank their functional forms and fit coefficients • Interpretation and evaluation of physical significance are still roles for human scientists • The discovery process is becoming machine-assisted, but we still need astrophysics to supply the data, analyze results, and provide context. 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}