platforms. Massive amount of information consumes the attention of its recipients. We need to allocate that attention efciently. Need to extract knowledge from large, noisy, redundant, missing and fuzzy data.
hidden relationships that exist in these huge volumes of data and do not follow a particular parametric design. Random Forest have desirable statistical properties.
hidden relationships that exist in these huge volumes of data and do not follow a particular parametric design. Random Forest have desirable statistical properties. Random Forest scales well computationally.
exist in these huge volumes of data and do not follow a particular parametric design. Random Forest have desirable statistical properties. Random Forest scales well computationally. Random Forest performs extremely well in a variety of possible complex domains (Breiman, 2001; Gonzalez-Recio & Forni, 2011). Why Random Forest?
- They have very good predictive ability because use additivity of models performances. Based on Classifcation And Regression Trees (CART). Use Randomization and Bagging. Performs Feature Subset Selection. Convenient for classifcation problems. Fast computation. Simple interpretation of results for human minds. Previous work in genome-wide prediction (Gonzalez-Recio and Forni, 2011) The Algorithm
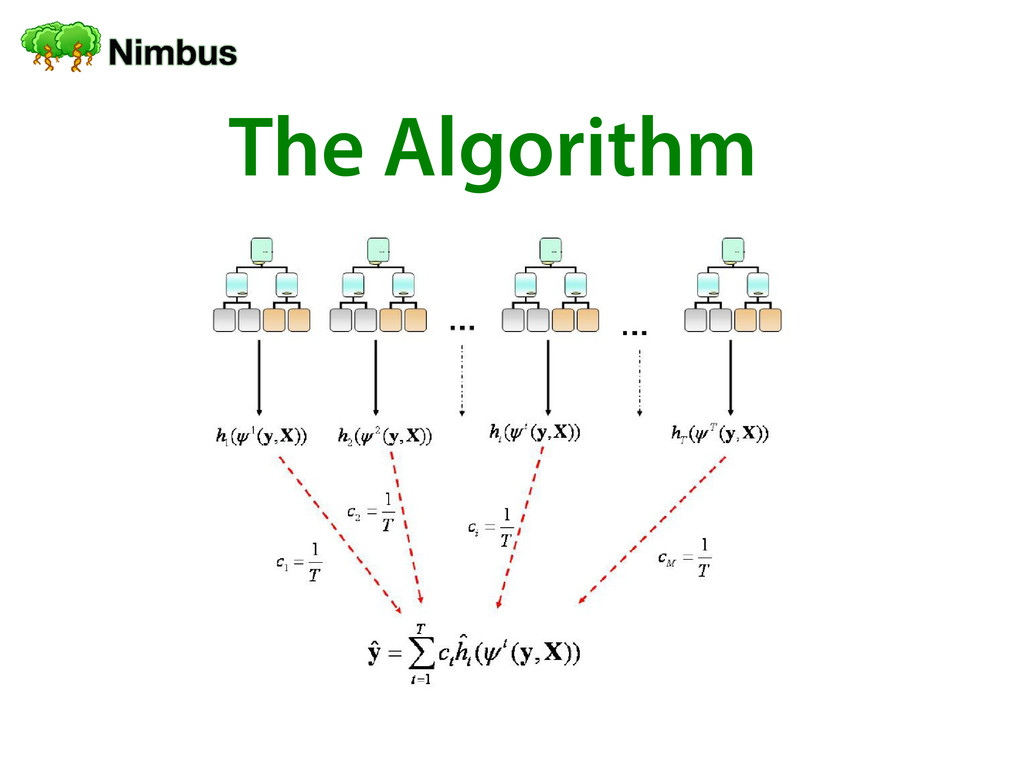
Build a CART ( fi (y, X) = ht (x) ) using only mtry proportion of SNPs in each node. Repeat M times to reduce residuals by a factor of M. Average estimates c0 = μ ; ci = 1/M
with y = vector of phenotypes (response variables) X = (x1, x2) = matrix of features y1 x11 x12 … … ... yi xi1 xi2 … … ... yn xn1 xn2 The Algorithm Classifcation and regression trees:
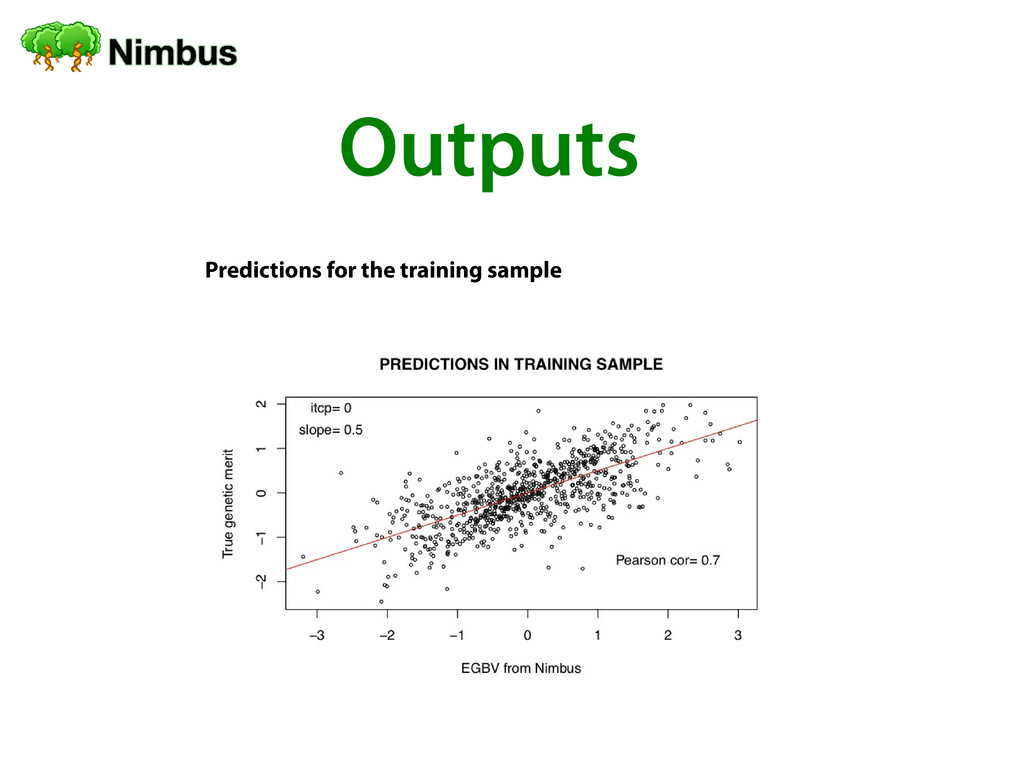
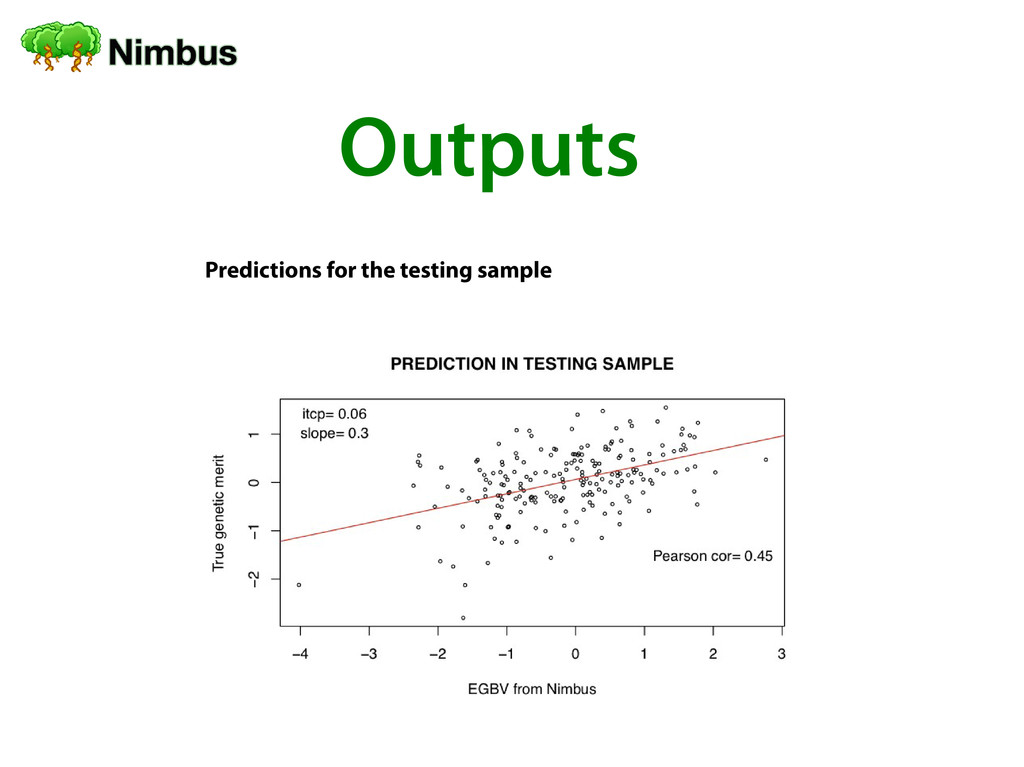
Training of a prediction forest Genomic Prediction of a testing sample Using a training set of individuals Nimbus creates a reutilizable forest Nimbus calculates SNP importances Generalization error are computed for every tree in the forest Using a custom/reused forest, specif i ed via conf i g.yml Using a new trained forest
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}