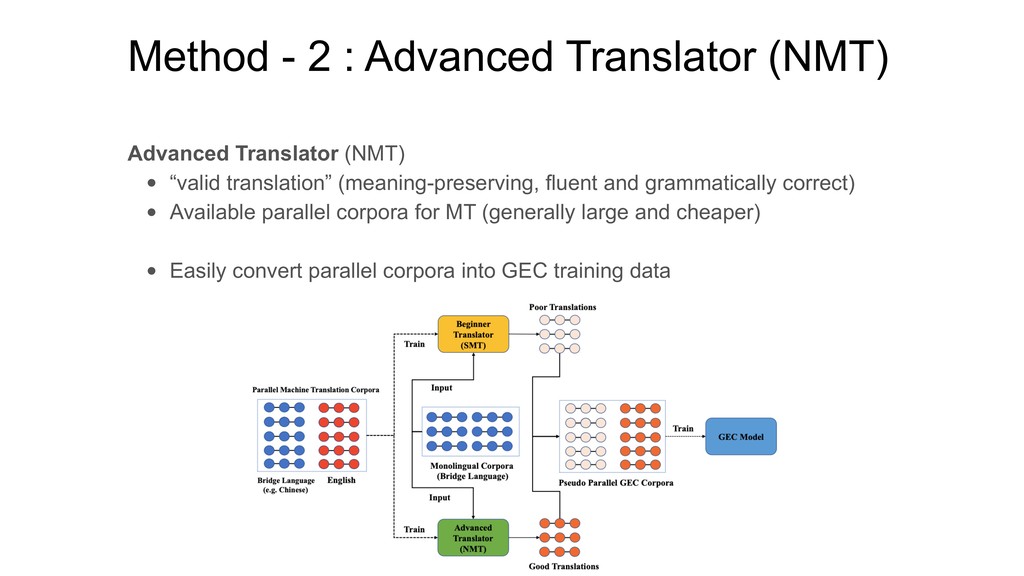
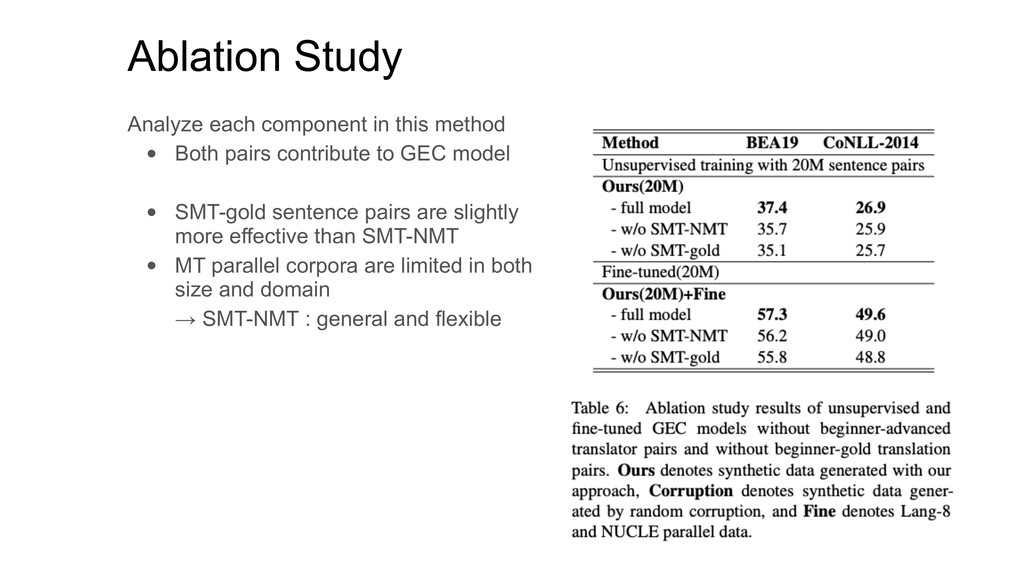
Corpus [Ziemski et al., 2016] • 15M parallel sentence pairs with around 400M tokens Monolingual Chinese corpora (for synthesize GEC data) • news2016zh [Xu, 2019] • news corpus containing 2.5M Chinese news articles In experiments, • 10M pseudo-parallel data (SMT-NMT) • 10M sentence pairs (SMT-gold) • To compare : NewsCrawl dataset + random corruption (40M sents) [Zhao et al., 2019] • Filter the generated corpora based on the fluency [Ge et al., 2018] • Discard : fluency of target sentence is lower than that of the source sentence
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}