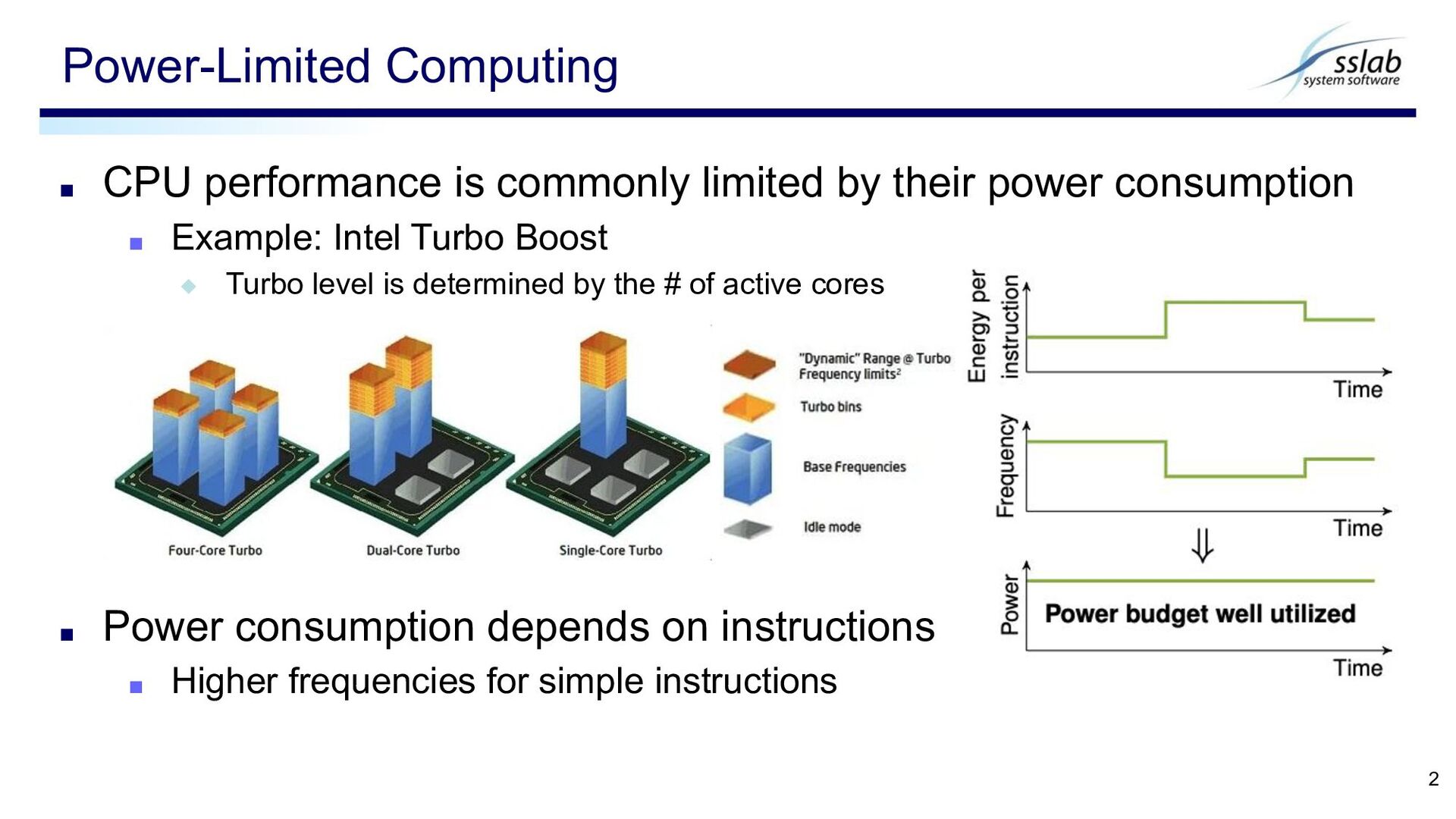
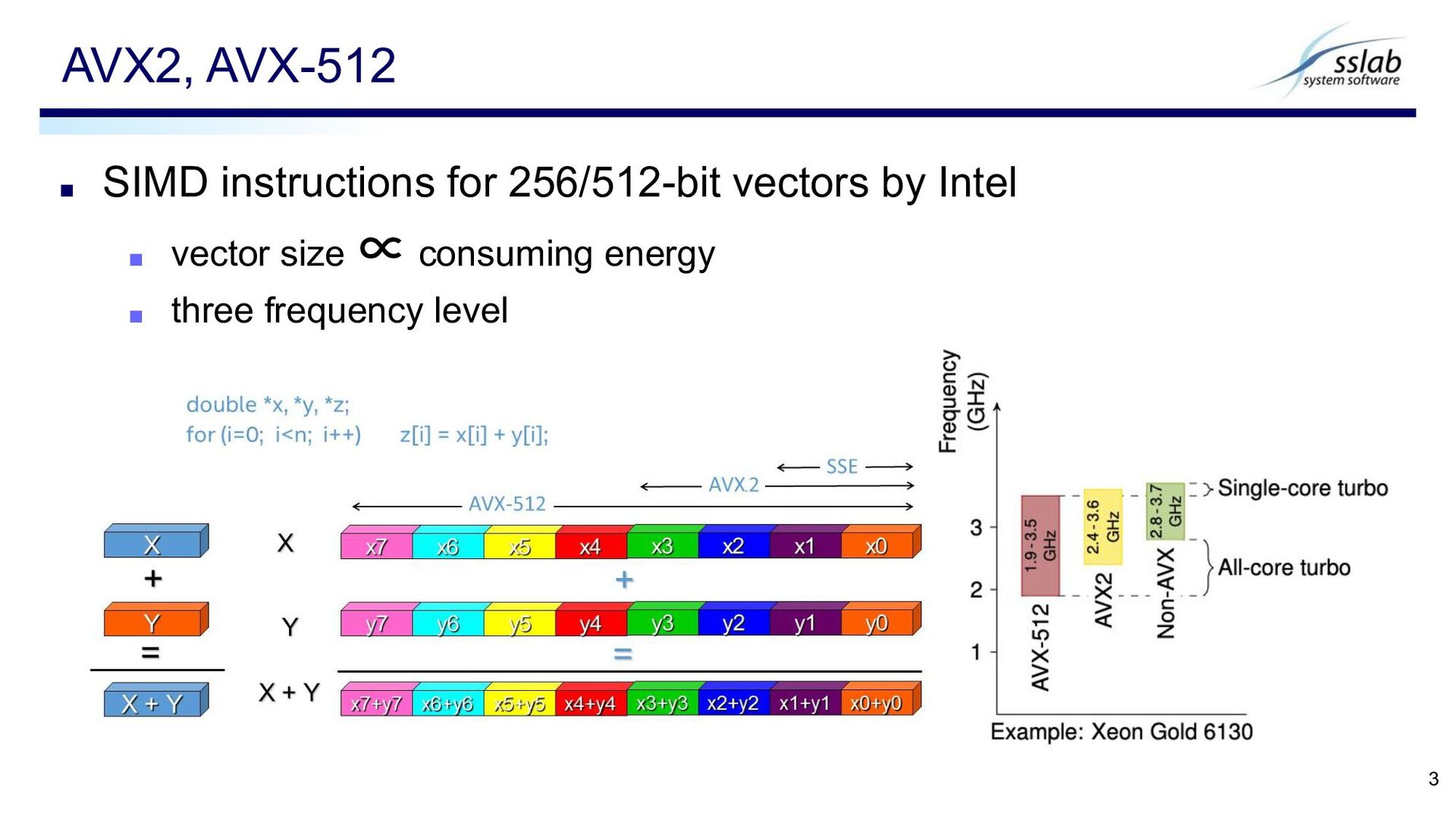
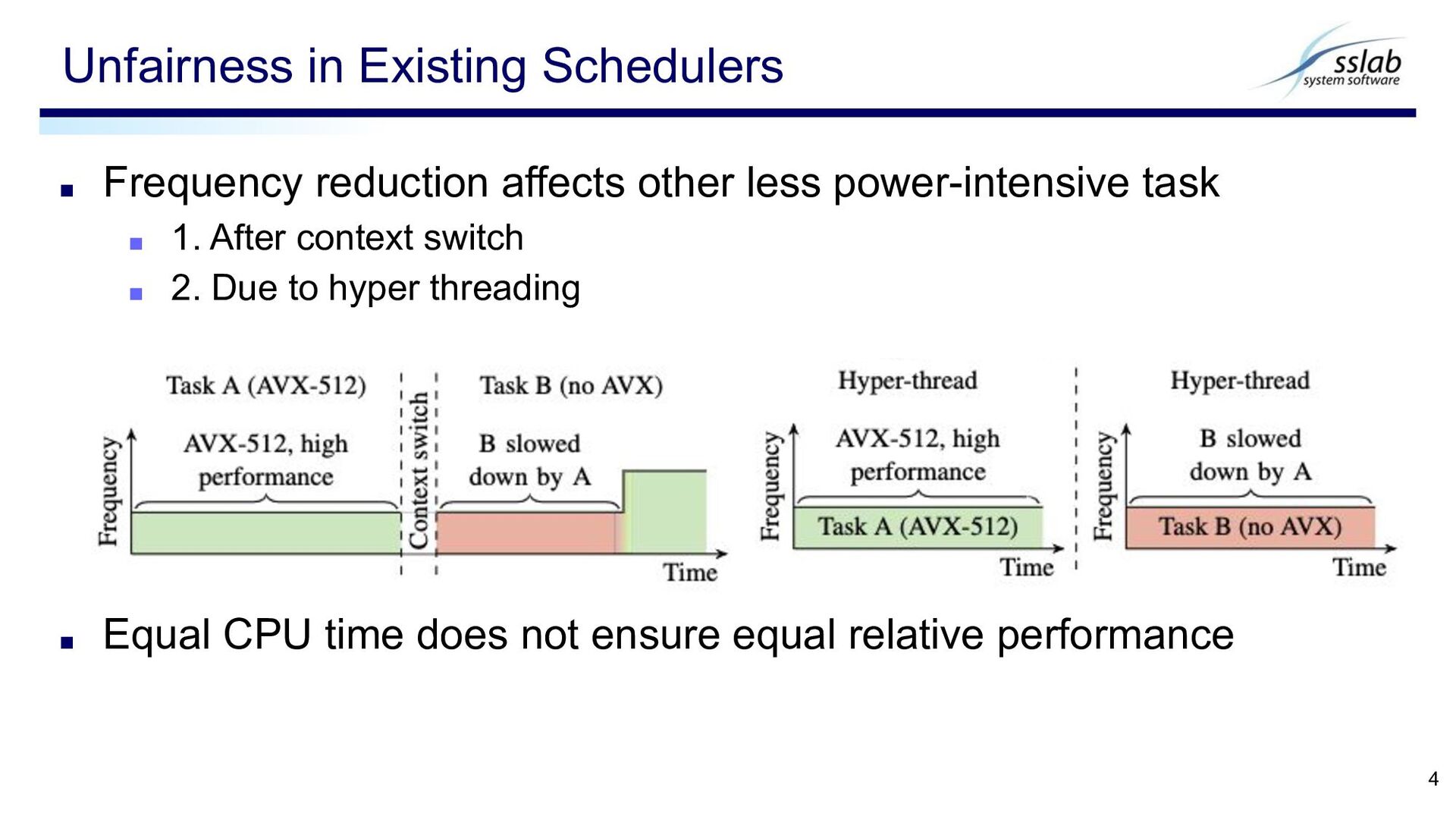
▪ Example: Intel Turbo Boost ◆ Turbo level is determined by the # of active cores ▪ Power consumption depends on instructions ▪ Higher frequencies for simple instructions Power-Limited Computing 2
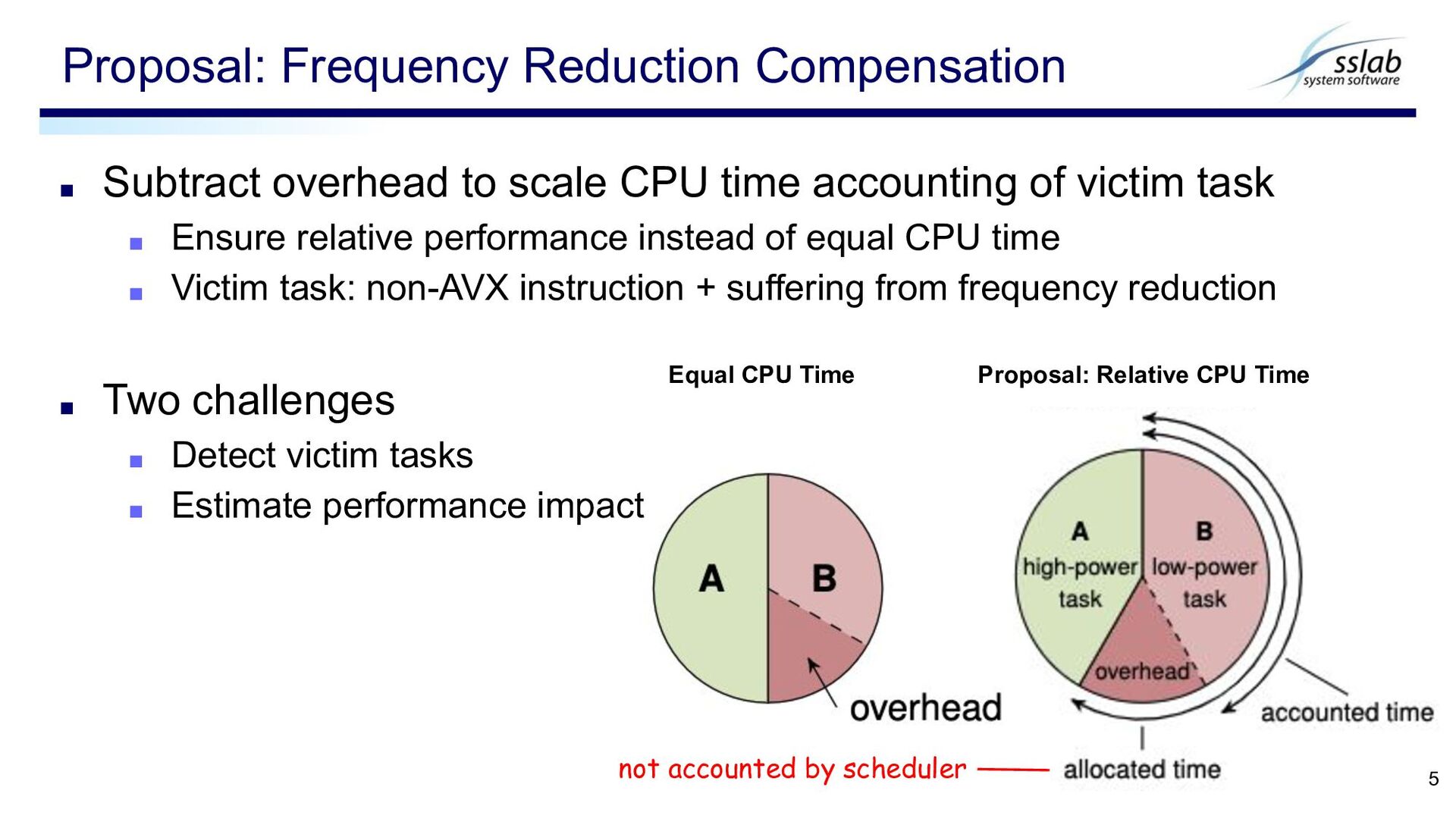
Time not accounted by scheduler ▪ Subtract overhead to scale CPU time accounting of victim task ▪ Ensure relative performance instead of equal CPU time ▪ Victim task: non-AVX instruction + suffering from frequency reduction ▪ Two challenges ▪ Detect victim tasks ▪ Estimate performance impact 5
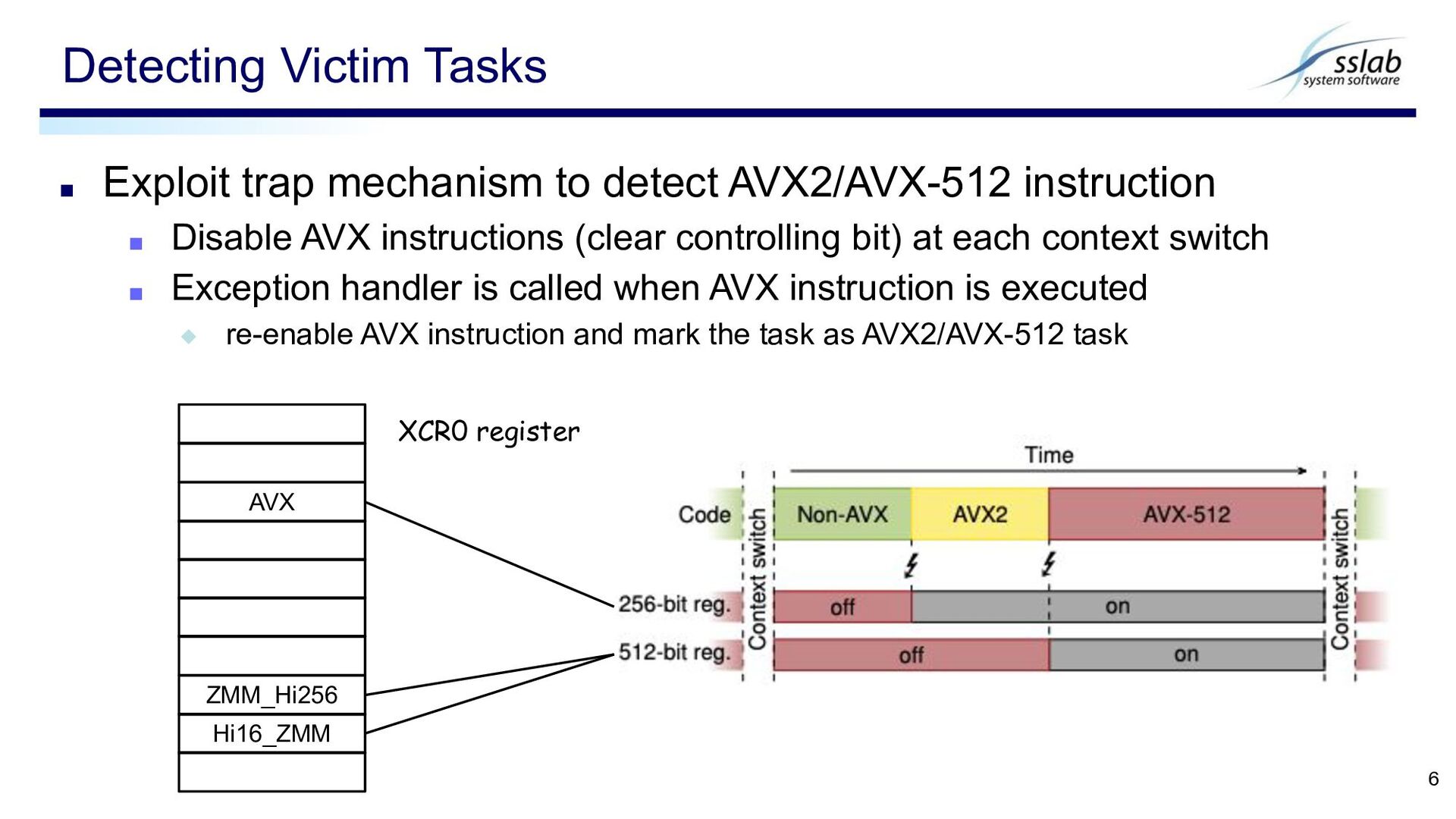
AVX instructions (clear controlling bit) at each context switch ▪ Exception handler is called when AVX instruction is executed ◆ re-enable AVX instruction and mark the task as AVX2/AVX-512 task Detecting Victim Tasks 6 AVX ZMM_Hi256 Hi16_ZMM XCR0 register
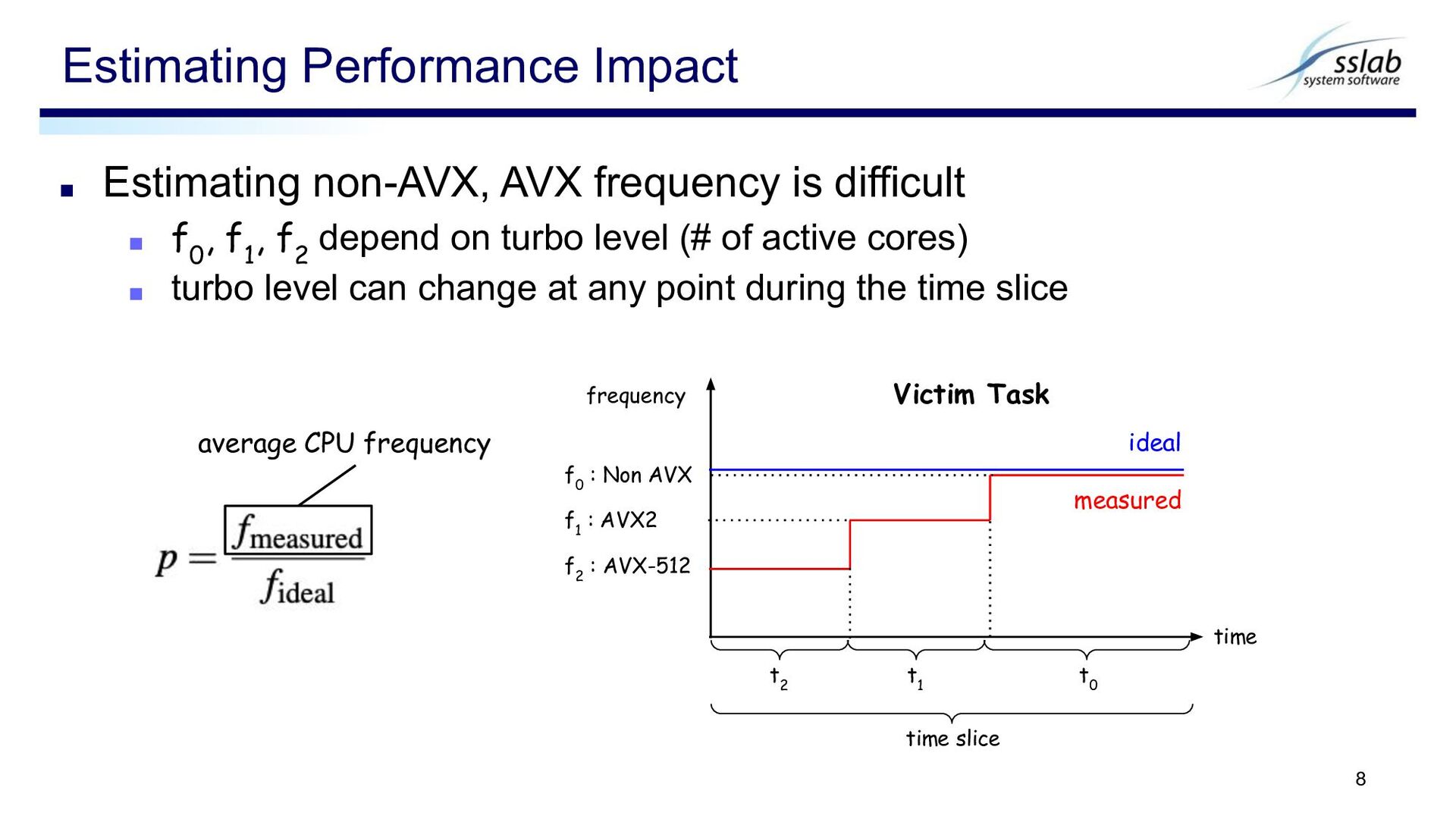
actual frequency ▪ Not add the entire time slice to vruntime Estimating Performance Impact 7 frequency time f 0 : Non AVX f 1 : AVX2 f 2 : AVX-512 measured t 0 t 1 t 2 time slice ideal average CPU frequency Victim Task
, f 1 , f 2 depend on turbo level (# of active cores) ▪ turbo level can change at any point during the time slice Estimating Performance Impact 8 average CPU frequency frequency time f 0 : Non AVX f 1 : AVX2 f 2 : AVX-512 measured t 0 t 1 t 2 time slice ideal Victim Task
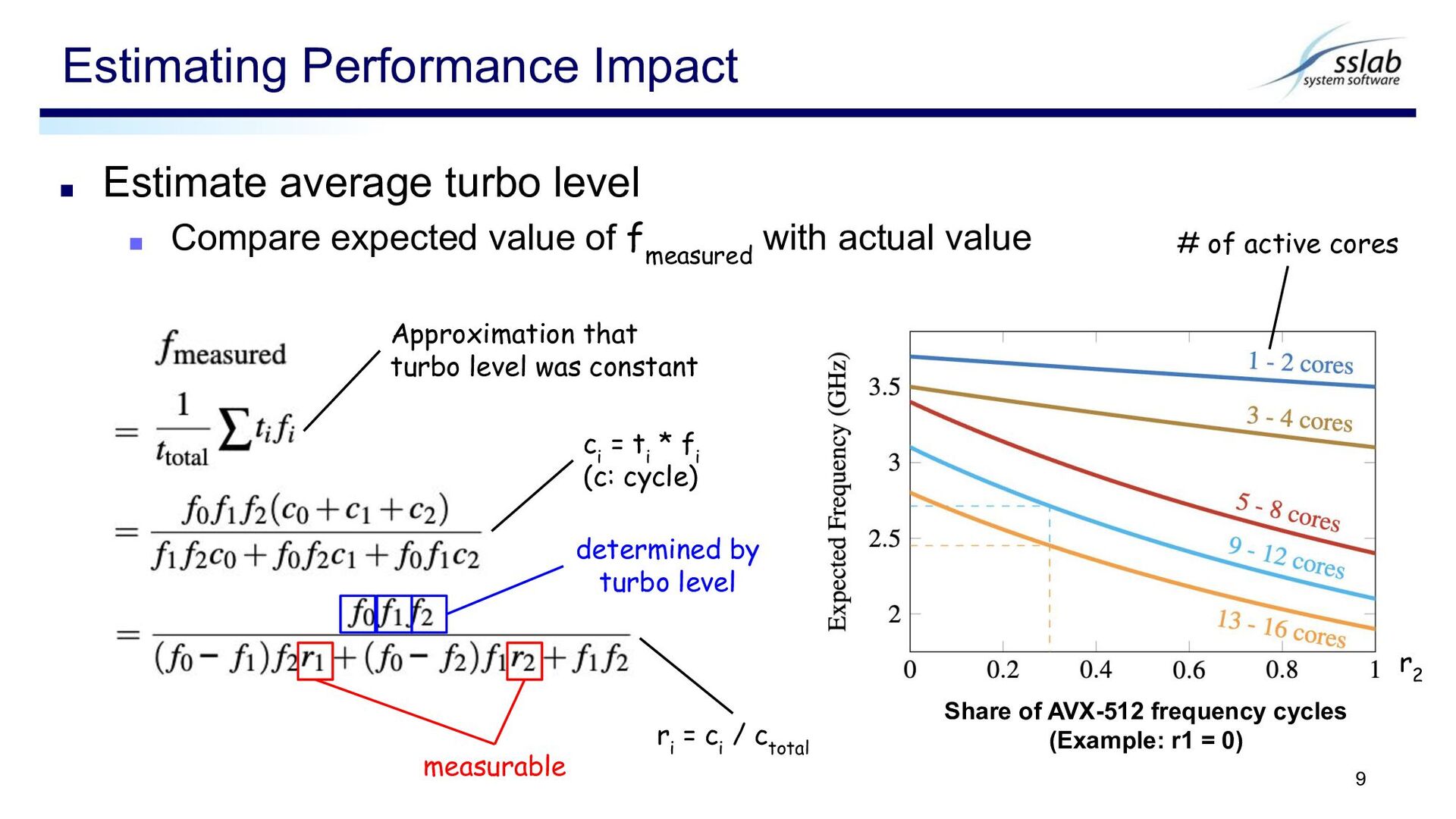
f measured with actual value Estimating Performance Impact 9 c i = t i * f i (c: cycle) r i = c i / c total measurable determined by turbo level Share of AVX-512 frequency cycles (Example: r1 = 0) r 2 Approximation that turbo level was constant # of active cores
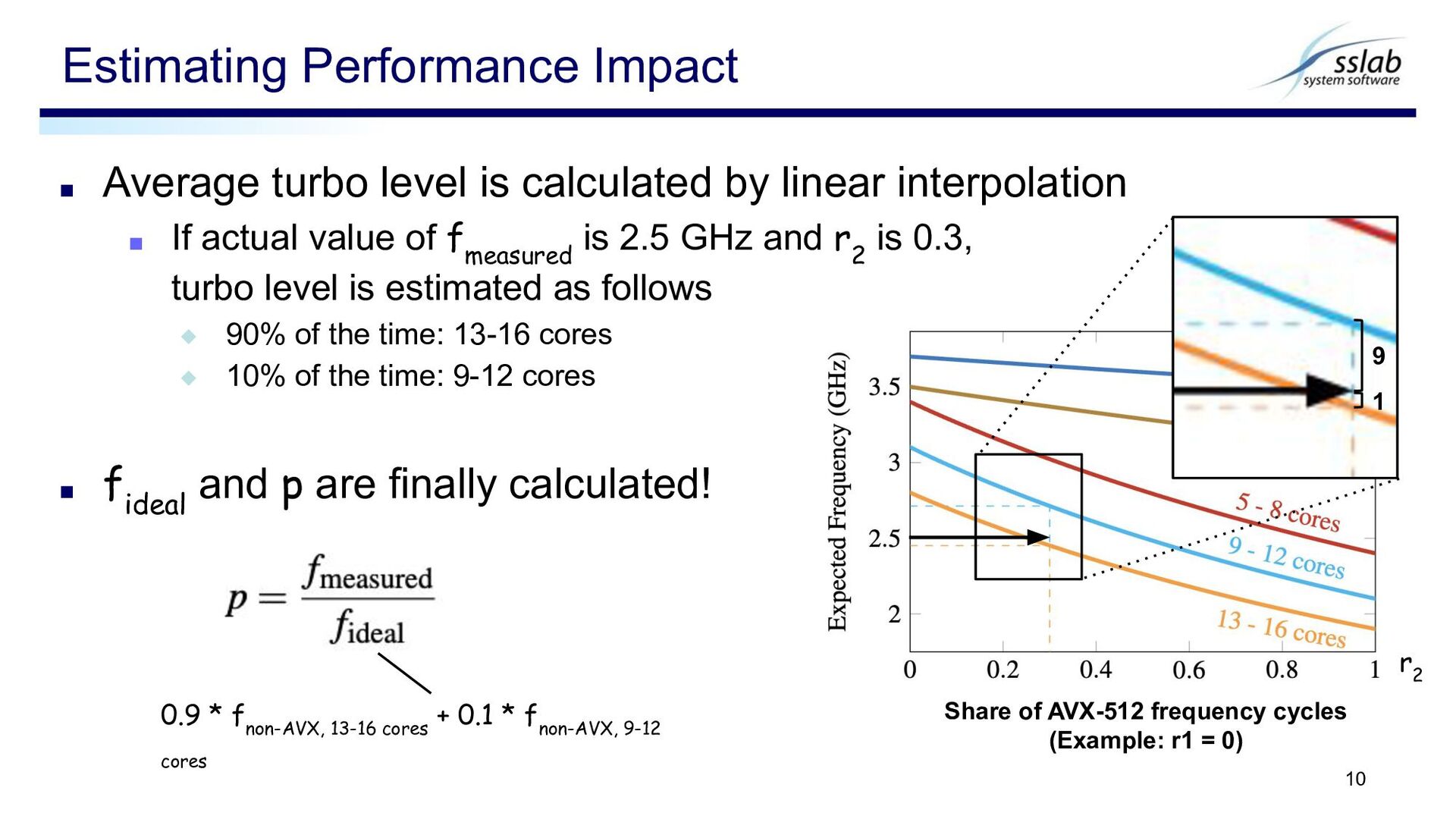
If actual value of f measured is 2.5 GHz and r 2 is 0.3, turbo level is estimated as follows ◆ 90% of the time: 13-16 cores ◆ 10% of the time: 9-12 cores ▪ f ideal and p are finally calculated! Estimating Performance Impact 10 Share of AVX-512 frequency cycles (Example: r1 = 0) r 2 9 1 0.9 * f non-AVX, 13-16 cores + 0.1 * f non-AVX, 9-12 cores
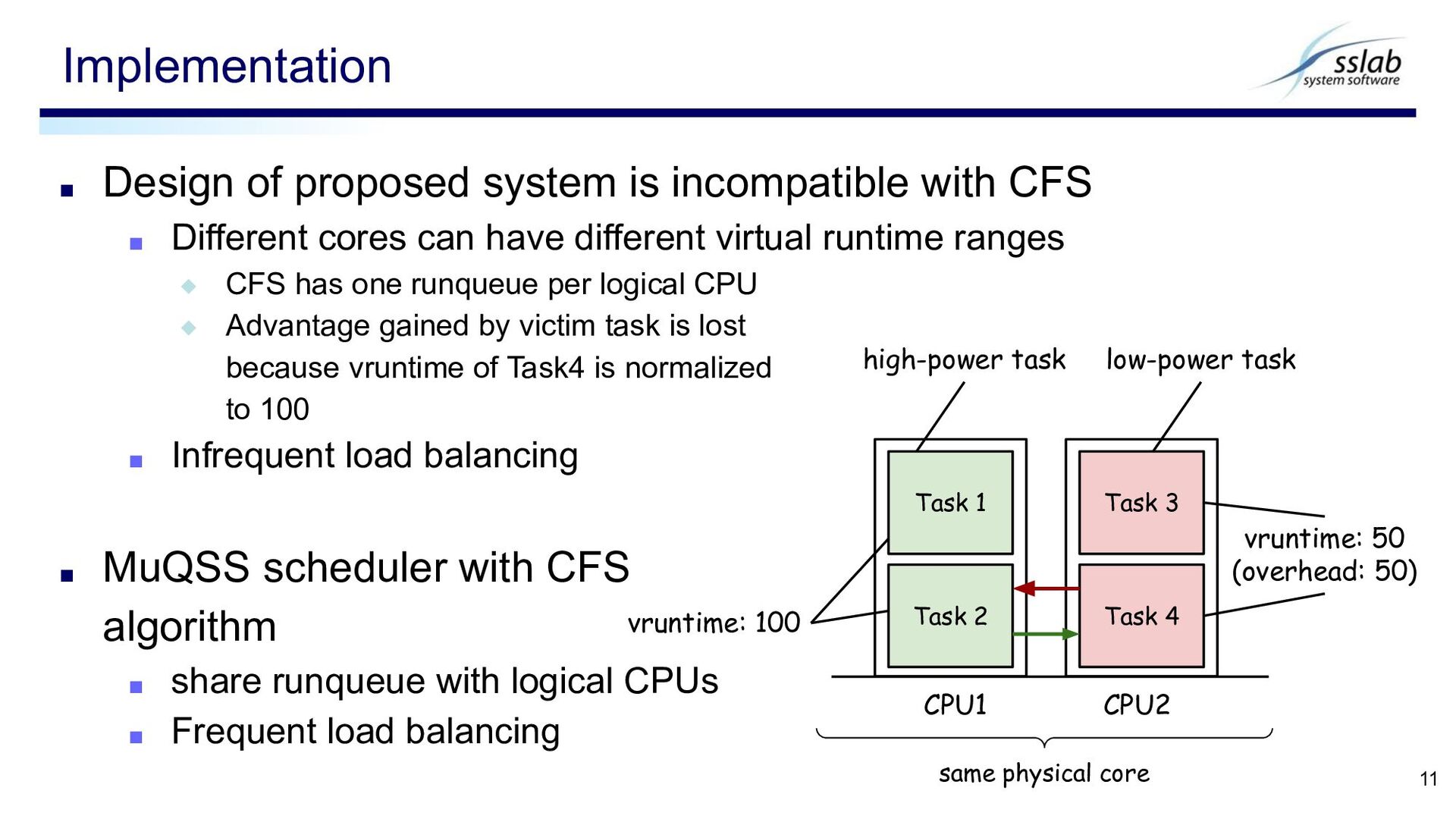
Different cores can have different virtual runtime ranges ◆ CFS has one runqueue per logical CPU ◆ Advantage gained by victim task is lost because vruntime of Task4 is normalized to 100 ▪ Infrequent load balancing ▪ MuQSS scheduler with CFS algorithm ▪ share runqueue with logical CPUs ▪ Frequent load balancing Implementation 11 same physical core low-power task high-power task vruntime: 100 vruntime: 50 (overhead: 50) Task 1 Task 2 Task 3 Task 4 CPU1 CPU2
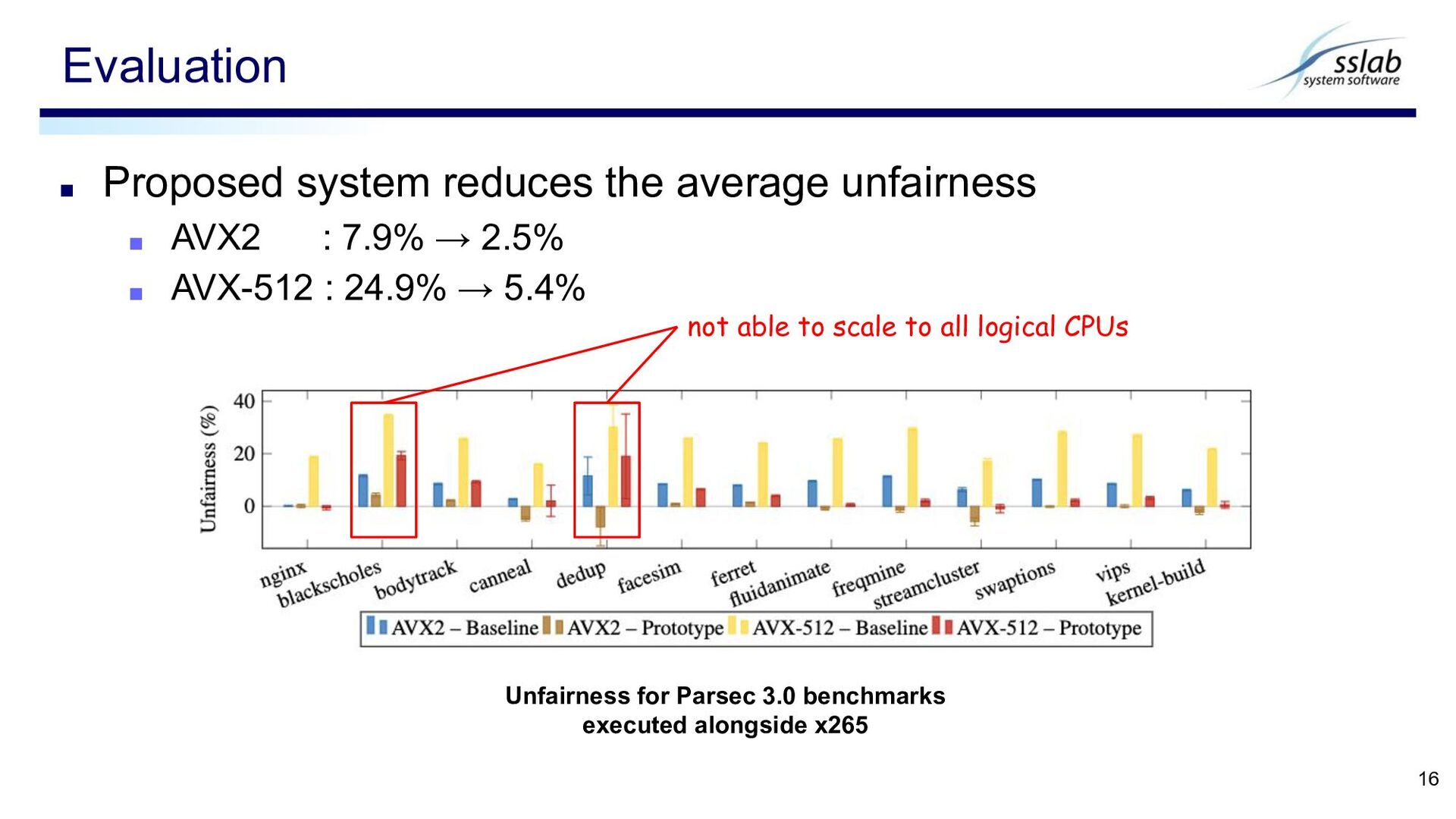
Additional overhead introduced? ▪ Execute benchmarks alongside x265 which uses AVX2/AVX-512 ▪ 4 instances of x265 video encoder with 8 threads ◆ configured to use either AVX2, AVX-512 Evaluation 13
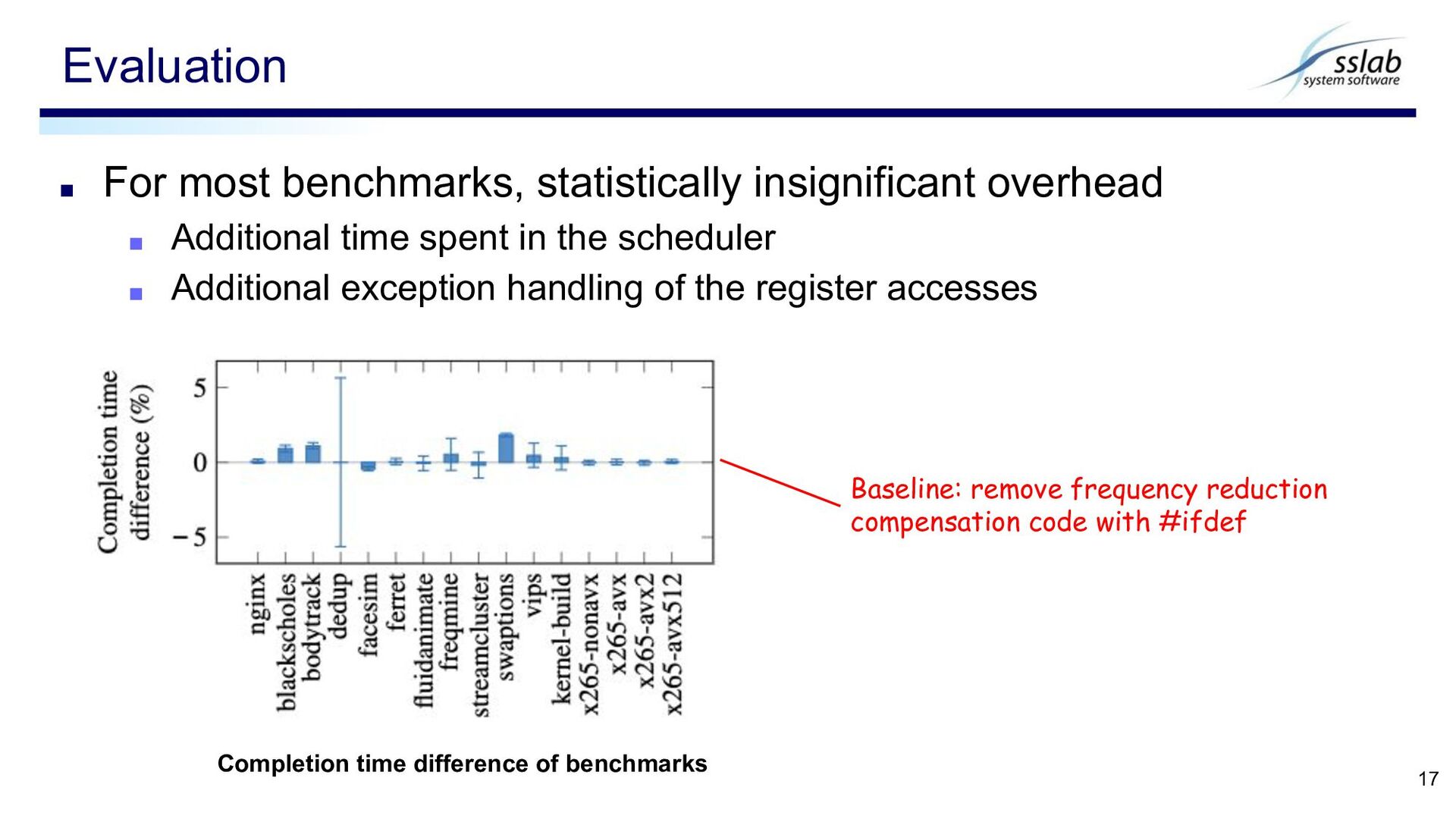
spent in the scheduler ▪ Additional exception handling of the register accesses Evaluation 17 Baseline: remove frequency reduction compensation code with #ifdef Completion time difference of benchmarks
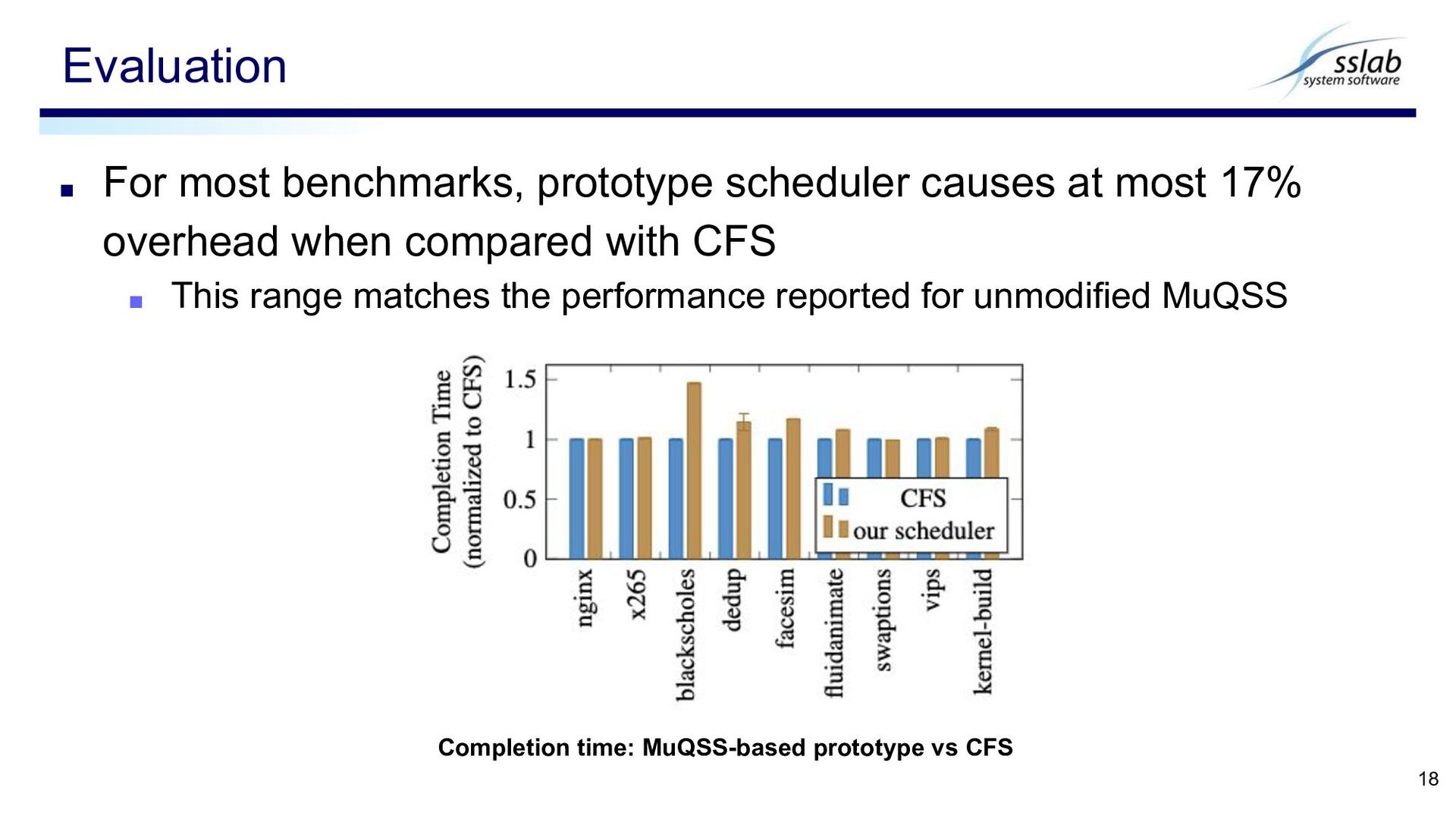
overhead when compared with CFS ▪ This range matches the performance reported for unmodified MuQSS Evaluation 18 Completion time: MuQSS-based prototype vs CFS
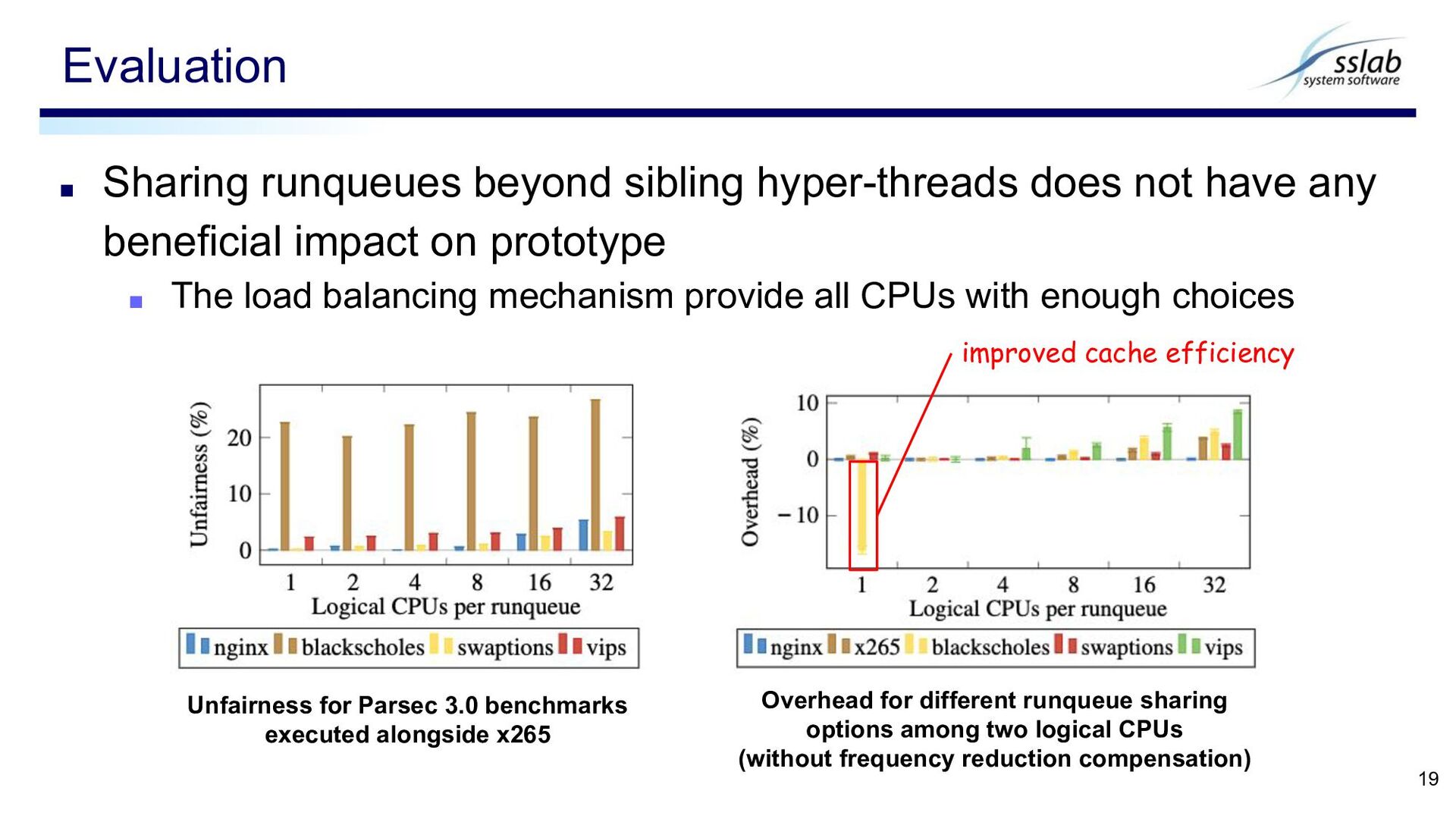
beneficial impact on prototype ▪ The load balancing mechanism provide all CPUs with enough choices Evaluation 19 Unfairness for Parsec 3.0 benchmarks executed alongside x265 Overhead for different runqueue sharing options among two logical CPUs (without frequency reduction compensation) improved cache efficiency
the basis for scheduling ▪ Not viable on current hardware as the CPUs lack interfaces required for sufficiently accurate energy models ▪ Core scheduling [Aubrey+, LPC ’19] ▪ Limit co-scheduling of AVX-512 and non-AVX tasks ▪ May leaves hyper-threads idle, which cause reduced utilization of CPU Related Works 20
▪ CPU frequency reduction may affects tasks that do not execute such power-intensive instructions ▪ This paper propose a system to achieve fair scheduling ▪ Frequency reduction compensation ▪ Trap-based detection of affected tasks ▪ Prototype reduced unfairness for AVX-512 workload by 4x Conclusion 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![▪ ECOSystem [Heng+, SIGOPS ’02] ▪ Use consumed energy as](https://files.speakerdeck.com/presentations/a65a2d8a39ab45e38f4819197a727f5e/slide_19.jpg){kind=link}
{kind=link}