Relaxed Co-Scheduling [VMware ’10] ◆ Co-schedule all vCPUs of the same VM ◆ Expensive to implement and causes CPU fragmentation ▪ Guest OS-assisted: Delay Scheduling [Uhlig+, VM ’04] ◆ Guest OS notifies the hypervisor before acquiring a spin-lock and hypervisor delays preemption to avoid LHP and LW ◆ Hypervisor need to deviate from its existing scheduling algorithm ▪ Hardware-assisted: Intel Pause-Loop Exiting (PLE) [Riel ’11] ◆ Detect excessive spinning and prevent a VM from wasting CPU cycles Prior Works 4
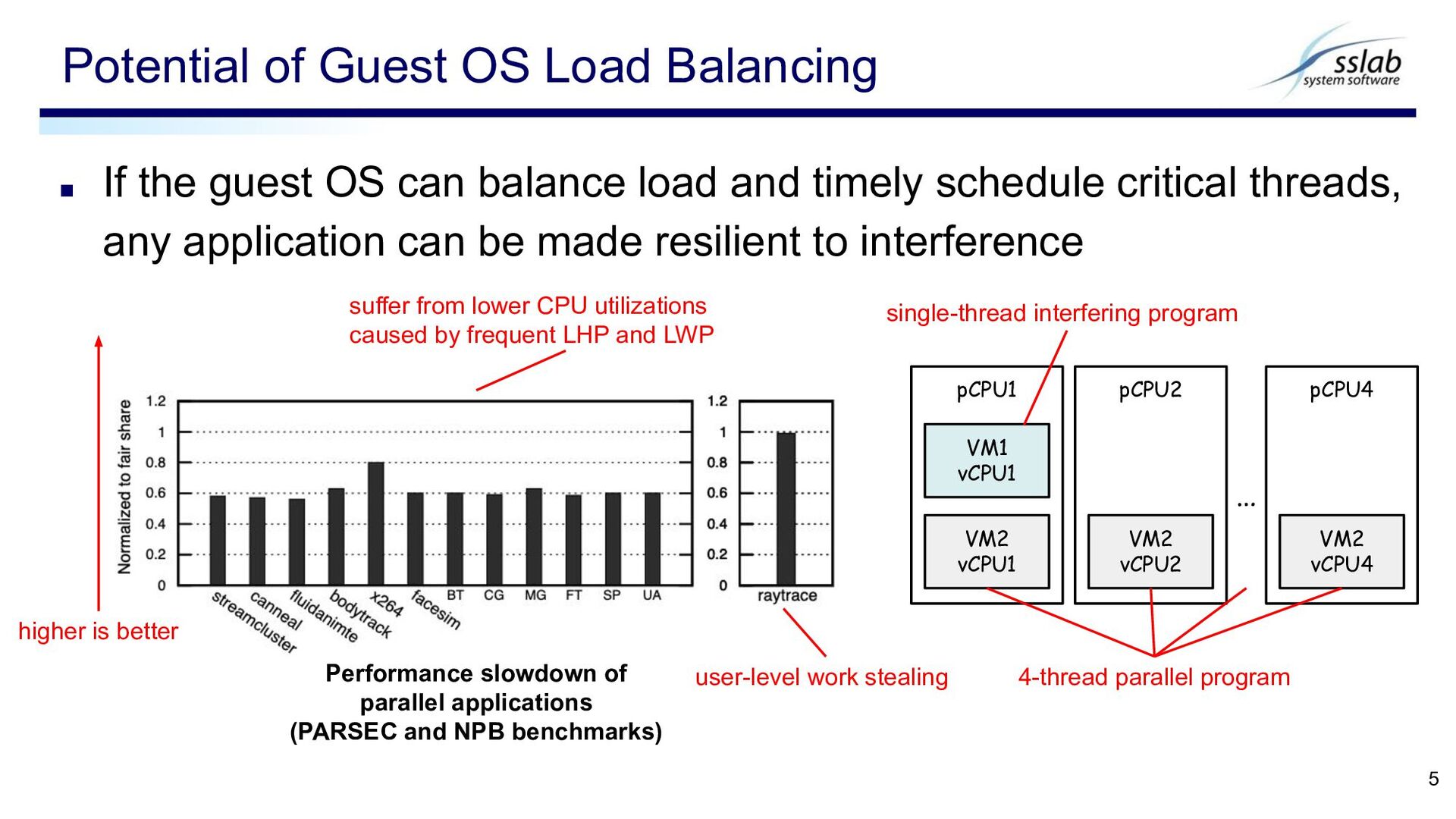
schedule critical threads, any application can be made resilient to interference Potential of Guest OS Load Balancing 5 suffer from lower CPU utilizations caused by frequent LHP and LWP user-level work stealing Performance slowdown of parallel applications (PARSEC and NPB benchmarks) pCPU1 VM2 vCPU1 VM1 vCPU1 pCPU2 VM2 vCPU2 pCPU4 VM2 vCPU4 … higher is better single-thread interfering program 4-thread parallel program
OS migrates the critical thread on this vCPU to another running vCPU ▪ Motivation & Objective ▪ Inspired by Scheduler Activation [Anderson+, TOCS ’92] ▪ Minimize interference-induced idling and CPU waste Proposal: Interference-Resilient Scheduling (IRS) 6
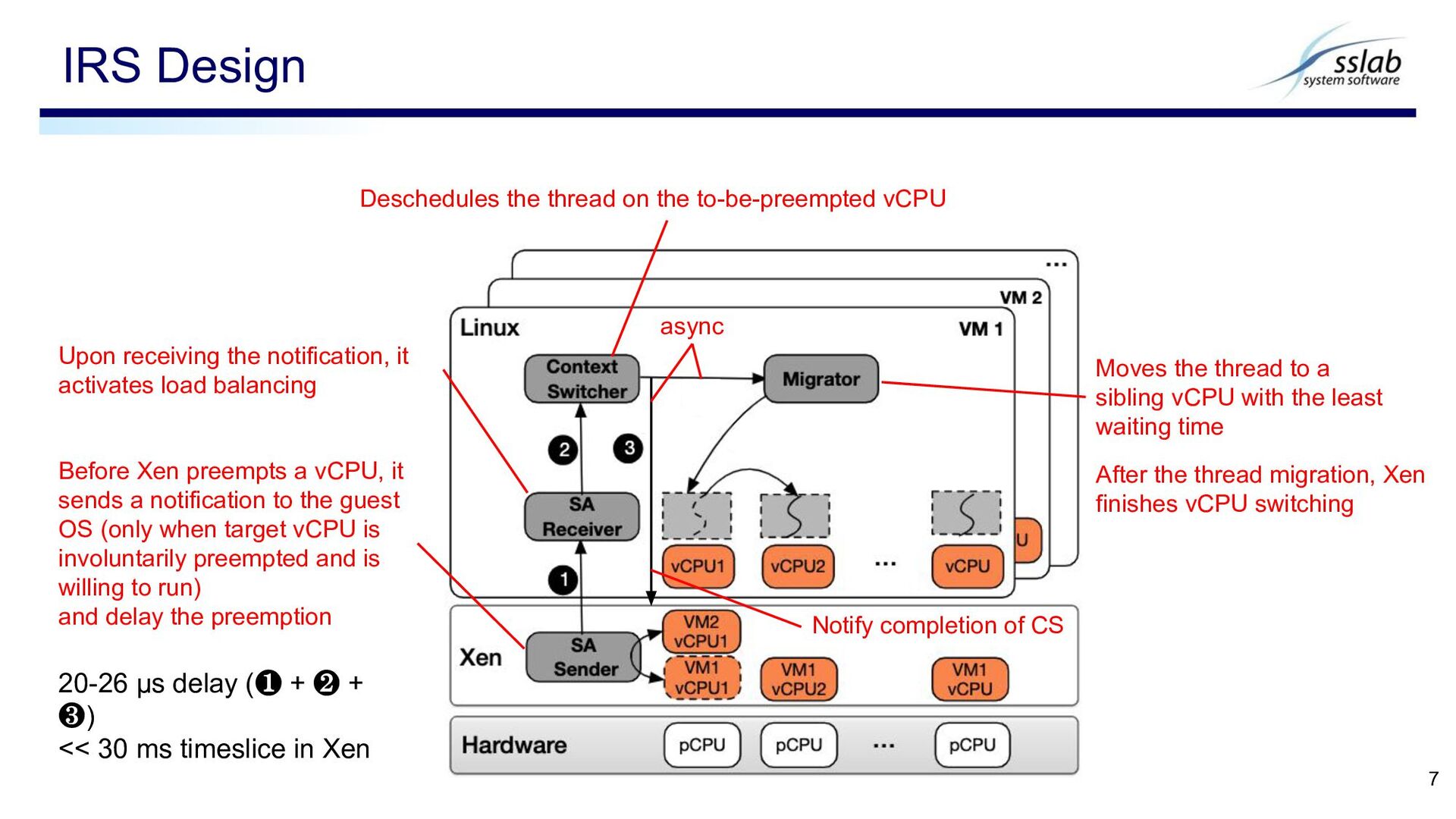
a notification to the guest OS (only when target vCPU is involuntarily preempted and is willing to run) and delay the preemption Upon receiving the notification, it activates load balancing Deschedules the thread on the to-be-preempted vCPU Moves the thread to a sibling vCPU with the least waiting time After the thread migration, Xen finishes vCPU switching 20-26 μs delay (❶ + ❷ + ❸) << 30 ms timeslice in Xen async Notify completion of CS
in pCPUs ▪ Balance load and ensure cache locality when preempted vCPUs come back ▪ Approach ▪ Estimate vCPU load based on rt_avg which considers steal time ▪ Allow the wakeup balancer preempt the current task if it was migrated by IRS Migrator 8 vCPU1 pCPU0 pCPU1 thread1 thread2 Other VM thread1 thread2 vCPU2 vCPU2 vCPU1 vCPU1 preempted migrated by IRS thread2 migrated by wakeup balancer enter critical section blocked thread2 wakes up Simple IRS Approach IRS Approach vCPU1 pCPU0 pCPU1 thread1 thread2 Other VM thread1 thread2 vCPU2 vCPU2 vCPU1 vCPU1 preempted migrated by IRS thread1 migrated by periodic balancer enter critical section blocked thread2 wakes up cache polluted!! thread1 vCPU2 : critical section
▪ Xen: 30 LOC ▪ Linux kernel: 130 LOC ▪ Hypervisor-guest communication uses Xen’s event channel ▪ SA sender: send notification with virtual interrupt (vIRQ) ▪ SA receiver: implemented as an interrupt handler Implementation 9
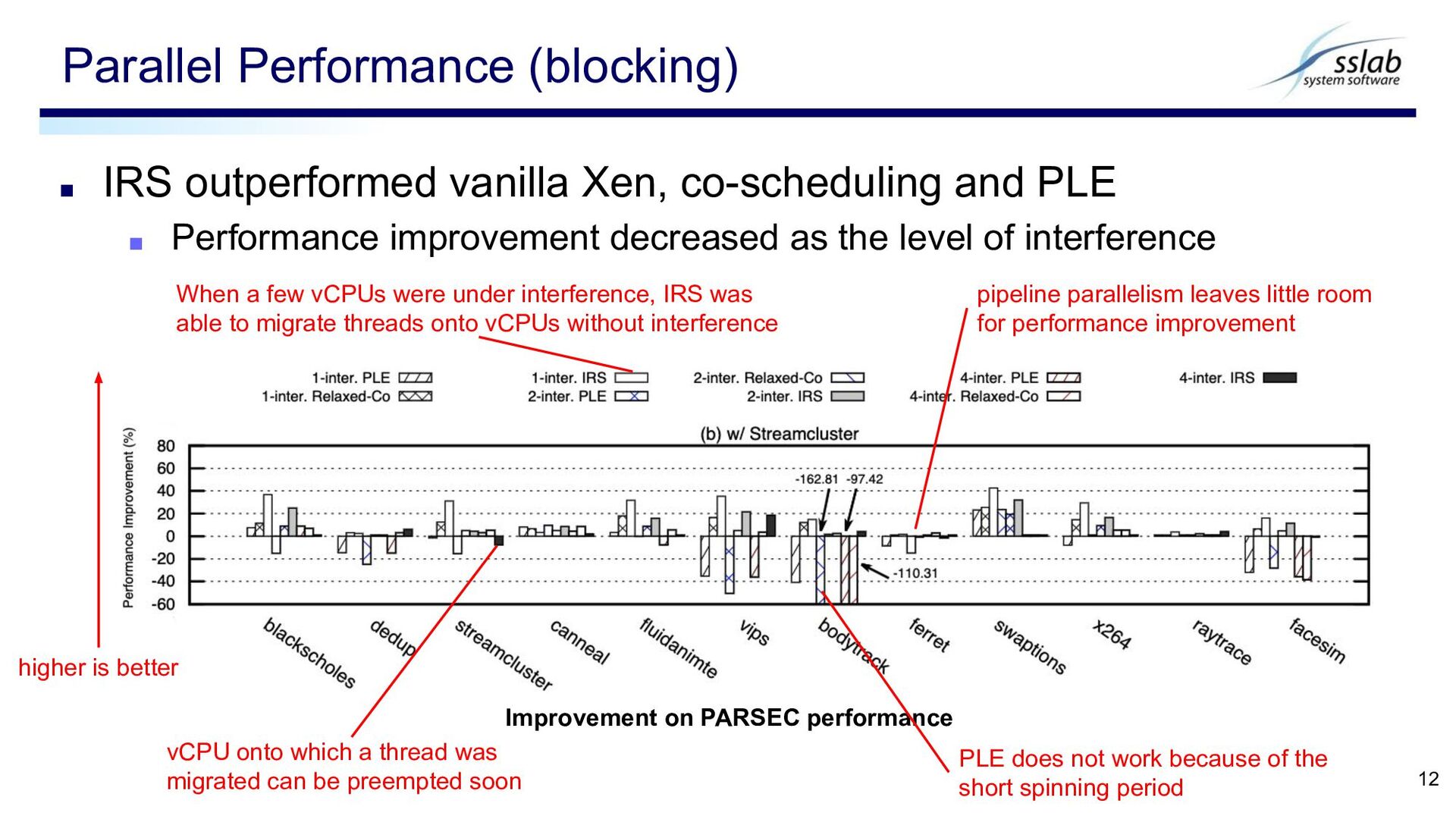
improvement decreased as the level of interference Parallel Performance (blocking) 12 Improvement on PARSEC performance higher is better vCPU onto which a thread was migrated can be preempted soon When a few vCPUs were under interference, IRS was able to migrate threads onto vCPUs without interference pipeline parallelism leaves little room for performance improvement PLE does not work because of the short spinning period
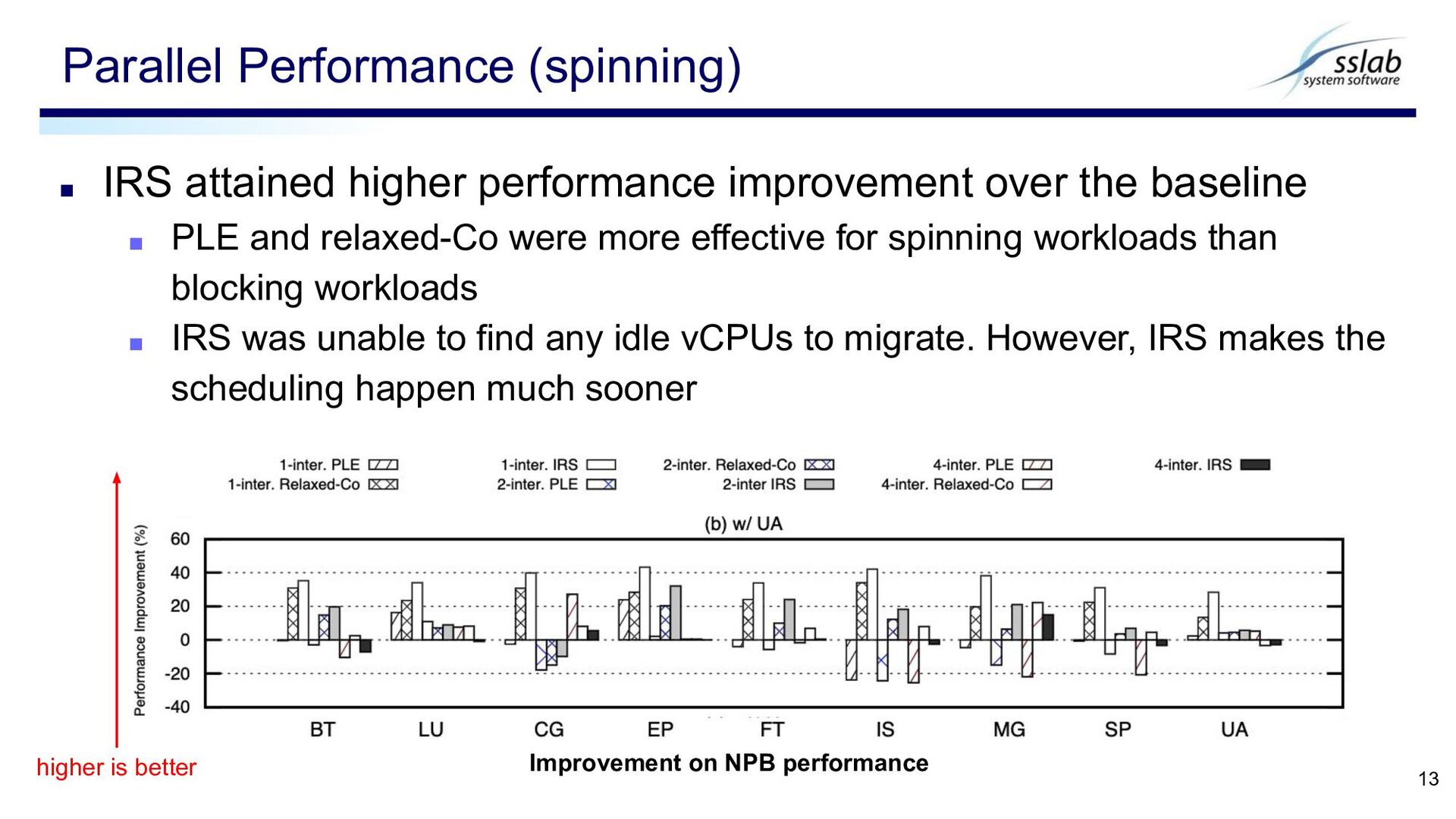
PLE and relaxed-Co were more effective for spinning workloads than blocking workloads ▪ IRS was unable to find any idle vCPUs to migrate. However, IRS makes the scheduling happen much sooner Parallel Performance (spinning) 13 Improvement on NPB performance higher is better
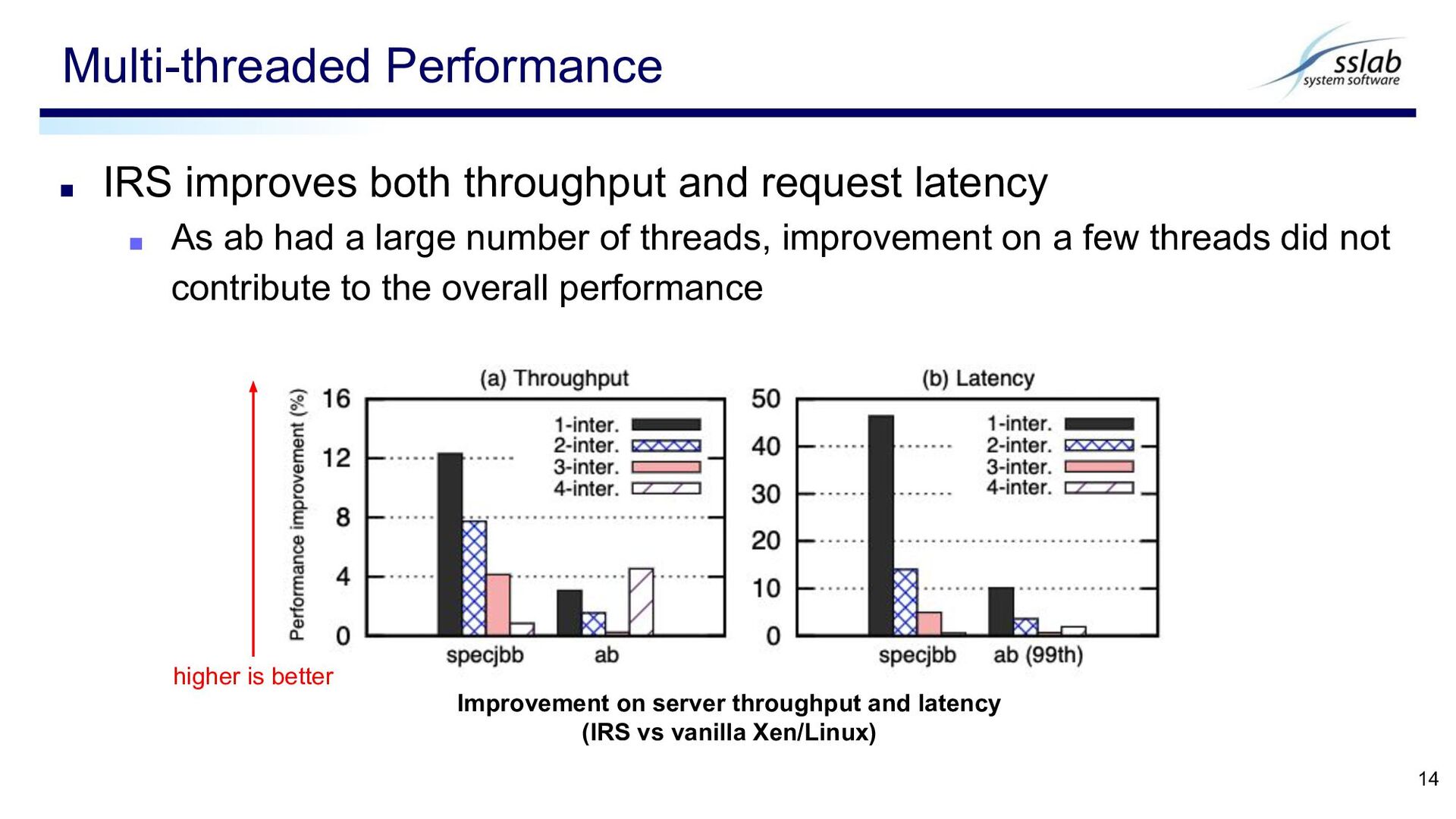
ab had a large number of threads, improvement on a few threads did not contribute to the overall performance Multi-threaded Performance 14 Improvement on server throughput and latency (IRS vs vanilla Xen/Linux) higher is better
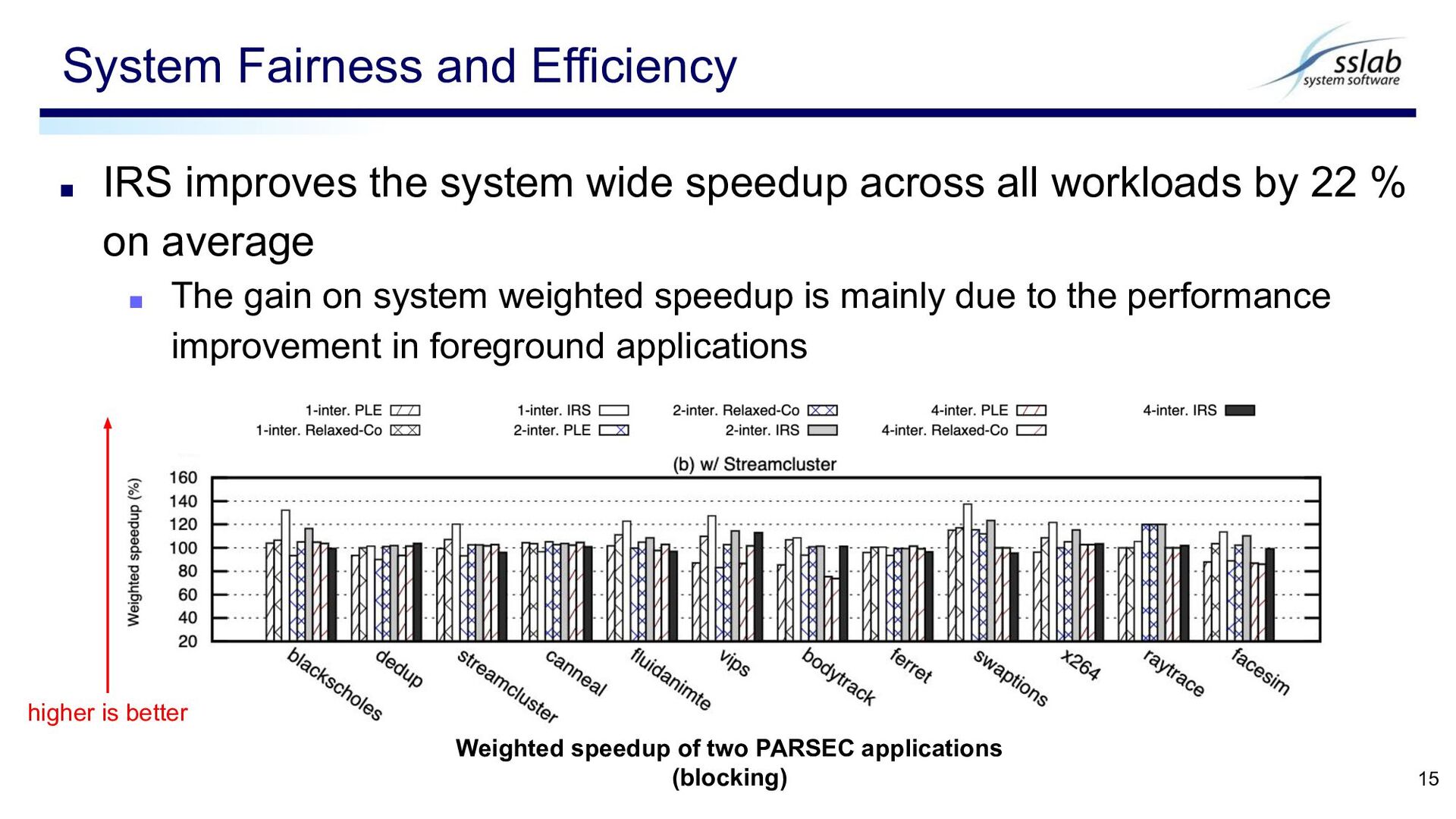
by 22 % on average ▪ The gain on system weighted speedup is mainly due to the performance improvement in foreground applications System Fairness and Efficiency 15 Weighted speedup of two PARSEC applications (blocking) higher is better
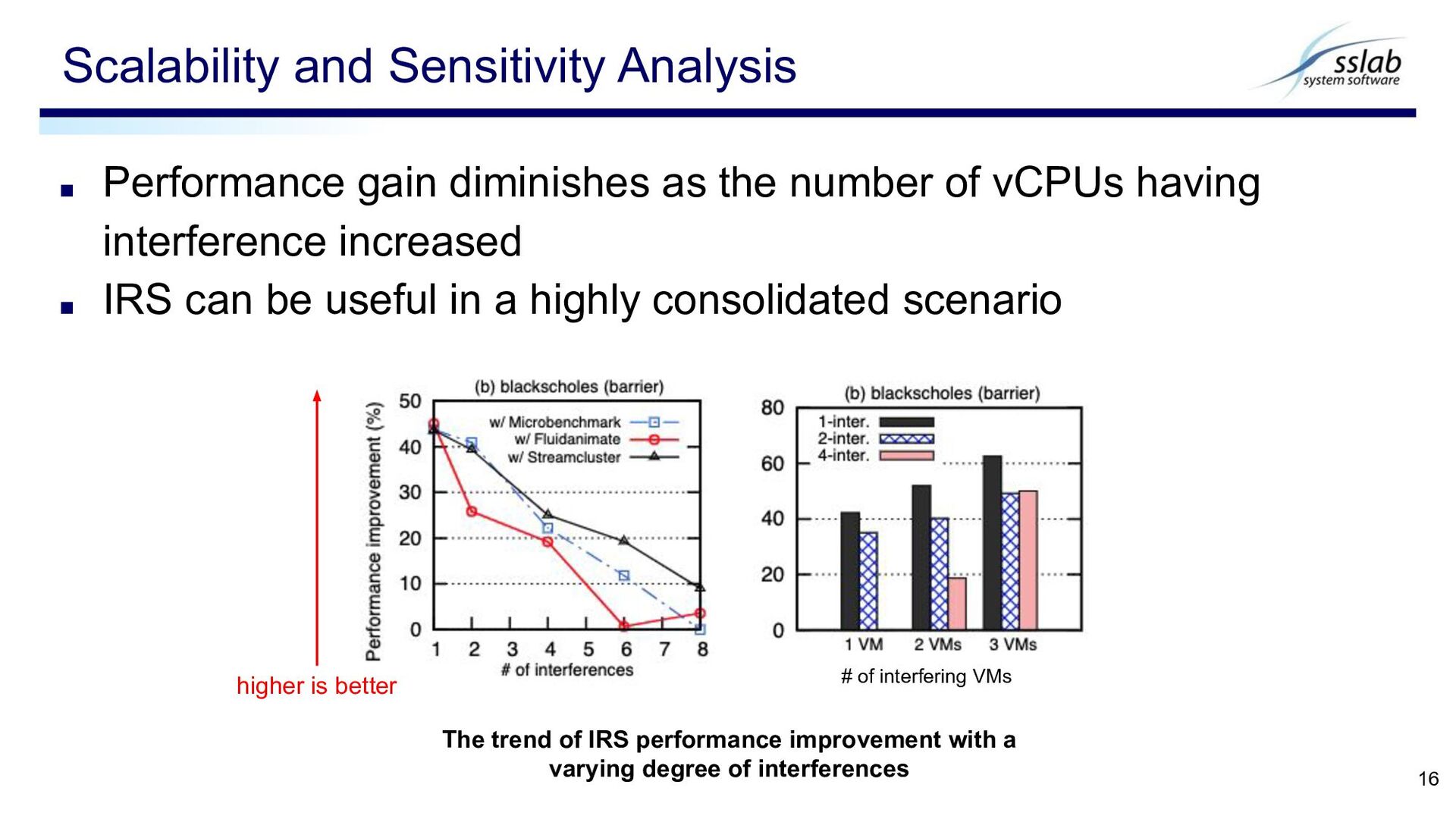
interference increased ▪ IRS can be useful in a highly consolidated scenario Scalability and Sensitivity Analysis 16 The trend of IRS performance improvement with a varying degree of interferences higher is better # of interfering VMs
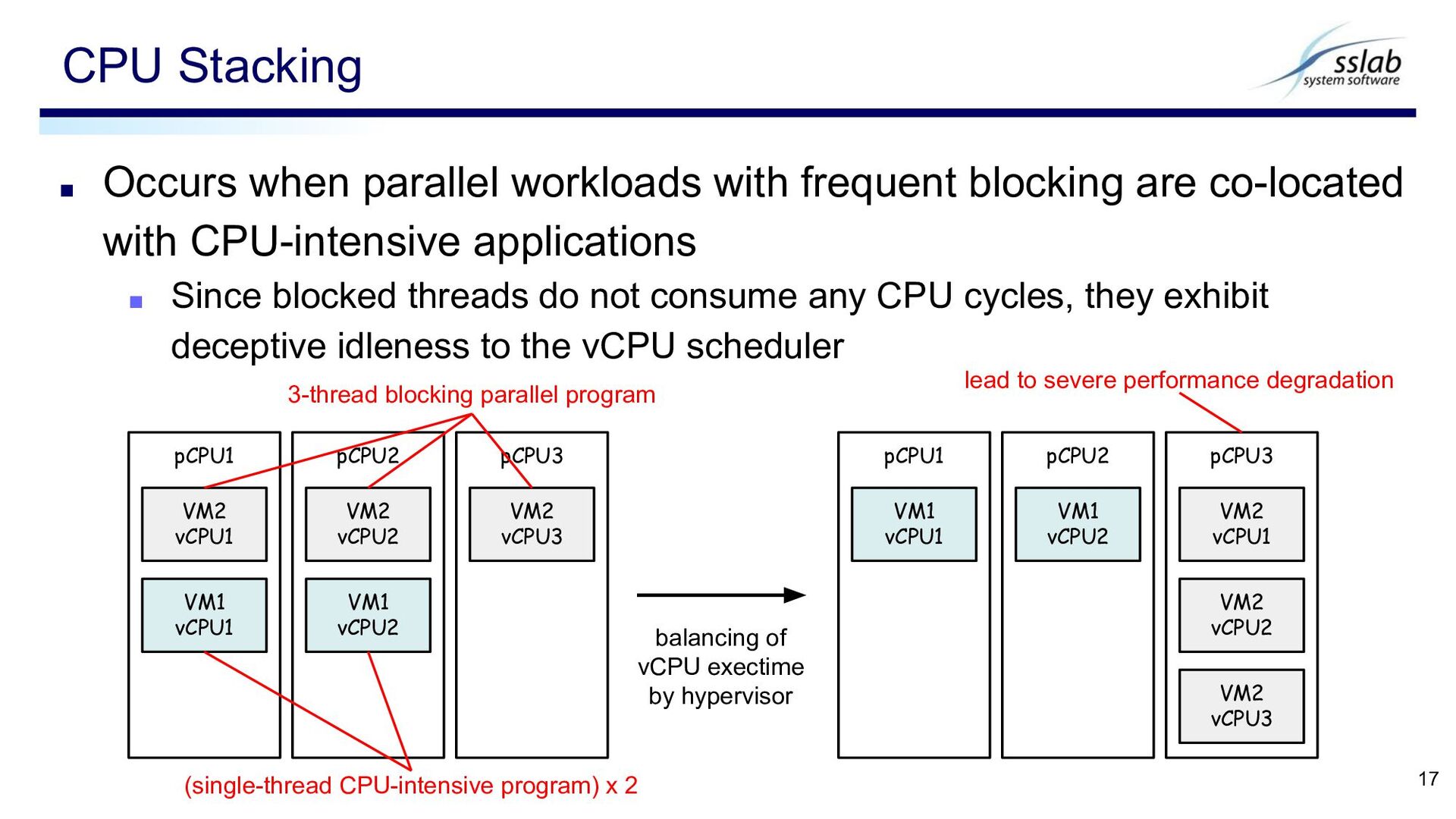
with CPU-intensive applications ▪ Since blocked threads do not consume any CPU cycles, they exhibit deceptive idleness to the vCPU scheduler CPU Stacking 17 pCPU1 VM2 vCPU1 VM1 vCPU1 pCPU2 VM2 vCPU2 pCPU3 VM2 vCPU3 VM1 vCPU2 pCPU1 pCPU2 pCPU3 (single-thread CPU-intensive program) x 2 3-thread blocking parallel program VM1 vCPU1 VM1 vCPU2 VM2 vCPU1 VM2 vCPU2 VM2 vCPU3 balancing of vCPU exectime by hypervisor lead to severe performance degradation
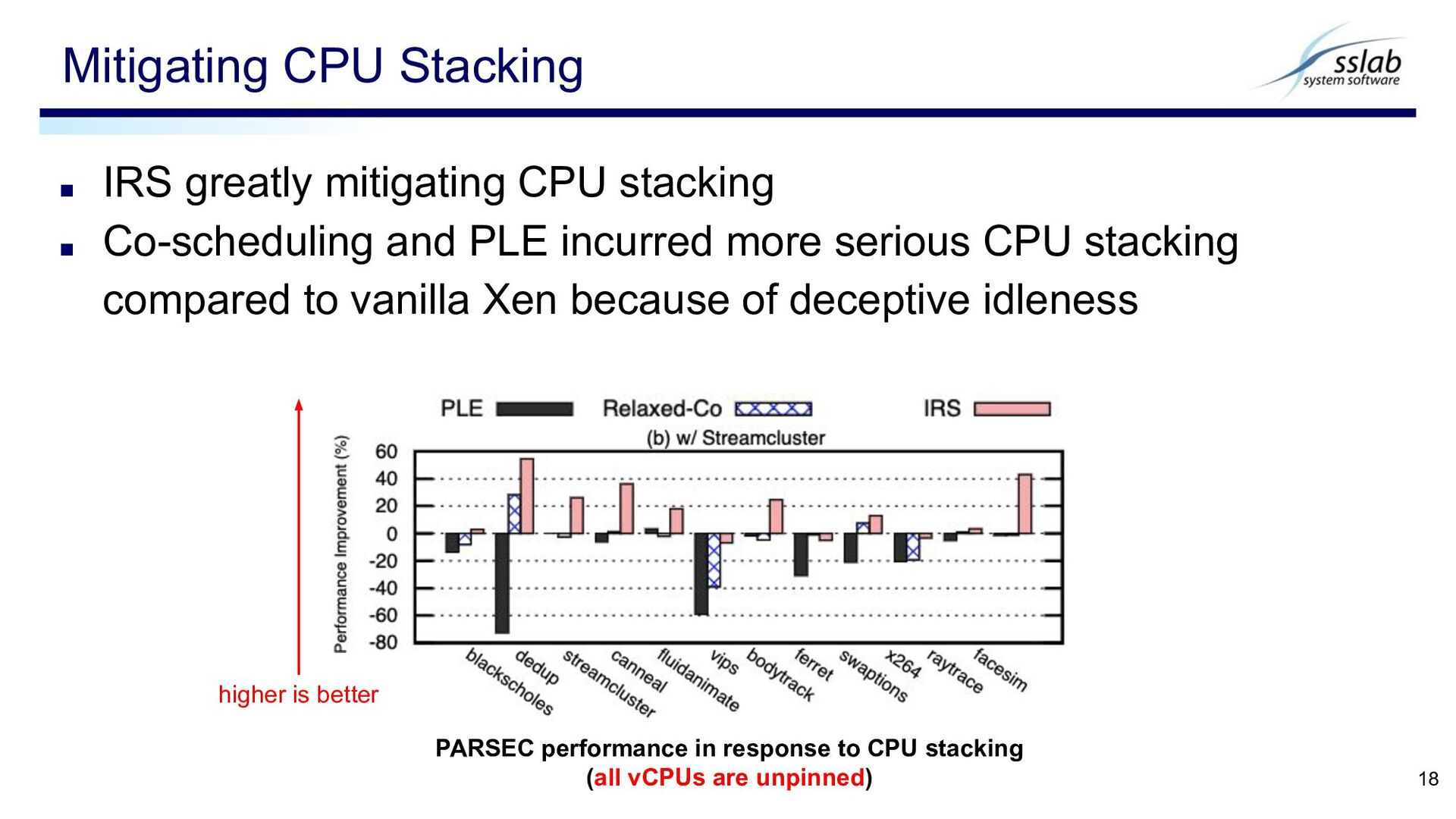
incurred more serious CPU stacking compared to vanilla Xen because of deceptive idleness Mitigating CPU Stacking 18 PARSEC performance in response to CPU stacking (all vCPUs are unpinned) higher is better
the guest-hypervisor semantic gap at the guest OS side. ▪ Inspired by Scheduler Activation [Anderson+, TOCS ’92] ▪ Enhances Guest OS load balancing to make any parallel applications resilient to interference ▪ Mitigates LHP and LWP problems ▪ Alleviates the CPU stacking problem ▪ Outperforms PLE and relaxed co-scheduling Conclusion 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}