Zach Furman1, George Wang1, Daniel Murfet2, Susan Wei3 (1:Timaeus, 2:University of Melbourne, 3:Monash University) https://arxiv.org/abs/2308.12108v2 2025/10/19 xiangze
Loss landscape, wide/flat minima ◦ Rademacher複雑性との違い PAC-Vayes(Deep Learning is Not So Mysterious or Different) と並行した議論 (実験https://github.com/xiangze/soft_inductive_bias) 正規モデルの場合は“事後分布”q(w|w*)がガウシアンλPAC-bayesはlの二次微分、HessianのTraceに比例する(BICと一致) • Model Complexity vs Model independent Complexity “Thus, while in general LLC is not a model-independent complexity measure, it seems distinctly possible that for neural networks (perhaps even models in some broader “universality class"), the LLC could be model-independent in some way. This would theoretically establish the inductive biases of neural networks. We believe this to be an intriguing direction for future work.” ”My Criticism of Singular Learning Theory”の例 f1(x) has a learning coefficient of λ = 1/2, whereas f2(x) has a learning coefficient of λ = 1/ 16 . Therefore, despite f1(x) being more Kolmogorov-simple, it is more complex for f(x,w) to implement — the model is biased towards f2(x) instead of f1(x), f1(x) requires relatively more information to learn
Transformers We thank Google’s TPU Research Cloud program for supporting some of our experiments with Cloud TPUs Quantifying degeneracy in singular models via the learning coefficient Variational Bayesian Neural Networks via Resolution of Singularities Singular Learning Theory with Daniel Murfet(interview Blog) 内容 • LLCの推定、SLTの一般化 • NTKなど他の理論との関係 • AIアラインメントとの関係、未解決問題 • SLTはAIの性能を上げるか • 幾何学と情報 など
Bayesian estimation (式解説 ) 本論文のベースとなった行列モデルの RLCTの厳密解の計算 The loss surface of deep linear networks(DLN)viewed through the algebraic geometry lens 正則化項を入れると局所最適解が増え大域最適解に到達できなくなってしまうらしい。 そのうえでホモトピー的手法を用いて解の個数を数え上げている。個数はNNの層、幅に対して組み合わせ的に増え る • 相転移との関係(拡散モデルの場合) ◦ [2305.19693] Spontaneous Symmetry Breaking in Generative Diffusion Models ◦ [2508.19897] The Information Dynamics of Generative Diffusion
![[論文紹介]The Local Learning Coefficient: A Singularity-Aware Complexity Measure Edmund Lau2,](https://files.speakerdeck.com/presentations/2074be2e83b64aa9a42b6952916366b3/slide_0.jpg){kind=link}
{kind=link}
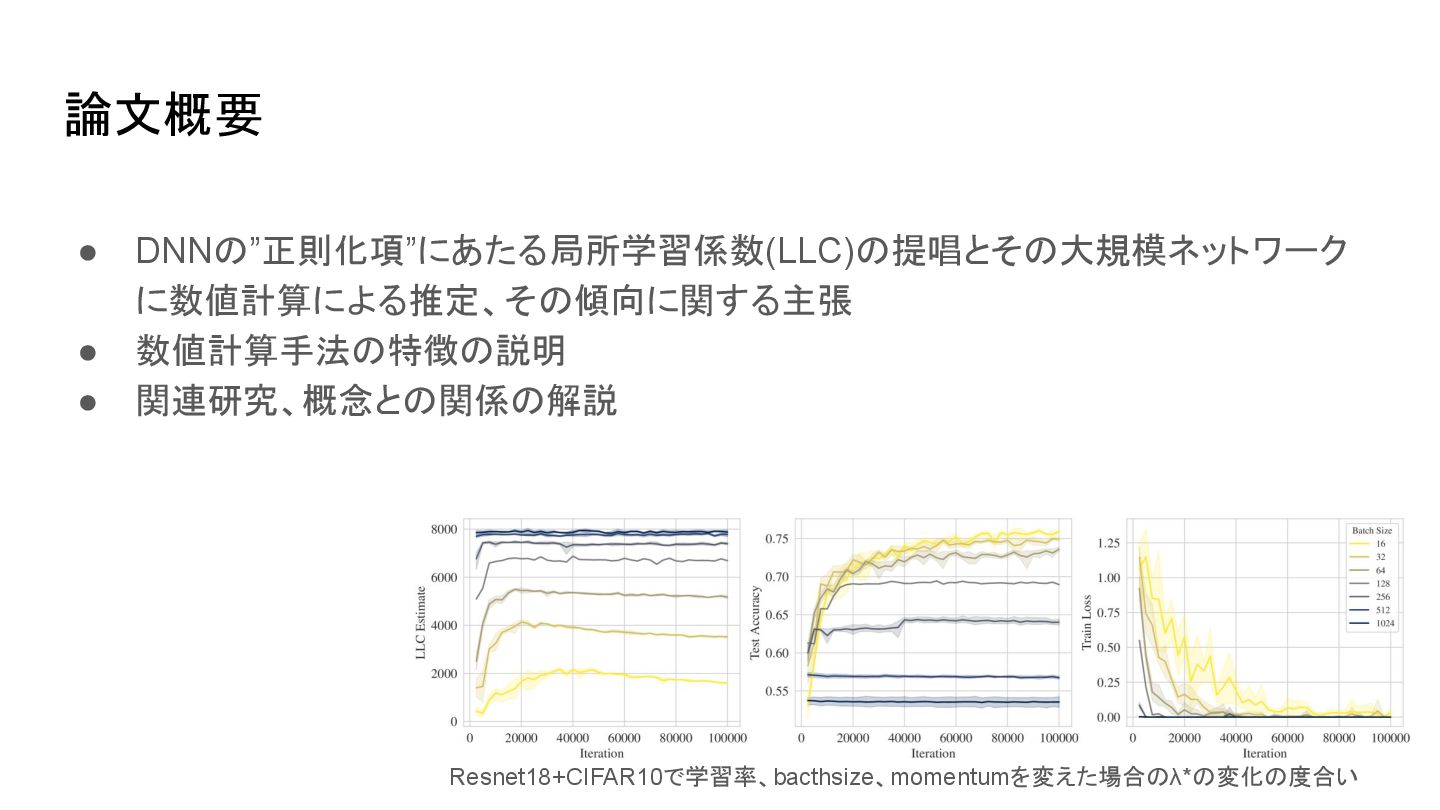{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
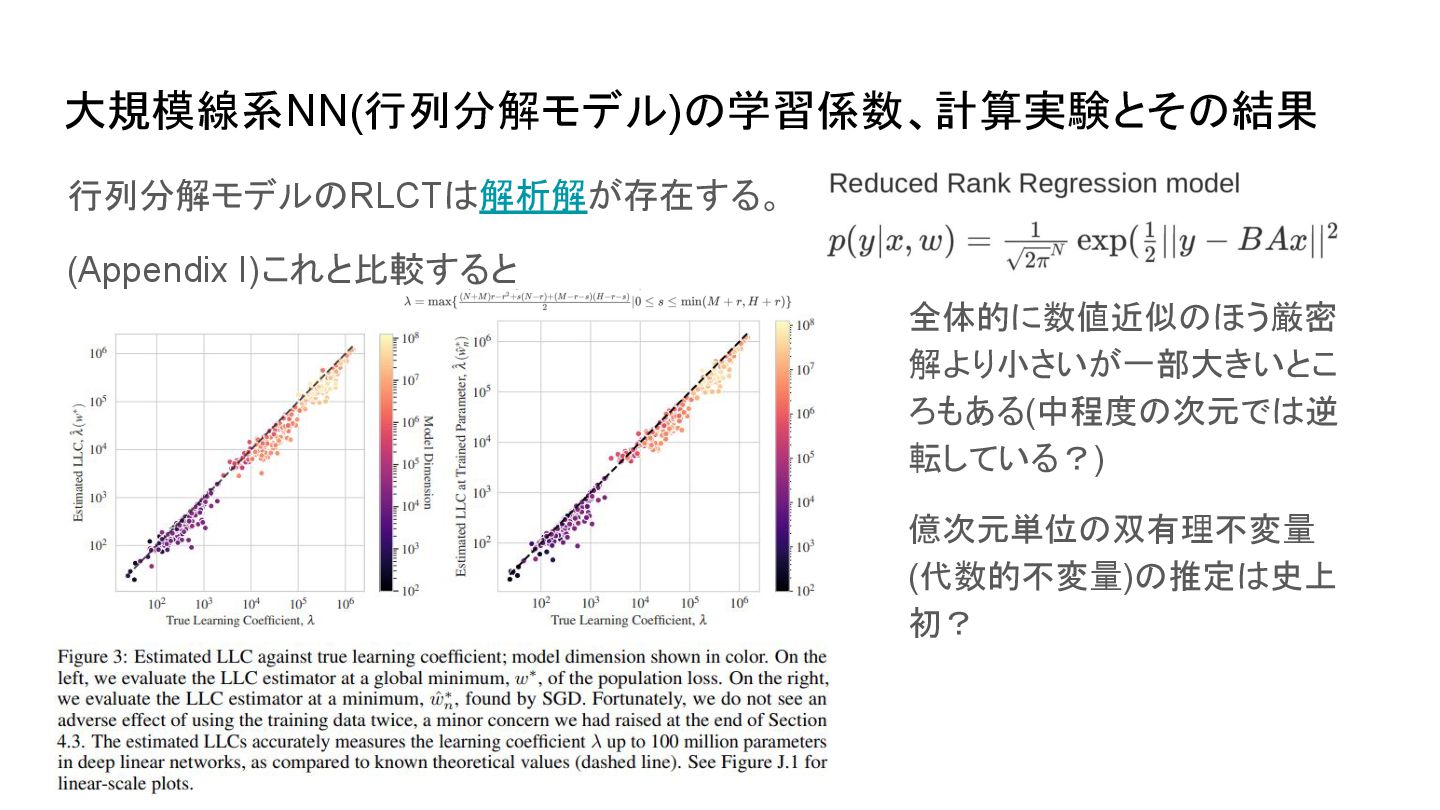{kind=link}
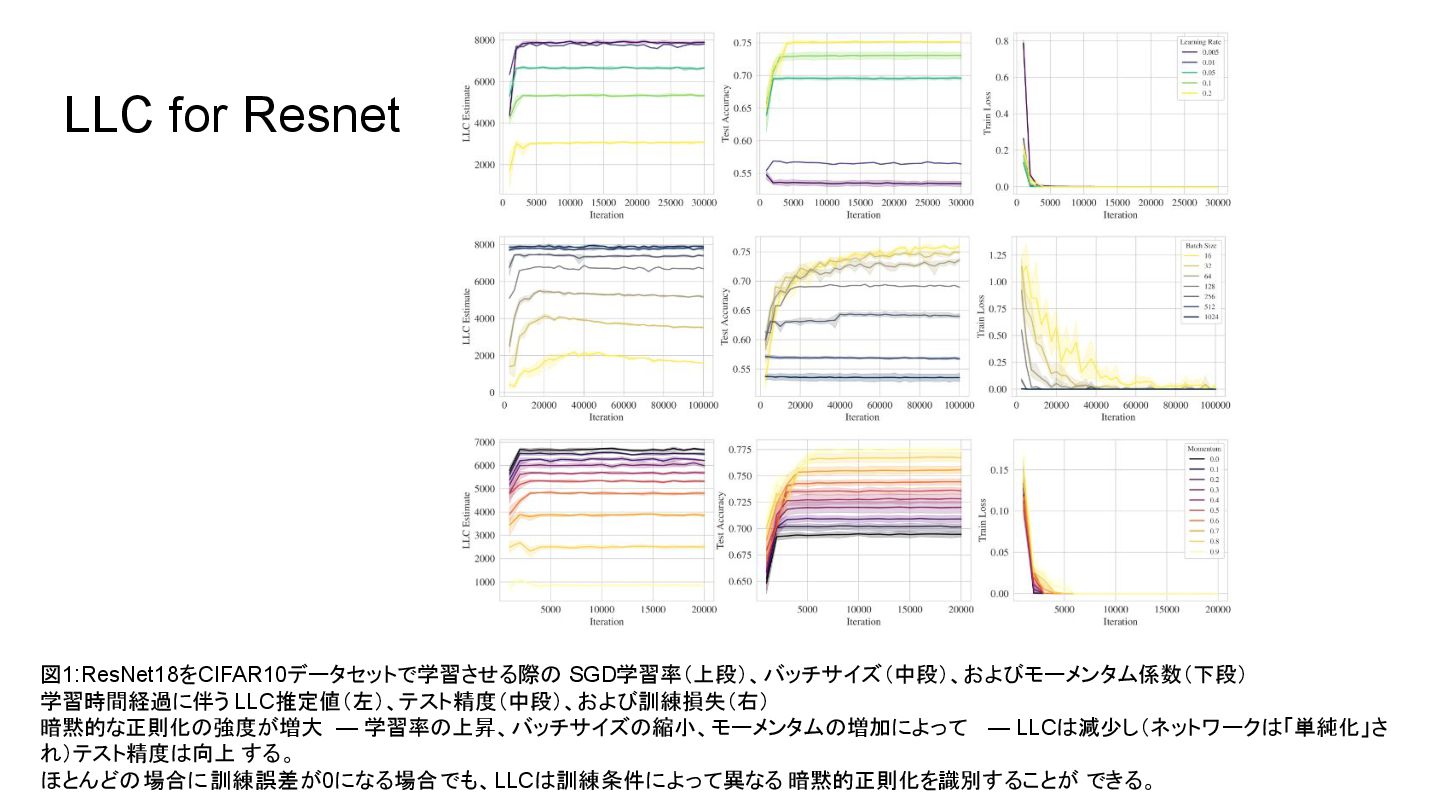{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}