Everyone knows poor performance when they see it, and performance concerns affect every application -- web applications more than most. But finding performance problems can be extraordinarily difficult, and requires an analytical approach coupled with good instrumentation. This talk explores approaches to instrumentation and what that instrumentation can tell you.
https://us.pycon.org/2015/schedule/presentation/349/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
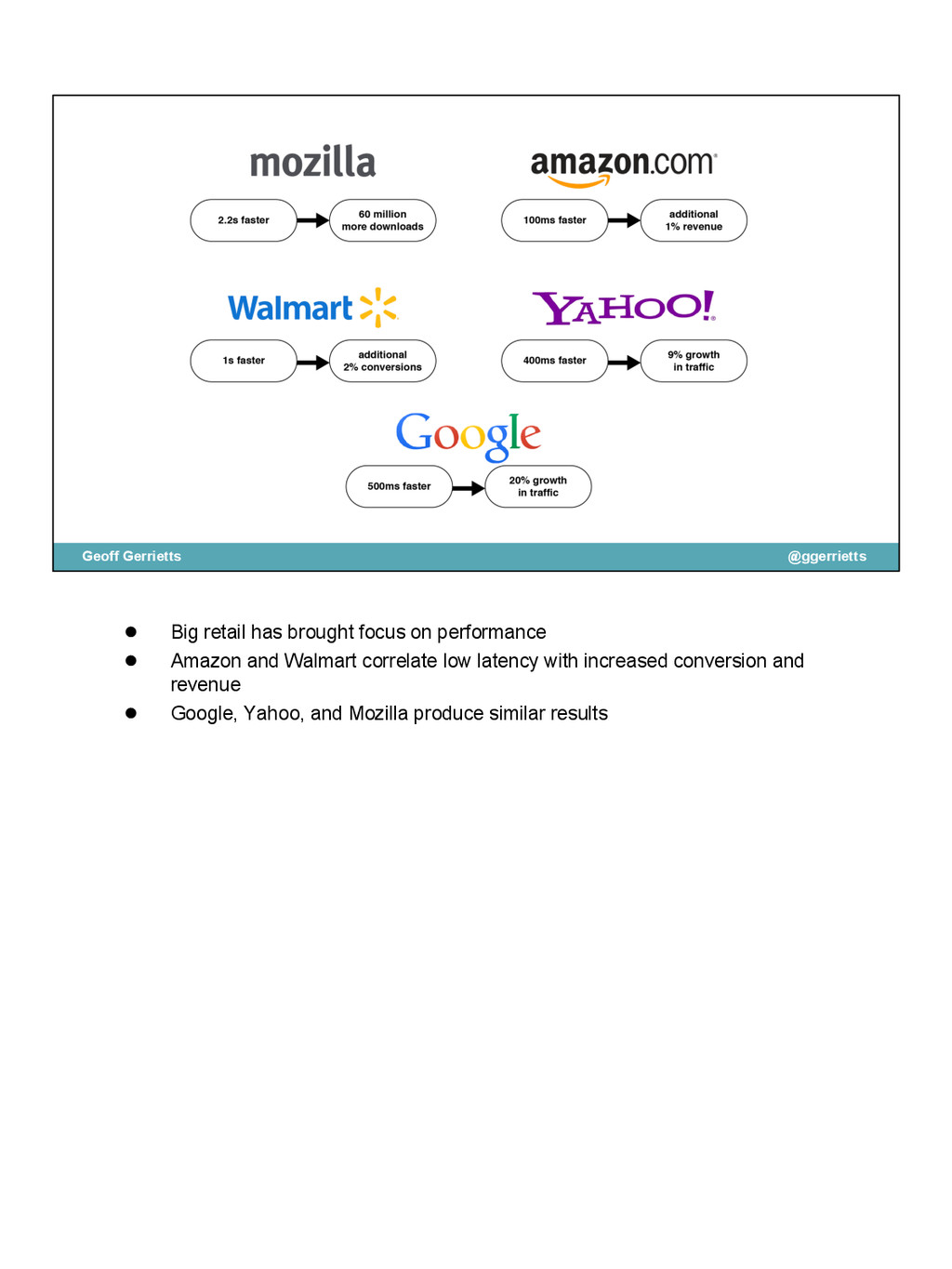{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
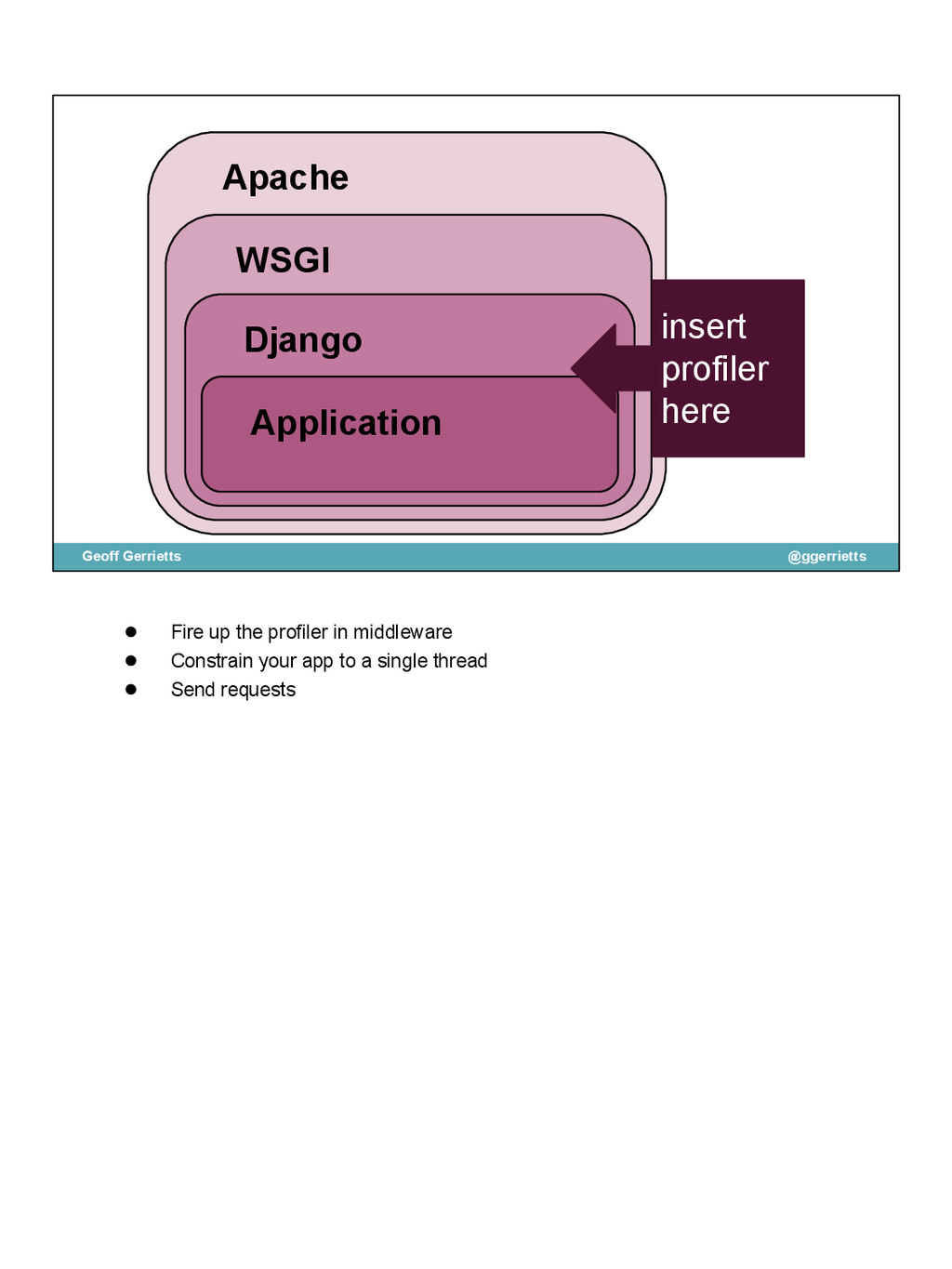{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
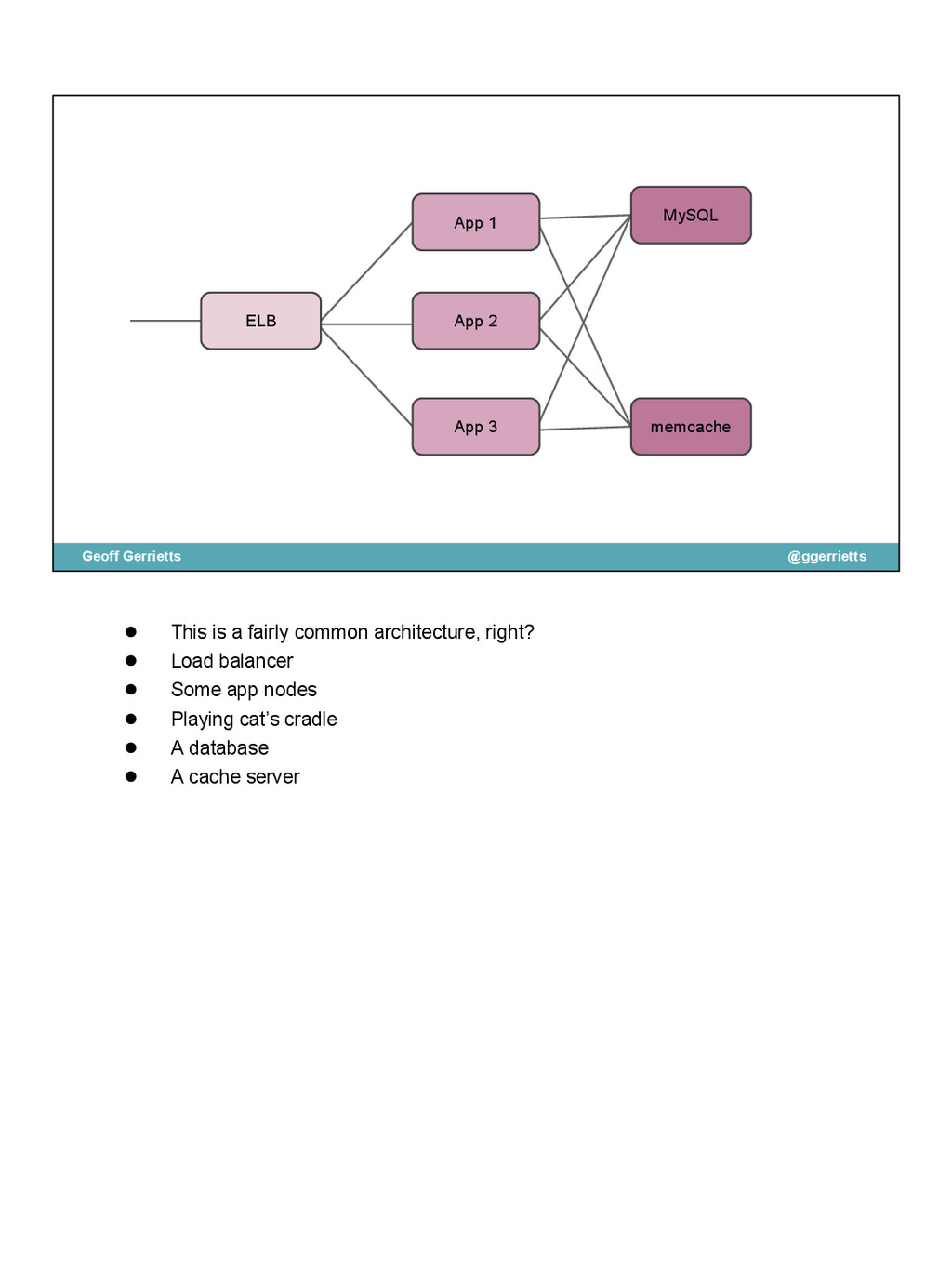{kind=link}
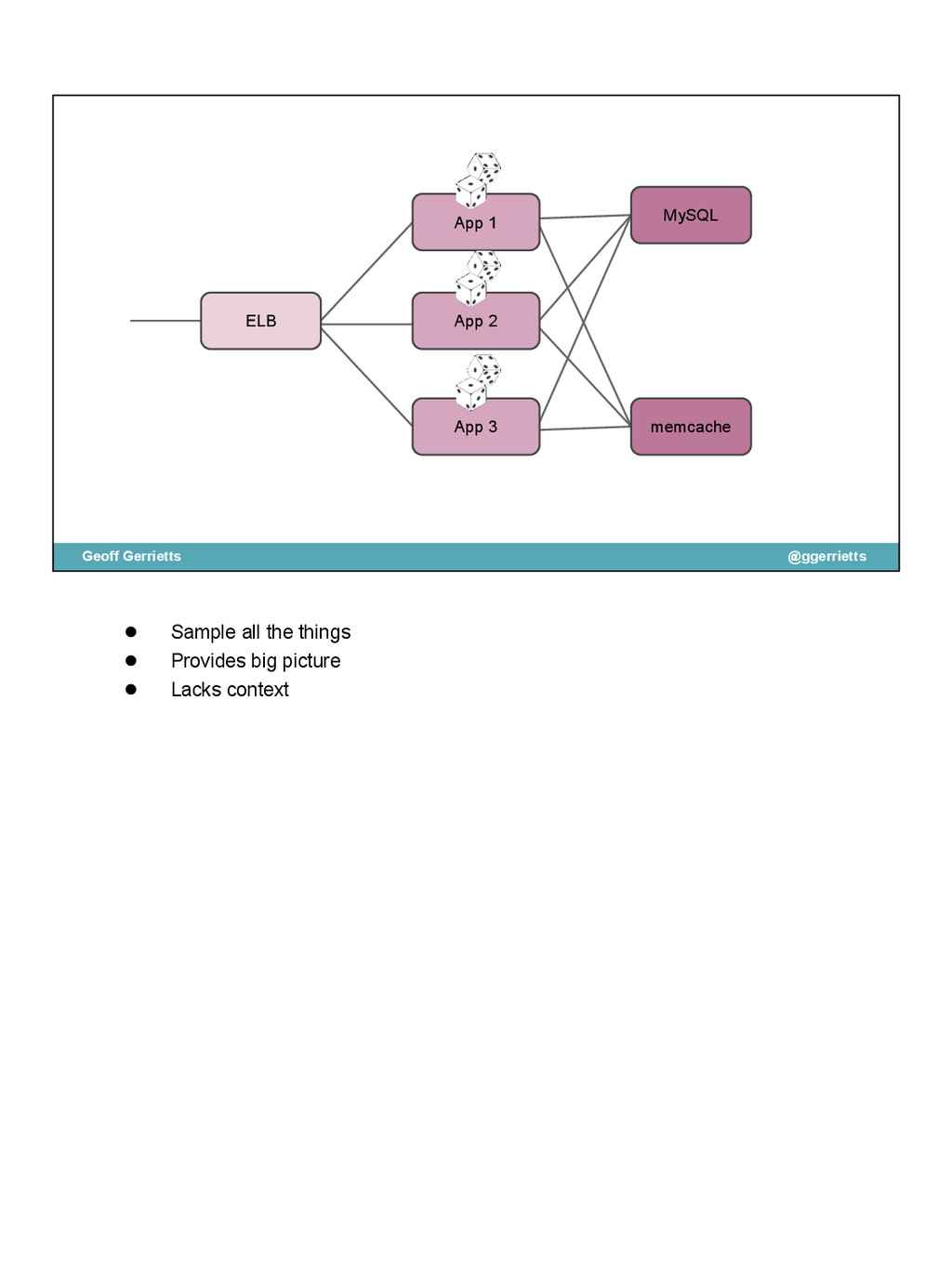{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
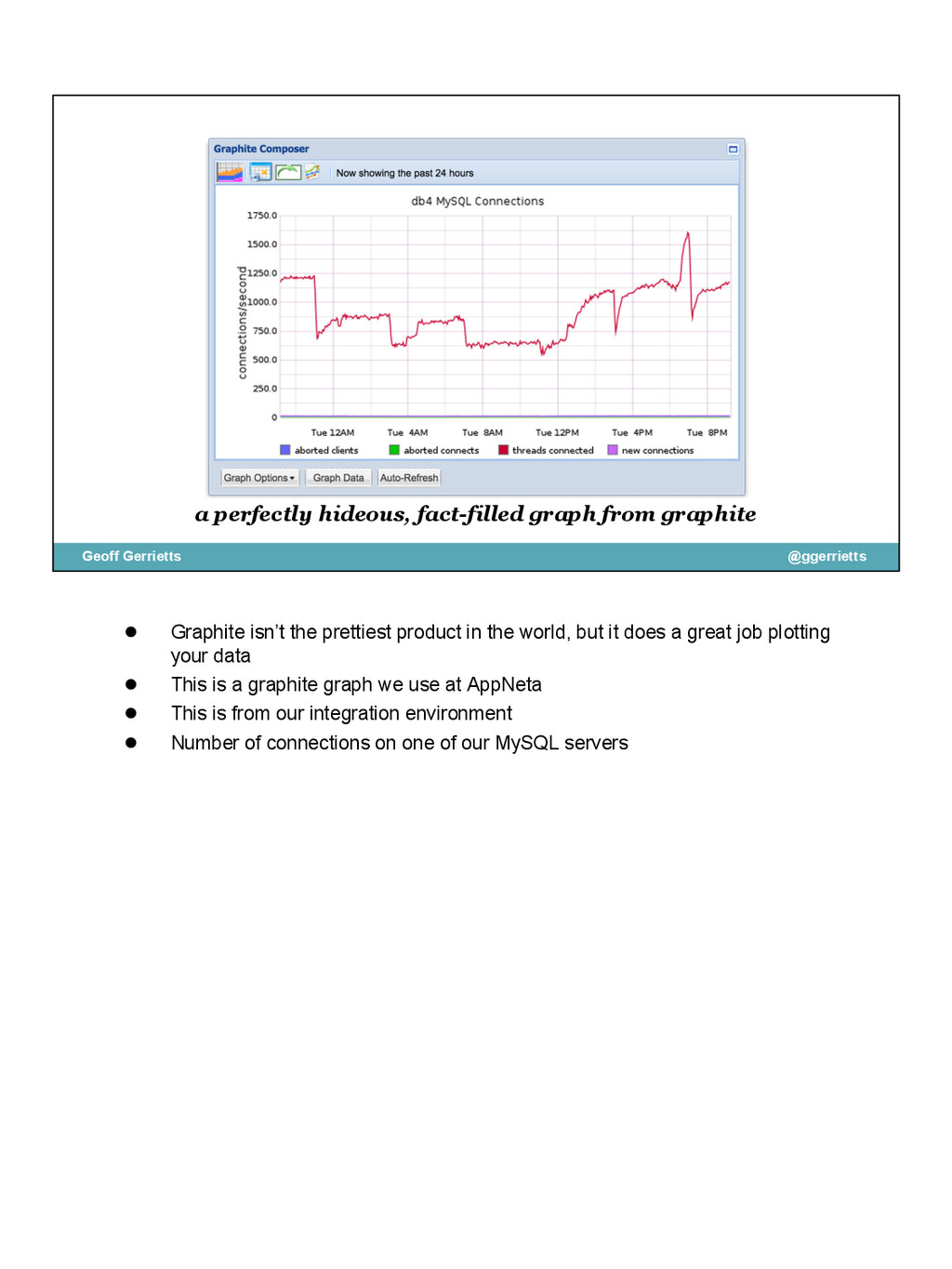{kind=link}
{kind=link}
{kind=link}
{kind=link}
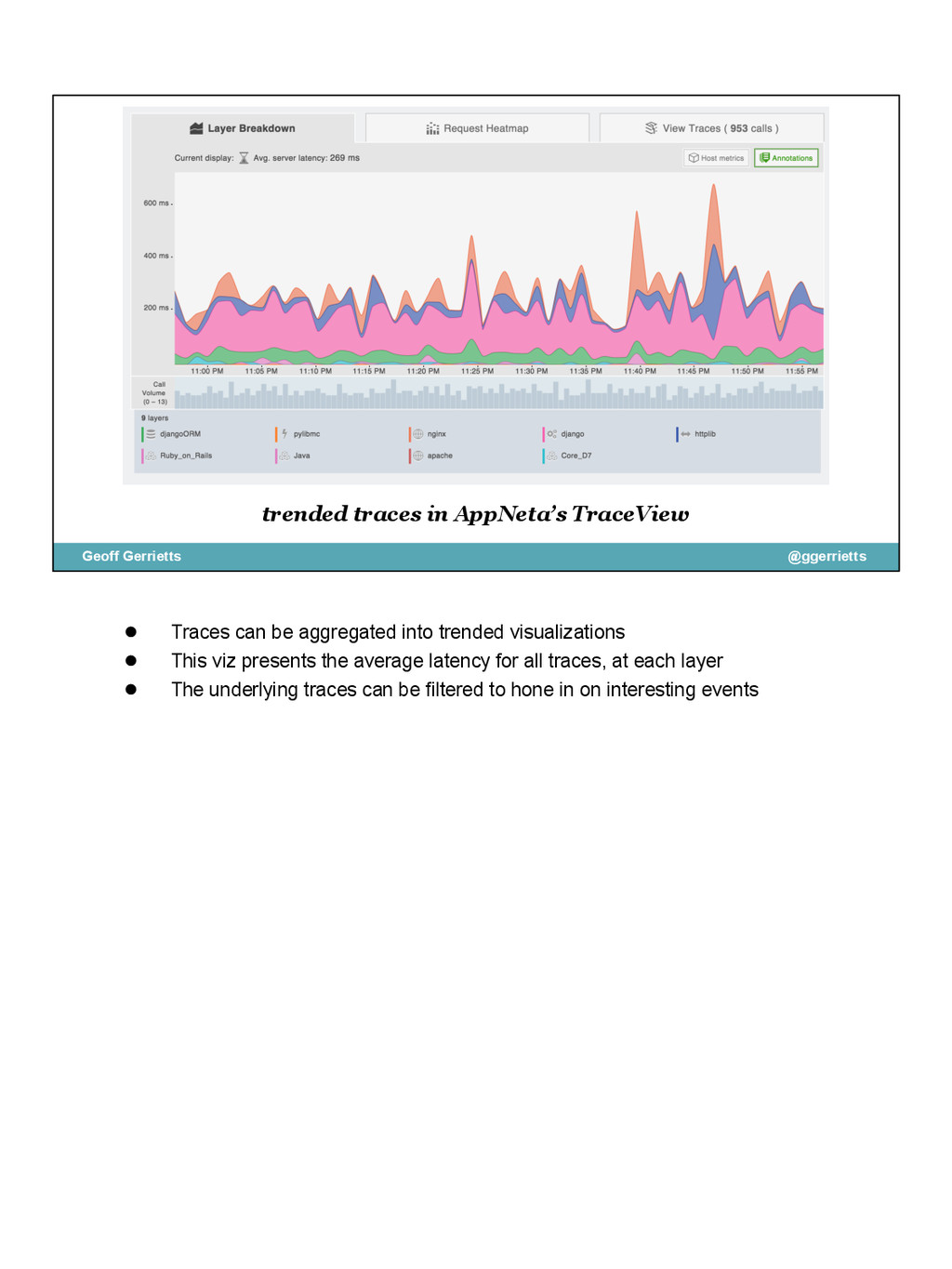{kind=link}
{kind=link}
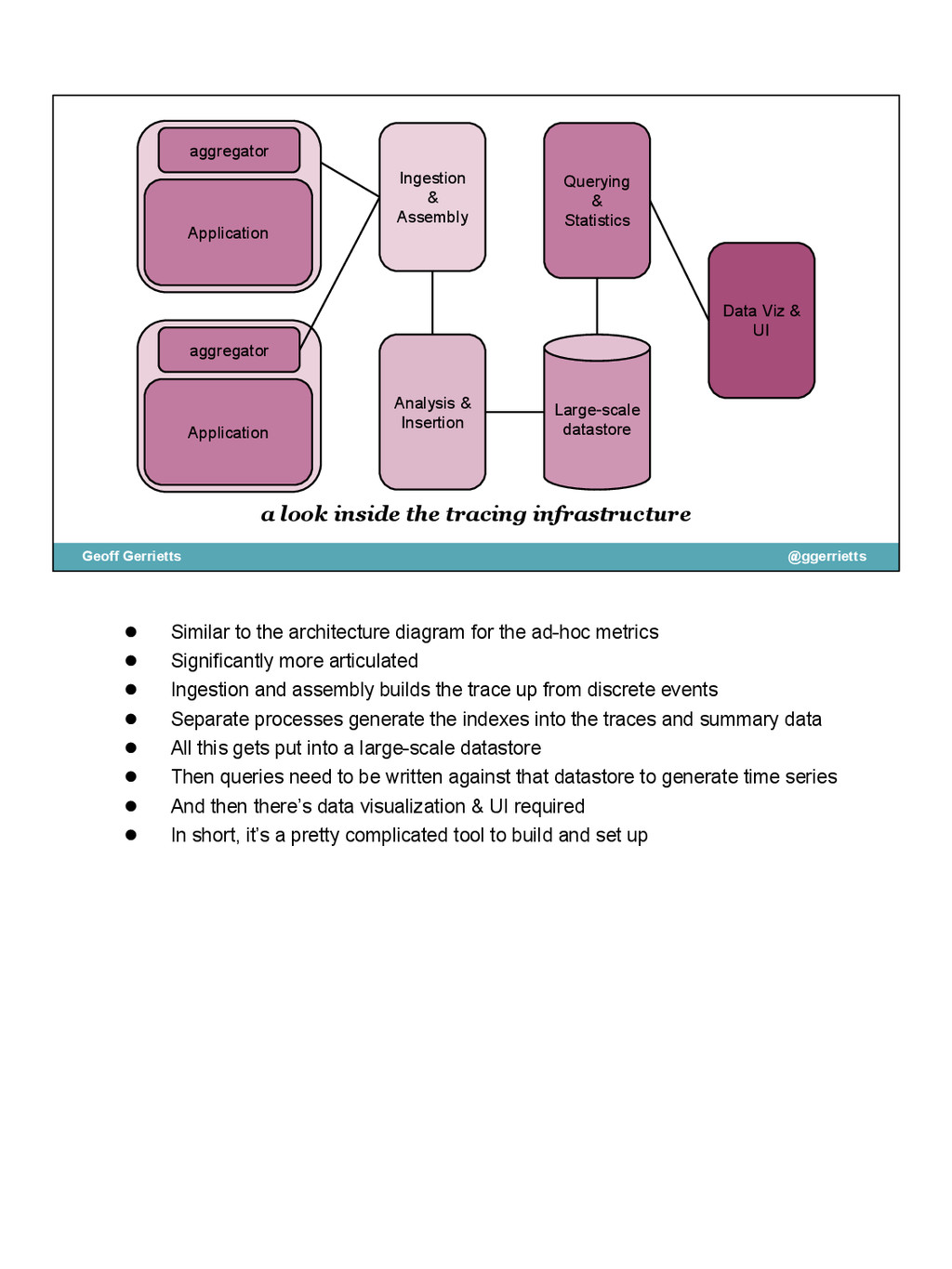{kind=link}
{kind=link}
{kind=link}
{kind=link}
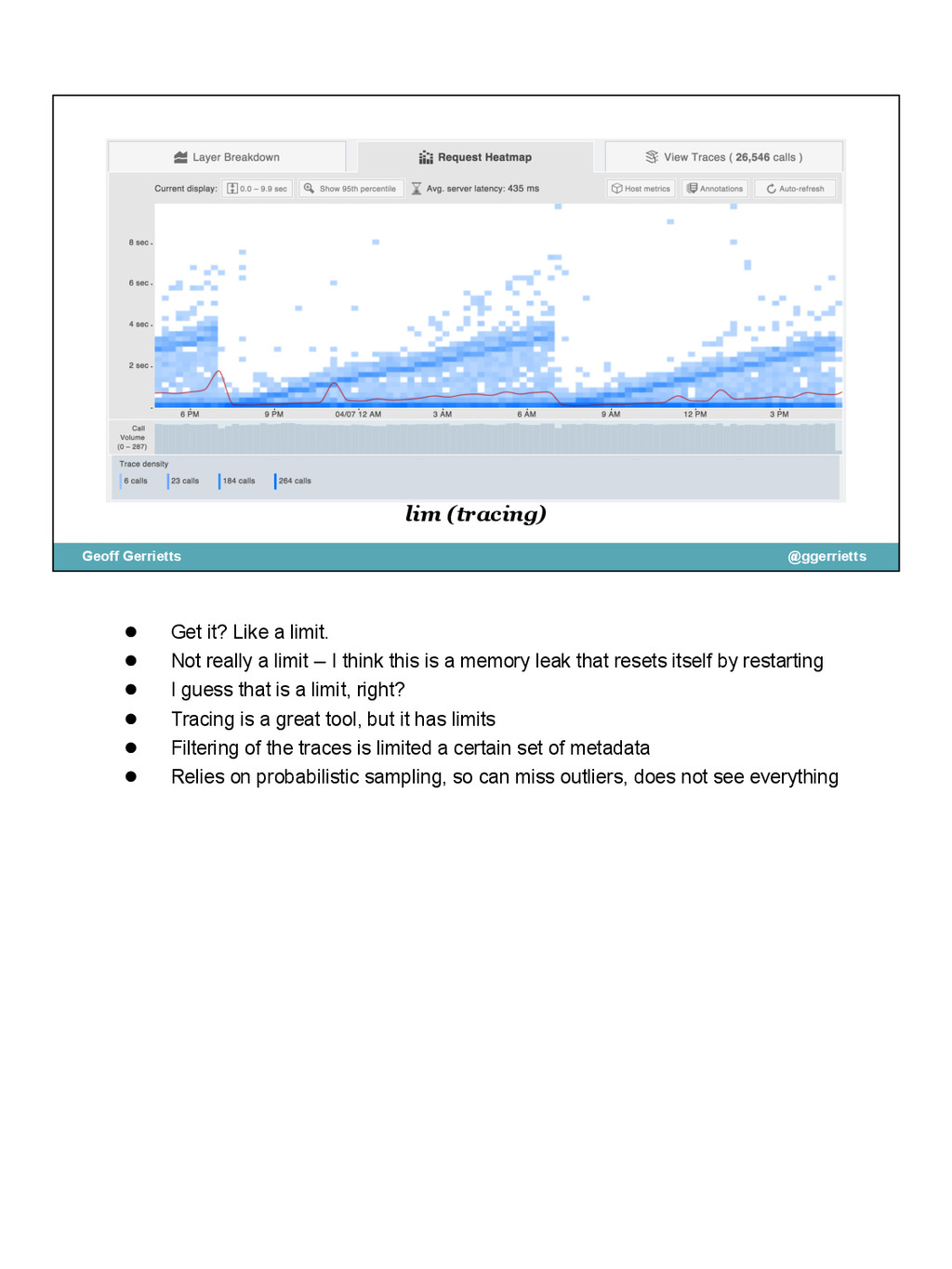{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Questions/comments: [email protected] @ggerrietts](https://files.speakerdeck.com/presentations/4da10d28e43e49b6956e4c7311a41125/slide_49.jpg){kind=link}