In questo talk vedremo una architettura per creare un data lake, cioè il dove salviamo e processiamo i nostri dati, usando l'infrastruttura serverless su AWS.
In this short talk we'll se an architecture for a data lake - the place where you store and process your data - built with serverless services on AWS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
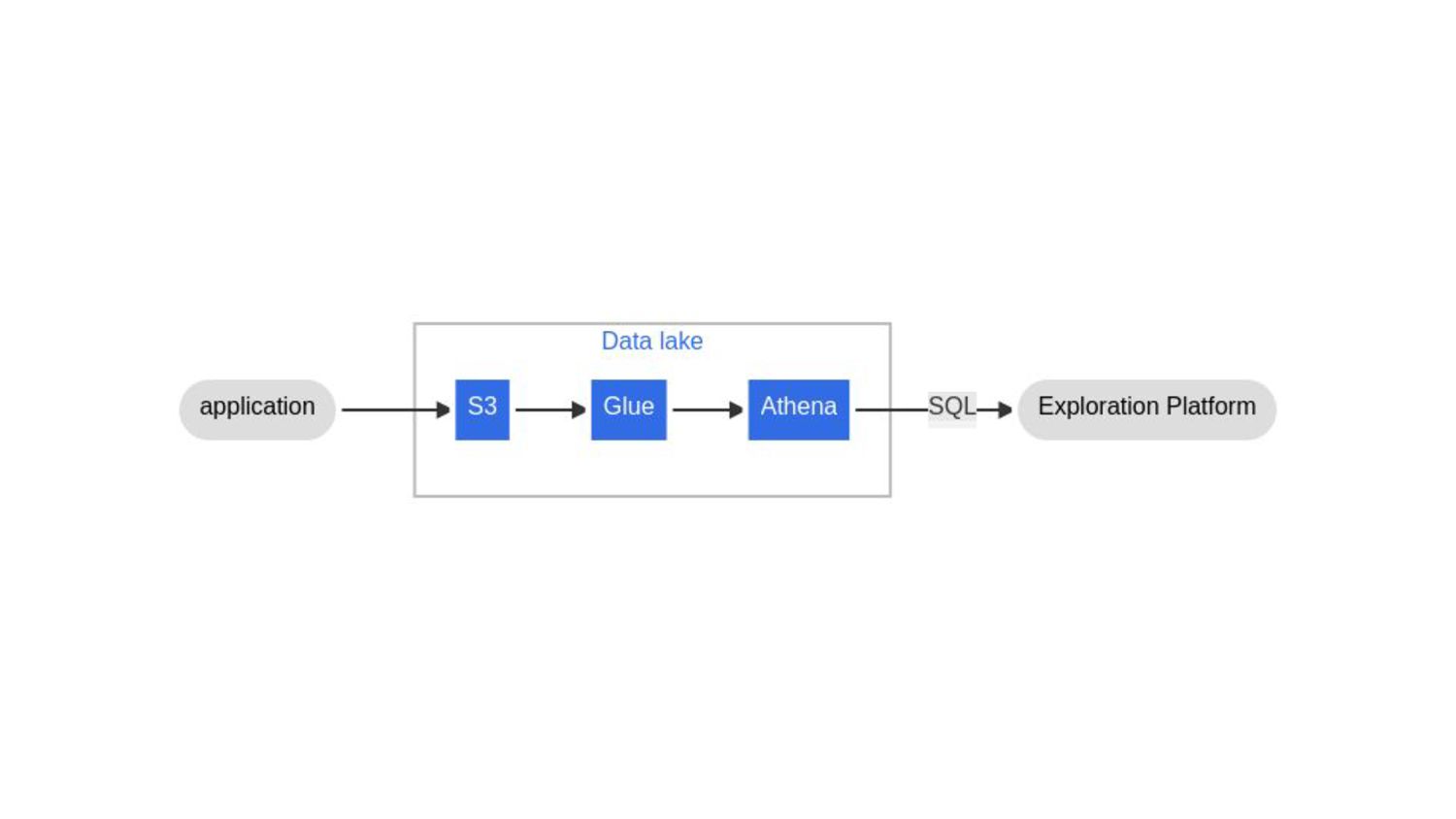{kind=link}
{kind=link}
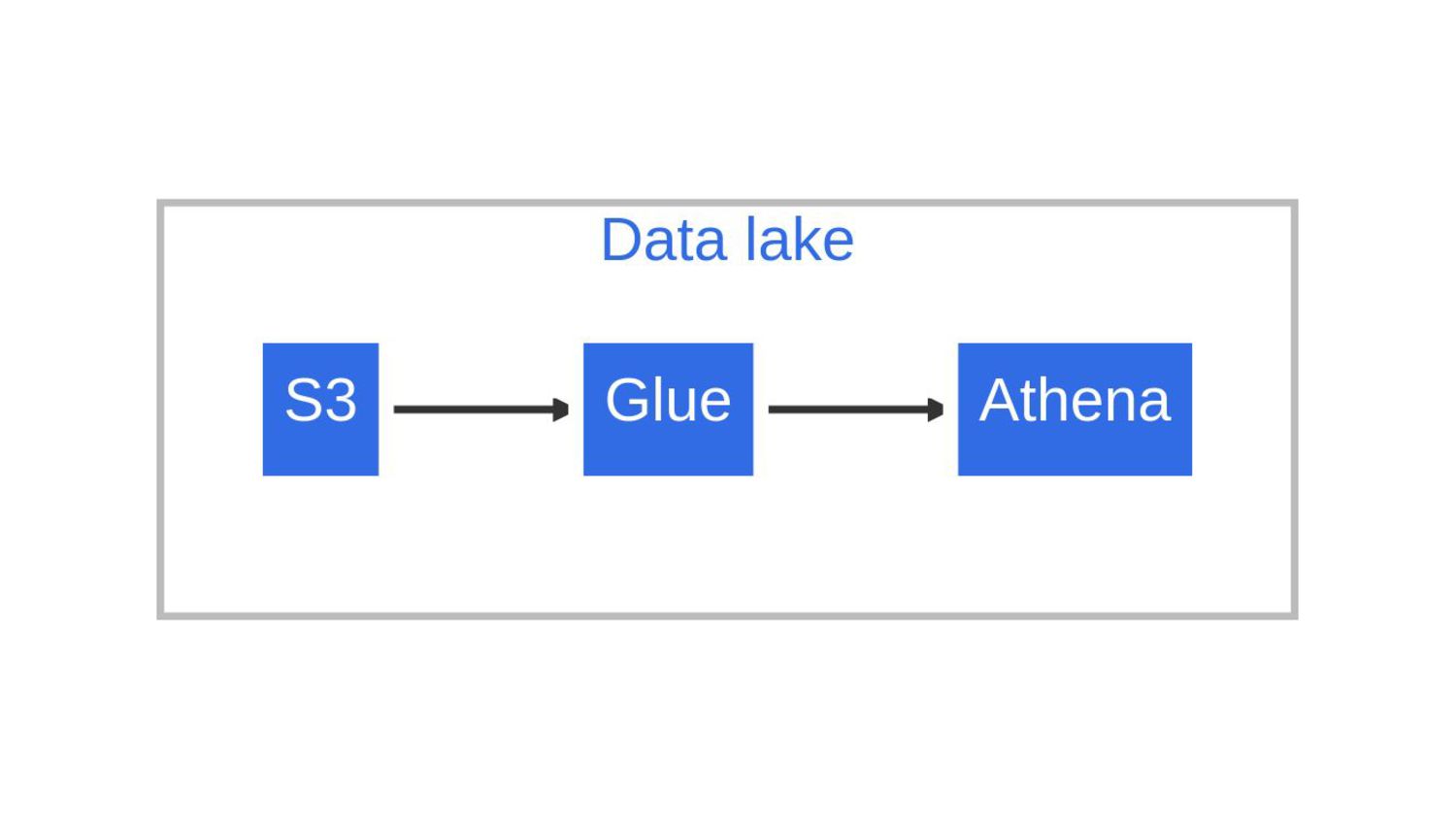{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Riccardo Magliocchetti @rmistaken / @[email protected]](https://files.speakerdeck.com/presentations/8c5aa8f64c3848328a502e126dbc5239/slide_18.jpg){kind=link}