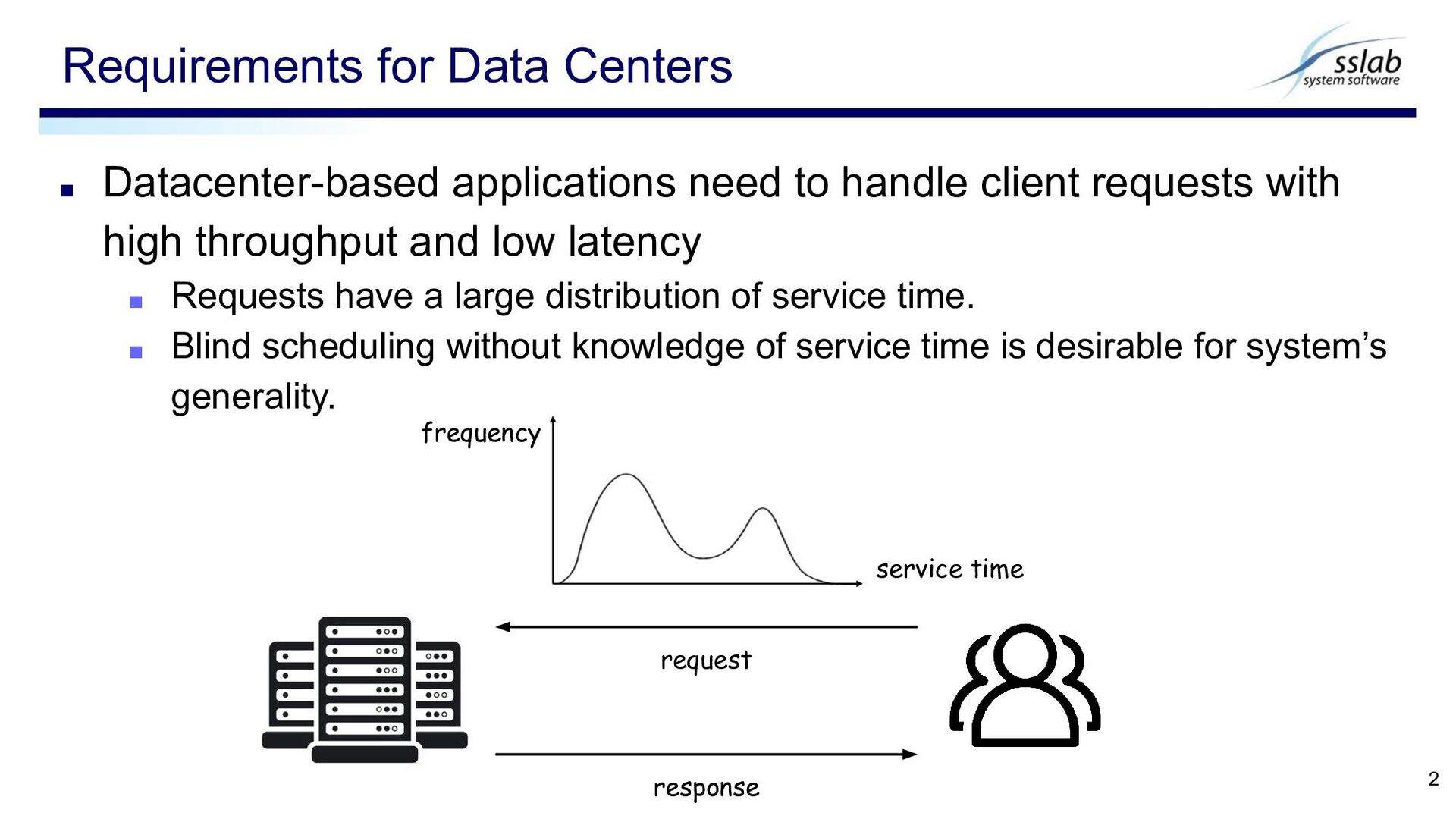
throughput and low latency ▪ Requests have a large distribution of service time. ▪ Blind scheduling without knowledge of service time is desirable for system’s generality. Requirements for Data Centers 2 response request frequency service time
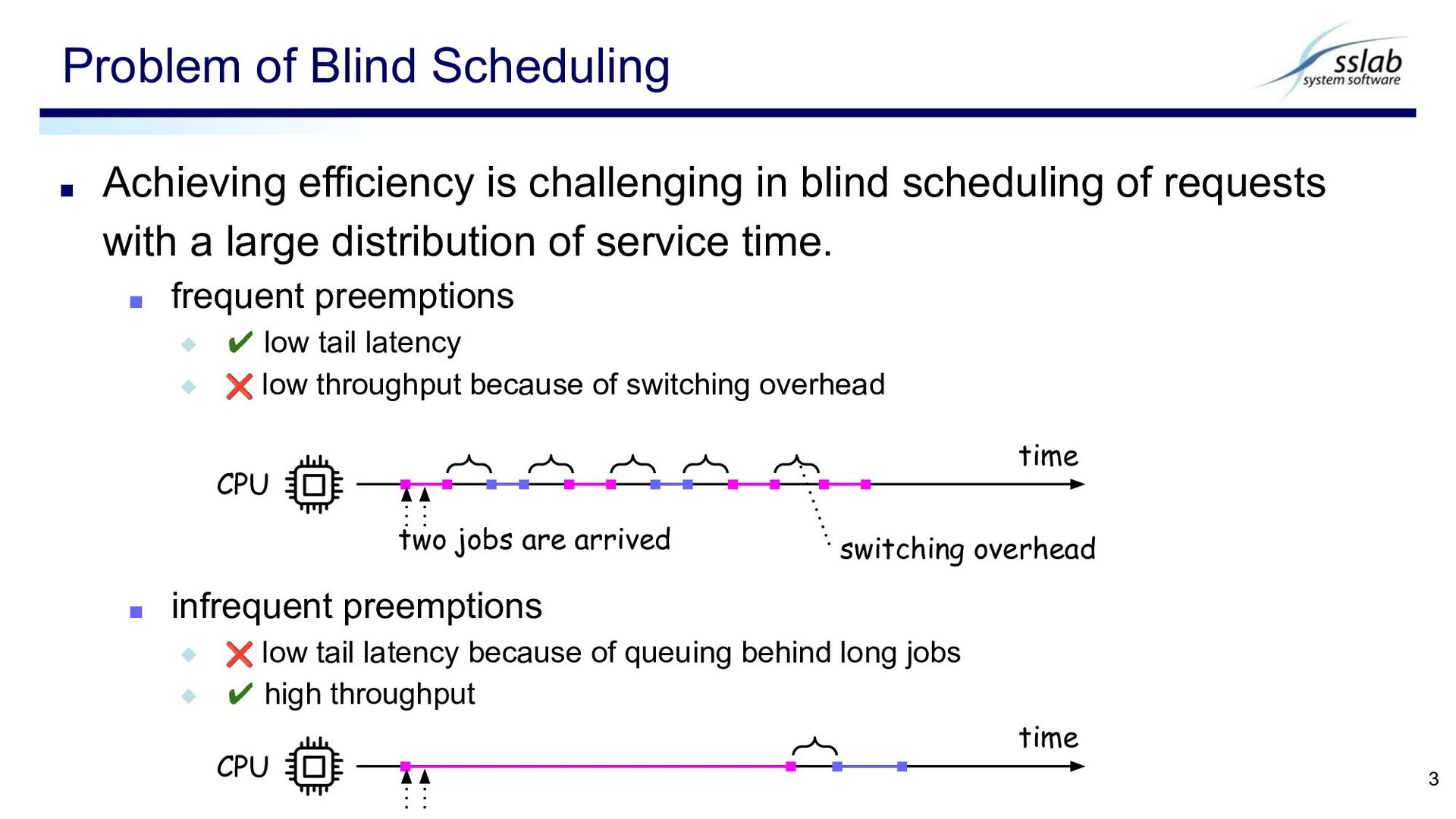
with a large distribution of service time. ▪ frequent preemptions ◆ ✔ low tail latency ◆ ❌ low throughput because of switching overhead ▪ infrequent preemptions ◆ ❌ low tail latency because of queuing behind long jobs ◆ ✔ high throughput Problem of Blind Scheduling 3 time CPU time two jobs are arrived CPU switching overhead
at least 5 μs ▪ suffers from throughput degradations when operating at sub-5μs quanta Prior Works for μs-scale Blind Scheduling 4 Centralized Dispatcher Global queue ✔ faster than Linux signals ❌ still has 1μs latency ❌ frequency increases as inverse of quantum size interrupt (IPI) ❌ CPU cache can become polluted ✔ minimal queue waiting time
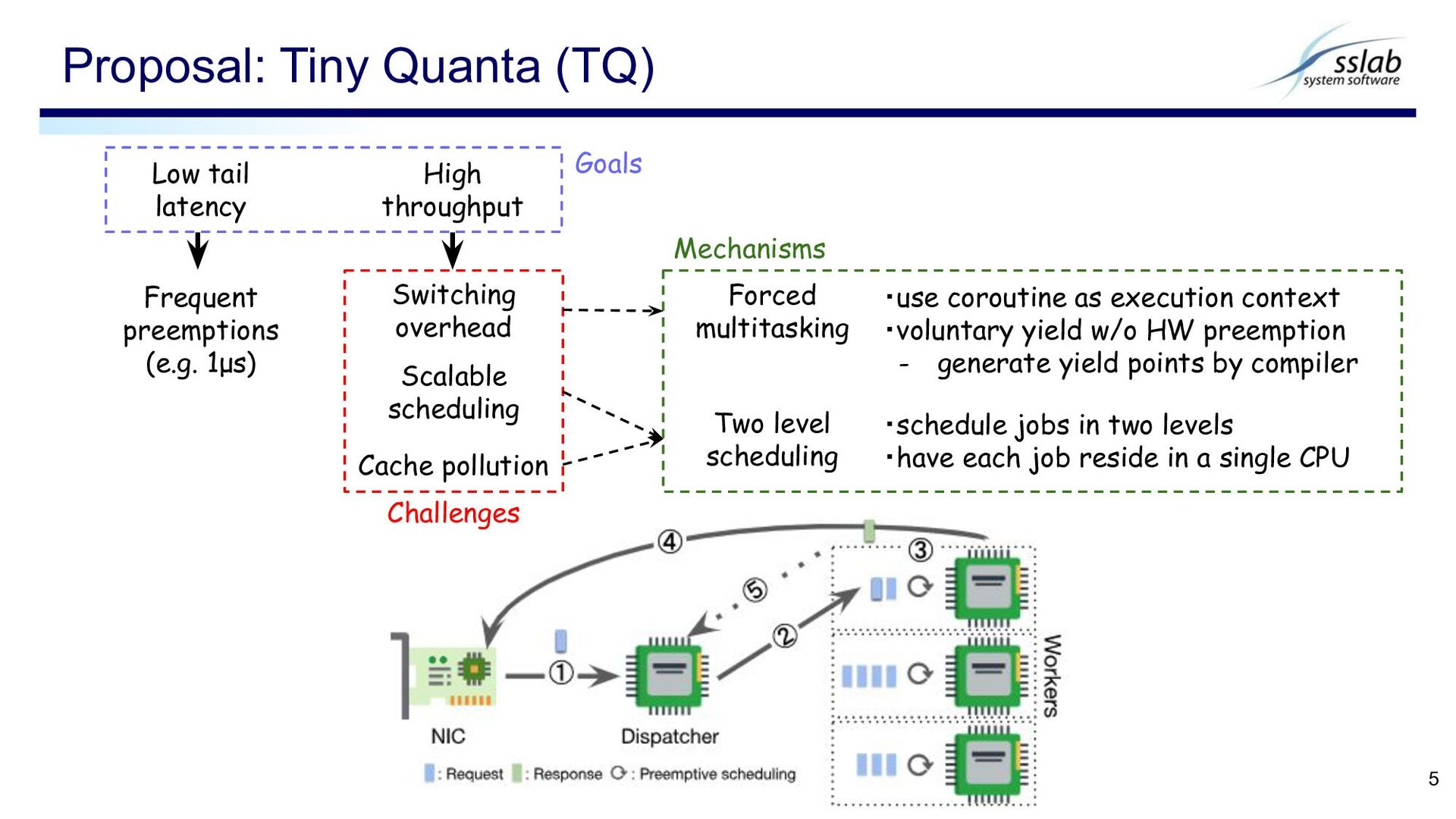
pollution Challenges Forced multitasking Two level scheduling Mechanisms ・use coroutine as execution context ・voluntary yield w/o HW preemption - generate yield points by compiler ・schedule jobs in two levels ・have each job reside in a single CPU Goals Frequent preemptions (e.g. 1μs) High throughput Low tail latency
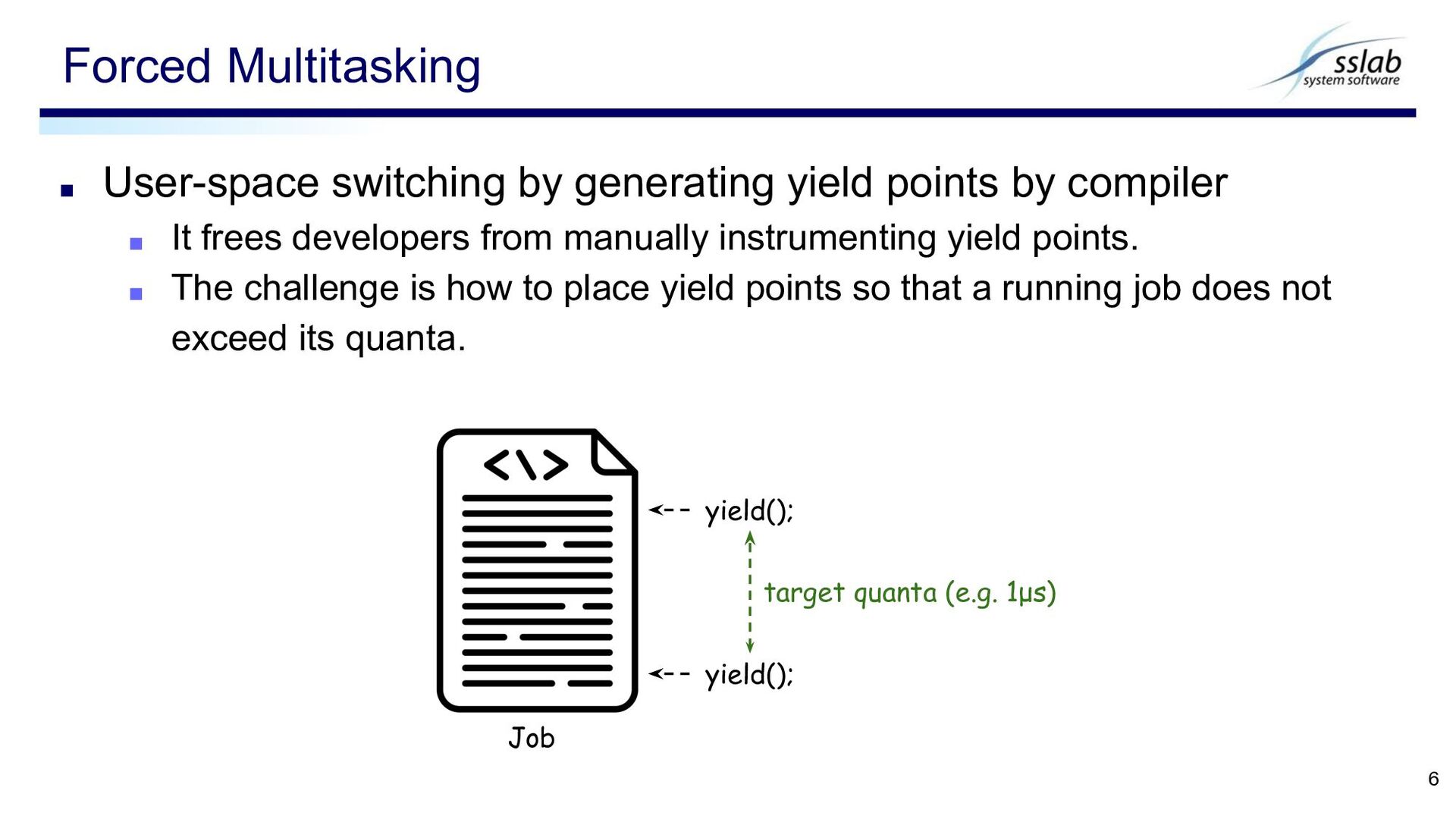
It frees developers from manually instrumenting yield points. ▪ The challenge is how to place yield points so that a running job does not exceed its quanta. Forced Multitasking 6 yield(); yield(); target quanta (e.g. 1μs) Job
◆ put a probe at the end of every basic block ◆ ❌ large overhead due to calculation in every basic block ▪ Yield timing ◆ yield CPU if instruction counter is greater than the target instruction count ◆ ❌ inaccurate due to translation from cycles into instruction counts Forced Multitasking in Prior work 7 basic block a++; b += 2; if (a > 2) void probe() { cnt_inst += LOC_BB; if (cnt_inst > TARGET_INST) { yield(); } } insert
▪ Probe placement ◆ use instruction-counter to control the probe density ◆ ✔ no need to place in every basic block: physical-clock probes can function correctly in arbitrary program locations ▪ Yield timing ◆ yield CPU if elapsed clock is greater than the target cycle ◆ ✔ More accurate because it does not suffer from cycle-to-instruction translation Forced multitasking in TQ 8
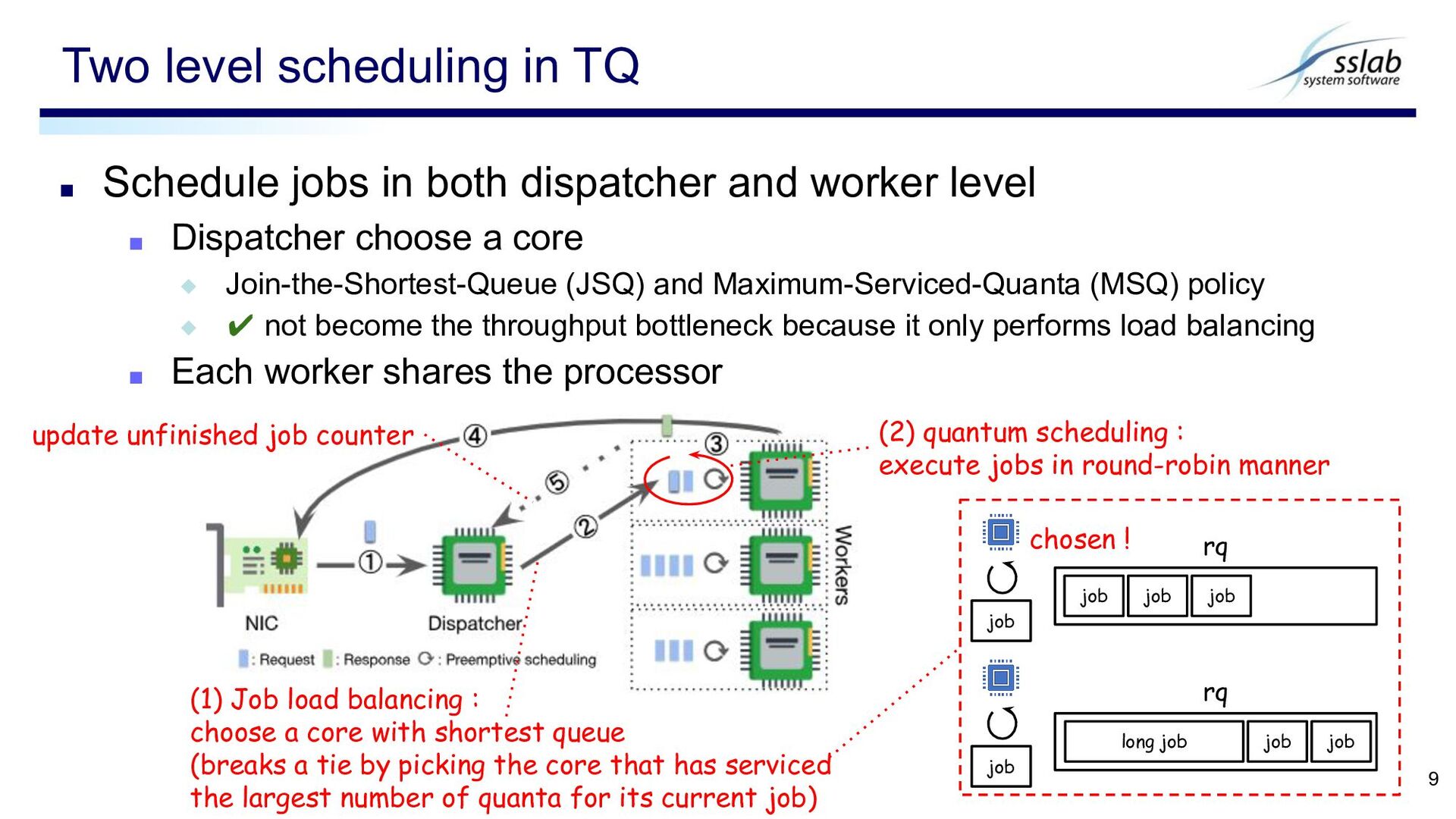
both dispatcher and worker level ▪ Dispatcher choose a core ◆ Join-the-Shortest-Queue (JSQ) and Maximum-Serviced-Quanta (MSQ) policy ◆ ✔ not become the throughput bottleneck because it only performs load balancing ▪ Each worker shares the processor (1) Job load balancing : choose a core with shortest queue (breaks a tie by picking the core that has serviced the largest number of quanta for its current job) (2) quantum scheduling : execute jobs in round-robin manner update unfinished job counter job job rq job job job rq long job job job chosen !
coroutine in C++ ▪ probe instrumentation : LLVM compiler pass ▪ Networking ▪ user-space network stack : DPDK ◆ one RX queue for the dispatcher to poll requests ◆ one TX queue for each worker core to push out responses ▪ Critical section ▪ disable preemptions during critical sections by providing jobs with specific functions to call at the entrances and exits of these sections
support? ▪ How well does TQ perform compared to prior systems? ▪ How do different components of TQ contribute to its performance? ▪ How do caches perform with small quanta in TQ? ▪ How do forced multitasking and two-level scheduling perform? ▪ Workloads Evaluation 11
▪ Runs 10 seconds for each request rate and the first 10% samples are discarded to remove warm-up effects ▪ Systems ▪ 2μs quanta ▪ Worker cores perform work stealing to minimize load imbalance ▪ Latency metrics ▪ 1. end-to-end latency, which is recorded by the client ◆ used for all comparisons between systems ▪ 2. sojourn time, which is calculated by the server ◆ used for highlighting the effects of configurations within TQ Evaluation Setup 12
Xeon Platinum 8176 CPUs are used for (1) TQ and Caladan and (2) Shinjuku respectively. ◆ TQ and Caladan – Ubuntu 22.04 with Linux kernel 5.15.0 – 40 Gbits/s Mellanox Connect X-5 Bluefield NIC ◆ Shinjuku – Ubuntu 18.04 with Linux kernel 4.4.0 – 10 Gbits/s Intel 82599ES NIC ▪ use 16 worker threads on dedicated physical cores Evaluation Setup 13
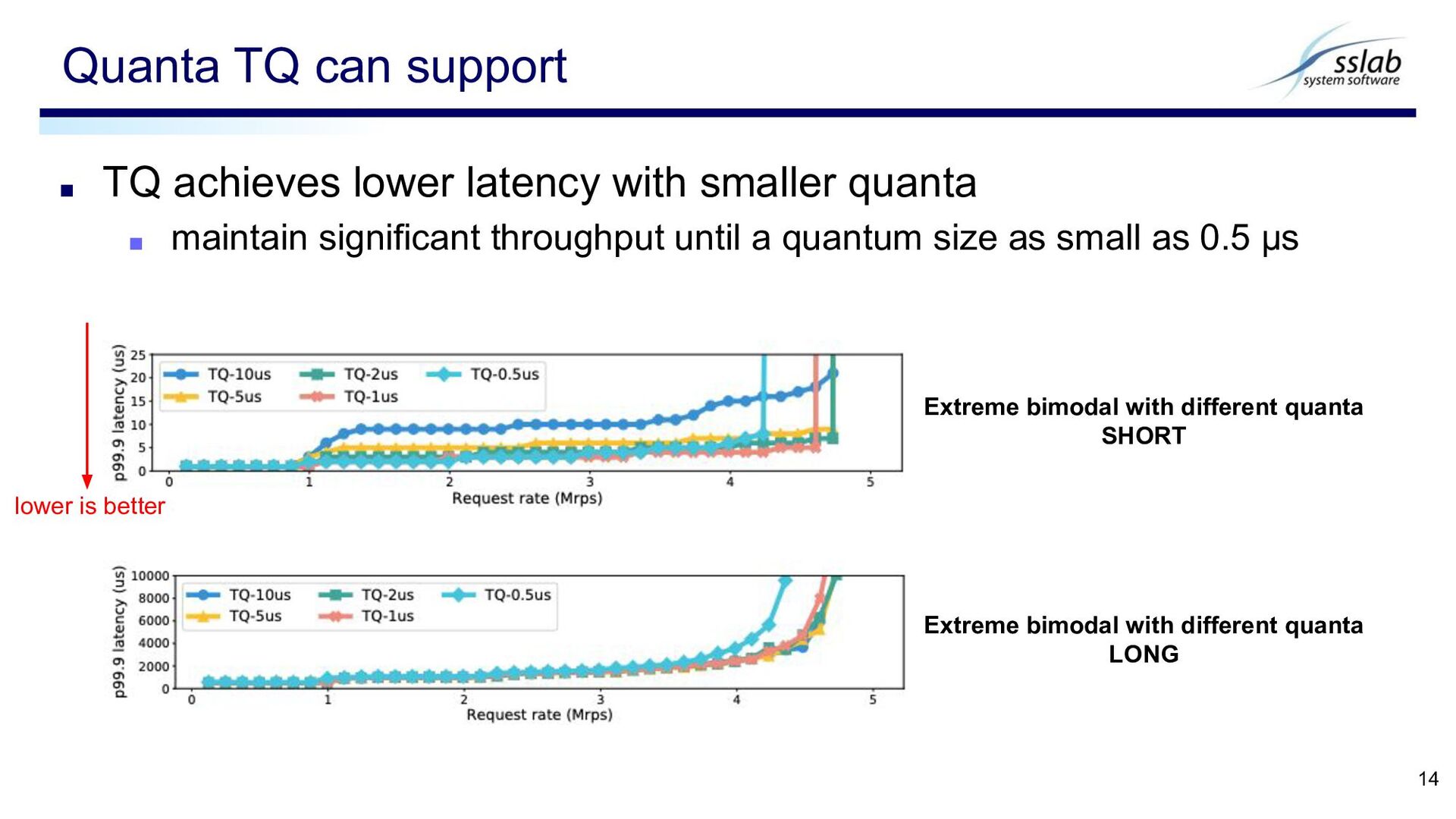
significant throughput until a quantum size as small as 0.5 μs Quanta TQ can support 14 lower is better Extreme bimodal with different quanta SHORT Extreme bimodal with different quanta LONG
and 2.1x throughput of Shinjuku and Caladan for short jobs respectively ▪ 1.8x and 1.2x throughput of Shinjuku and Caladan for long jobs respectively Comparison with Prior Systems 15 Extreme Bimodal and High Bimodal workloads suffers from poor latency due to head-line-blocking not able to sustain high throughput due to the large preemption overhead high throughput because of using a FCFS policy
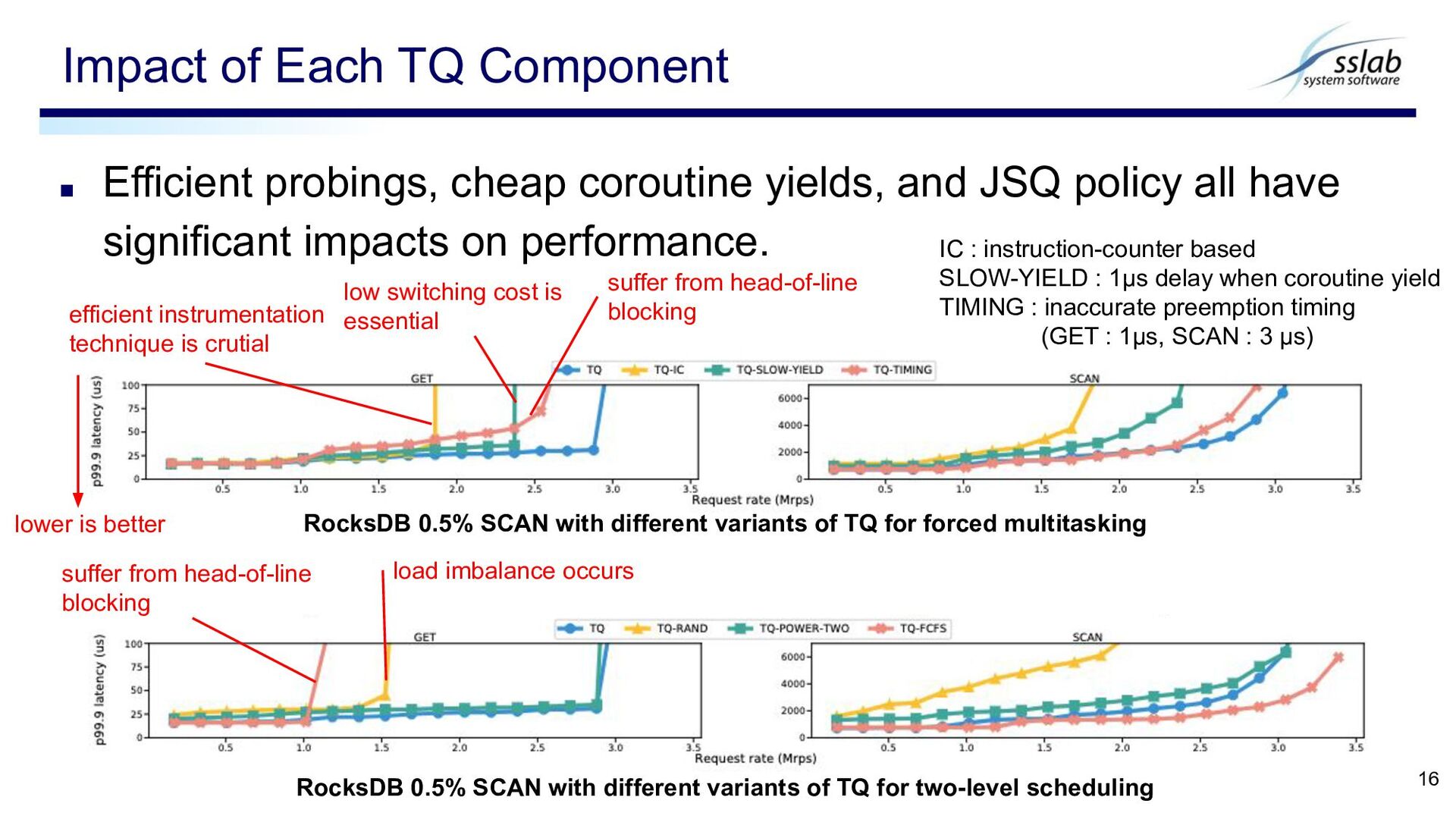
have significant impacts on performance. Impact of Each TQ Component 16 RocksDB 0.5% SCAN with different variants of TQ for forced multitasking RocksDB 0.5% SCAN with different variants of TQ for two-level scheduling IC : instruction-counter based SLOW-YIELD : 1μs delay when coroutine yield TIMING : inaccurate preemption timing (GET : 1μs, SCAN : 3 μs) efficient instrumentation technique is crutial low switching cost is essential load imbalance occurs suffer from head-of-line blocking lower is better suffer from head-of-line blocking
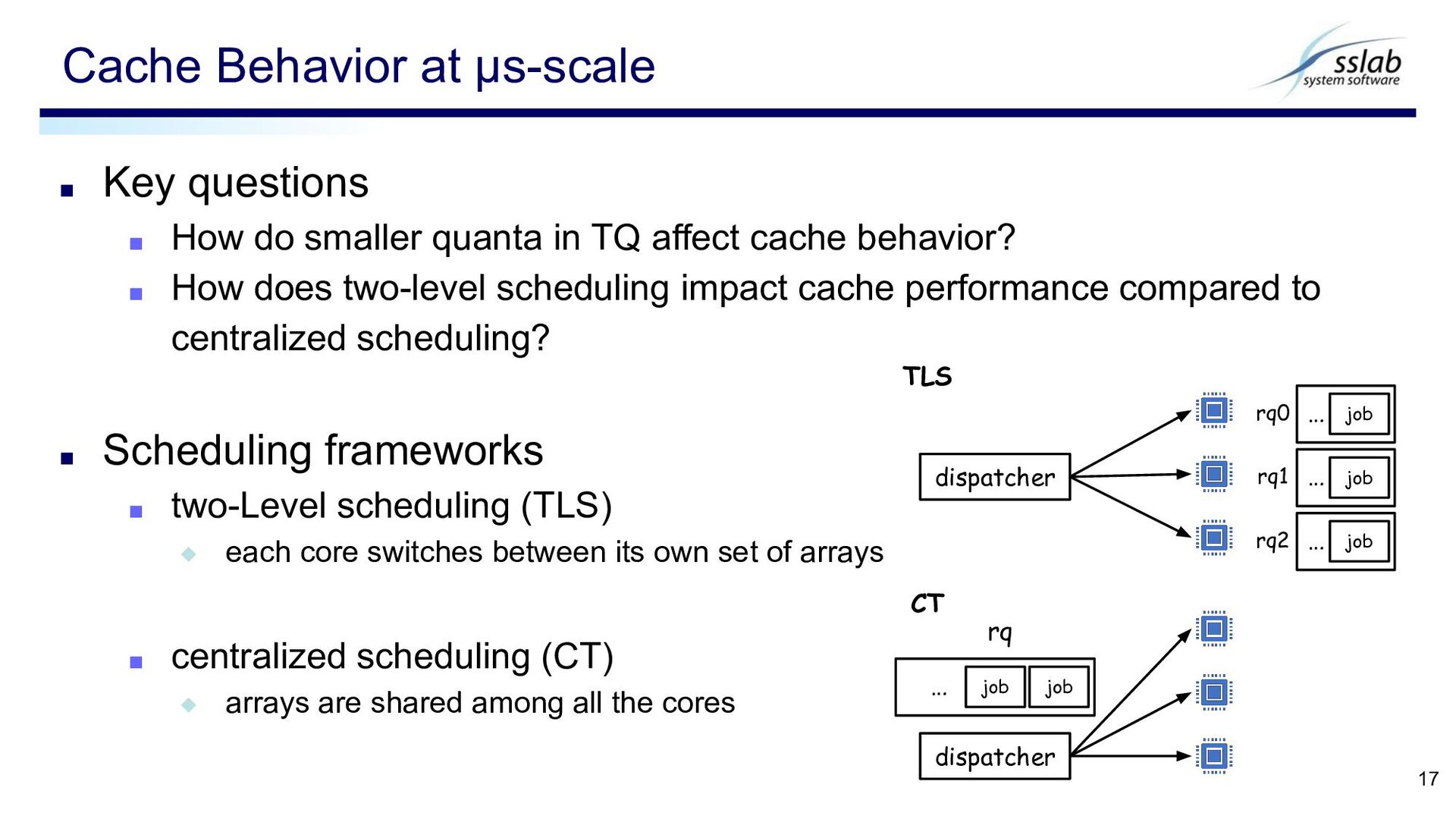
affect cache behavior? ▪ How does two-level scheduling impact cache performance compared to centralized scheduling? ▪ Scheduling frameworks ▪ two-Level scheduling (TLS) ◆ each core switches between its own set of arrays ▪ centralized scheduling (CT) ◆ arrays are shared among all the cores Cache Behavior at μs-scale 17 TLS dispatcher CT dispatcher job job rq … job rq0 … job rq1 job rq2 … …
(64 in total) ▪ iterate through the array 100K times ▪ array size: 2^n KB (n: 0~10) ▪ Cache misses are amplified by … ▪ preemption frequency ▪ number of jobs per core ▪ array size Cache Behavior at μs-scale 18 Reuse distances of accesses in array iterations for CT and TLS CT: centralized, TLS: two-level scheduling C: # of worker cores, J: # of jobs per core A: array size J: 64 J: 4 If the quantum is small, more accesses will fall into this category. job 0 array 0 job 1 array 1 (i) iterate random accesses during a quanta (ii) switch to the next array
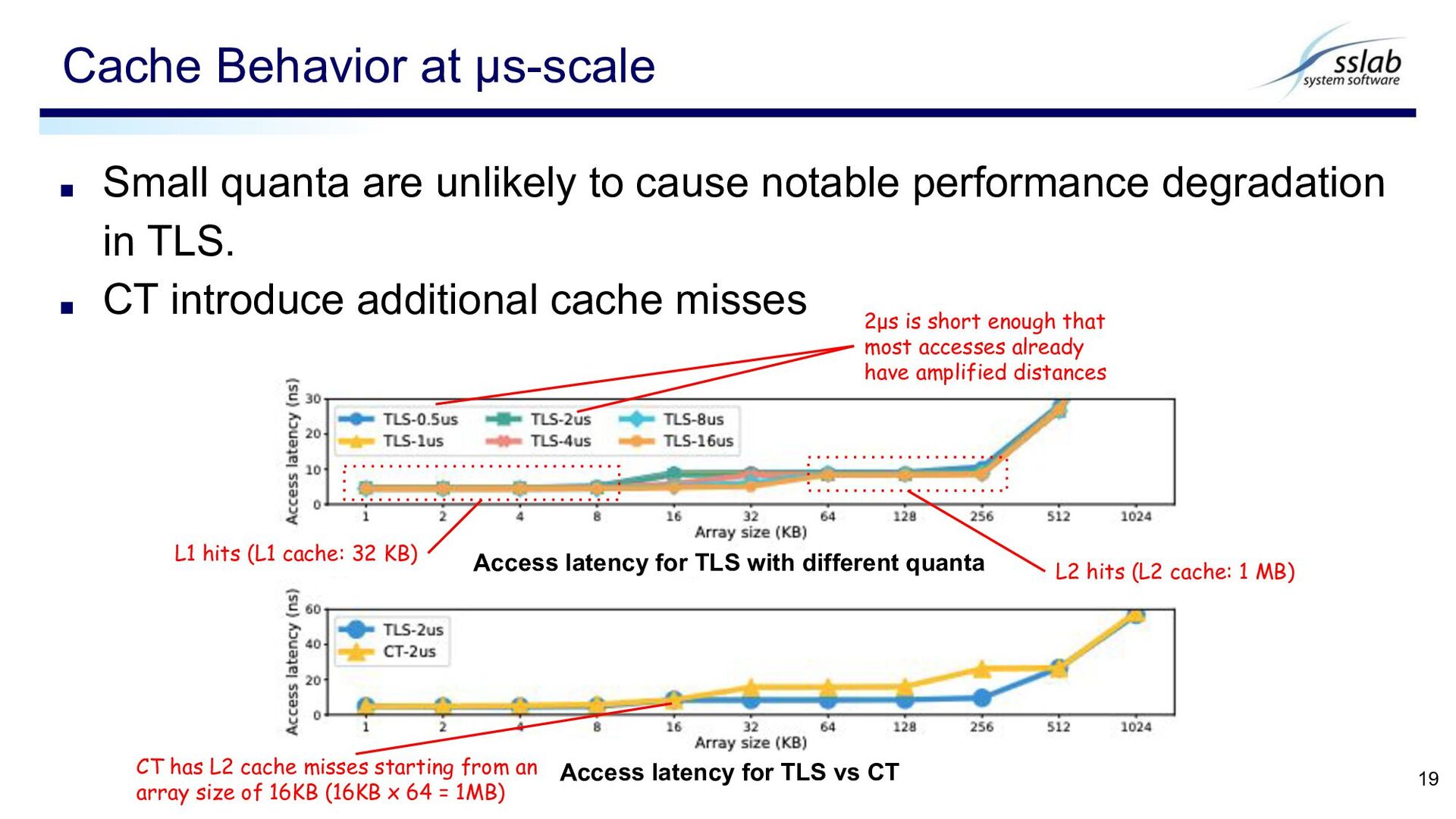
in TLS. ▪ CT introduce additional cache misses Cache Behavior at μs-scale 19 Access latency for TLS with different quanta Access latency for TLS vs CT L1 hits (L1 cache: 32 KB) L2 hits (L2 cache: 1 MB) 2μs is short enough that most accesses already have amplified distances CT has L2 cache misses starting from an array size of 16KB (16KB x 64 = 1MB)
probing overhead by 43% ▪ MAE of yield timings by 57% Probing overhead and Yield timing accuracy 20 Probing overhead and yield timing accuracy of TQ compiler pass in SPLASH-2, Phoenix, Parsec (single core, quantum size: 2μs) CI : instruction-counter based CICY : CI but checks physical clock MAE : Mean Average Error
inter-processor interrupt ▪ its dispatcher suffers from increasing load with the preemption frequency ▪ Concord [Iyer+, SOSP ’23] ▪ μs-scale scheduling mechanism with replacing interrupt with a shared cache line ▪ its dispatcher suffers from increasing load with the preemption frequency ▪ Coredet [Bergan, ASPLOS ’10] ▪ frees multithreaded program from timining effect by instruction-counter approach ▪ suffers from large probing overhead and poor timing accuracy Related works 21
difficult to achieve both high throughput and low tail latency. ▪ TQ performs fine-grained preemptive scheduling with ▪ forced multitasking ▪ two-level scheduling ▪ TQ achieves low tail latency while sustaining 1.2x to 6.8x the throughput of prior blind scheduling systems. Conclusion 22
{kind=link}
{kind=link}
{kind=link}
![▪ Shinjuku [Kaffes+, NSDI ’19] ▪ only supports quanta of](https://files.speakerdeck.com/presentations/fa4b793a02984fe68c17ecf56b978569/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![▪ Coredet [Bergan+, ASPLOS’10] : instruction-counter based ▪ Probe placement](https://files.speakerdeck.com/presentations/fa4b793a02984fe68c17ecf56b978569/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![▪ Shinjuku [Kaffes+, NSDI ’19] ▪ μs-scale scheduling mechanism with](https://files.speakerdeck.com/presentations/fa4b793a02984fe68c17ecf56b978569/slide_20.jpg){kind=link}
{kind=link}