Однажды я провел день на колоссальном девятичасовом созвоне в попытке понять «а почему продакшн не работает?» и выводы, которые я вынес из этого дебага, я хочу принести вам в этом докладе.
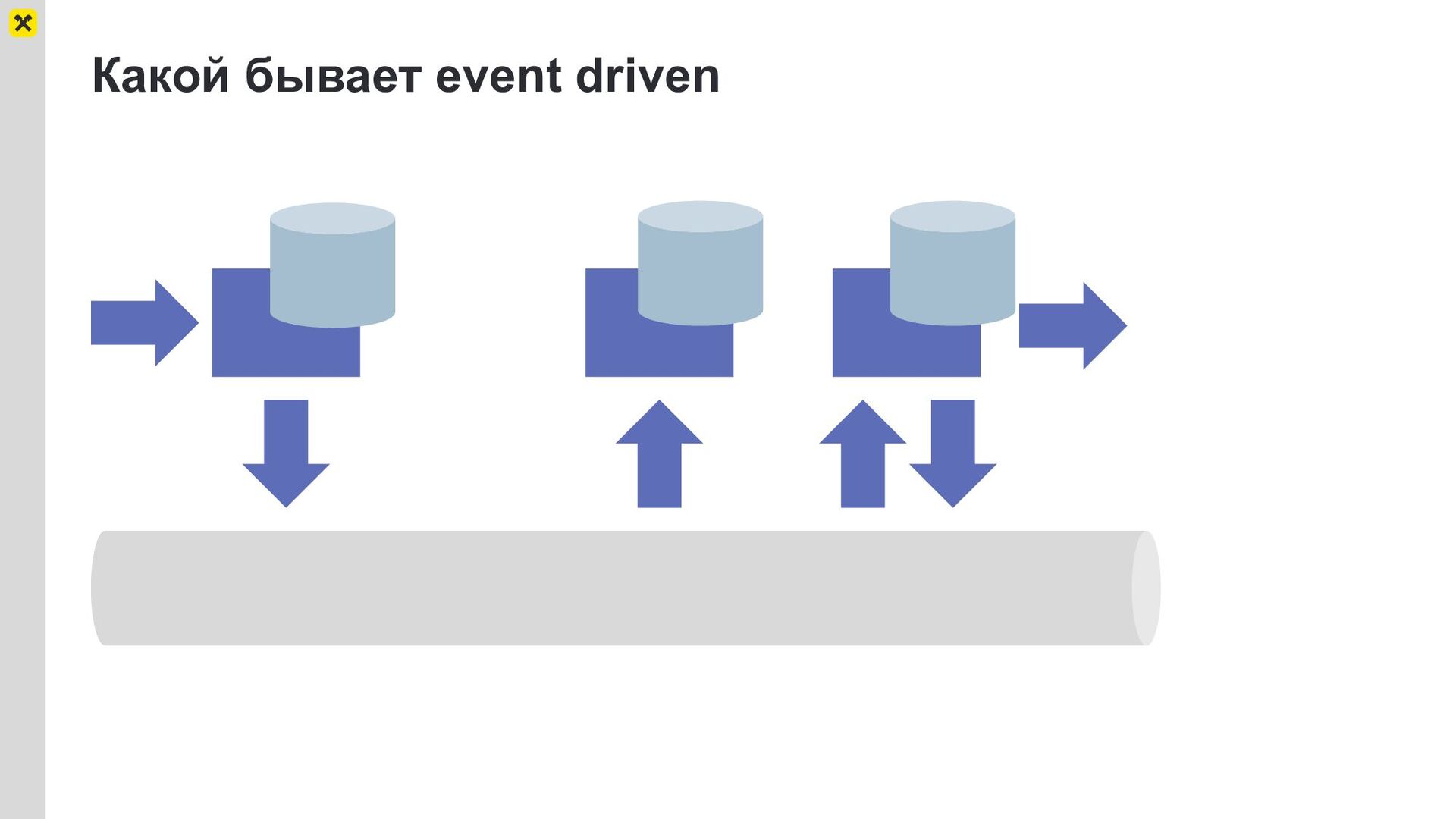
Что же у нас за система? Мы делаем чат, это современная event-driven архитектура, все наши бэкенды — это rest-like части на fastapi и основная часть системы базируется на kafka продюсерах/консьюмерах. Весь наш код асинхронный, а баз две штуки — postgres и keydb.
Моя история будет о том:
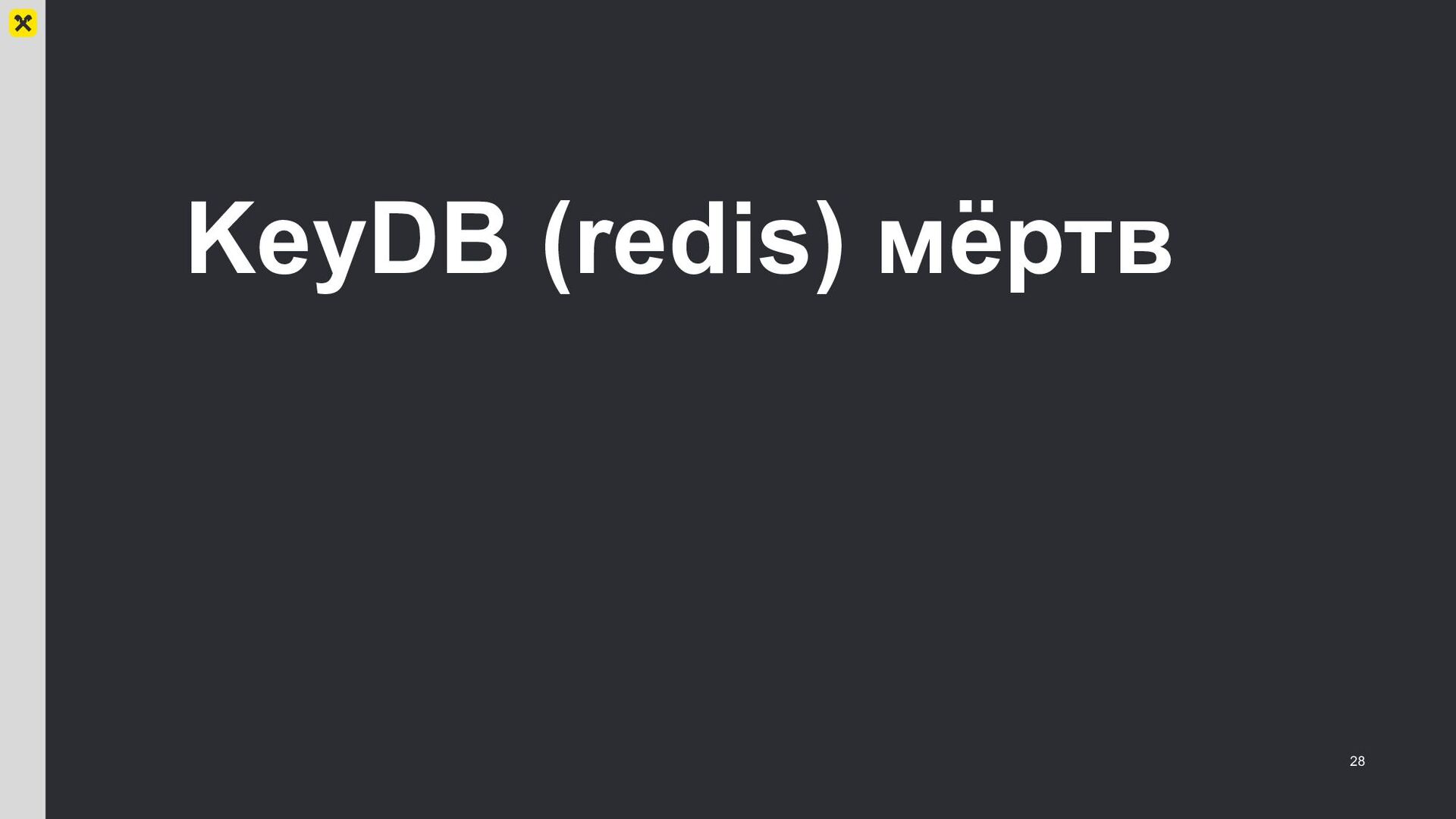
— как уронить keydb;
— как kafka может уничтожить ваше асинхронное приложение;
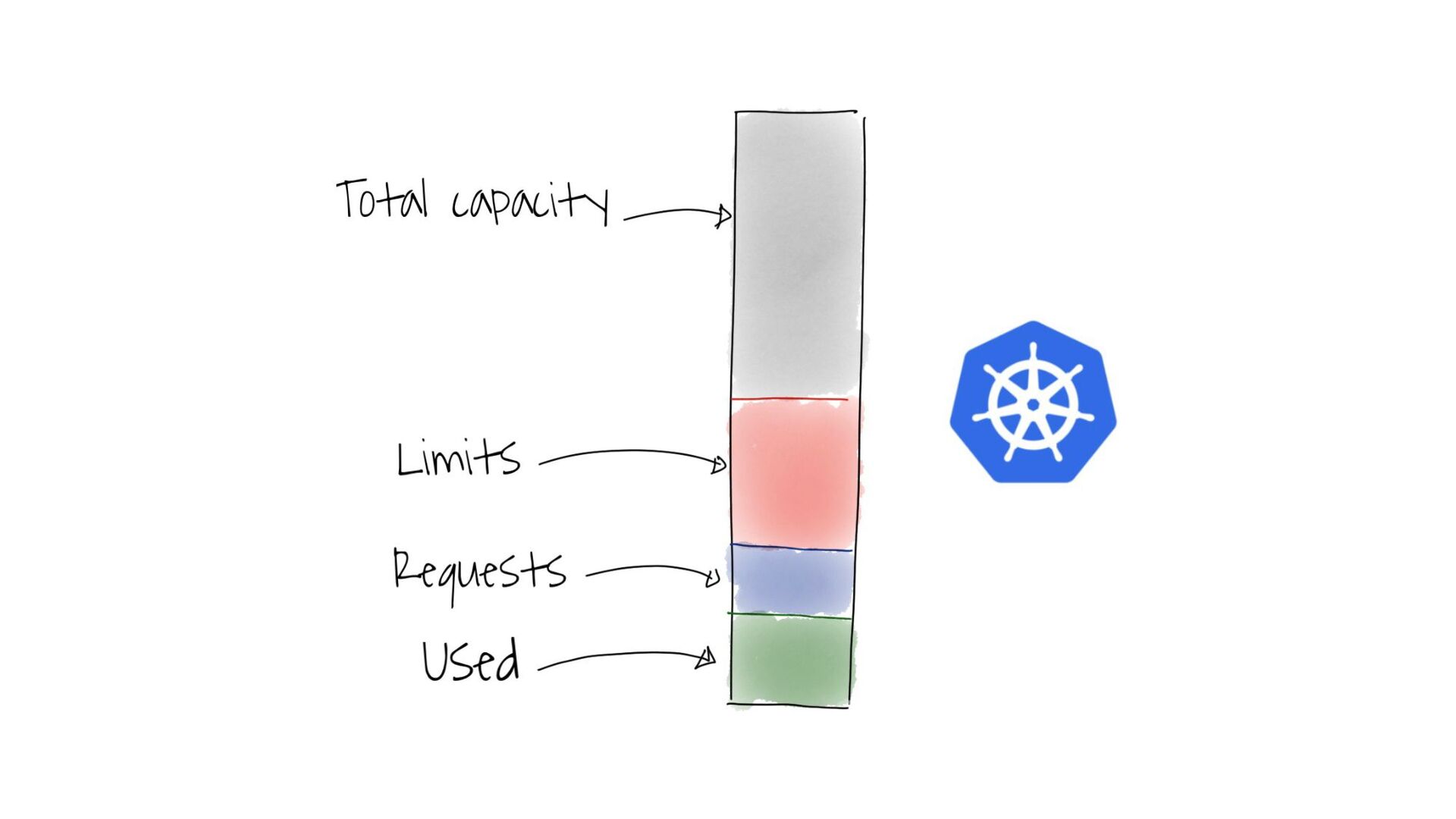
— как неправильно планировать ресурсы в кубер кластере;
— как можно покалечиться всей системой, если у тебя кривая библиотека для работы с БД;
— какие мониторинги делать обязательно;
— что такое плохой healtcheck;
— почему документация может быть очень коварной.
Доклад стыдный, но, надеюсь, полезный!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}