Building and maintaining data pipelines when it’s not your full time job is a pain! So better keep things simple without the need to manage the system yourself. In this talk I’ll show a data pipeline architecture built leveraging some cloud offerings by AWS and Preset.
In this talk we’ll discuss:
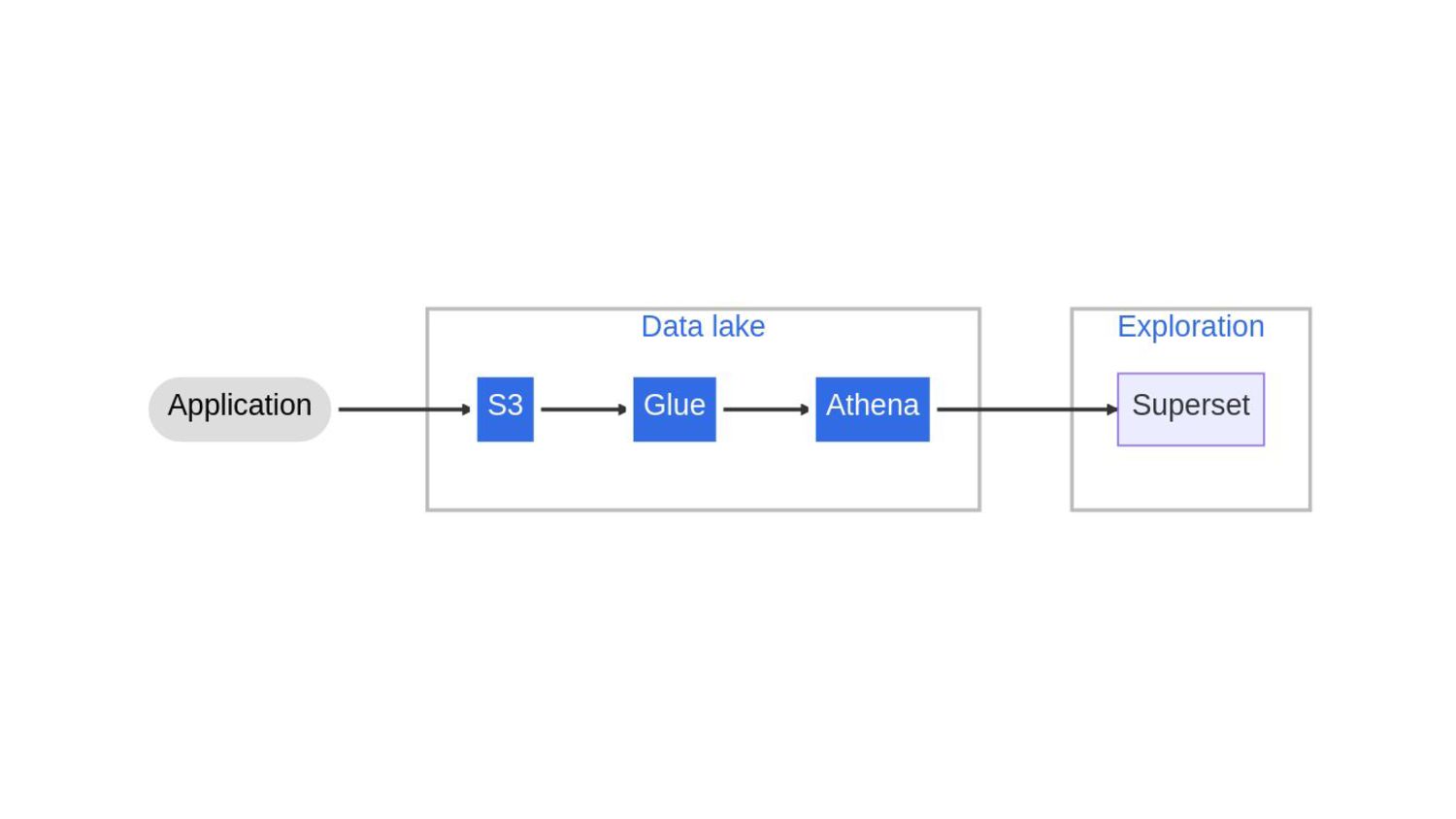
- an overview of the architecture
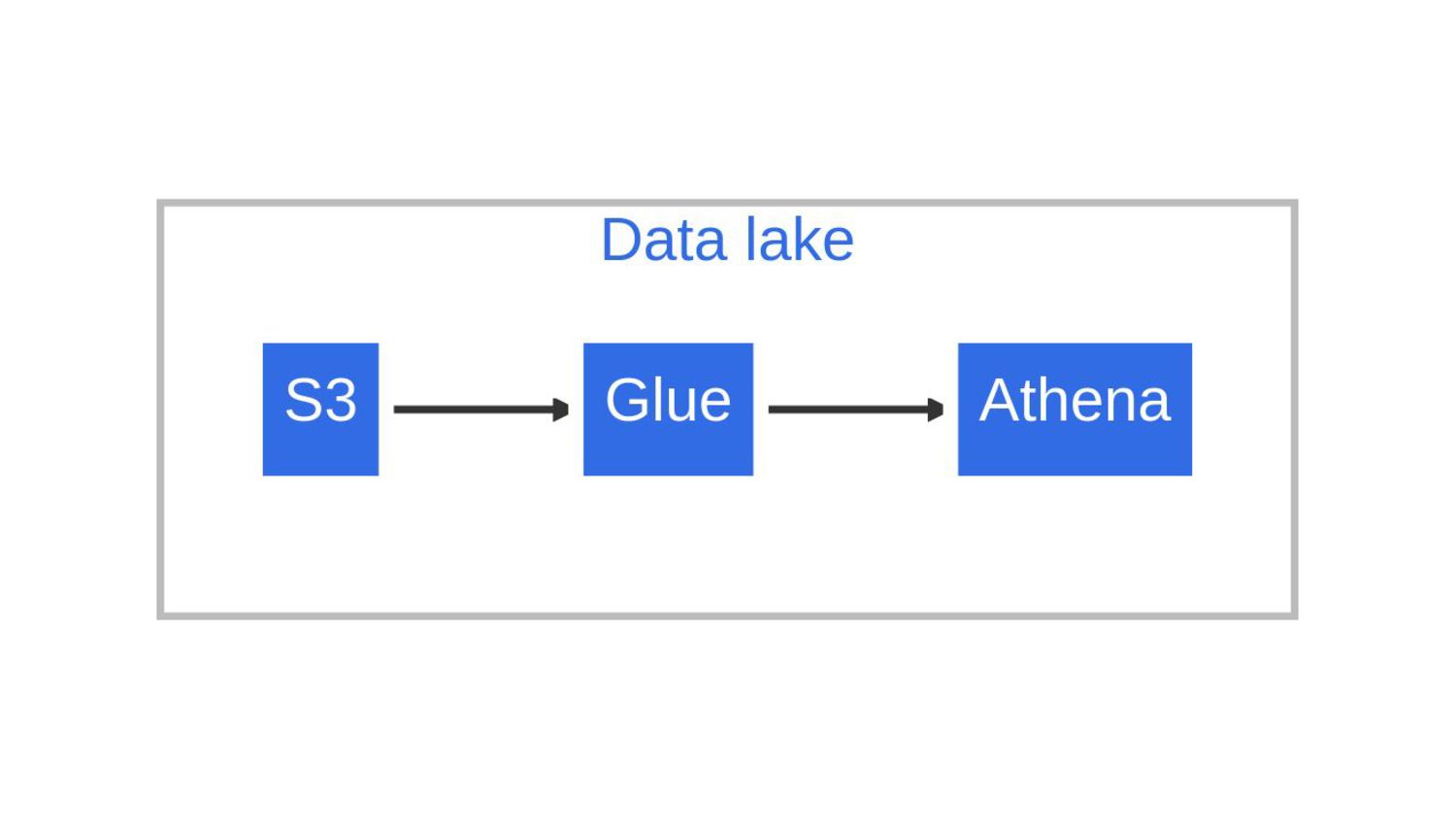
- the data lake: AWS S3, AWS Glue and AWS Athena
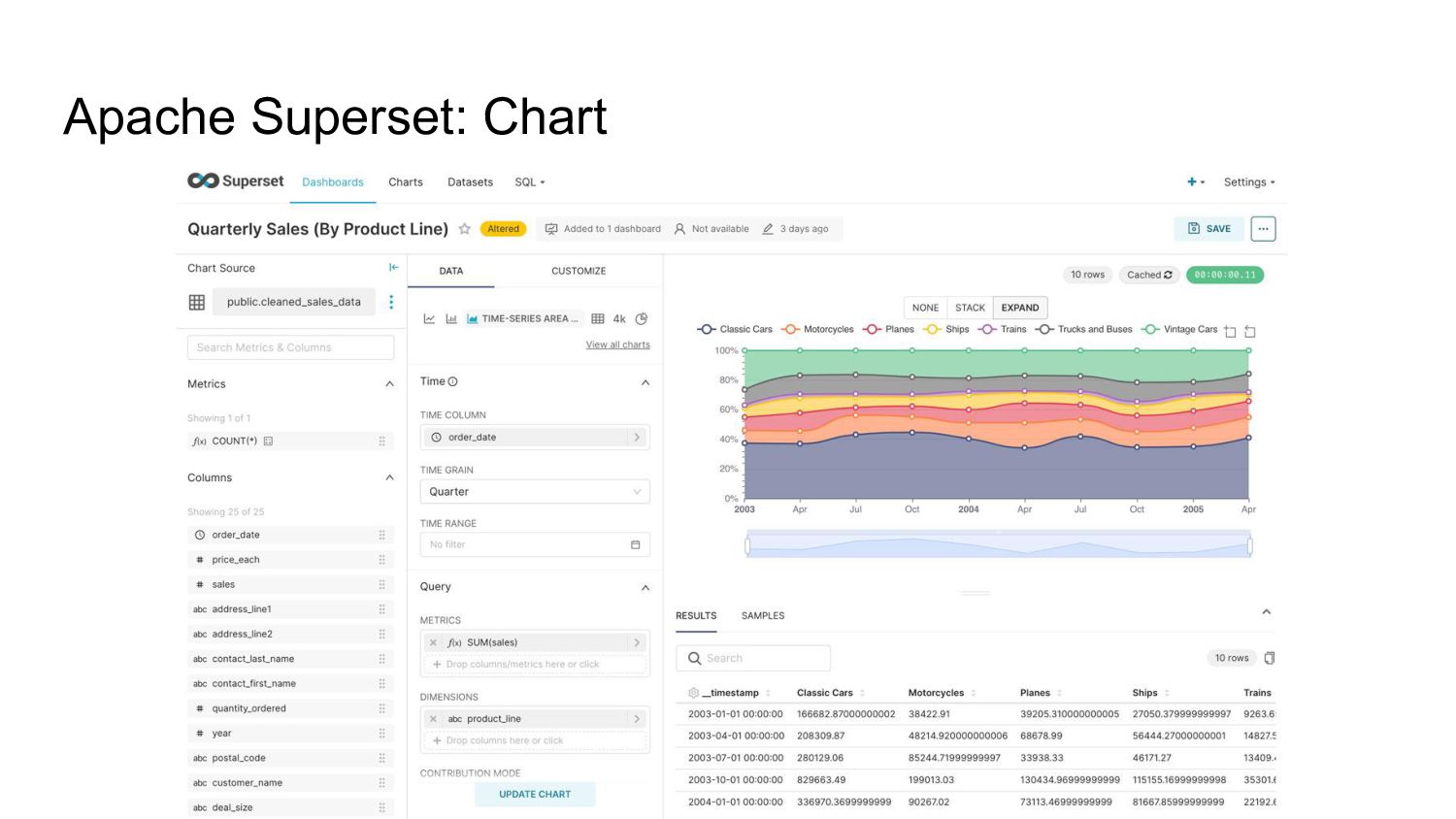
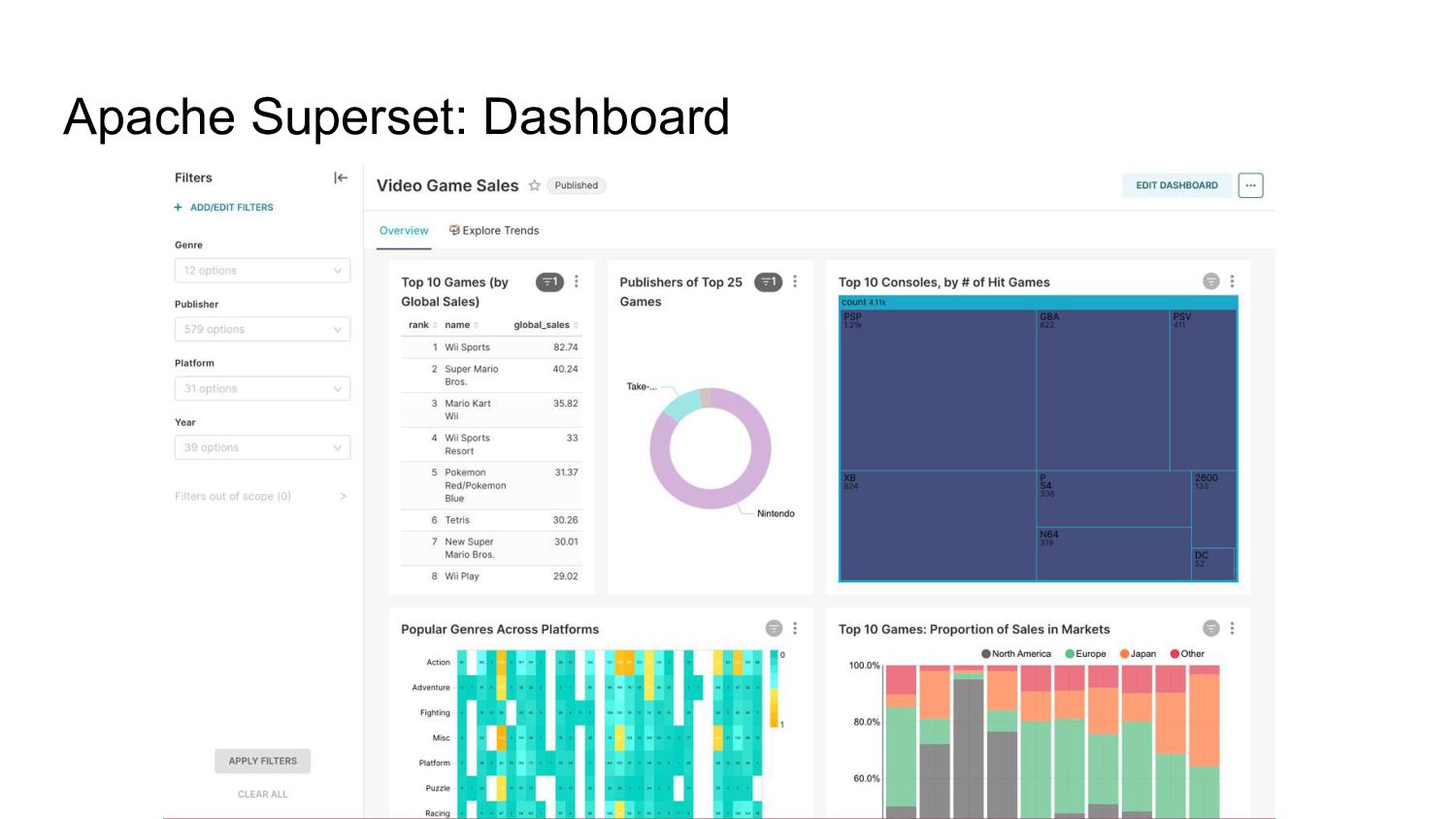
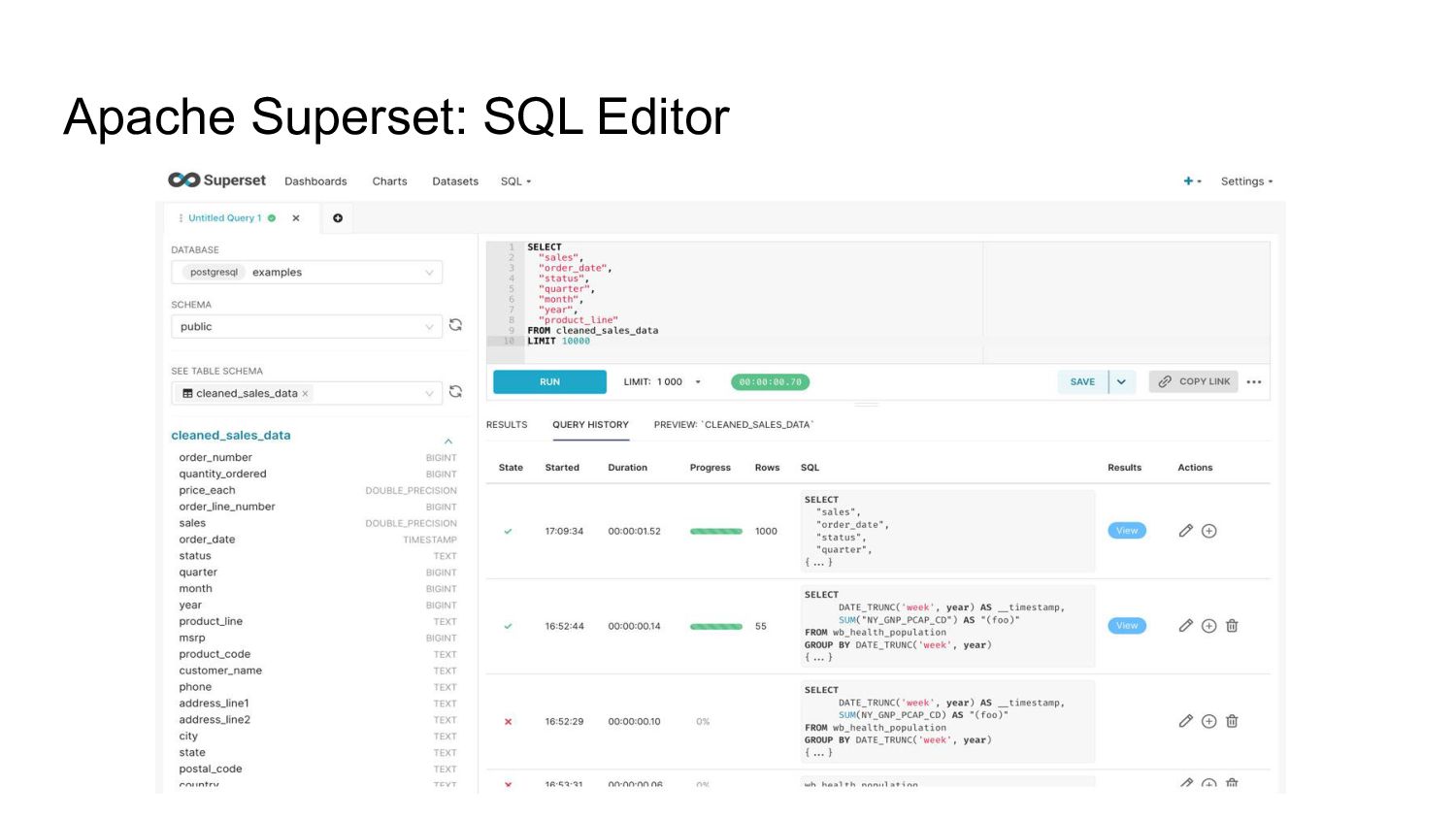
- the exploration and visualization platform: Apache Superset
- data formats and Python implementations
- vendors lock-in
Presented at Pycon Portugal 2023 on September 7th 2023.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Riccardo Magliocchetti @rmistaken / @[email protected]](https://files.speakerdeck.com/presentations/a0355b56ea5f4679b2b3e8cf3ebb89b7/slide_25.jpg){kind=link}