Packing Jinsu Park1, Seongbeom Park1, Myeonggyun Han1, Woongki Baek2 (1Department of CSE, UNIST, 2Department of CSE and Graduate School of AI, UNIST) Keio University Kono Laboratory, Daiki Wakabayashi IPDPS ’21
Launch an app with fewer number of threads than available cores ▪ ✔ Easy to ensure fairness between threads ▪ ✖ System performance needs to be considered by the app ▪ ✖ Vulnerable to the change such as core counts and energy ▪ ✖ Vulnerable to the colocated applications Thread Reduction (TR) 2 App thread0 Core0 App thread1 Core1 App thread2 Core2
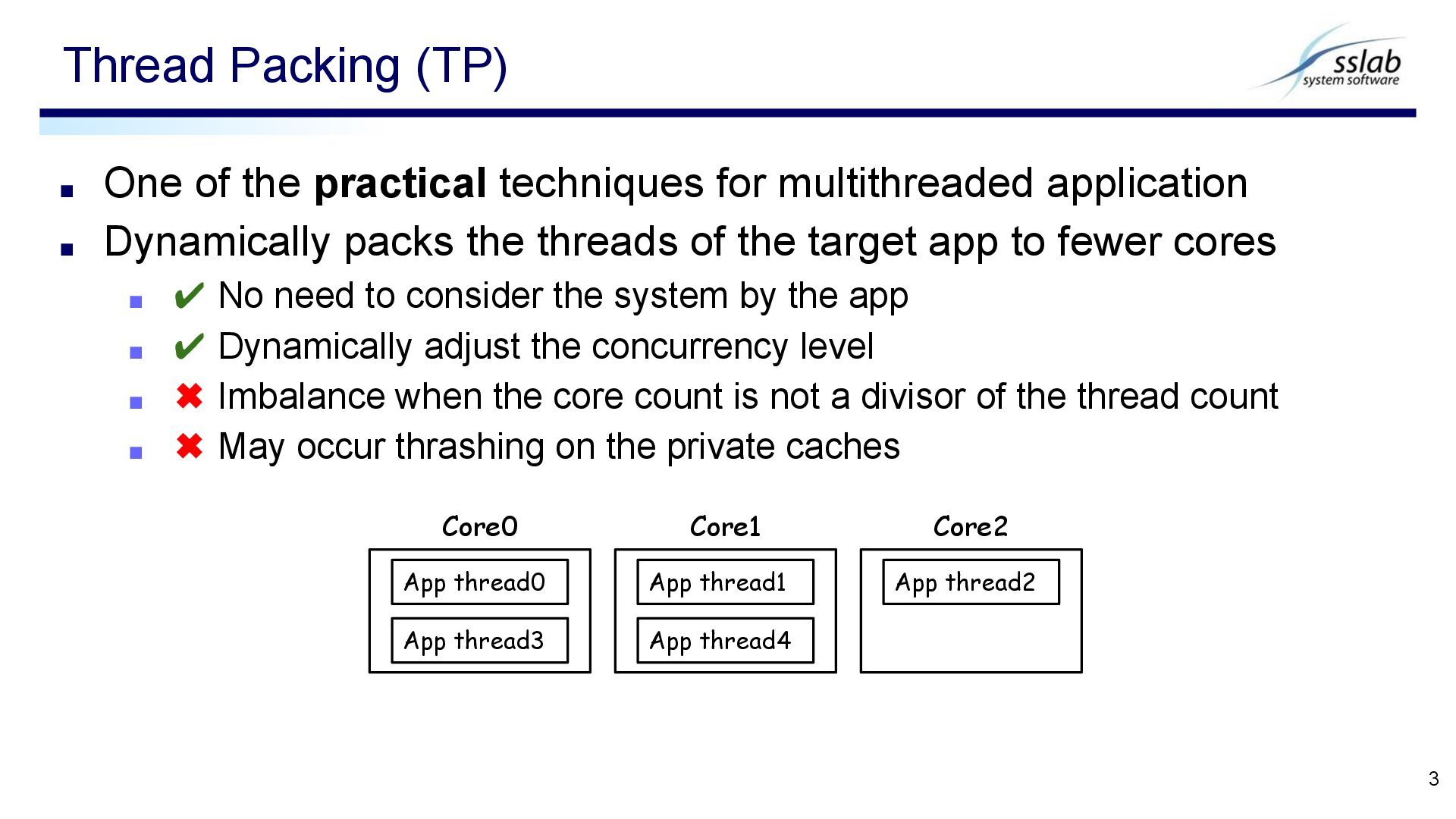
Dynamically packs the threads of the target app to fewer cores ▪ ✔ No need to consider the system by the app ▪ ✔ Dynamically adjust the concurrency level ▪ ✖ Imbalance when the core count is not a divisor of the thread count ▪ ✖ May occur thrashing on the private caches Thread Packing (TP) 3 App thread0 Core0 Core1 Core2 App thread3 App thread1 App thread4 App thread2
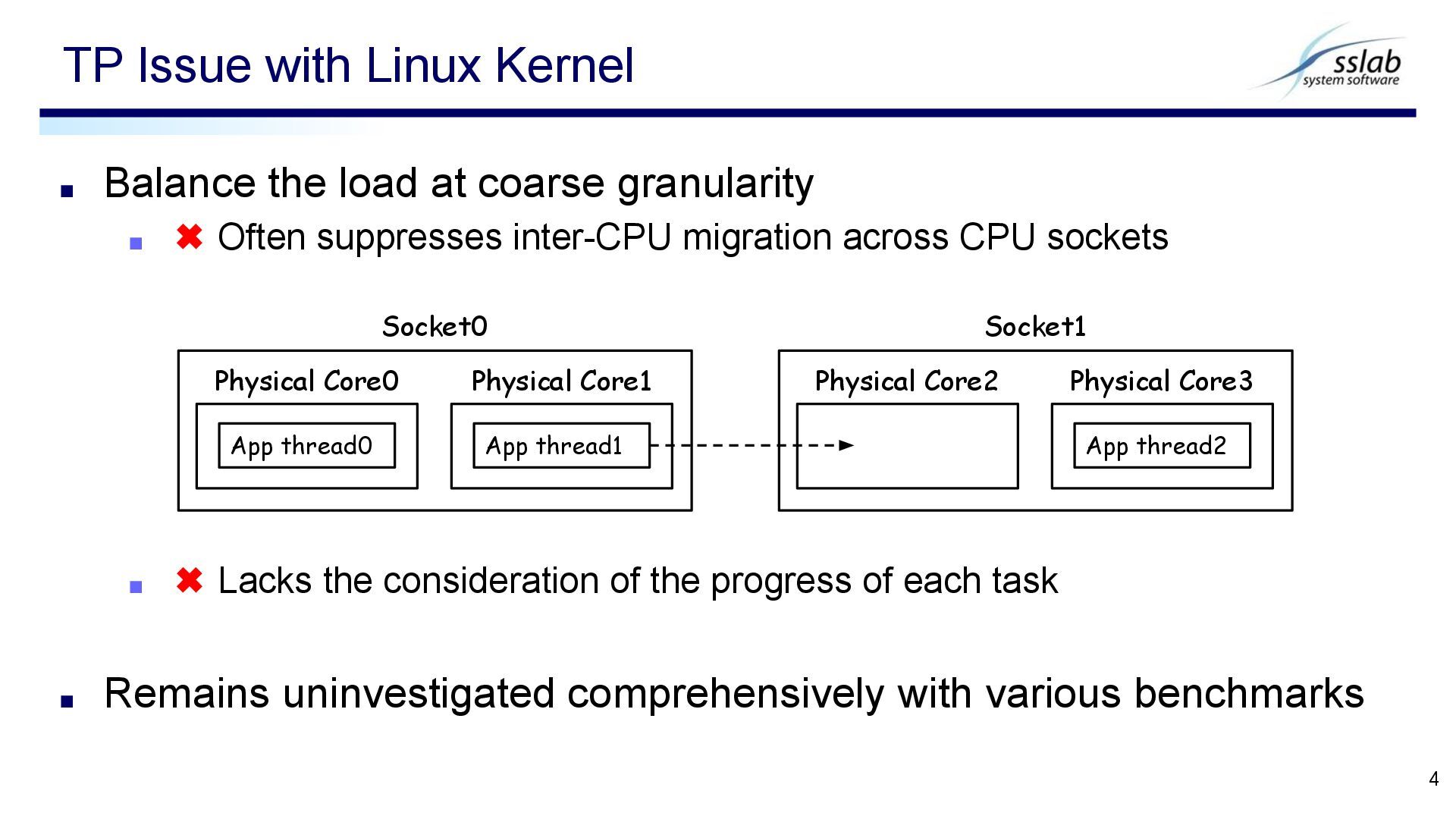
App thread1 Physical Core1 Socket0 Physical Core2 App thread2 Physical Core3 Socket1 ▪ Balance the load at coarse granularity ▪ ✖ Often suppresses inter-CPU migration across CPU sockets ▪ ✖ Lacks the consideration of the progress of each task ▪ Remains uninvestigated comprehensively with various benchmarks
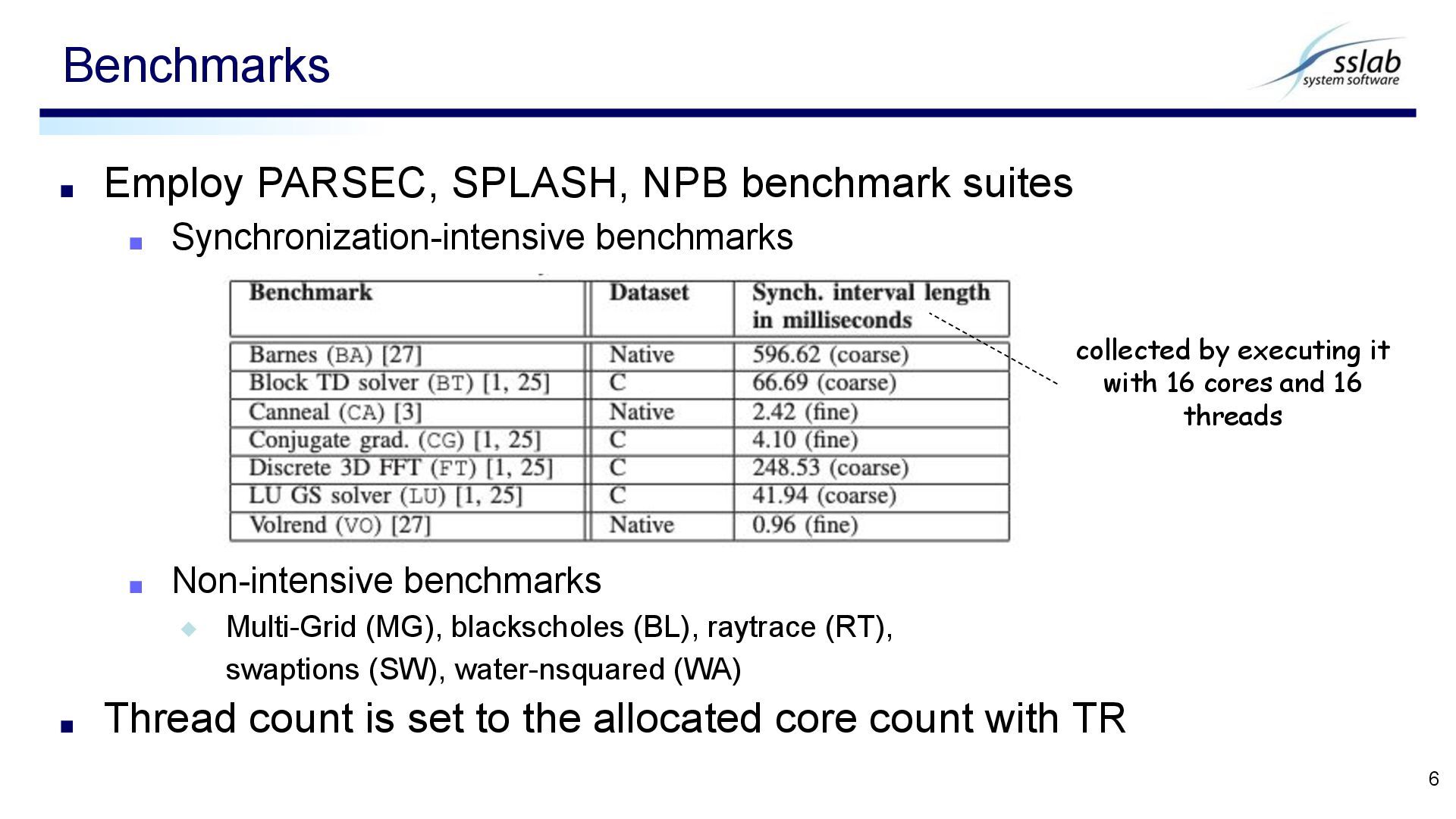
▪ Non-intensive benchmarks ◆ Multi-Grid (MG), blackscholes (BL), raytrace (RT), swaptions (SW), water-nsquared (WA) ▪ Thread count is set to the allocated core count with TR Benchmarks 6 collected by executing it with 16 cores and 16 threads
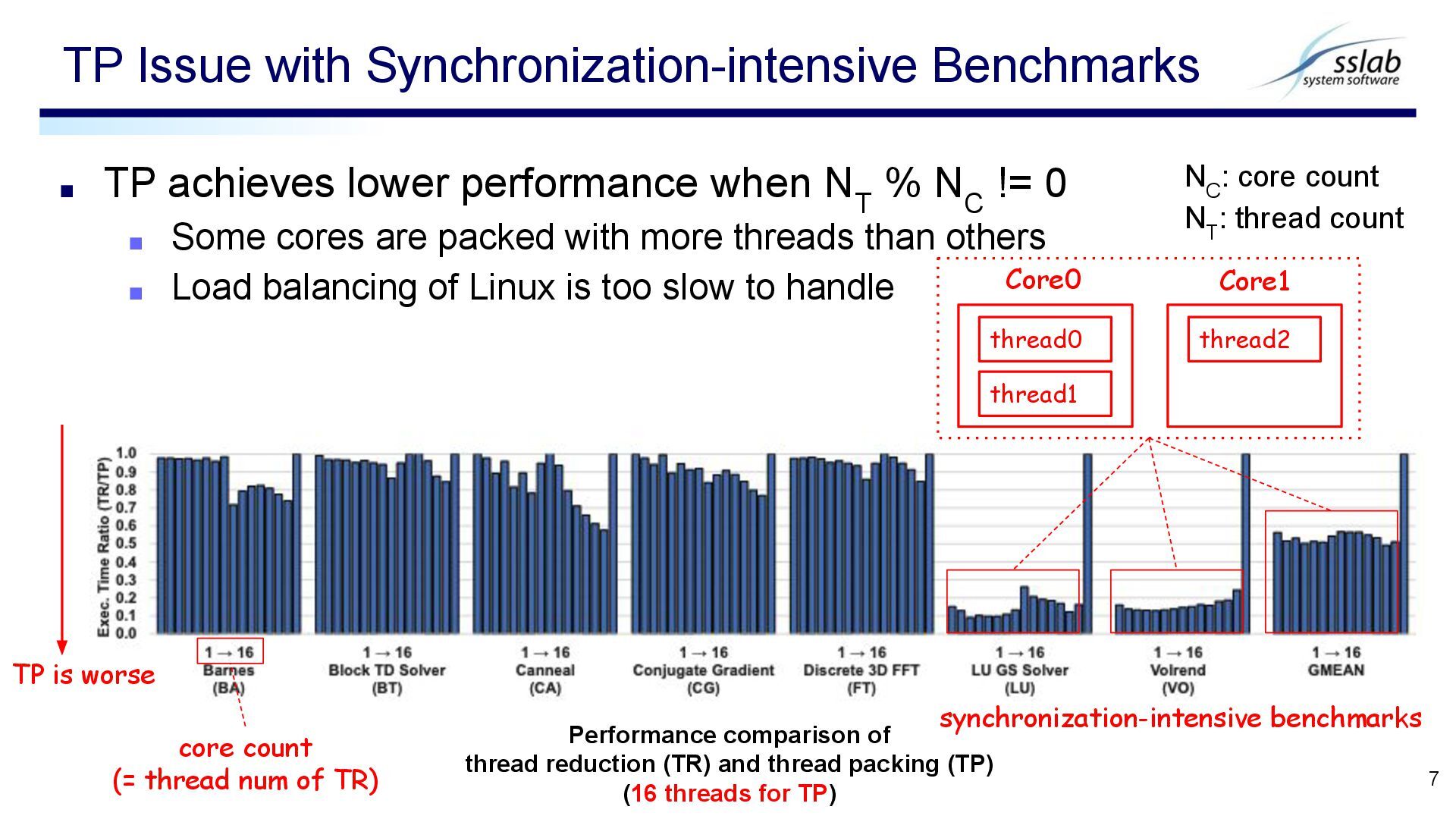
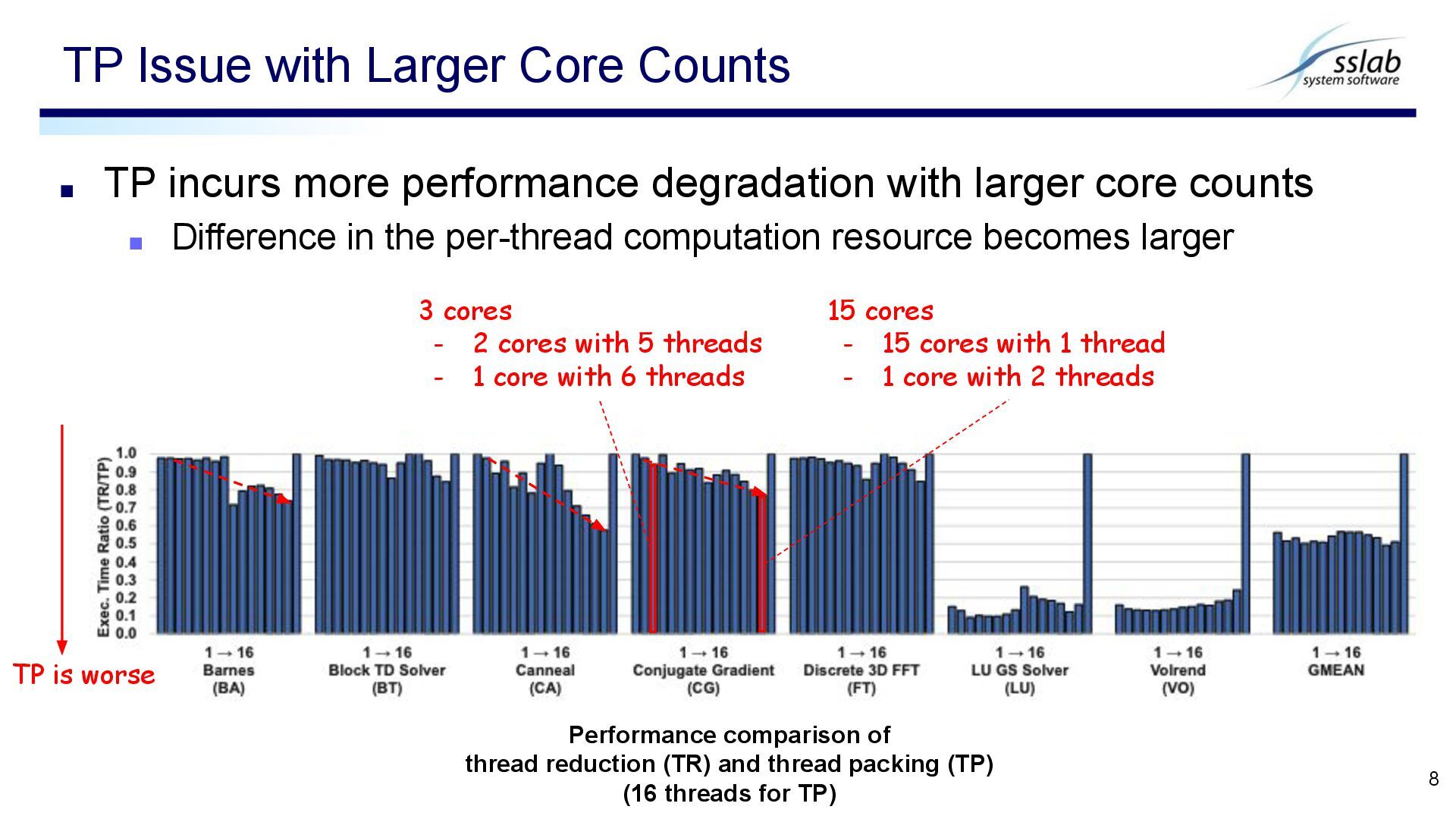
C != 0 ▪ Some cores are packed with more threads than others ▪ Load balancing of Linux is too slow to handle TP Issue with Synchronization-intensive Benchmarks 7 Performance comparison of thread reduction (TR) and thread packing (TP) (16 threads for TP) TP is worse synchronization-intensive benchmarks N C : core count N T : thread count thread0 Core0 thread1 Core1 core count (= thread num of TR) thread2
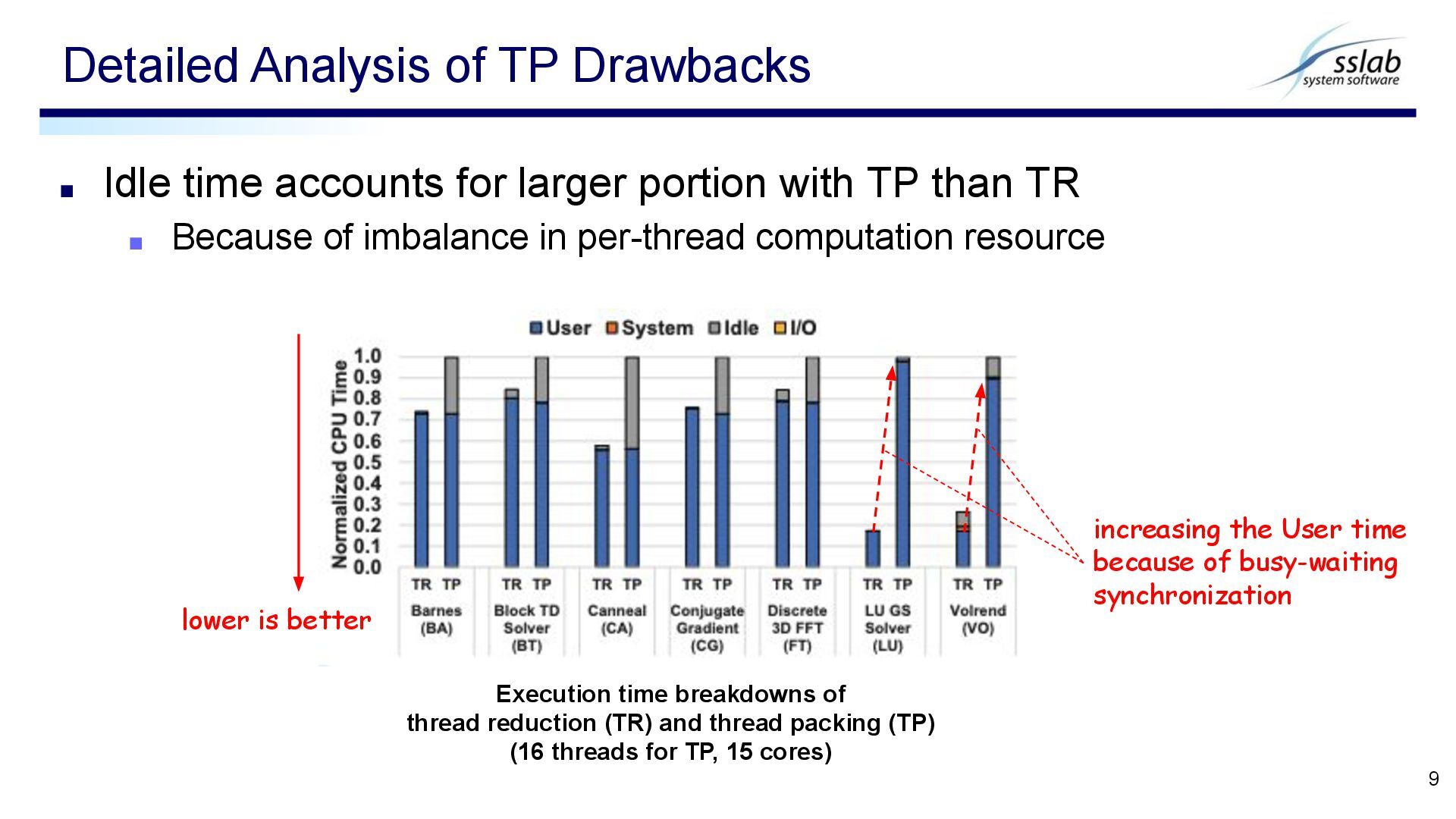
TR ▪ Because of imbalance in per-thread computation resource Detailed Analysis of TP Drawbacks 9 Execution time breakdowns of thread reduction (TR) and thread packing (TP) (16 threads for TP, 15 cores) lower is better increasing the User time because of busy-waiting synchronization
issue when N T % N C != 0 ▪ Handle the TP issue of cache thrashing ▪ Dynamical adjustment of the scheduling period ▪ Start with the shortest period (i.e., 0.125 ms) ▪ Handle the TP issue with synchronization-intensive benchmarks ▪ Support heterogeneous multiprocessing systems (HMP) ▪ Pack threads considering core capacity Proposal: PALM 10
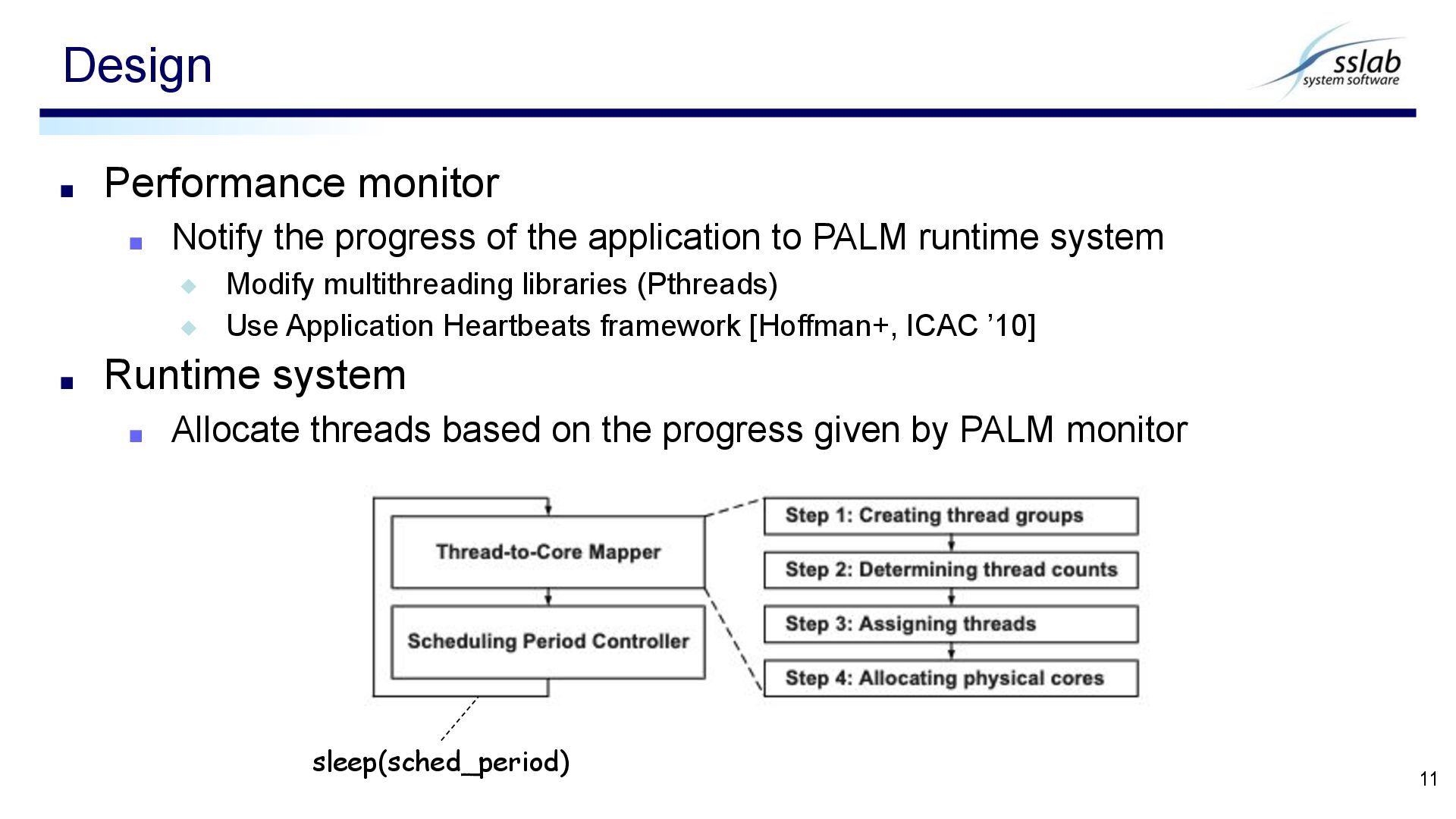
to PALM runtime system ◆ Modify multithreading libraries (Pthreads) ◆ Use Application Heartbeats framework [Hoffman+, ICAC ’10] ▪ Runtime system ▪ Allocate threads based on the progress given by PALM monitor Design 11 sleep(sched_period)
core count ▪ Each thread groups is assigned with ▪ the core type ◆ Different computation capacity in HMP environment ▪ 1 thread at least Step1: Creating thread groups 12 capacity: 360 thread_count: 1 capacity_per_thread: 360 Thread Group0 capacity: 220 thread_count: 1 capacity_per_thread: 220 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2
thread selects the thread group with the largest per-thread capacity Step2: Determining thread counts 14 capacity: 360 thread_count: 1 capacity_per_thread: 360 Thread Group0 capacity: 220 thread_count: 1 capacity_per_thread: 220 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2 When application is executed with 6 threads, remaining 3 threads need to be allocated.
thread selects the thread group with the largest per-thread capacity Step2: Determining thread counts 15 capacity: 360 thread_count: 2 capacity_per_thread: 180 Thread Group0 capacity: 220 thread_count: 1 capacity_per_thread: 220 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2 When application is executed with 6 threads, remaining 2 threads need to be allocated.
thread selects the thread group with the largest per-thread capacity Step2: Determining thread counts 16 capacity: 360 thread_count: 2 capacity_per_thread: 180 Thread Group0 capacity: 220 thread_count: 2 capacity_per_thread: 110 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2 When application is executed with 6 threads, remaining 1 threads need to be allocated.
thread selects the thread group with the largest per-thread capacity Step2: Determining thread counts 17 capacity: 360 thread_count: 3 capacity_per_thread: 120 Thread Group0 capacity: 220 thread_count: 2 capacity_per_thread: 110 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2 All threads have been allocated. ・Seems inefficient to allocate threads one by one … ・Similar operation is instrumented by Linux 6.8.0
capacity ▪ Priority is determined by the amount of resources thread has received ▪ Assigns consecutive threads to the same group to utilize cache, if possible Step3: Assigning threads 18 capacity: 360 thread_count: 3 capacity_per_thread: 120 Thread Group0 capacity: 220 thread_count: 2 capacity_per_thread: 110 Thread Group1 capacity: 100 thread_count: 1 capacity_per_thread: 100 Thread Group2 progress: 100 Thread3 progress: 120 Thread4 progress: 160 Thread5 progress: 200 Thread1 progress: 220 Thread2 progress: 300 Thread0 threads that have received a less amount of resources are assigned with thread group with large capacity
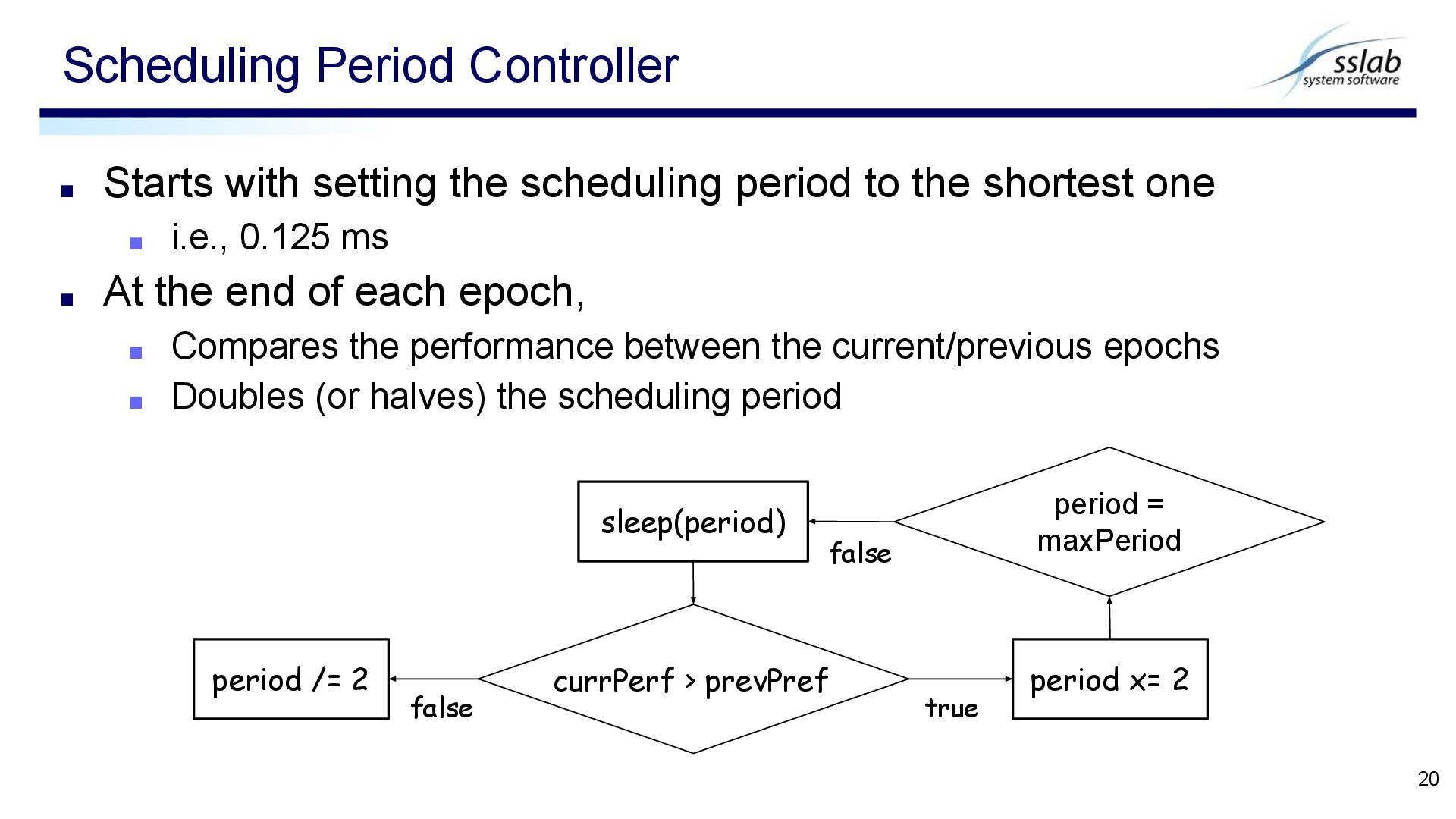
one ▪ i.e., 0.125 ms ▪ At the end of each epoch, ▪ Compares the performance between the current/previous epochs ▪ Doubles (or halves) the scheduling period Scheduling Period Controller 20 currPerf > prevPref period x= 2 period /= 2 true sleep(period) period = maxPeriod false false
Effectiveness for dynamic server consolidation and power capping ▪ 3. Performance impact of the PALM components ▪ 4. Performance sensitivity to the system parameters ▪ Setup ▪ Almost same as preliminary experiment ▪ Use TP, TR, PALM, SB ▪ 16 threads for TP, PALM, SB Evaluation 21 Static Best: PALM + optimal scheduling period by offline profiling
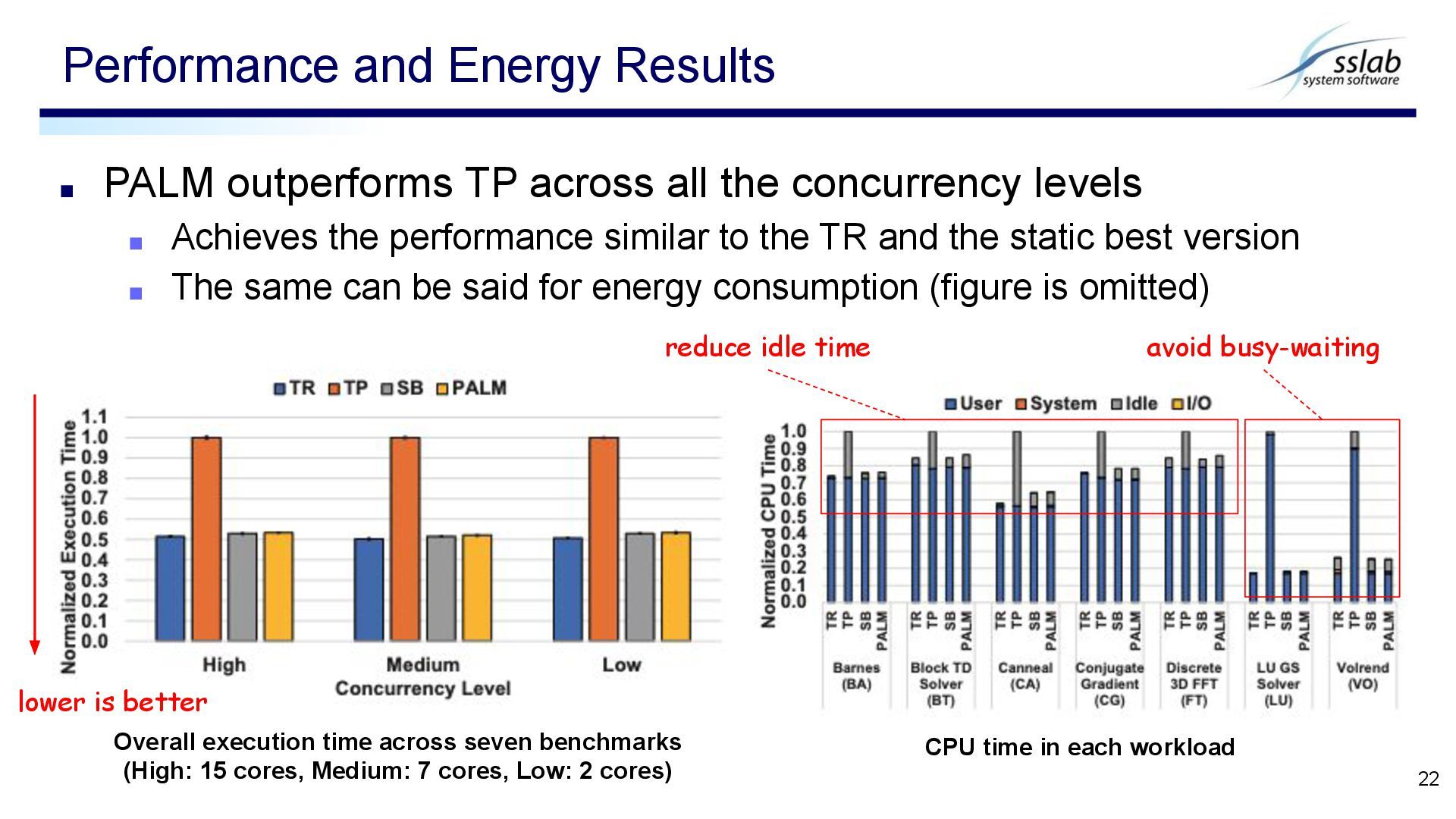
Achieves the performance similar to the TR and the static best version ▪ The same can be said for energy consumption (figure is omitted) Performance and Energy Results 22 reduce idle time avoid busy-waiting Overall execution time across seven benchmarks (High: 15 cores, Medium: 7 cores, Low: 2 cores) CPU time in each workload lower is better
Adjust the core affinity of LC/batch app based on the load ▪ PALM outperforms TP when memcached and VO are colocated Case study: Dynamic Server Consolidation 23 Runtime behavior (latency critical (LC): memcached, batch: VO) higher is better load applied to the LC benchmark core counts of batch app decreases performance of VO dynamically control the core counts of LC/batch app statically allocate the core in a way that LC app satisfies the SLO
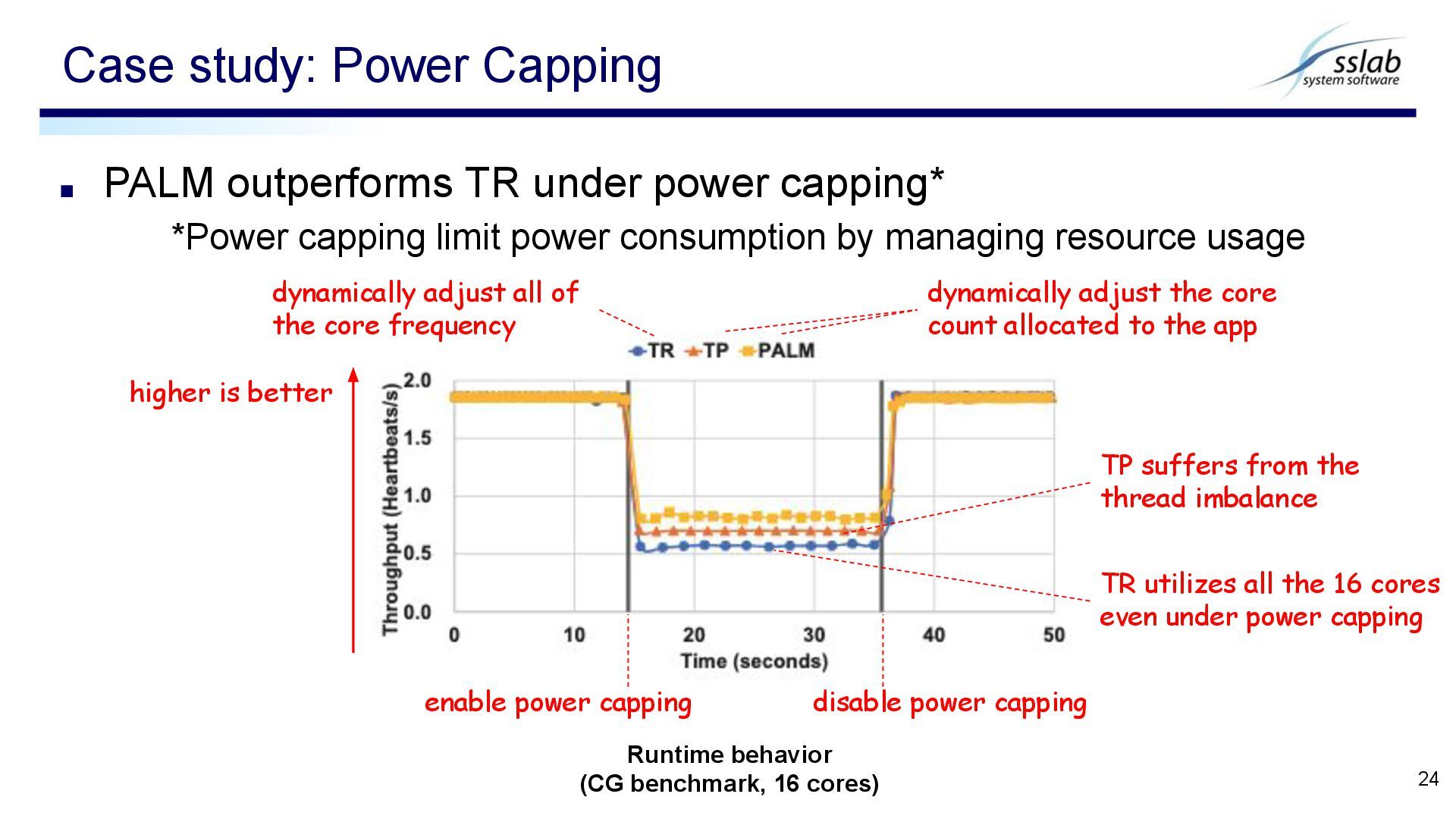
power consumption by managing resource usage Case study: Power Capping 24 Runtime behavior (CG benchmark, 16 cores) enable power capping disable power capping TR utilizes all the 16 cores even under power capping higher is better dynamically adjust the core count allocated to the app dynamically adjust all of the core frequency TP suffers from the thread imbalance
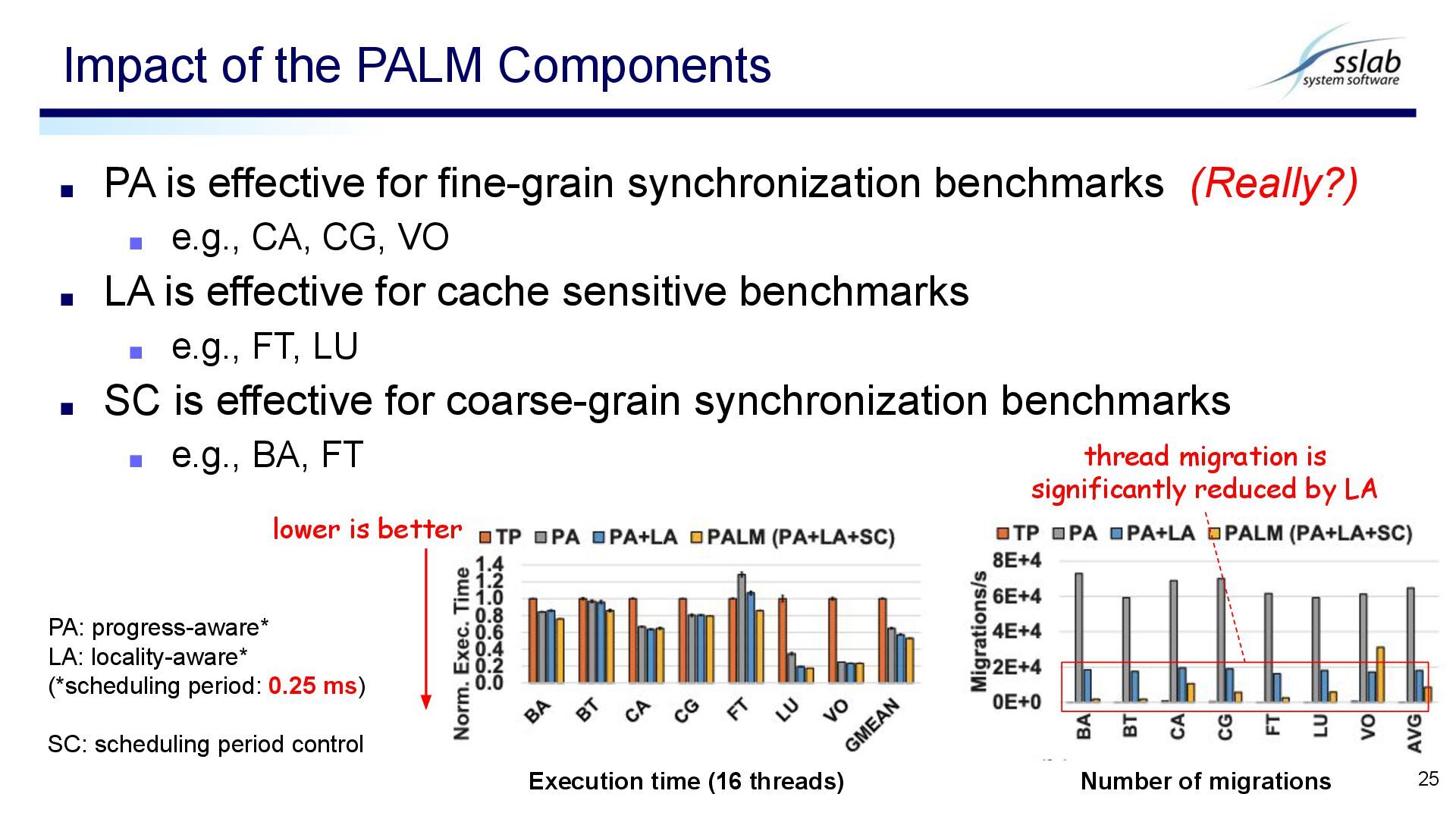
e.g., CA, CG, VO ▪ LA is effective for cache sensitive benchmarks ▪ e.g., FT, LU ▪ SC is effective for coarse-grain synchronization benchmarks ▪ e.g., BA, FT Impact of the PALM Components 25 Execution time (16 threads) Number of migrations PA: progress-aware* LA: locality-aware* (*scheduling period: 0.25 ms) SC: scheduling period control thread migration is significantly reduced by LA lower is better
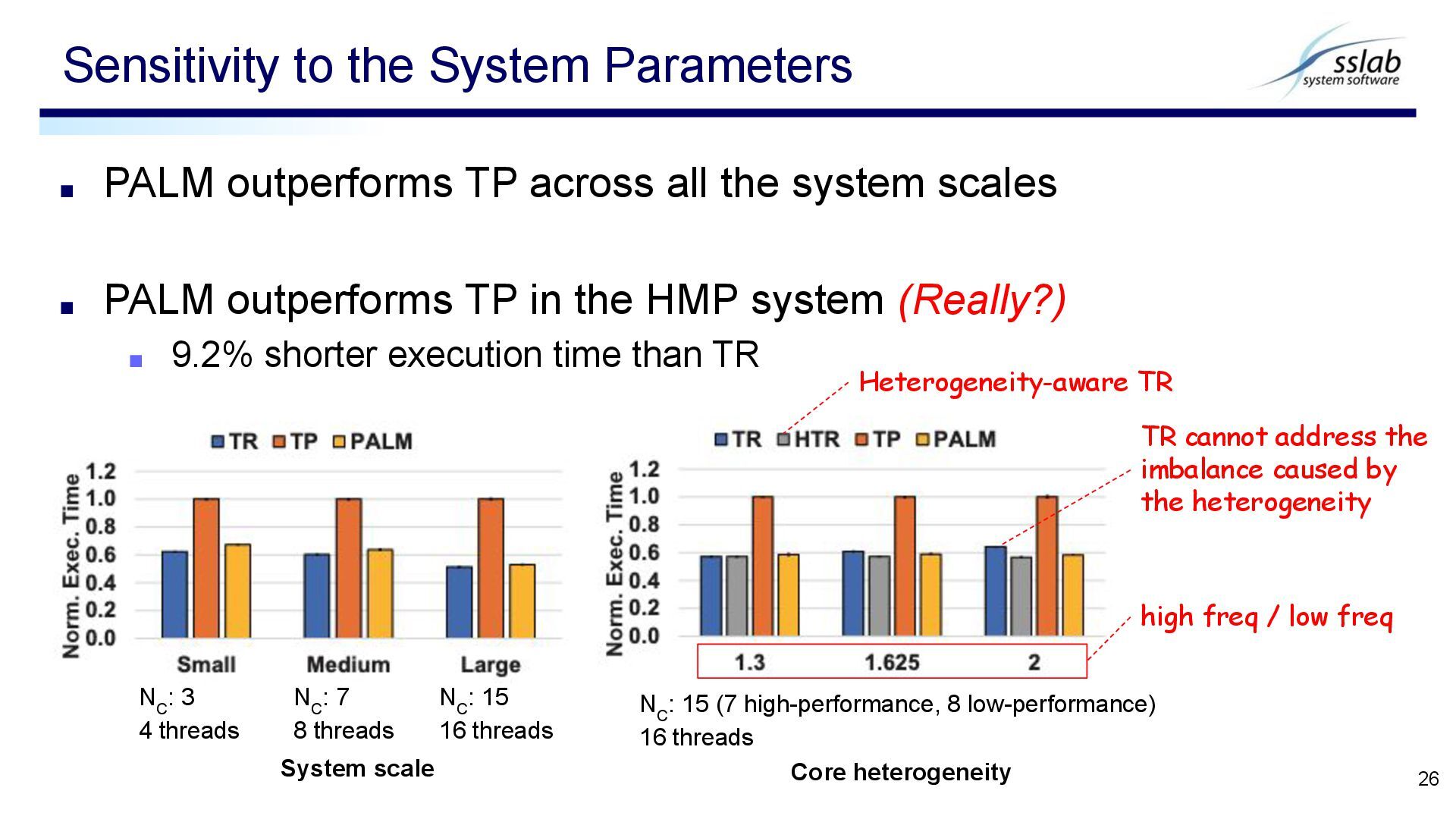
PALM outperforms TP in the HMP system (Really?) ▪ 9.2% shorter execution time than TR Sensitivity to the System Parameters 26 System scale Core heterogeneity N C : 3 4 threads N C : 7 8 threads N C : 15 16 threads N C : 15 (7 high-performance, 8 low-performance) 16 threads Heterogeneity-aware TR TR cannot address the imbalance caused by the heterogeneity high freq / low freq
TP to optimize performance under power caps ▪ Require extensive profiling, limiting adaptability to different systems ▪ The Linux scheduler: a decade of wasted cores [Lozi+, Eurosys ’16] ▪ Demonstrate the Work Conserving bugs in the Linux kernel ▪ Lacks the investigation of the impact of TP Related Works 27 Weakpoint of PALM compared to my research - ✖ Need to modify pthread library, scheduling period, and CPU affinity - ✖ Not investigate the actual problem of HMP environment
▪ with in-depth analysis using various synchronization-intensive benchmarks ▪ PALM: progress- and locality-aware adaptive task migration ▪ Achieves the greater performance than TP at high concurrency level ◆ 47% shorter execution time ◆ 39.3% lower energy consumption ▪ Improves ◆ the efficiency of dynamic server consolidation ◆ the performance under power capping Conclusion 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![▪ Implement dynamic resource manager like Heracles[David+, ISCA ’15] ▪](https://files.speakerdeck.com/presentations/21fd902efa714b3fb0189f5c229b7bf7/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![▪ Pack & Cap [Cochran+, MICRO-44] ▪ Combine DVFS and](https://files.speakerdeck.com/presentations/21fd902efa714b3fb0189f5c229b7bf7/slide_26.jpg){kind=link}
{kind=link}