Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSとSRE 〜サービスの信頼性〜
Search
y-ohgi
March 26, 2025
390
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSとSRE 〜サービスの信頼性〜
つながりテック #2 AWSトークで締めくくる年度末LT大会 ~初登壇も大歓迎!~
https://tunagari-tech.connpass.com/event/344667/
y-ohgi
March 26, 2025
More Decks by y-ohgi
See All by y-ohgi
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
140
EKS Auto-Mode with Kro
y0hgi
0
250
AWS Cloud Control API & AWSCC Provider
y0hgi
1
83
re:Invent 2024 re:Cap コンピューティング&コンテナ
y0hgi
3
490
クラウドを今から学ぶには
y0hgi
0
740
クラウド・コンテナ・CI/CDわからん会
y0hgi
0
89
入門 Docker - JAWS-UG東京 ランチタイムLT会 #14
y0hgi
1
450
AWS CloudShell で開発したかった話 / i-cant-develop-in-cloudshell
y0hgi
1
2.1k
クラウド入門/Introduction Cloud
y0hgi
0
130
Featured
See All Featured
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Are puppies a ranking factor?
jonoalderson
1
3.7k
We Have a Design System, Now What?
morganepeng
55
8.2k
Building the Perfect Custom Keyboard
takai
2
810
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Navigating Team Friction
lara
192
16k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Six Lessons from altMBA
skipperchong
29
4.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Google's AI Overviews - The New Search
badams
0
1.1k
Thoughts on Productivity
jonyablonski
76
5.2k
Transcript
AWSとSRE 〜サービスの信頼性〜 つながりテック #2 AWSトークで締めくくる年度末 LT大会 ~初登壇も大歓迎!~ 2025/03/26
y-ohgi Topotal, Inc. SRE whoami
1. What is "SRE" 2. SLI/SLO 3. Observability 4. Toil
Agenda
「 SREとは、ソフトウェアエンジニアに運用チームの設計を依頼したときにできあがるものです。」 What is "SRE" https://www.oreilly.co.jp/books/9784873117911/ > 『SRE サイトリライアビリティエンジニアリング 』
> 1.2 サービス管理へのGoogleのアプローチ:サイトリライアビリティエンジニアリング
SREとは What is "SRE" Site Reliability Engineeringというプラクティス です。 また、それを実践するエンジニア をSite
Reliability Engineerとも呼びます。 組織によって形は違いますが、サービスの信頼性を担保すること をメインのミッションとしています。 SREについては書籍『SRE サイトリライアビリティエンジニアリング 』が原典と言えるでしょう。 この書籍からSREの成り立ちやプラクティスを学ぶことができます。 しかし、この本は590ページの長編かつある程度のCSの知識を前提としています。 はじめてSREを学ぶ方は、書籍『SREをはじめよう』から入る のも良いでしょう。 最終的にSREの本質を学ぶためには原典を読む必要があると個人的には考えます。 https://www.oreilly.co.jp/books/9784873117911/ https://www.oreilly.co.jp/books/9784814400904/
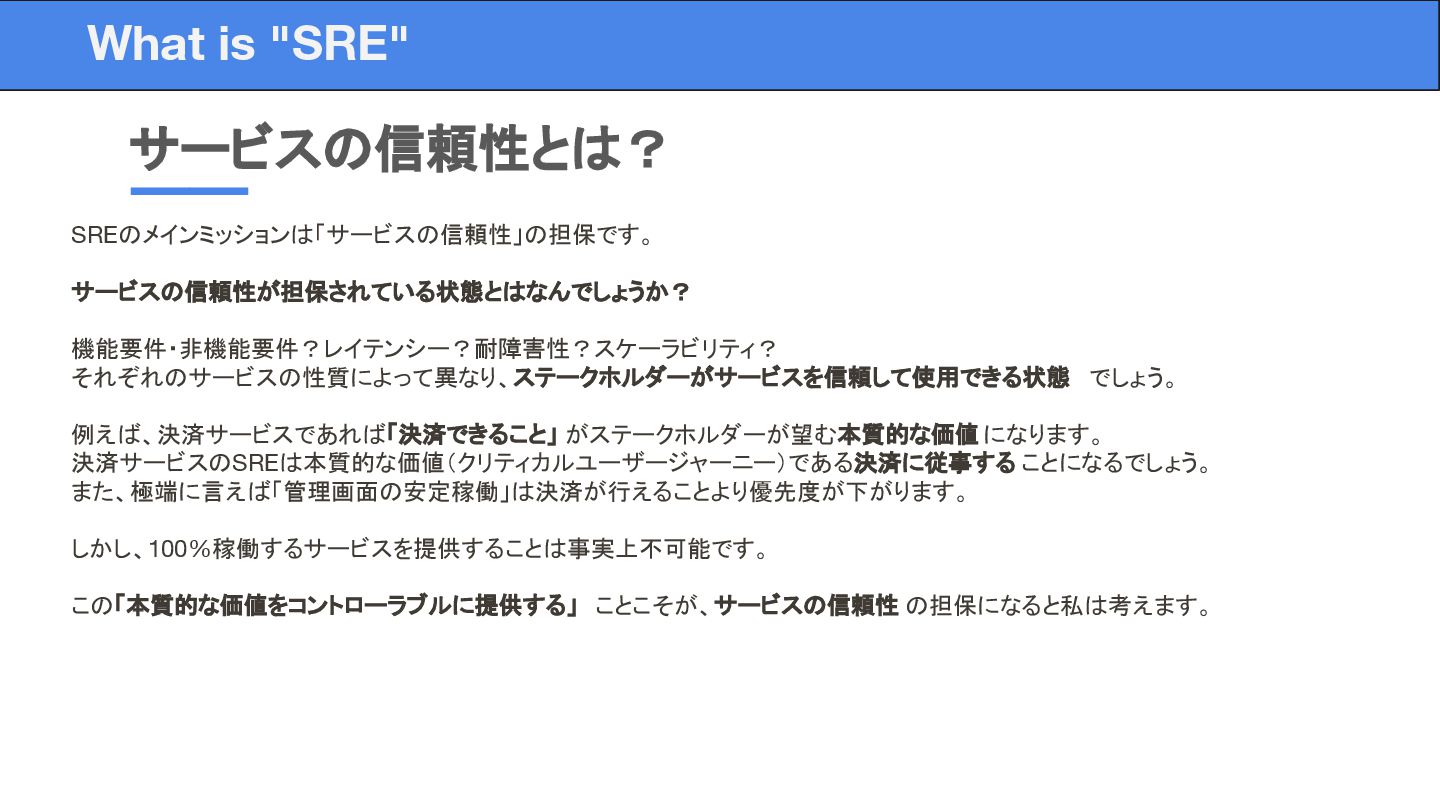
SREのメインミッションは「サービスの信頼性」の担保です。 サービスの信頼性が担保されている状態とはなんでしょうか? 機能要件・非機能要件?レイテンシー?耐障害性?スケーラビリティ? それぞれのサービスの性質によって異なり、ステークホルダーがサービスを信頼して使用できる状態 でしょう。 例えば、決済サービスであれば「決済できること」 がステークホルダーが望む本質的な価値 になります。 決済サービスのSREは本質的な価値(クリティカルユーザージャーニー)である決済に従事する ことになるでしょう。
また、極端に言えば「管理画面の安定稼働」は決済が行えることより優先度が下がります。 しかし、100%稼働するサービスを提供することは事実上不可能です。 この「本質的な価値をコントローラブルに提供する」 ことこそが、サービスの信頼性 の担保になると私は考えます。 サービスの信頼性とは? What is "SRE"
SREの進化 What is "SRE" SREは2005年頃にGoogleが提唱したプラクティス/ロールです。 原典的に言うと、ソフトウェアエンジニアの知識が必要です。 フロントエンド・バックエンド・インフラそれぞれの知識を持ってそれぞれ垣根を越えて改善を行います。 そしてGoogleというテクノロジーの大企業のプラクティス でもあります。 2025年現在、20年の月日が経ち、SREのプラクティスは進化をし続け、多様化しています。
小規模なスタートアップでもSREというロールがあることも当たり前になりつつあります。 また、インフラ専業(インフラのスキルセットのみ。)でもSREの肩書きを持つケースもあります。 それでもSREの本質は「サービスの信頼性」の担保がメインミッション であると私は考えています。
1. What is "SRE" 2. SLI/SLO 3. Observability 4. Toil
Agenda
サービスの信頼性の指針 SLI/SLO SLIとSLOを定義することがサービスの信頼性の指針になると考えます。 SLI(Service Level Indicator) Service Level Indicatorの略で、システムの安定稼働を表す指標です。 例えば「エラー率」・「リクエストのレイテンシ」・「稼働率」などです。
SLO(Service Level Objective) Service Level Objectiveの略で、システム提供の可用性を定義します。 例えば「リクエスト成功率が 99.5%以上」のようにです。 SLIをもとにSLOを定義し、このSLOを高く設定するほど当然設計・開発・運用の難易度が上がります。
SLI - Service Level Indicator SLI/SLO SLIはユーザー影響に直接関係 のある、定量的に観測可能な値 です。 例えば「レイテンシー」「エラーレート」「スループット」などです。
SLIにする値は単純なアラートとは異なり、 CUJベースであることが大事だと私は考えます。 SLIはサービスの性質・本質 によって異なります。 例として、 取り上げた決済サービスであれば、「決済の成功率」が重要な指標 になるでしょう。 ブログサイトであればステークホルダーは多くの閲覧者がサイトが高速に表示されることを期待するため、「レイテンシー」が重要 な指標になるでしょう。
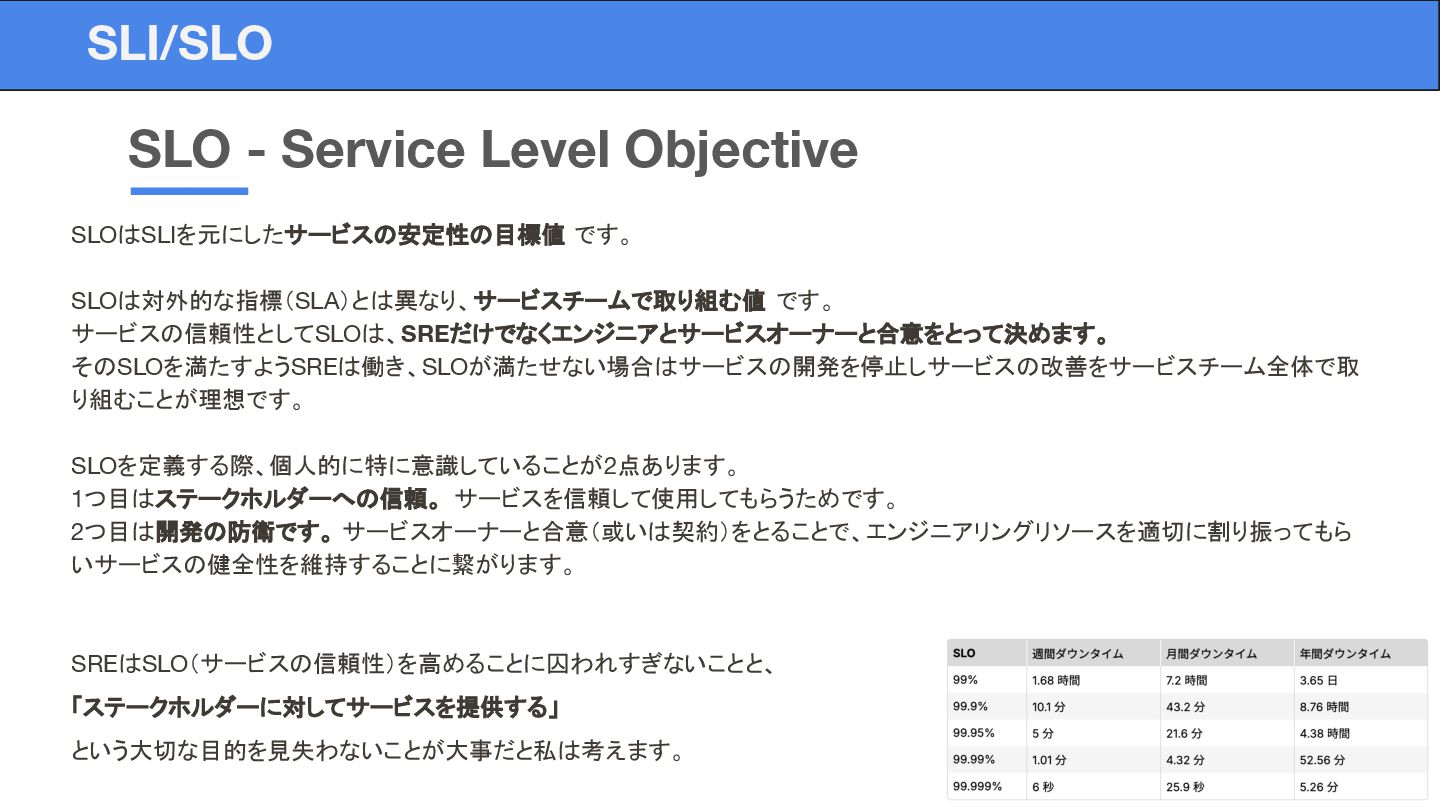
SLOはSLIを元にしたサービスの安定性の目標値 です。 SLOは対外的な指標(SLA)とは異なり、サービスチームで取り組む値 です。 サービスの信頼性としてSLOは、SREだけでなくエンジニアとサービスオーナーと合意をとって決めます。 そのSLOを満たすようSREは働き、SLOが満たせない場合はサービスの開発を停止しサービスの改善をサービスチーム全体で取 り組むことが理想です。 SLOを定義する際、個人的に特に意識していることが2点あります。 1つ目はステークホルダーへの信頼。 サービスを信頼して使用してもらうためです。
2つ目は開発の防衛です。 サービスオーナーと合意(或いは契約)をとることで、エンジニアリングリソースを適切に割り振ってもら いサービスの健全性を維持することに繋がります。 SREはSLO(サービスの信頼性)を高めることに囚われすぎないことと、 「ステークホルダーに対してサービスを提供する」 という大切な目的を見失わないことが大事だと私は考えます。 SLO - Service Level Objective SLI/SLO
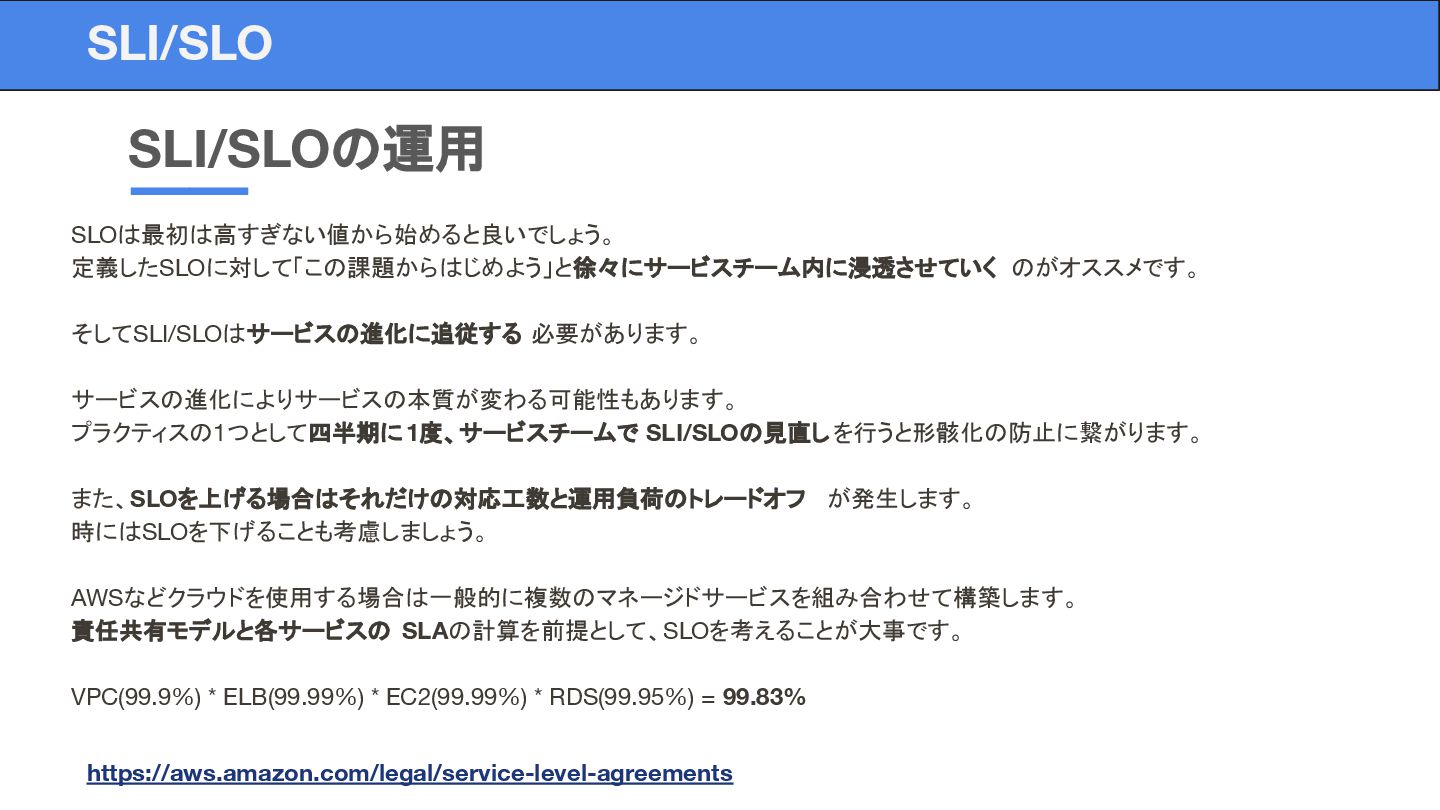
SLI/SLOの運用 SLI/SLO SLOは最初は高すぎない値から始めると良いでしょう。 定義したSLOに対して「この課題からはじめよう」と徐々にサービスチーム内に浸透させていく のがオススメです。 そしてSLI/SLOはサービスの進化に追従する 必要があります。 サービスの進化によりサービスの本質が変わる可能性もあります。 プラクティスの1つとして四半期に1度、サービスチームで SLI/SLOの見直しを行うと形骸化の防止に繋がります。
また、SLOを上げる場合はそれだけの対応工数と運用負荷のトレードオフ が発生します。 時にはSLOを下げることも考慮しましょう。 AWSなどクラウドを使用する場合は一般的に複数のマネージドサービスを組み合わせて構築します。 責任共有モデルと各サービスの SLAの計算を前提として、SLOを考えることが大事です。 VPC(99.9%) * ELB(99.99%) * EC2(99.99%) * RDS(99.95%) = 99.83% https://aws.amazon.com/legal/service-level-agreements
1. What is "SRE" 2. SLI/SLO 3. Observability 4. Toil
Agenda
3 Pillars of Observability Observability 監視はサービスを運用する上で切っても切り離せません。 サービスを安定して提供するには自身が運用開発している「サービス」を知る 必要があります。 そのための代表的なプラクティスとして 3
Pillars of Observability (可観測性の3つの柱)があります。 メトリクス CPU, Memory, Network, Diskなど、特定の時間の値です。 クラウドであれば各サービスが主要なメトリクスを自動的に取得してくれます。 ログ サービスが出力する何らかのイベントです。 起動時・終了時・アクセスログ・エラーログなどのイベント履歴です。 トレース システムの各処理を追跡し、詳細な情報を収集する仕組みです。 例えば特定のAPIがコールされた時に、その詳細情報(どの関数にどのぐらいの時間がかかったかなど)を取得します。
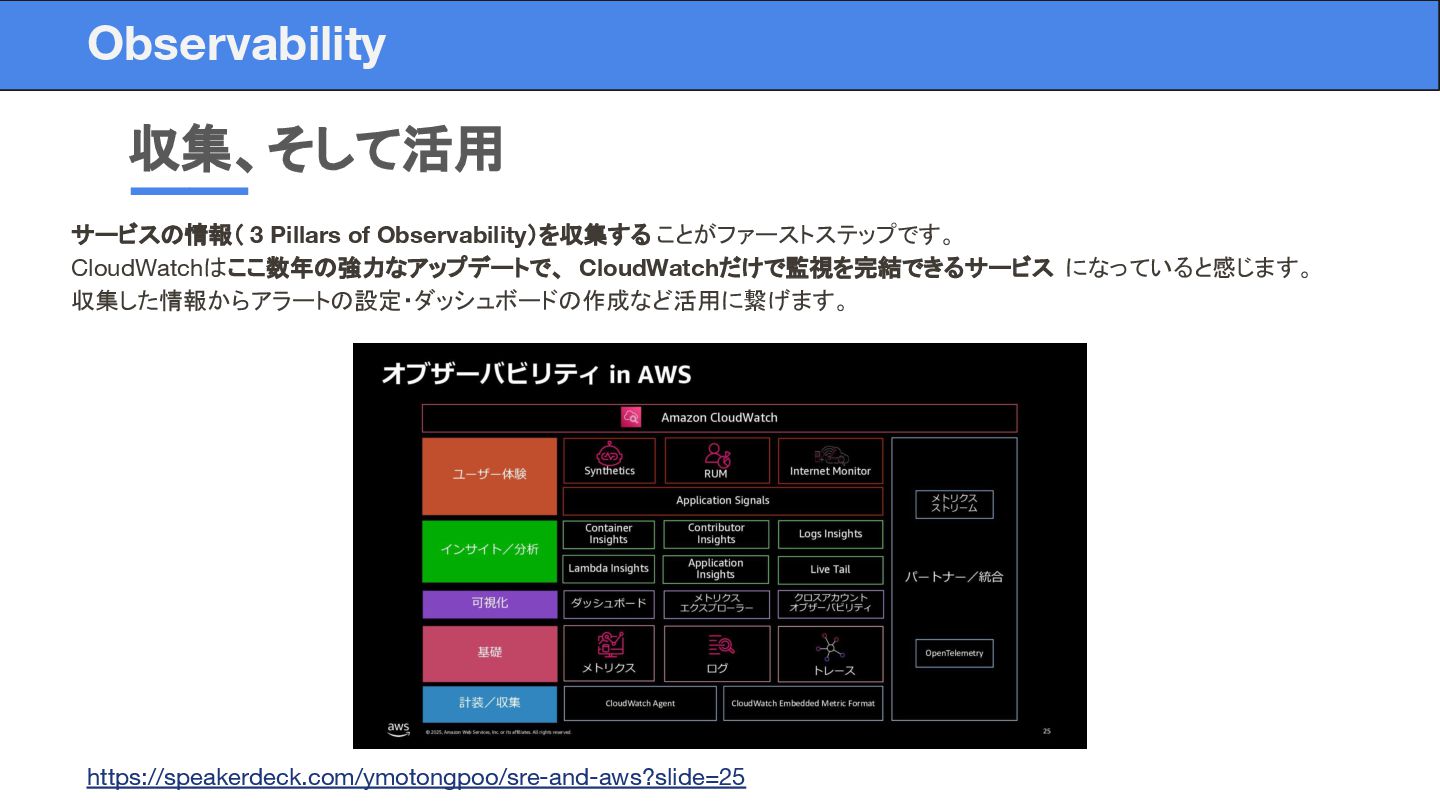
収集、そして活用 Observability サービスの情報( 3 Pillars of Observability)を収集する ことがファーストステップです。 CloudWatchはここ数年の強力なアップデートで、 CloudWatchだけで監視を完結できるサービス
になっていると感じます。 収集した情報からアラートの設定・ダッシュボードの作成など活用に繋げます。 https://speakerdeck.com/ymotongpoo/sre-and-aws?slide=25
サービスを学ぶ Observability サービスの監視の基盤が整うと、必然的にサービスの理解が深まります 。 監視はより良いサービスにする良い材料 になってくれます。 アラートやダッシュボードの活用を行うことでサービスの改善点が見えてきます 。 単純にエラーに気づくことだけでなく、未然に障害を防ぐことやキャパシティプランニングに繋げることができます。 そしてサービスは人間が開発運用する以上、障害は起きます
。 監視を行うことで「なぜ障害が起きたのか?」に対して収集した情報を元に解決に繋げる ことができます。 そして、それだけではもったいなく、振り返り(ポストモーテム )を行うことが大切です。 ポストモーテム 障害の収束後に行う事後検証と振り返り分析 です。 根本原因の調査・障害対応の振り返り・再発防止を行い、ドキュメント化することで組織の資産 になります。 責任追及の場ではなく「サービスの学習と改善」を目的に行う ことが大切です。 障害の発生は歓迎できるものではありませんが、サービスを学ぶ貴重な機会 にできます。
1. What is "SRE" 2. SLI/SLO 3. Observability 4. Toil
Agenda
トイルとは トイルとは「手動で行っている自動化可能な反復的な作業」 のことです。 例えば手動でのデプロイ・スケールアウト・バックアップなどです。 このようなトイルを放置してしまうと サービスの成長と共に(無駄な)工数が増えていきます 。 人間の工数はサービスの本質的な作業 に使いたいはずです。 自動化を行える作業を見つけたら
自動化を行い、「トイルの撲滅」 を意識すると良いでしょう。 しかし、過剰な自動化は複雑性や属人性を高めてしまう可能性を考慮しましょう。 Toil
トイルの撲滅 トイル撲滅の例を紹介します。 何からやるか迷ったら参考にしていただければ幸いです。 • CI/CD ◦ GitHub ActionsでCI、Code兄弟を使用してCD • 自動バックアップ
◦ AWS Backupを使用してRDS・EBSの自動バックアップ • Infrastructure as Code ◦ CDK・Terraformでリソースを手動ではなく、コード管理 • オートスケール ◦ Auto Scaling・AWS ECS Cluster Auto Scalingで自動でのスケールアウト/スケールイン • IAM Identity CenterでのSSO ◦ 入退職者管理のガバナンスの統制 Toil
まとめ
• SREは現在も進化しているプラクティス だよ! • サービスの信頼性 のファーストステップに、 SLI/SLOの導入はいかがでしょうか? • 監視の導入やポストモーテムへの取り組みで、 サービスを学んで改善
に繋げよう! • トイルの撲滅に取り組み サービスの本質 に取り組もう! まとめ
• SRE サイトリライアビリティエンジニアリング ◦ https://www.oreilly.co.jp/books/9784873117911/ • SREをはじめよう ◦ https://www.oreilly.co.jp/books/9784814400904/ •
サイト信頼性エンジニアリングと Amazon Web Services / SRE and AWS ◦ https://speakerdeck.com/ymotongpoo/sre-and-aws • 優れた SLO を策定するには : CRE が現場で学んだこと ◦ https://cloud.google.com/blog/ja/products/gcp/building-good-slos-cre-life-lessons • SRE の原則に沿ったトイルの洗い出しとトラッキング ◦ https://cloud.google.com/blog/ja/products/gcp/identifying-and-tracking-toil-using-sre-principles • SREとは?DevOpsとの違いや、よくある誤解を解説 ◦ https://newrelic.com/jp/blog/best-practices/what-is-sre 参考
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}