Liu1, Tianqiang Xu1, Zeyu Mi1,2, Zhichao Hua1,2, Binyu Zang1,2, Haibo Chen1,2 (1Institute of Parallel and Distributed Systems, SEIEE, Shanghai Jiao Tong University, 2Engineering Research Center for Domain-specific Operating Systems Ministry of Education) Keio University Kono Laboratory, Daiki Wakabayashi ASPLOS ’23
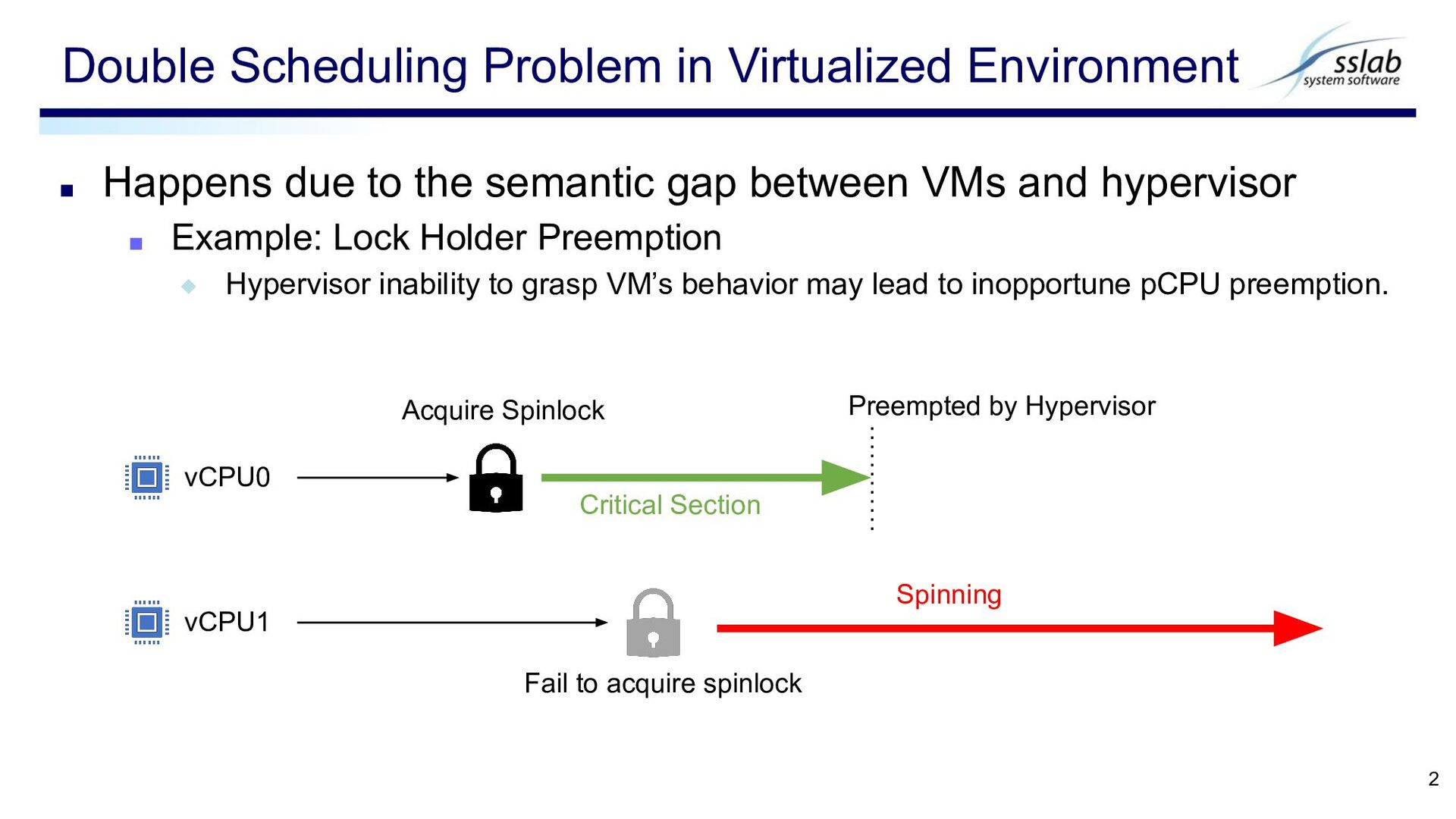
hypervisor ▪ Example: Lock Holder Preemption ◆ Hypervisor inability to grasp VM’s behavior may lead to inopportune pCPU preemption. Double Scheduling Problem in Virtualized Environment 2 vCPU0 vCPU1 Acquire Spinlock Preempted by Hypervisor Critical Section Fail to acquire spinlock Spinning
’21] ▪ Utilize Intel’s Pause Loop Exiting to detect vCPUs that keep busy waiting ▪ Difficult to pinpoint the lockholder due to the semantic gap ▪ eCS [Kashyap+, USENIX ATC ’18] ▪ Let the guest to annotate critical sections in which hypervisor will not schedule out the vCPU ▪ Only resolve the locking related issues ▪ VScale [Luwei+, Eurosys ’16] ▪ Employ gang scheduling and simultaneously schedule all vCPUs of a VM ▪ Can lead to significant CPU fragmentation Prior Efforts 3
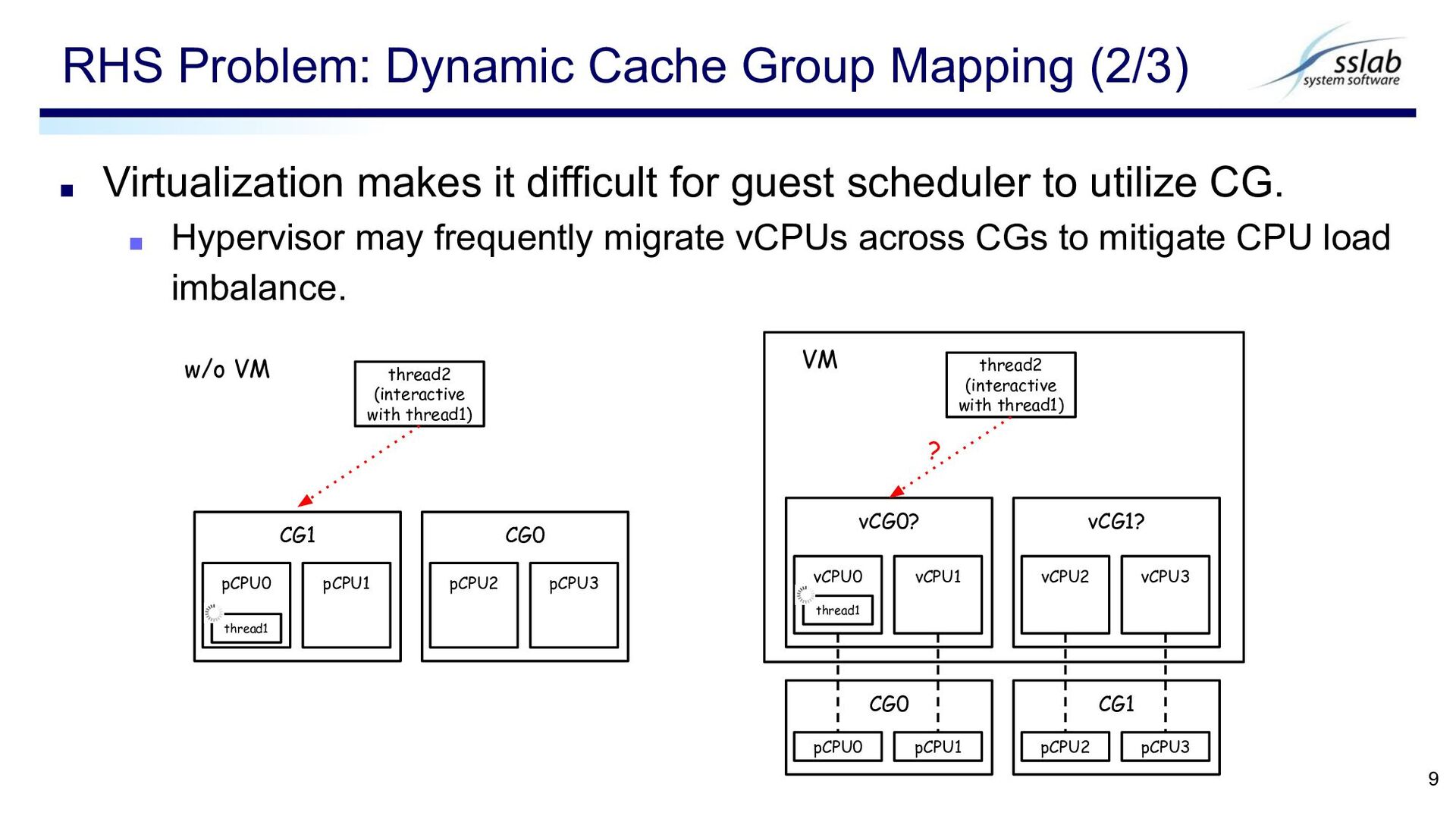
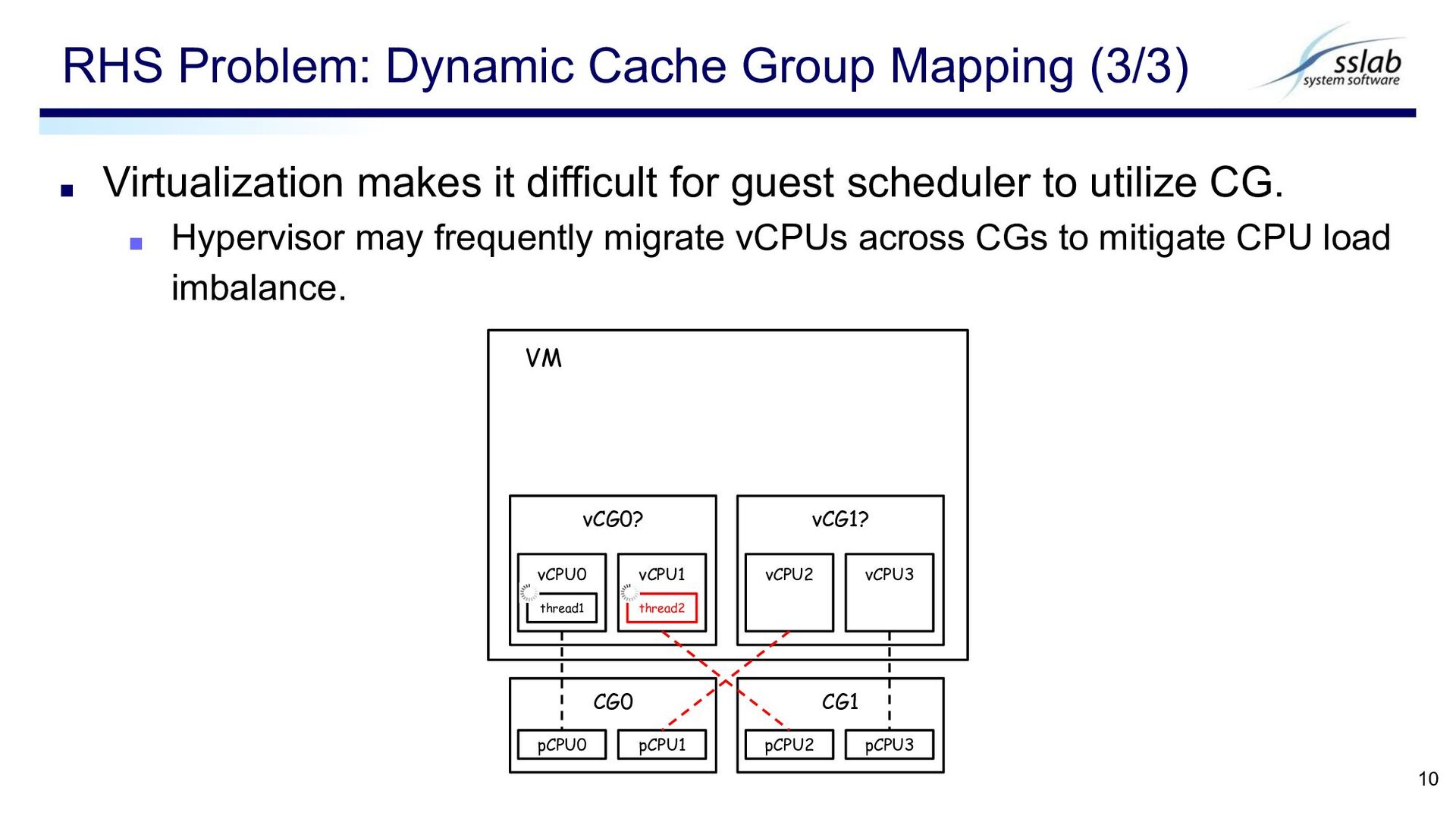
kernels due to the absence of hypervisor-internal information on the following ▪ pCPU load ▪ pCPU runtime ▪ etc. ▪ ≠ locking based problems ▪ Locking based problems are on the hypervisor’s perspective. Runtime Hypervisor-internal States (RHS) Problem 4
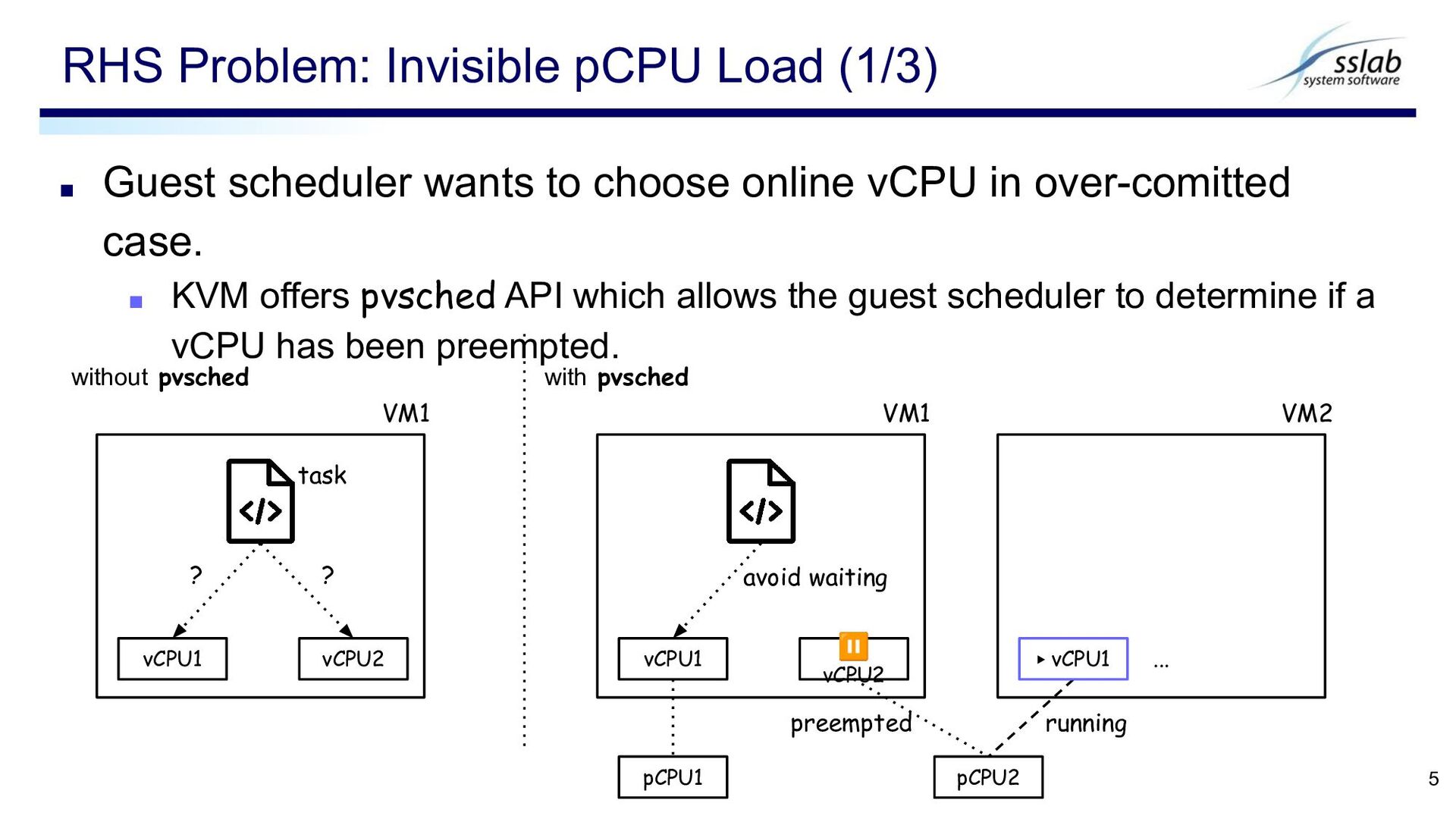
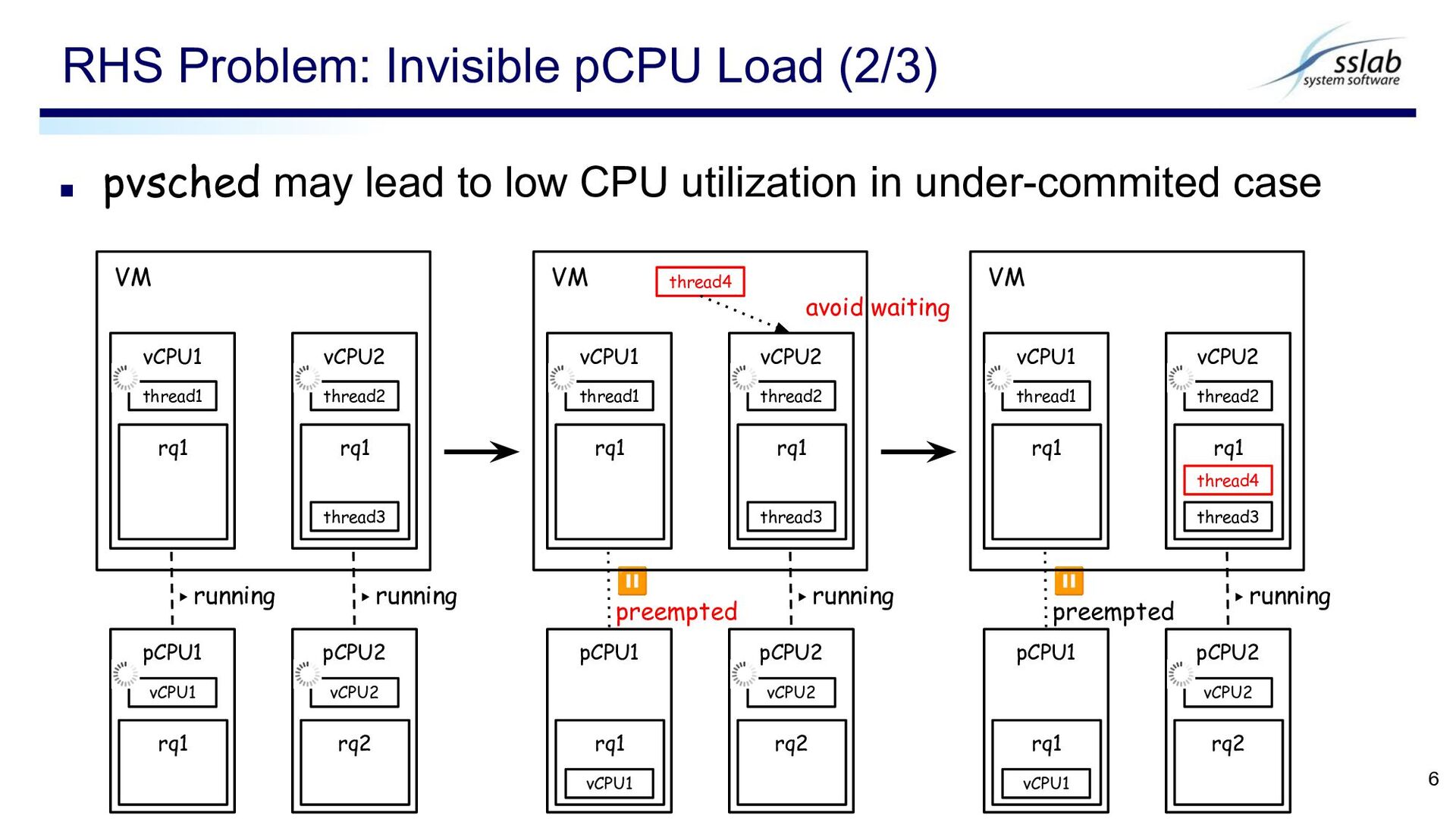
case. ▪ KVM offers pvsched API which allows the guest scheduler to determine if a vCPU has been preempted. RHS Problem: Invisible pCPU Load (1/3) 5 vCPU1 vCPU2 VM1 ? ? without pvsched with pvsched pCPU1 pCPU2 VM1 ▶ vCPU1 ... VM2 vCPU1 ⏸ vCPU2 running preempted avoid waiting task
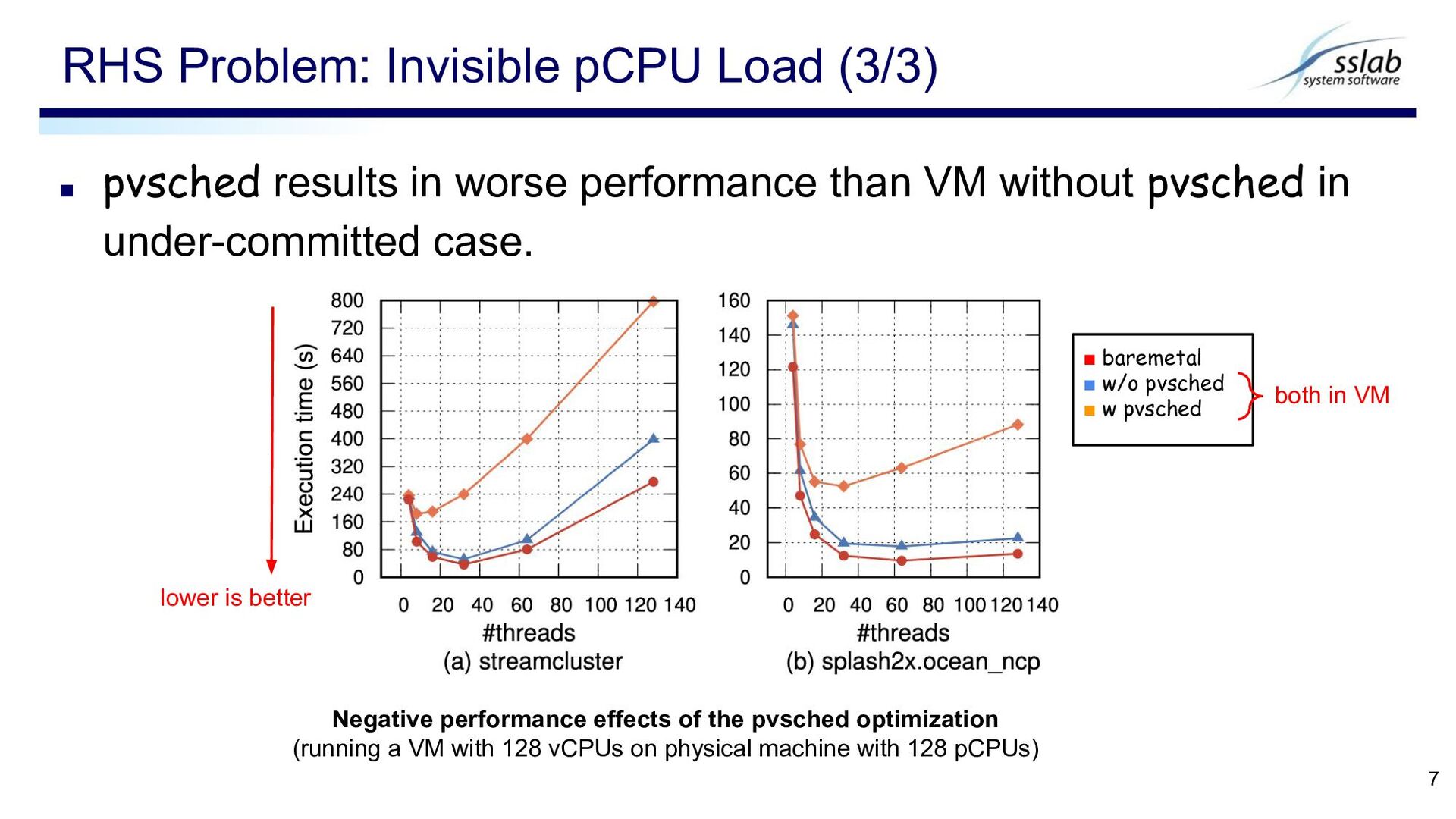
in under-committed case. RHS Problem: Invisible pCPU Load (3/3) 7 ▪ baremetal ▪ w/o pvsched ▪ w pvsched both in VM lower is better Negative performance effects of the pvsched optimization (running a VM with 128 vCPUs on physical machine with 128 pCPUs)
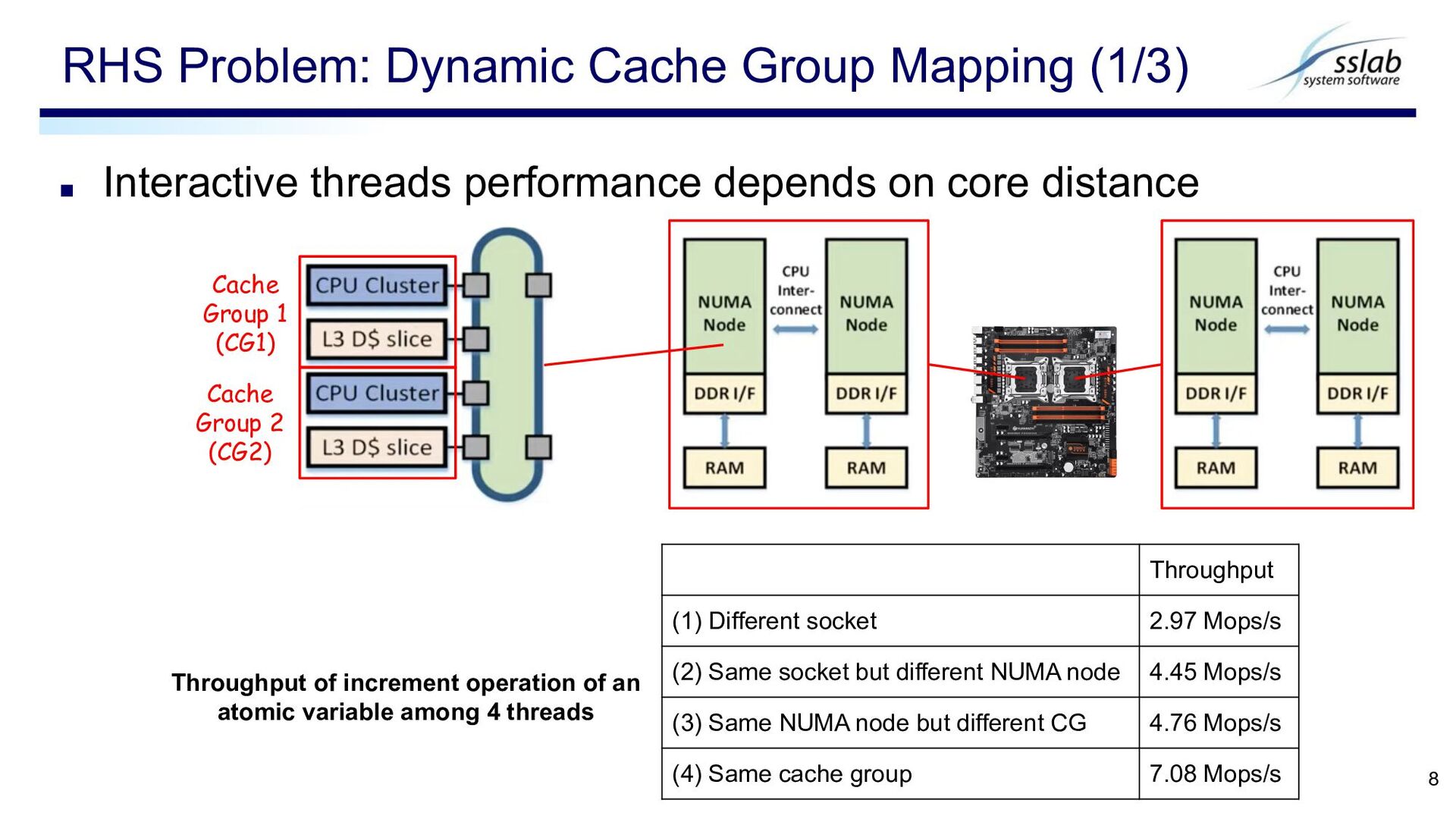
Dynamic Cache Group Mapping (1/3) 8 Cache Group 1 (CG1) Cache Group 2 (CG2) Throughput (1) Different socket 2.97 Mops/s (2) Same socket but different NUMA node 4.45 Mops/s (3) Same NUMA node but different CG 4.76 Mops/s (4) Same cache group 7.08 Mops/s Throughput of increment operation of an atomic variable among 4 threads
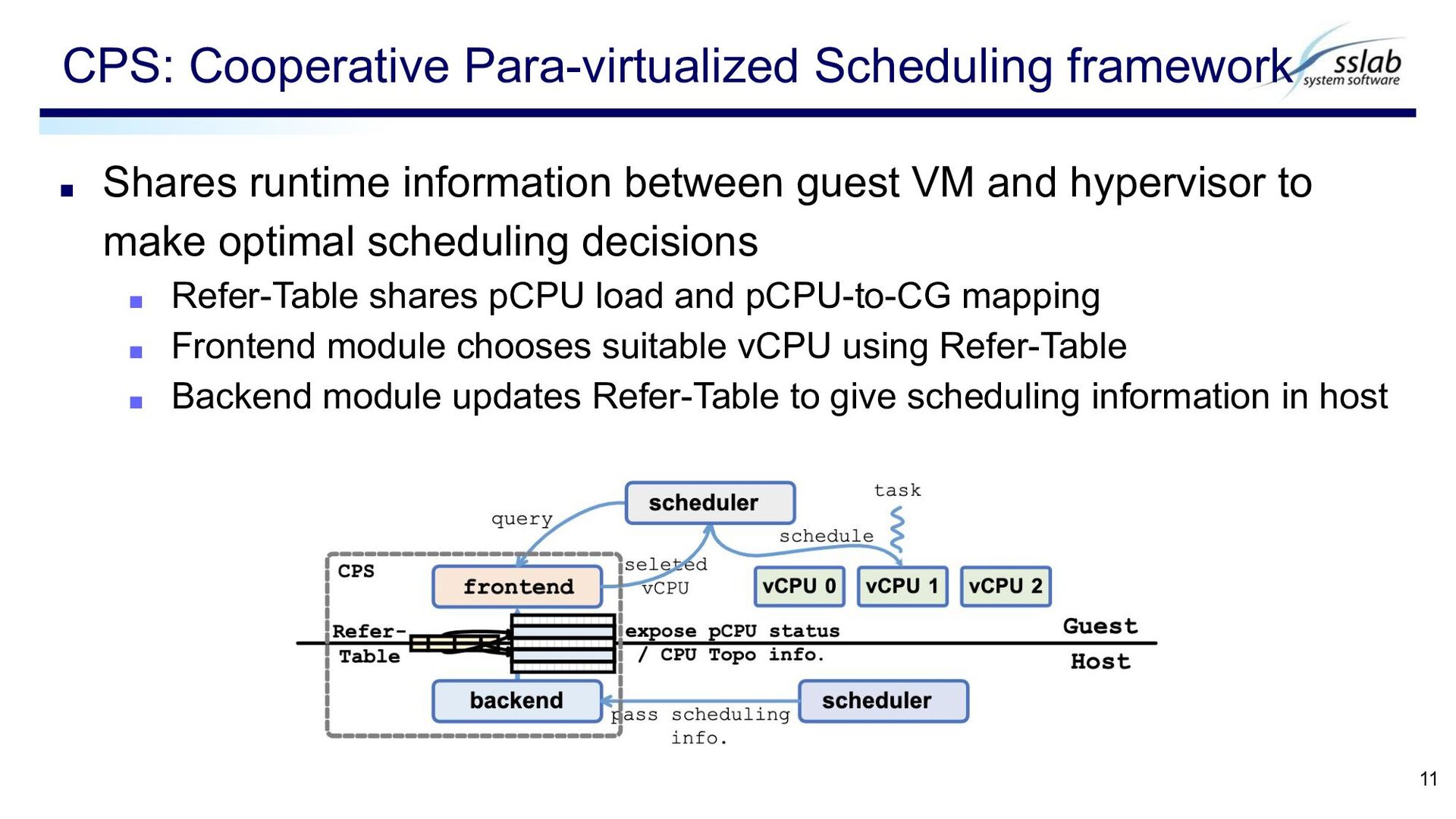
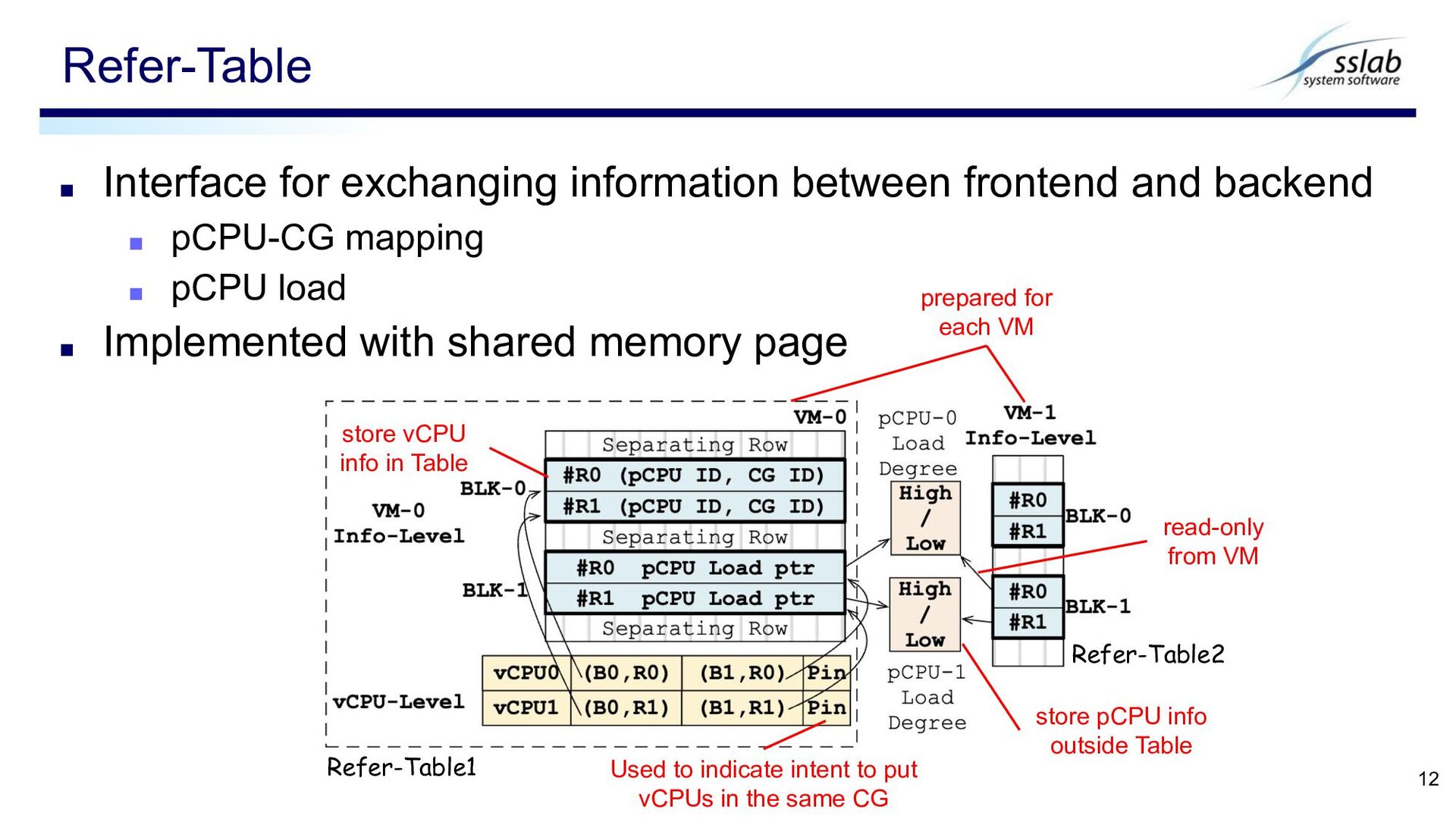
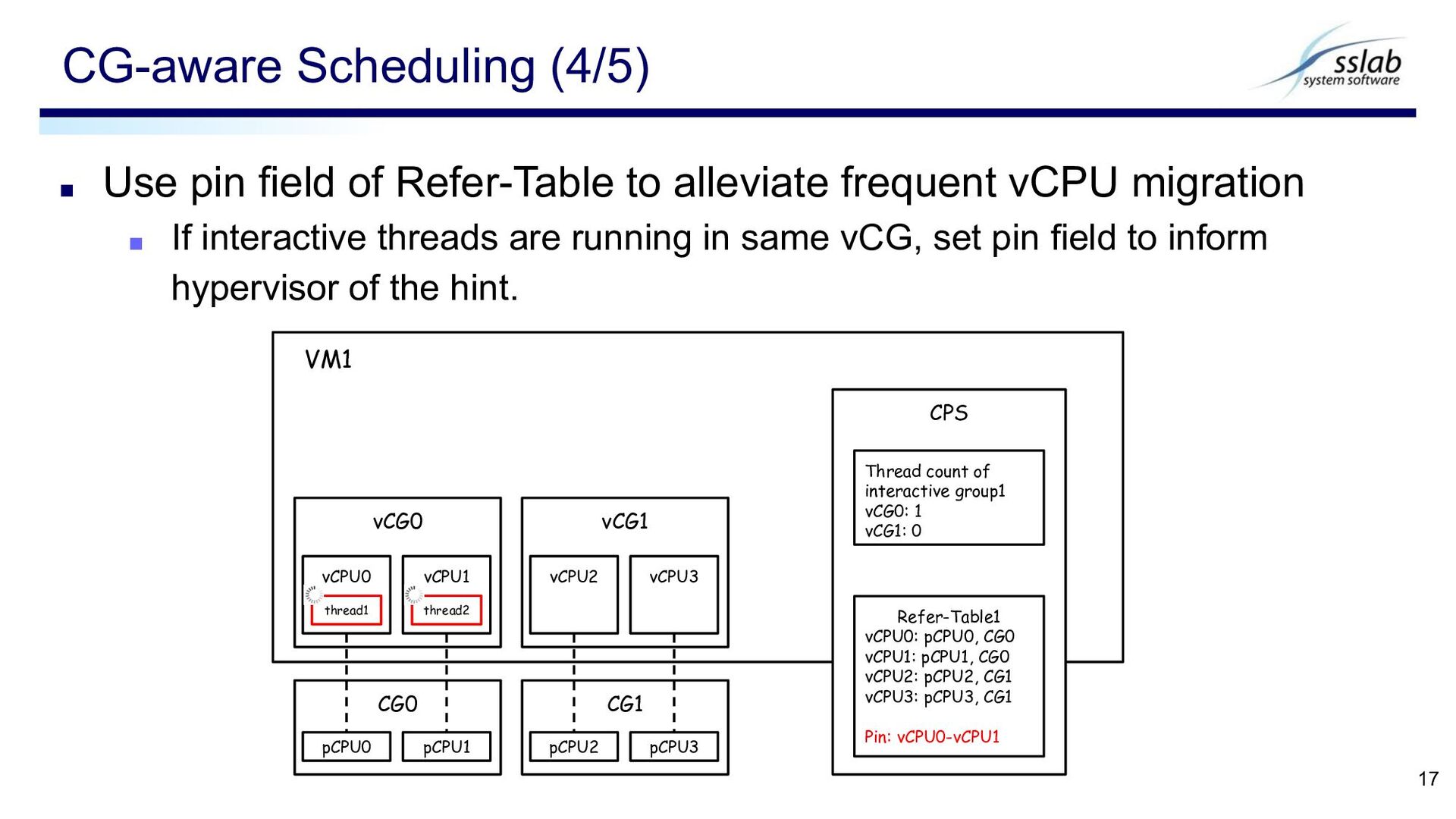
pCPU-CG mapping ▪ pCPU load ▪ Implemented with shared memory page Refer-Table 12 prepared for each VM store vCPU info in Table store pCPU info outside Table read-only from VM Used to indicate intent to put vCPUs in the same CG Refer-Table1 Refer-Table2
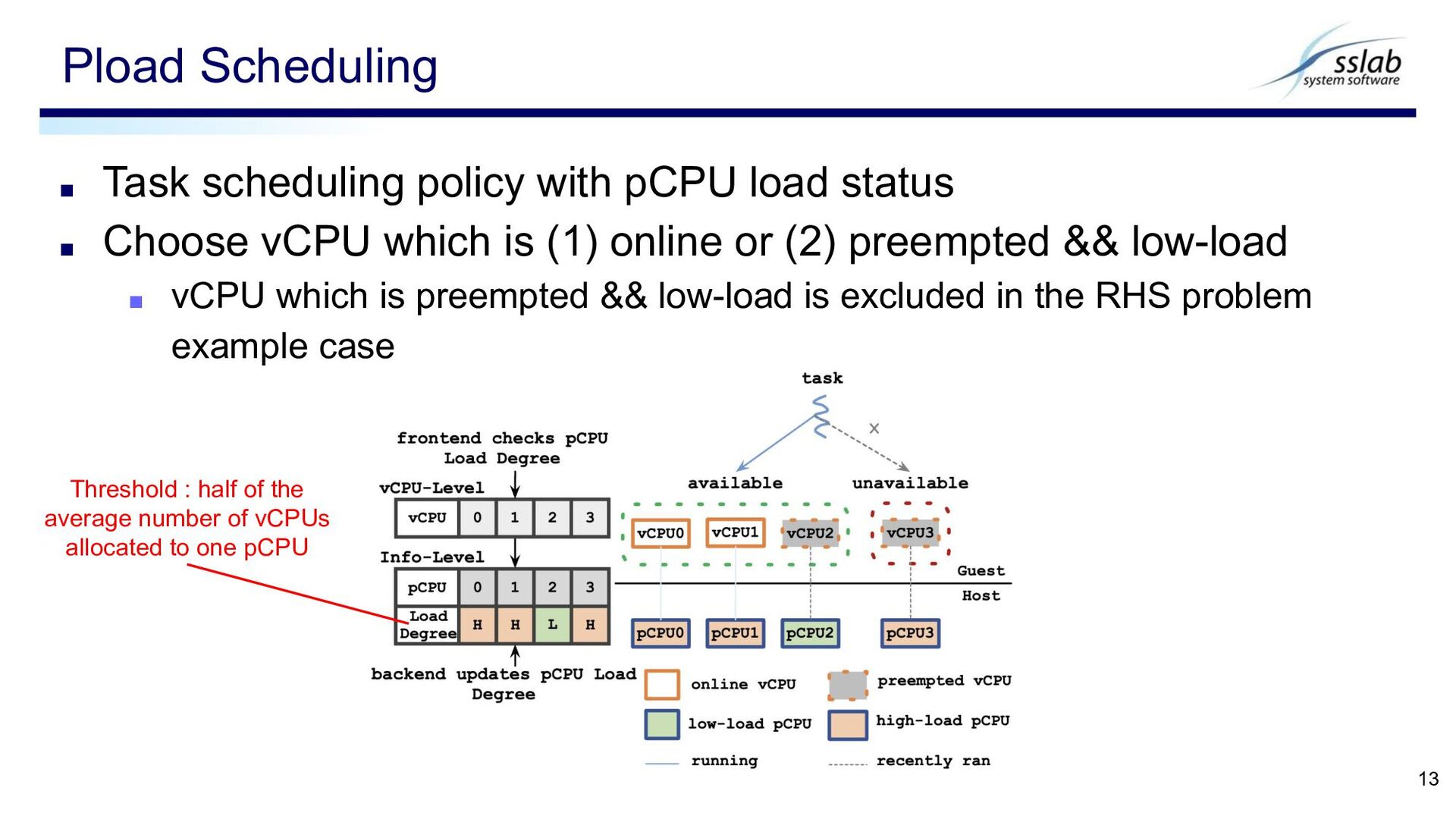
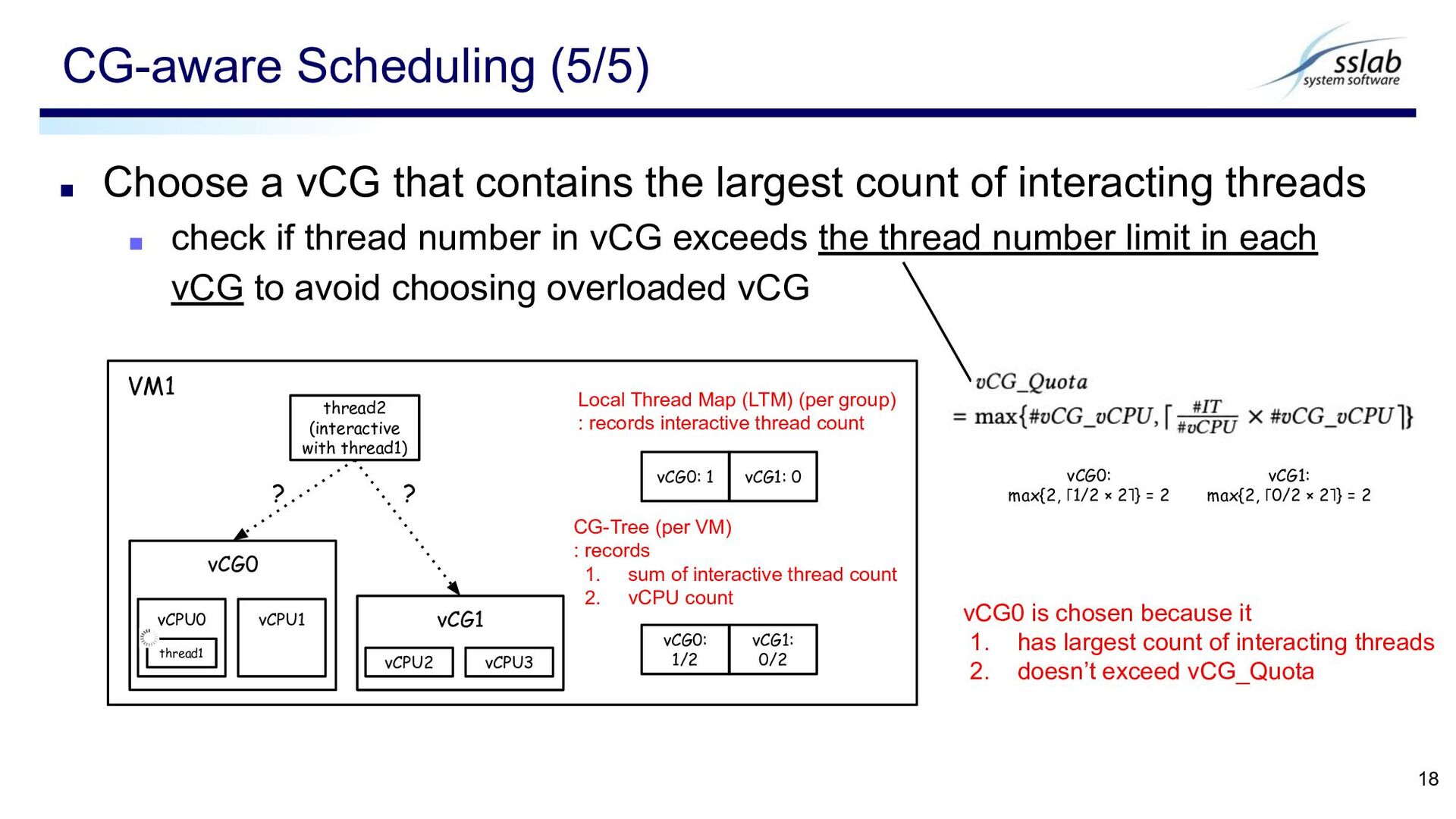
status ▪ Choose vCPU which is (1) online or (2) preempted && low-load ▪ vCPU which is preempted && low-load is excluded in the RHS problem example case Threshold : half of the average number of vCPUs allocated to one pCPU
the number of vCPU candidates ▪ accessing LTM, CG-tree ▪ calculating vCG_Quota Microbenchmark 20 HVM: : without pvsched CPS-Pload : Pload scheduling (with pvsched) PVM : pvsched CPS-Pload : CG-aware scheduling (with pvsched) don’t use / use Refer-Table don’t use / use preempted and low-load vCPU use LTM, CG-Tree vCG_Quota
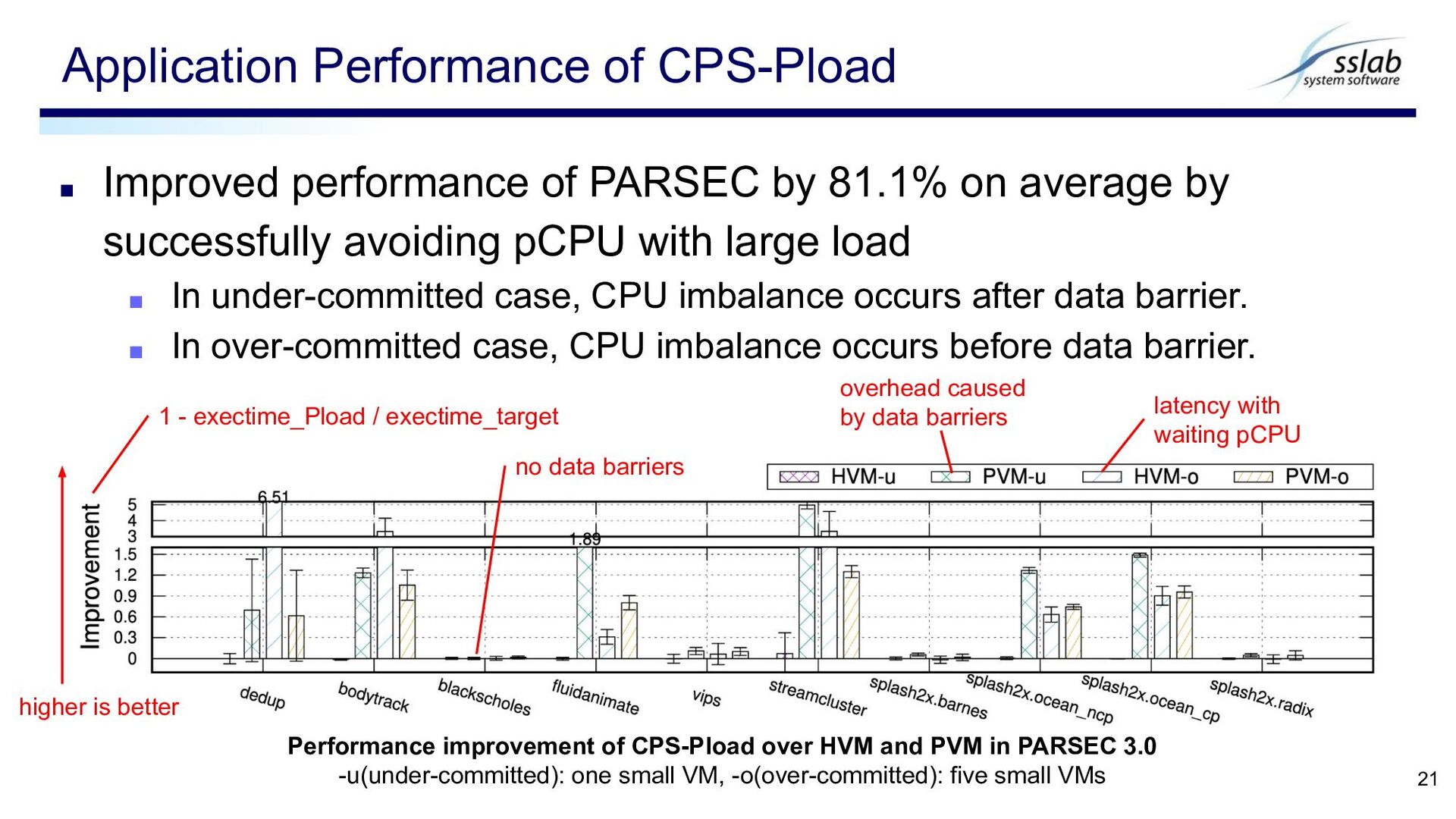
successfully avoiding pCPU with large load ▪ In under-committed case, CPU imbalance occurs after data barrier. ▪ In over-committed case, CPU imbalance occurs before data barrier. Application Performance of CPS-Pload 21 higher is better 1 - exectime_Pload / exectime_target Performance improvement of CPS-Pload over HVM and PVM in PARSEC 3.0 -u(under-committed): one small VM, -o(over-committed): five small VMs overhead caused by data barriers no data barriers latency with waiting pCPU
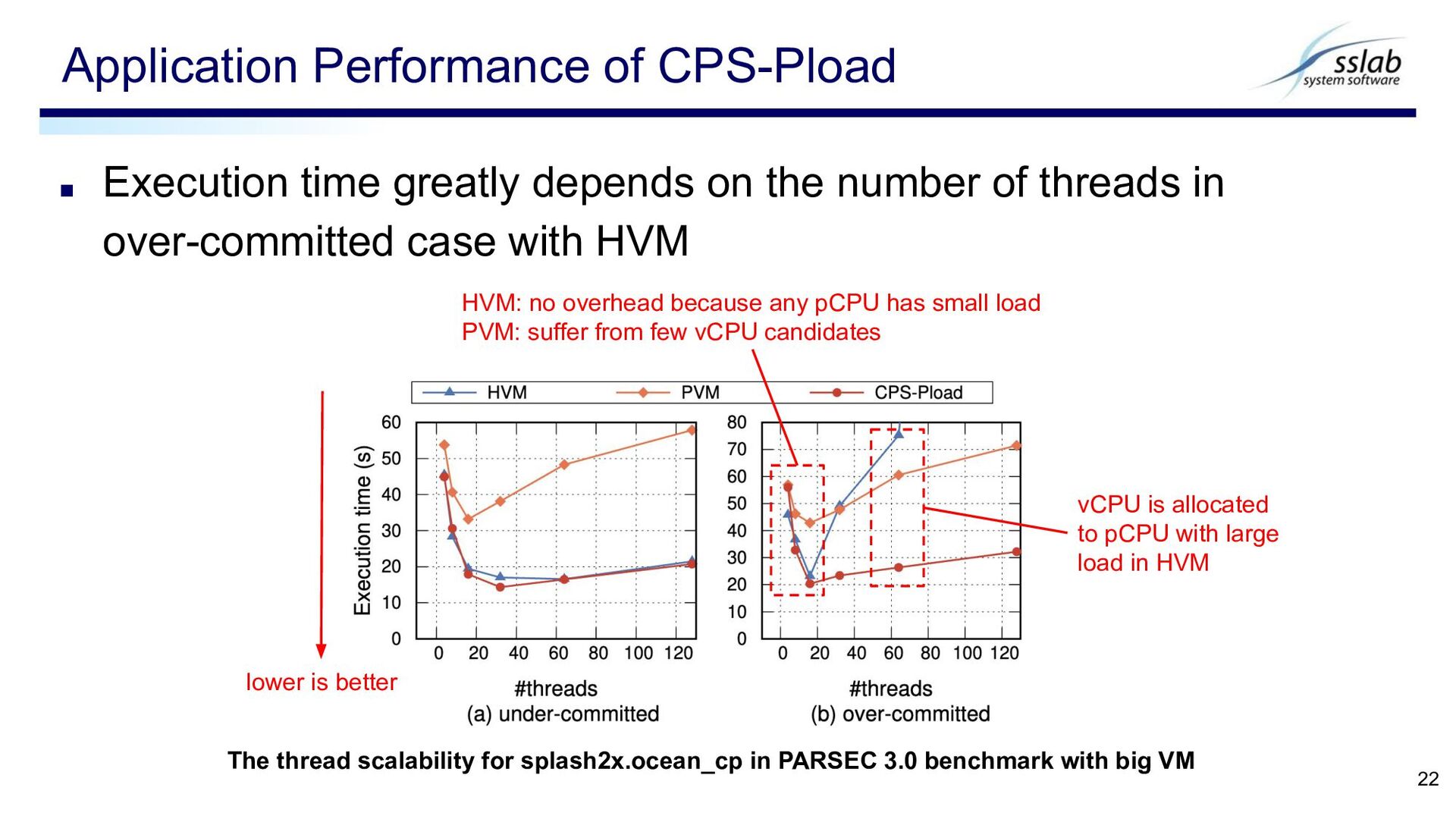
in over-committed case with HVM Application Performance of CPS-Pload 22 lower is better HVM: no overhead because any pCPU has small load PVM: suffer from few vCPU candidates vCPU is allocated to pCPU with large load in HVM The thread scalability for splash2x.ocean_cp in PARSEC 3.0 benchmark with big VM
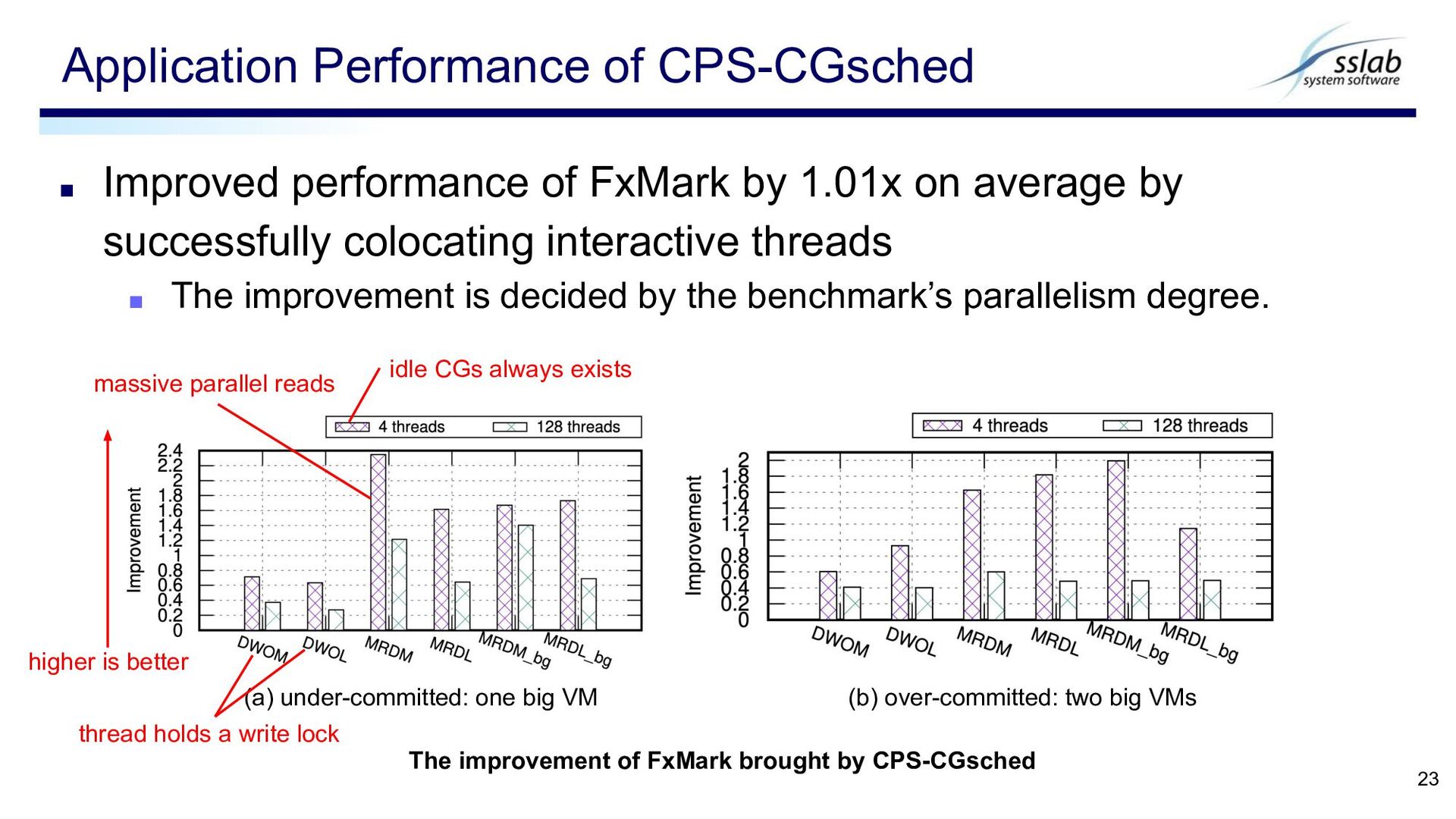
successfully colocating interactive threads ▪ The improvement is decided by the benchmark’s parallelism degree. Application Performance of CPS-CGsched 23 The improvement of FxMark brought by CPS-CGsched (a) under-committed: one big VM (b) over-committed: two big VMs higher is better idle CGs always exists massive parallel reads thread holds a write lock
absence of RHS. ▪ CPS allows host and guest to share dynamic scheduling information made by each other. ▪ Improved performance of PARSEC by 81.1% and FxMark by 1.01x on average for the two RHS problems. Conclusion 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}