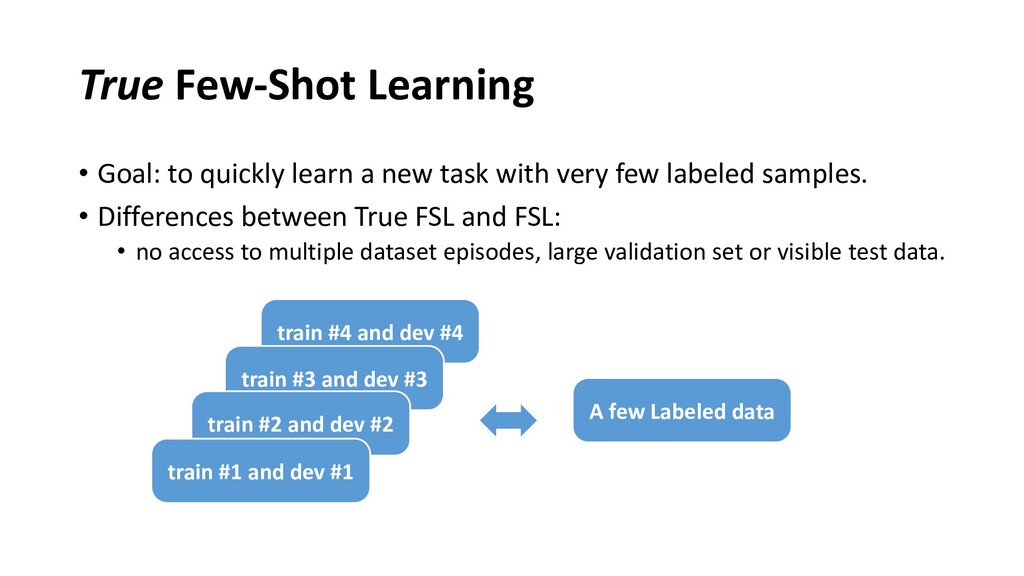
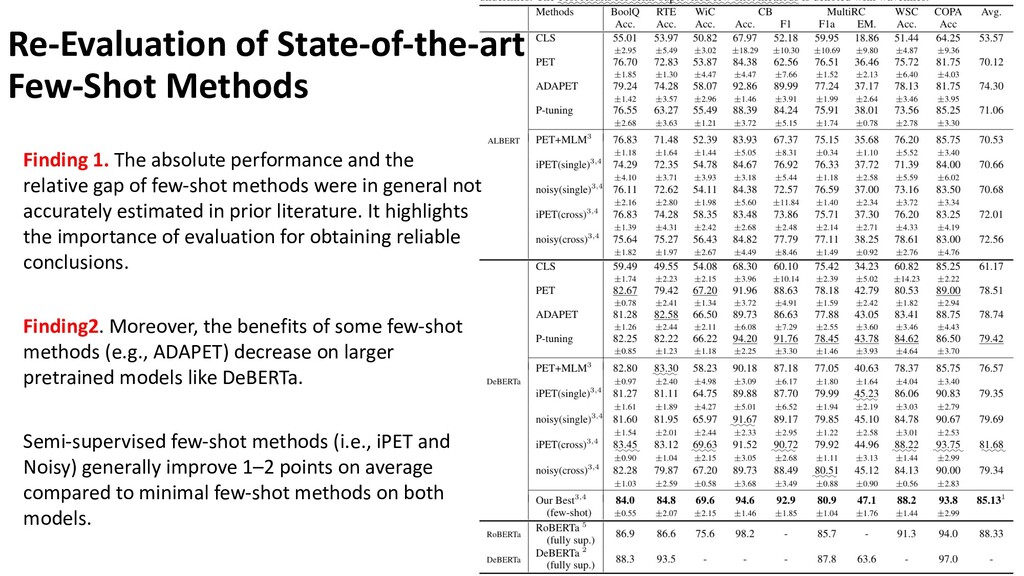
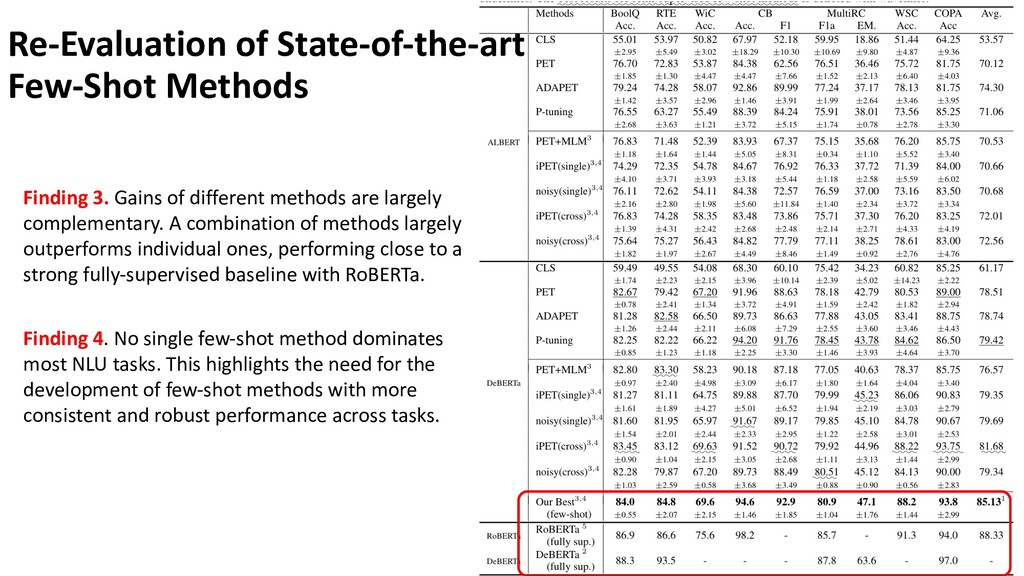
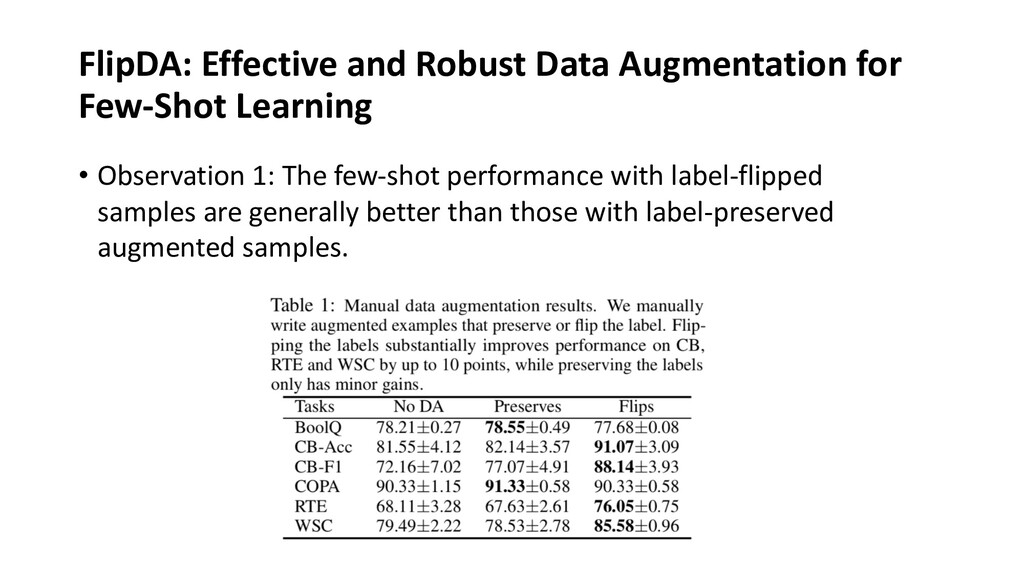
The few-shot learning has attracted much recent attention in the NLP community, which addresses a more practical real-world scenario when fully-supervised labels are insufficient. A key challenge lies in that prior research has been proceeding under an impractical assumption, and evaluated under a disparate set of protocols, which hinders fair comparison and measuring the progress of the field. This talk covers recent advances in few-shot learning for natural language understanding. I will first identify problems of few-shot assumptions and evaluation protocols, and then introduce and justify a practical way of few-shot evaluation. Next, by re-evaluating state-of-the-art methods on common ground, I will come to several key findings that reveal problems of the field. Finally, I will introduce several possible solutions in terms of how to improve few-shot robustness and performance.
Seminar page: https://wing-nus.github.io/ir-seminar/speaker-yanan
YouTube Video recording: https://www.youtube.com/watch?v=HppFsw9E50M
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}