Share
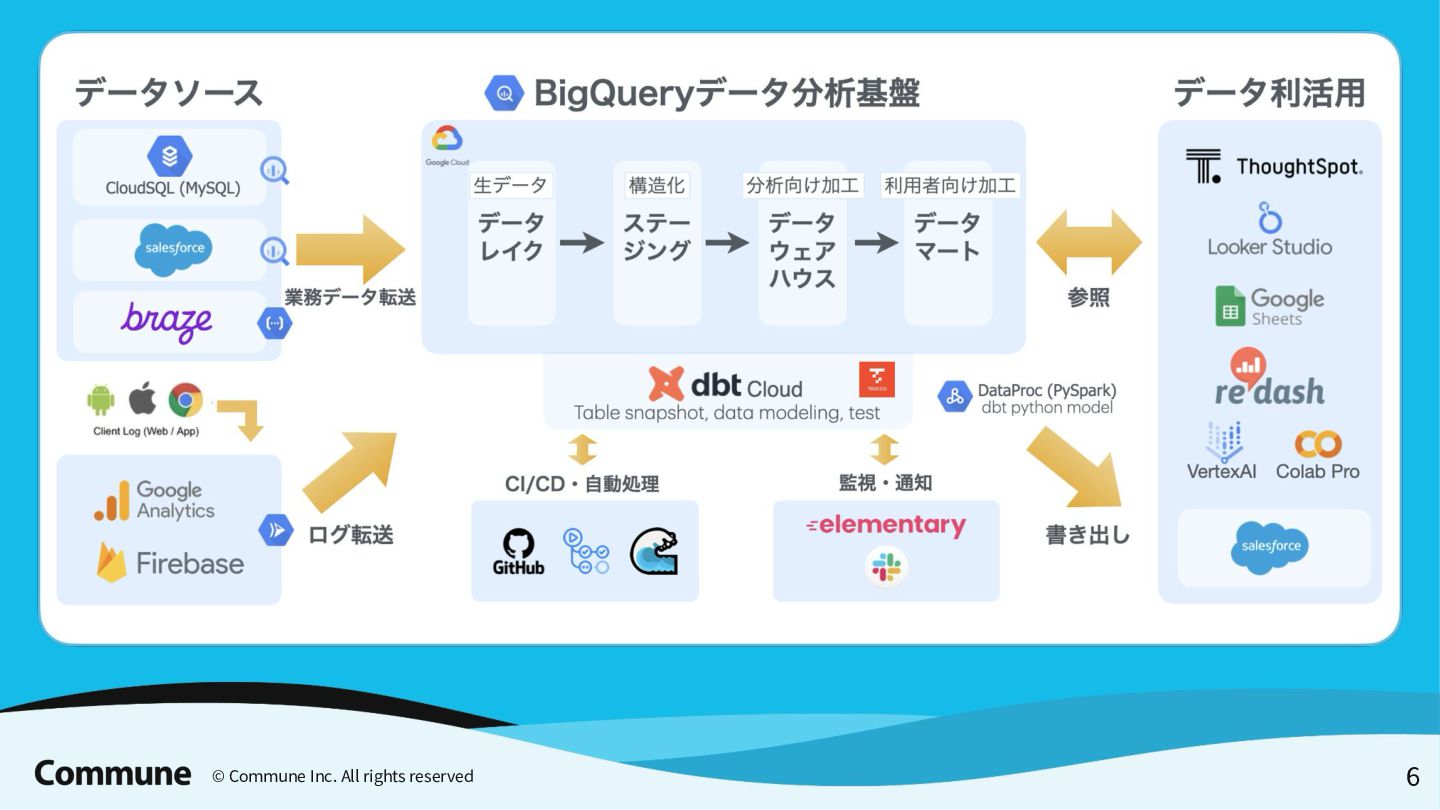
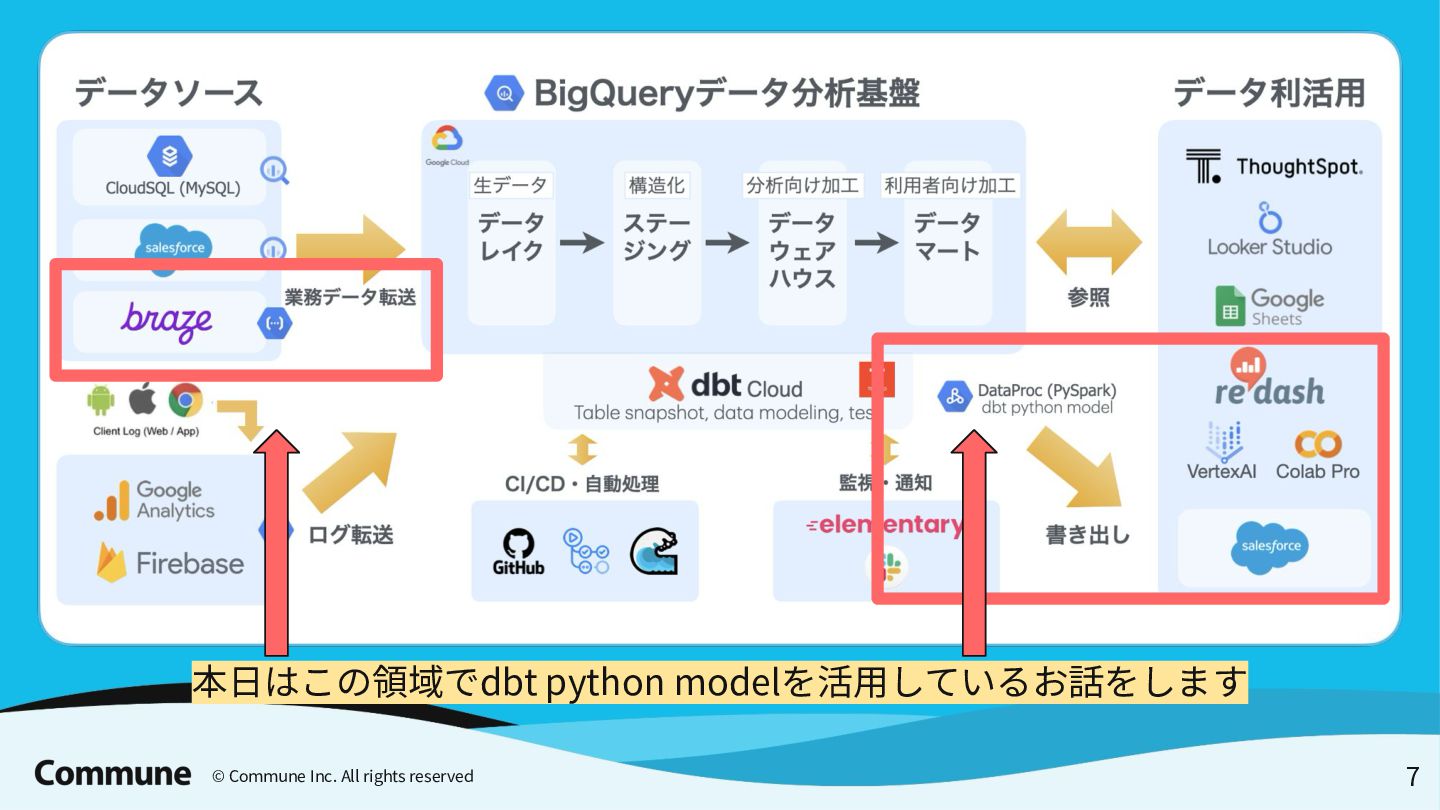
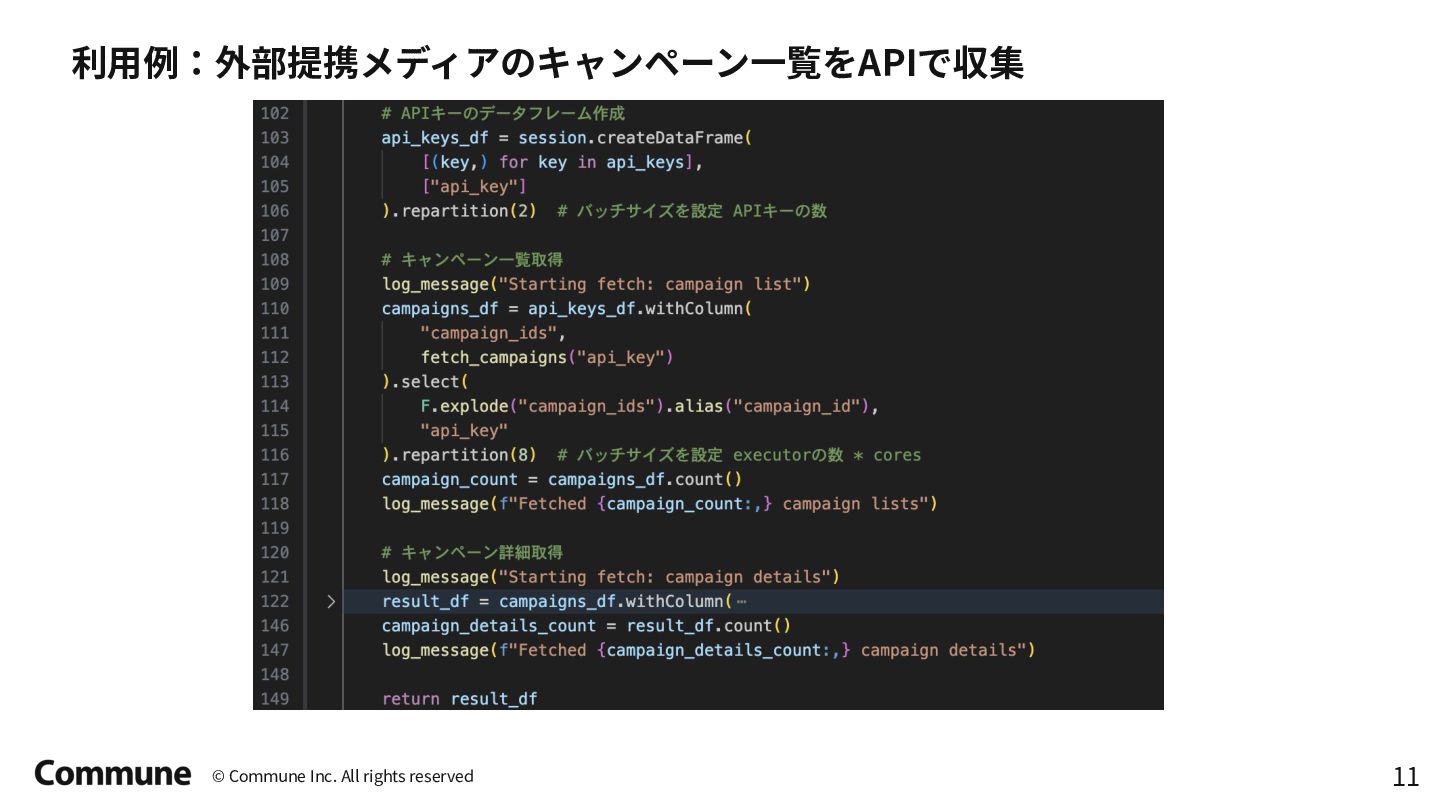
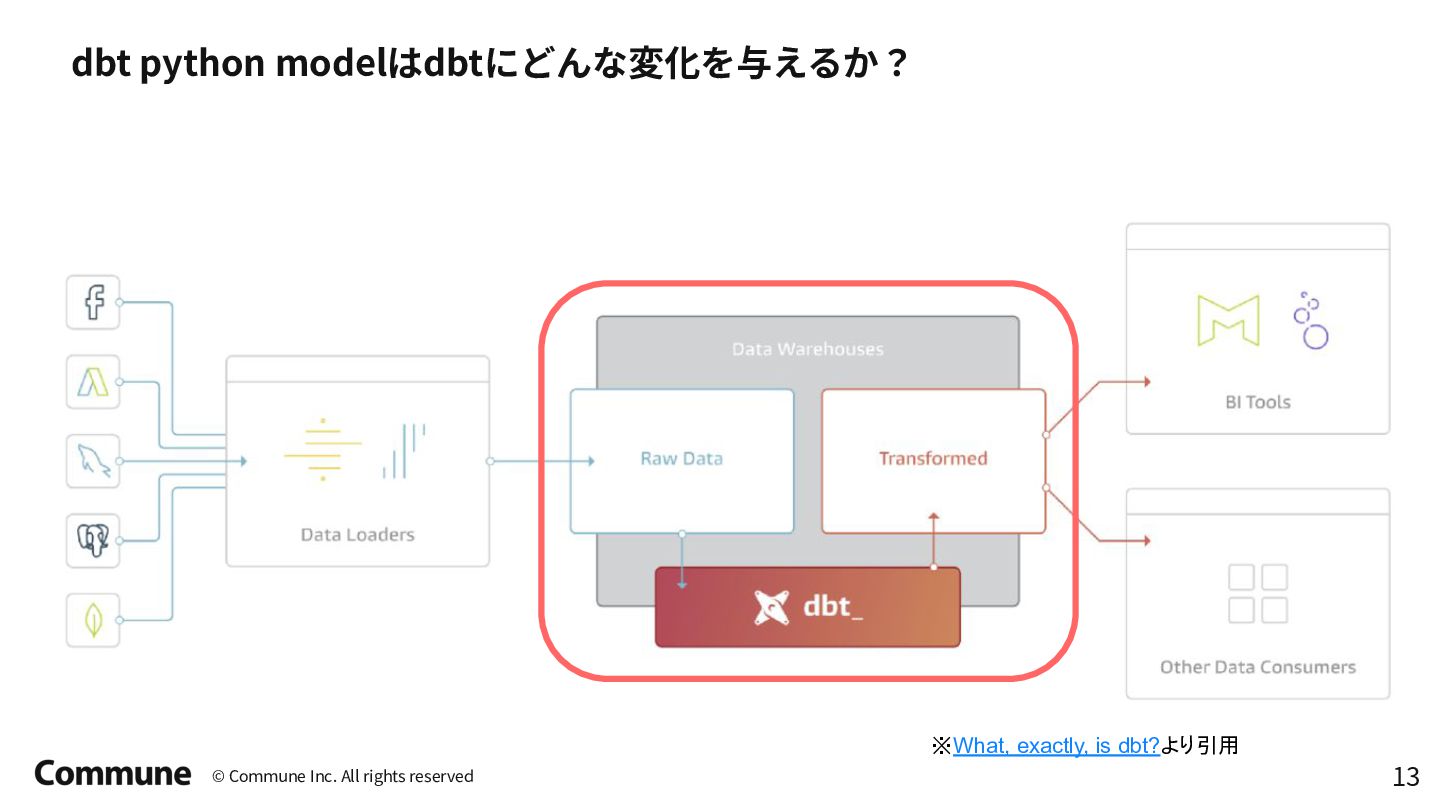
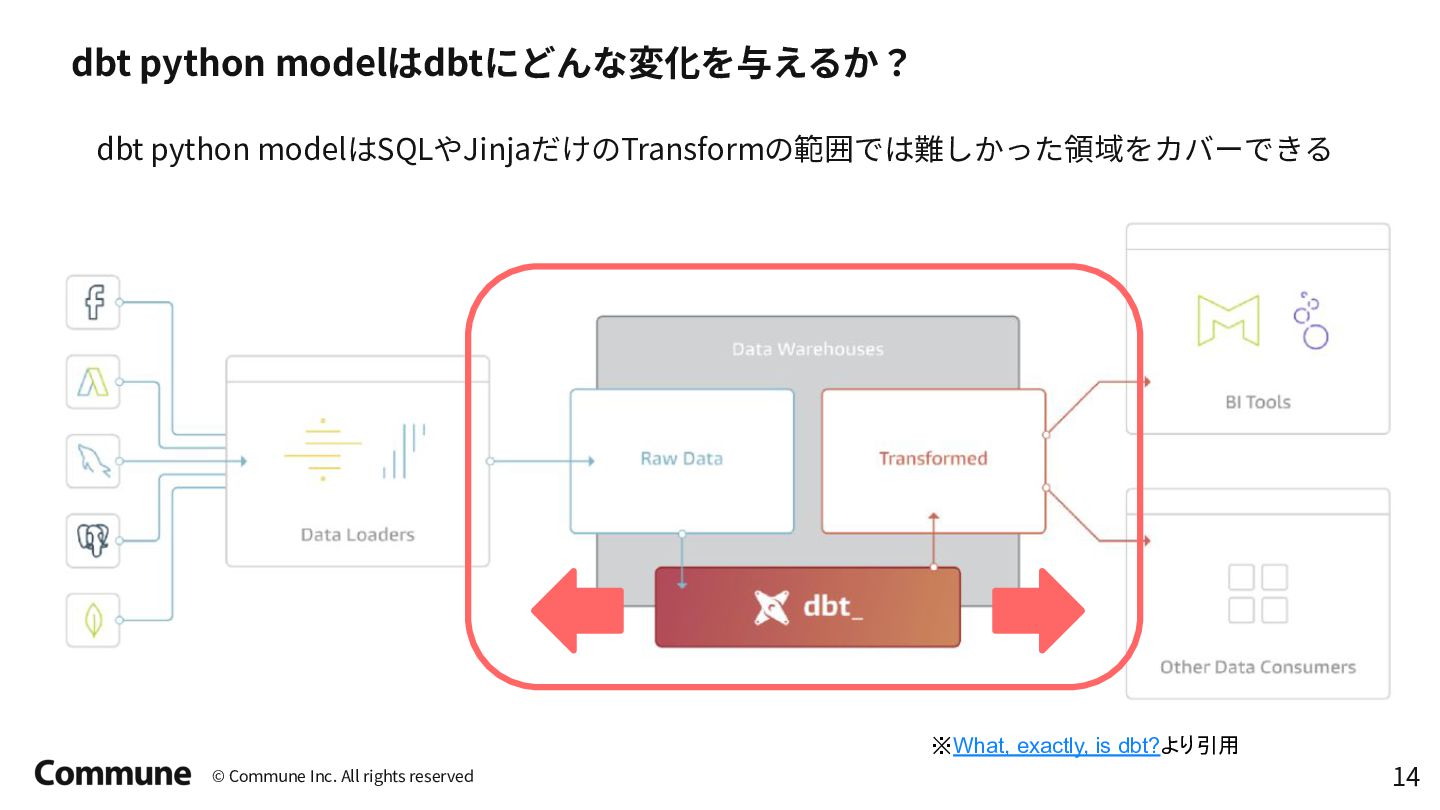
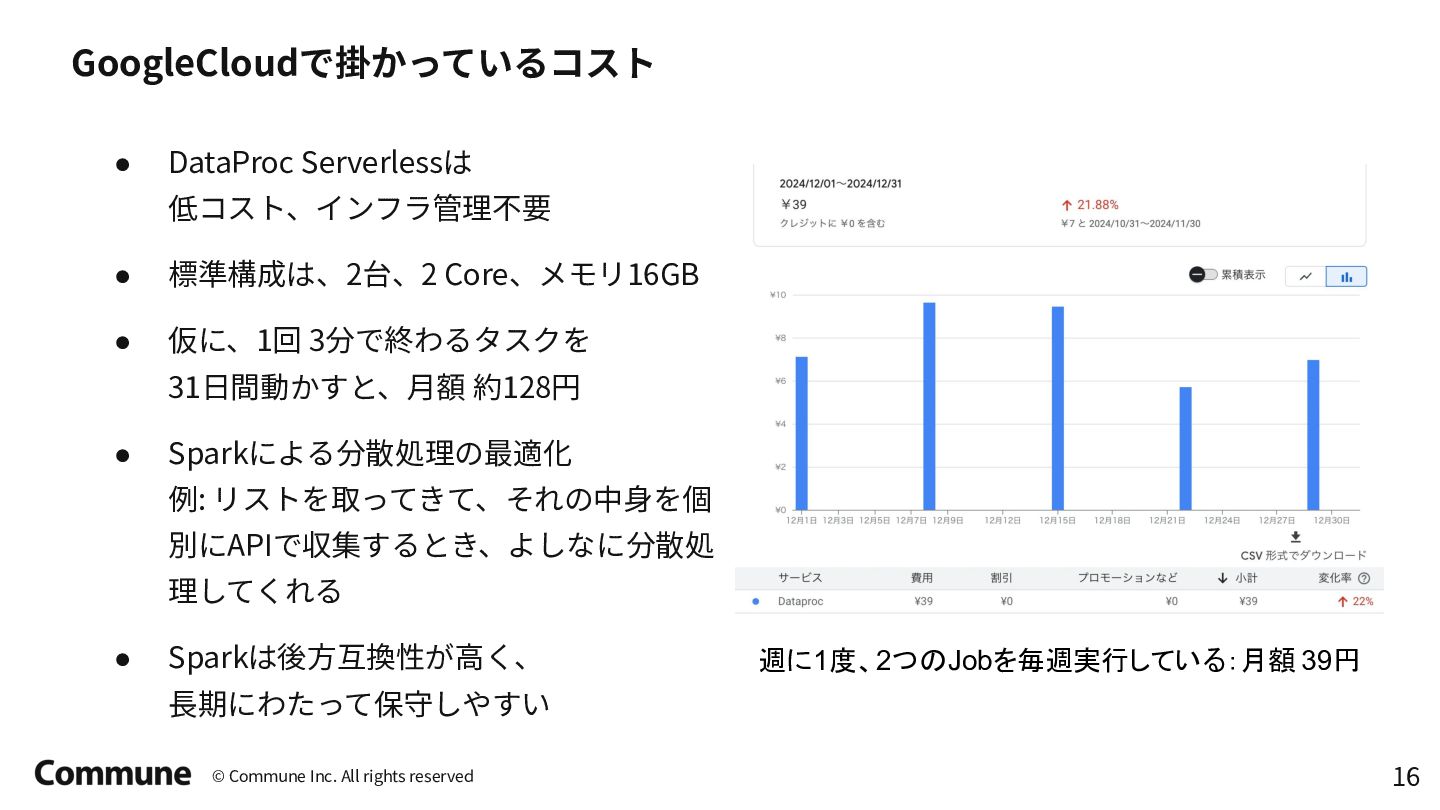
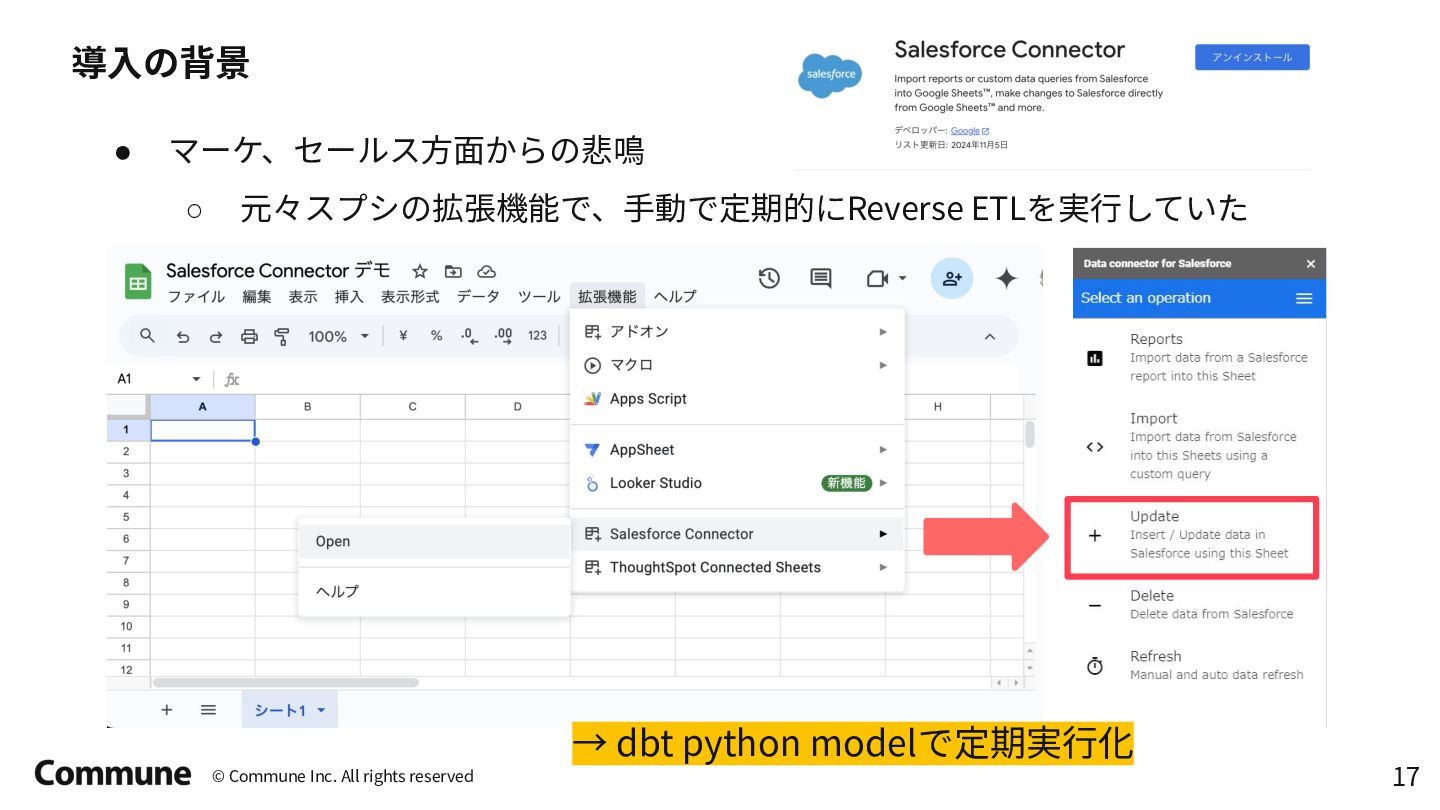
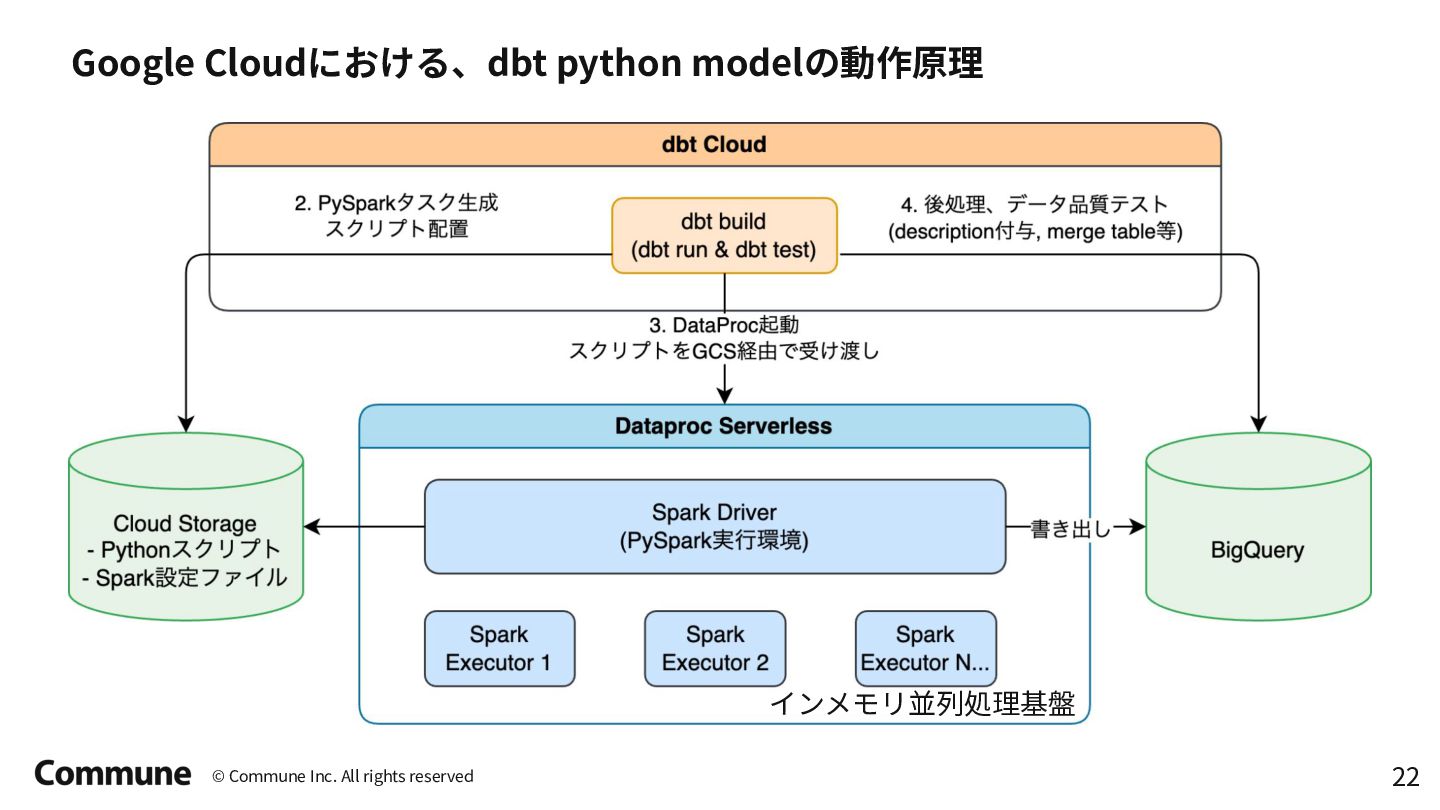
Tokyo dbt Meetup #12での発表資料 前半では弊社のデータパイプラインのアーキテクチャ概要とdbt導入のメリット、特にdbt python modelの活用事例(ReverseETL、外部APIからのデータ収集など)について説明し、 後半ではDataProc ServerlessでのPySpark活用方法や実践的な運用に関する10のTipsを紹介しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
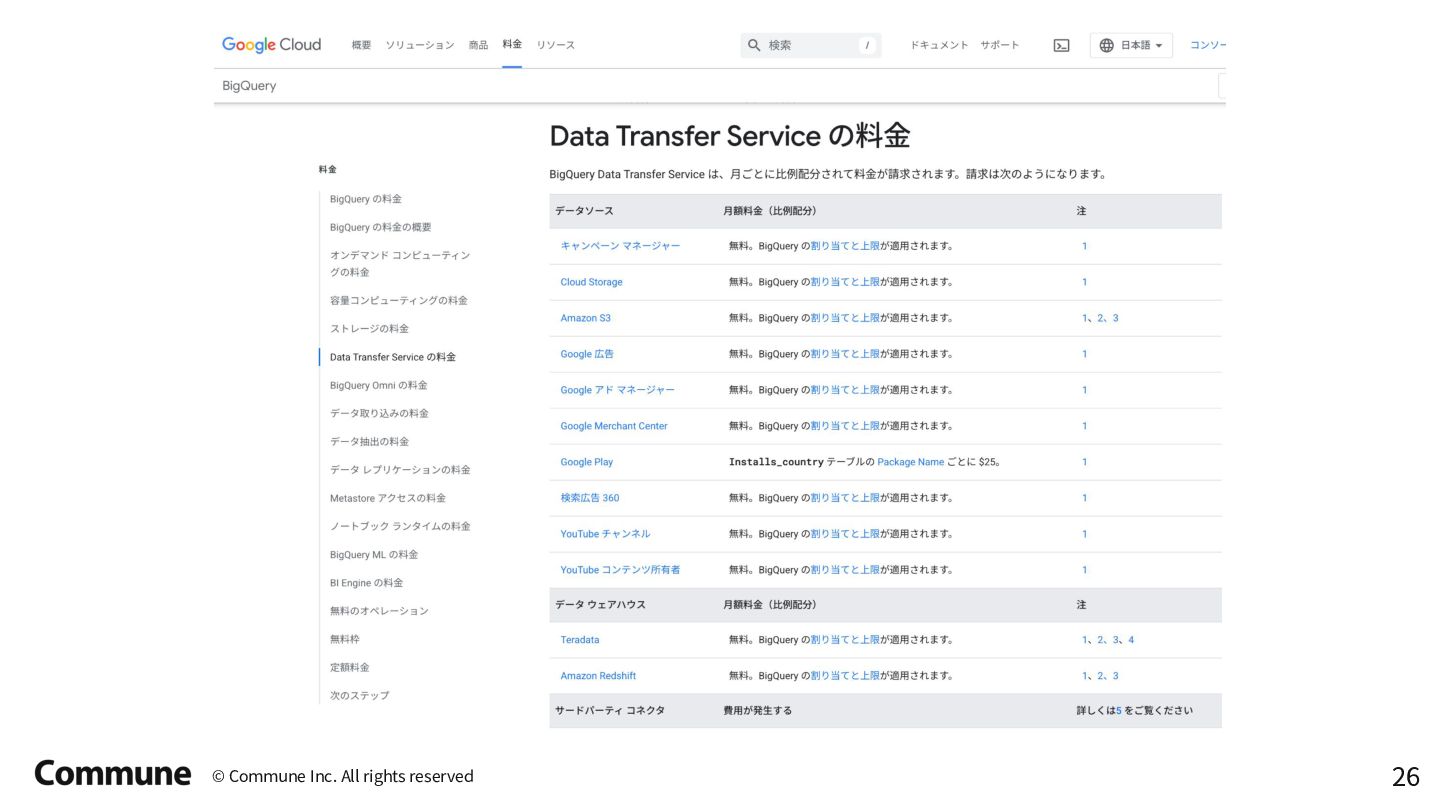{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
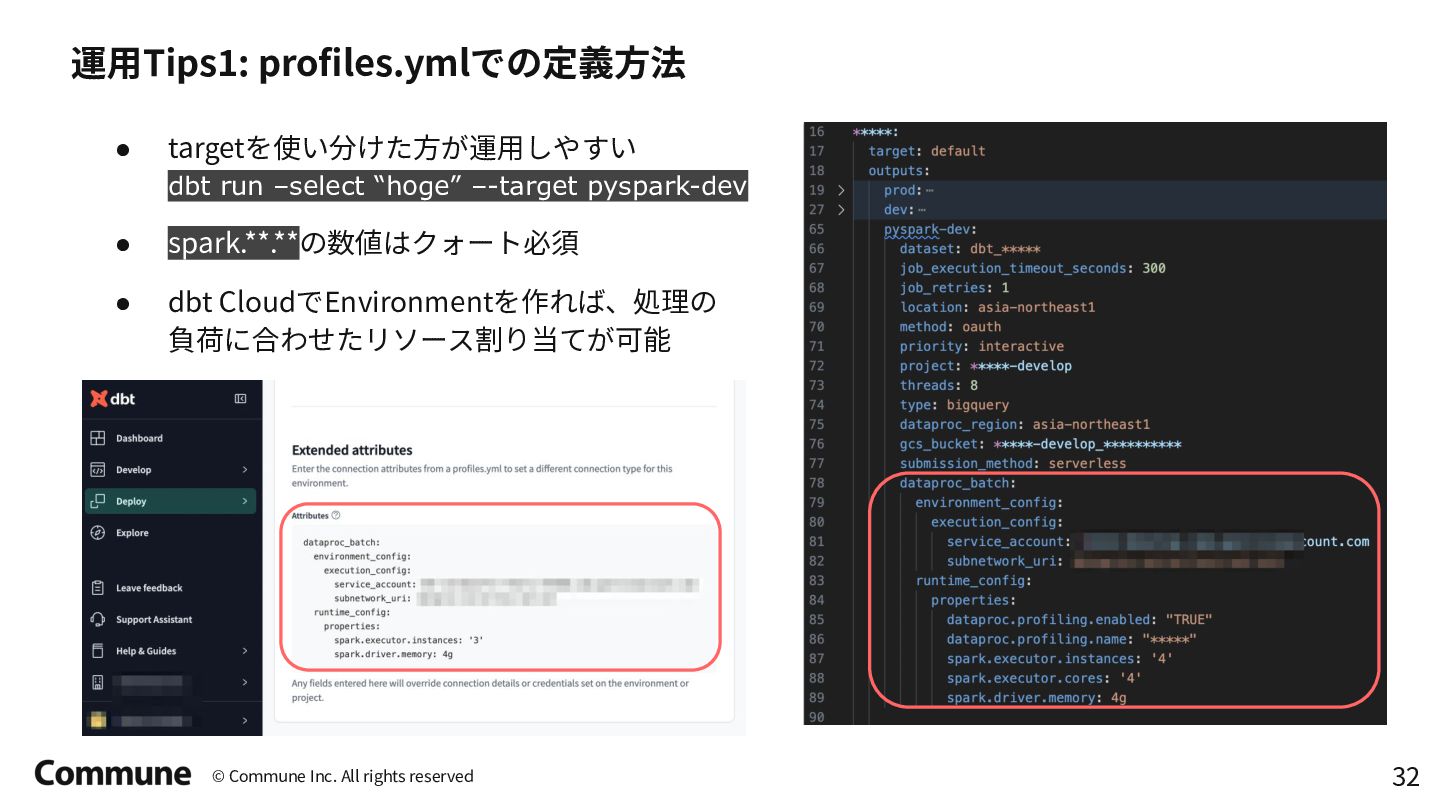{kind=link}
{kind=link}
{kind=link}
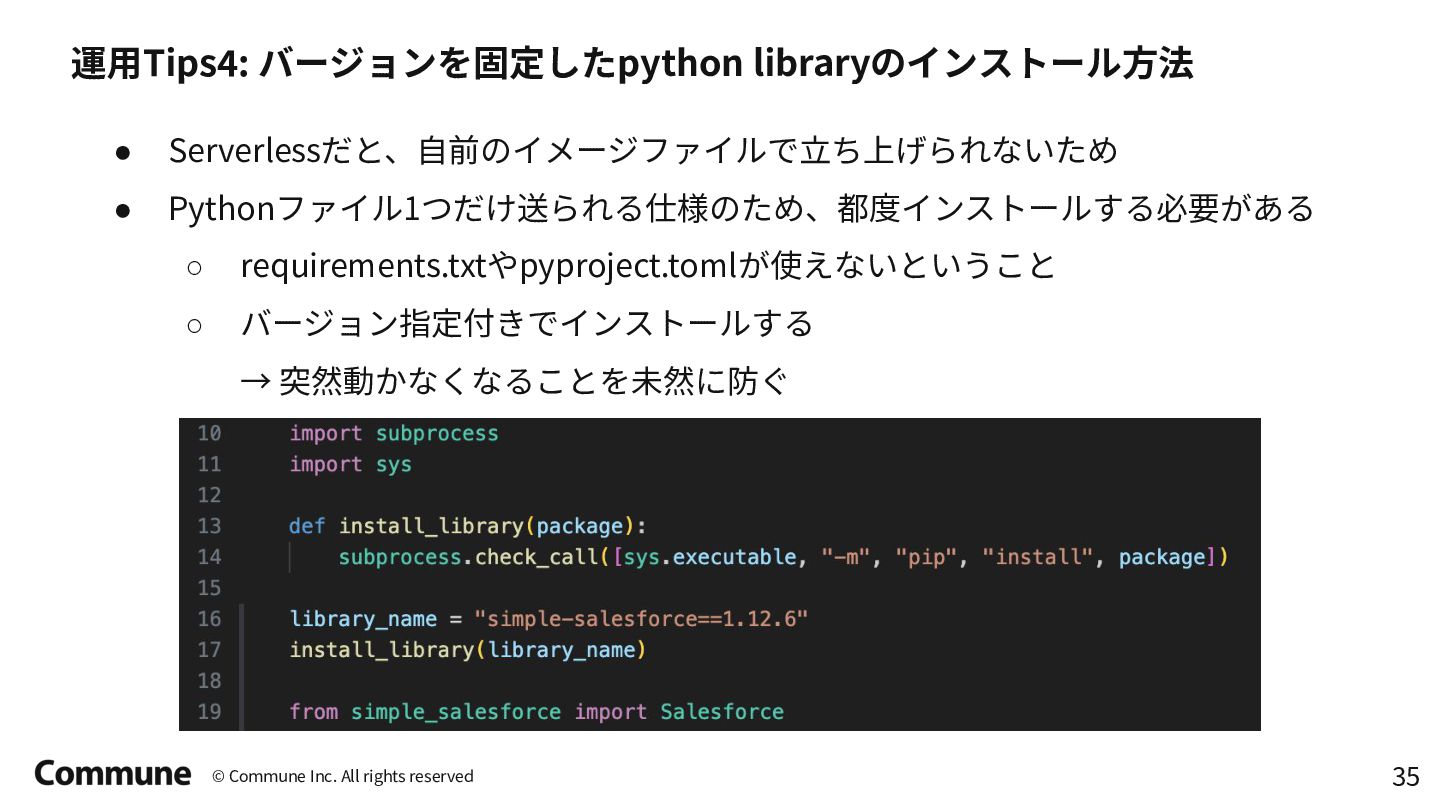{kind=link}
{kind=link}
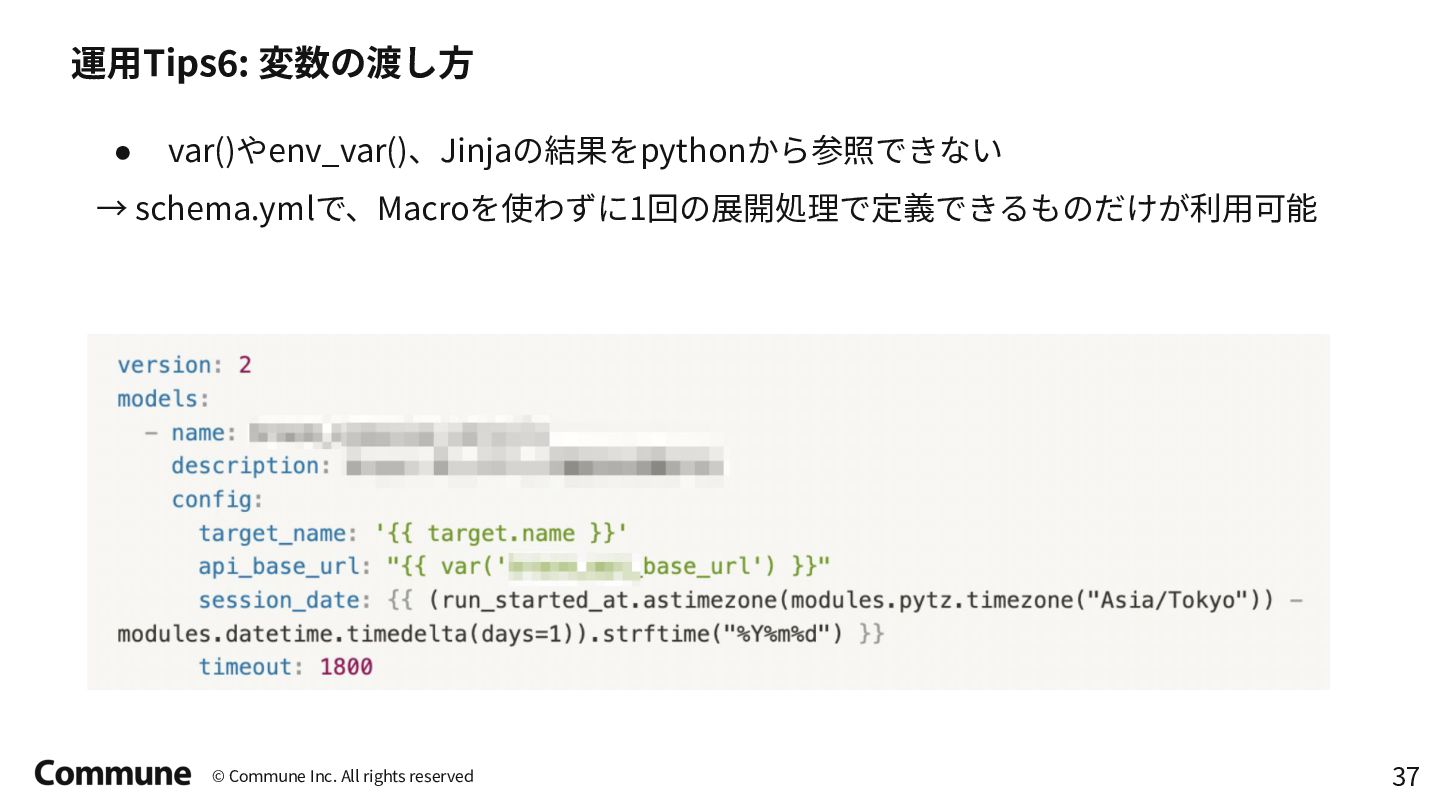{kind=link}
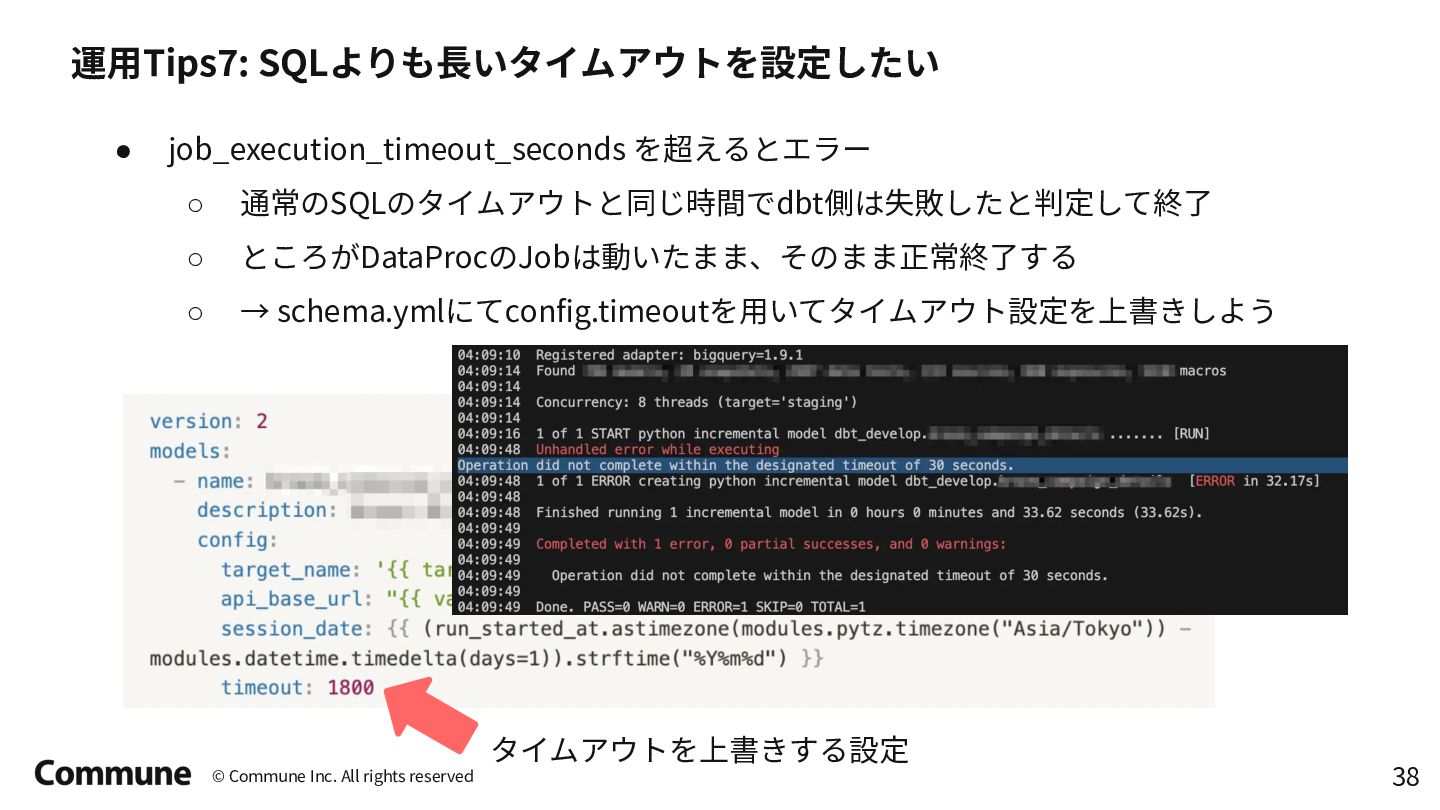{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
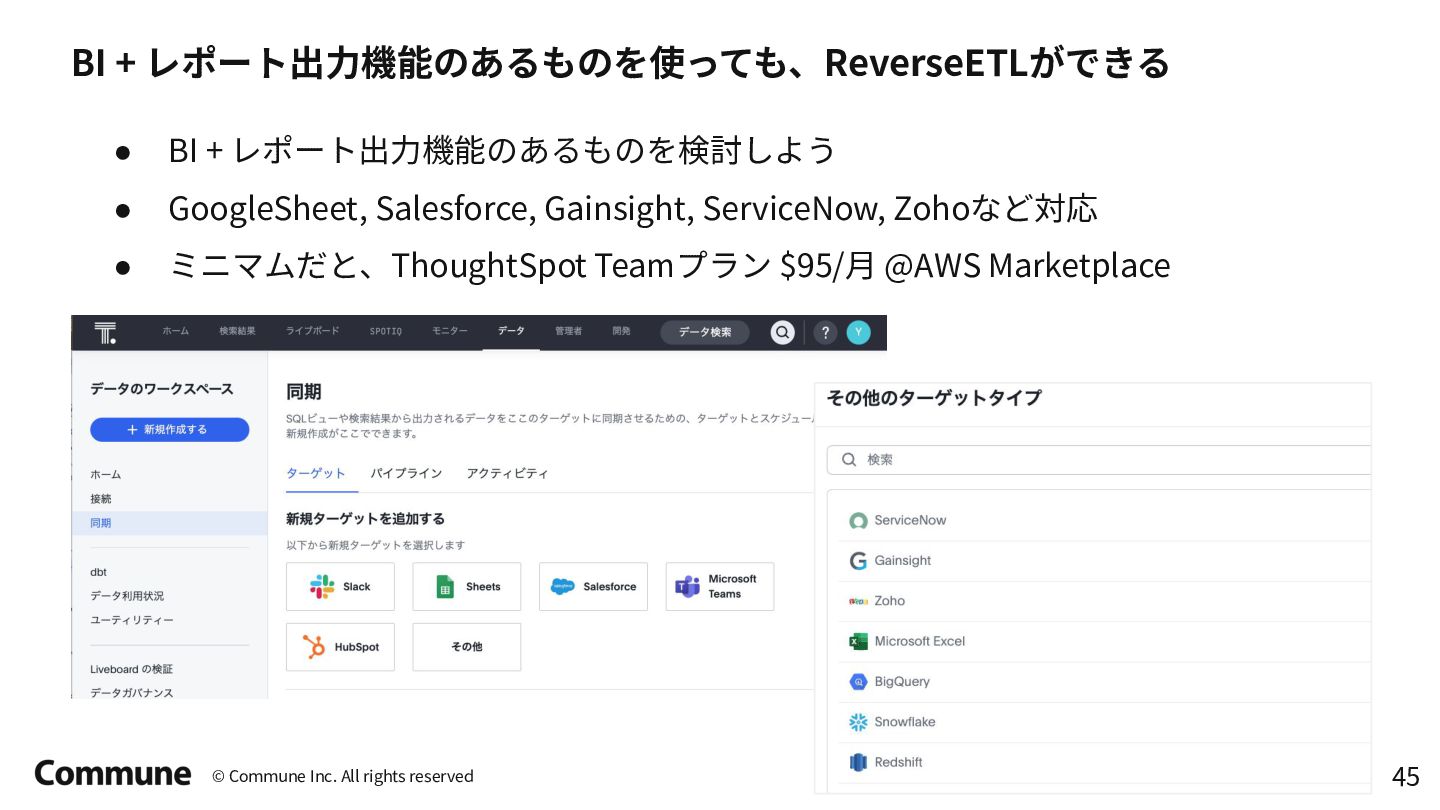{kind=link}
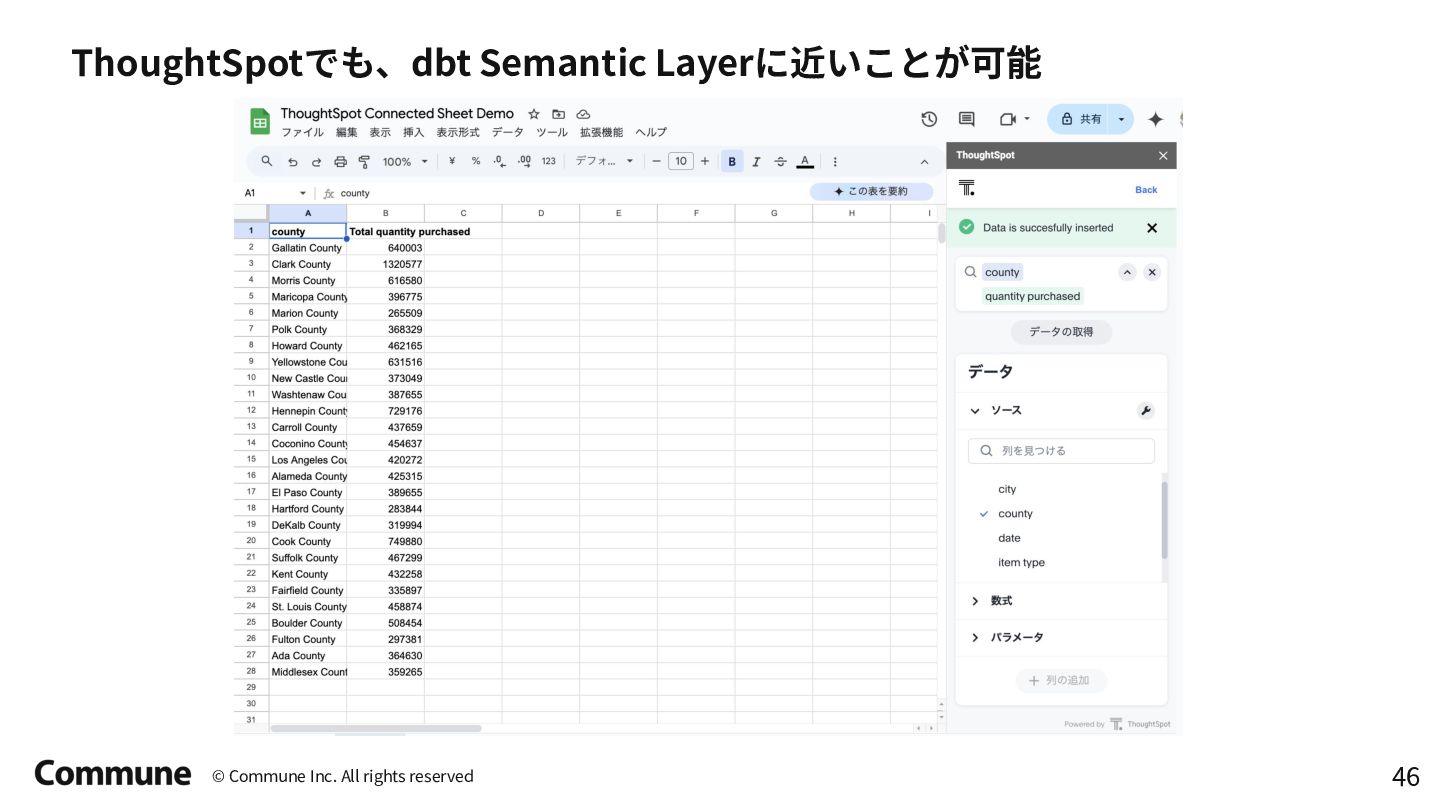{kind=link}
{kind=link}
{kind=link}
{kind=link}