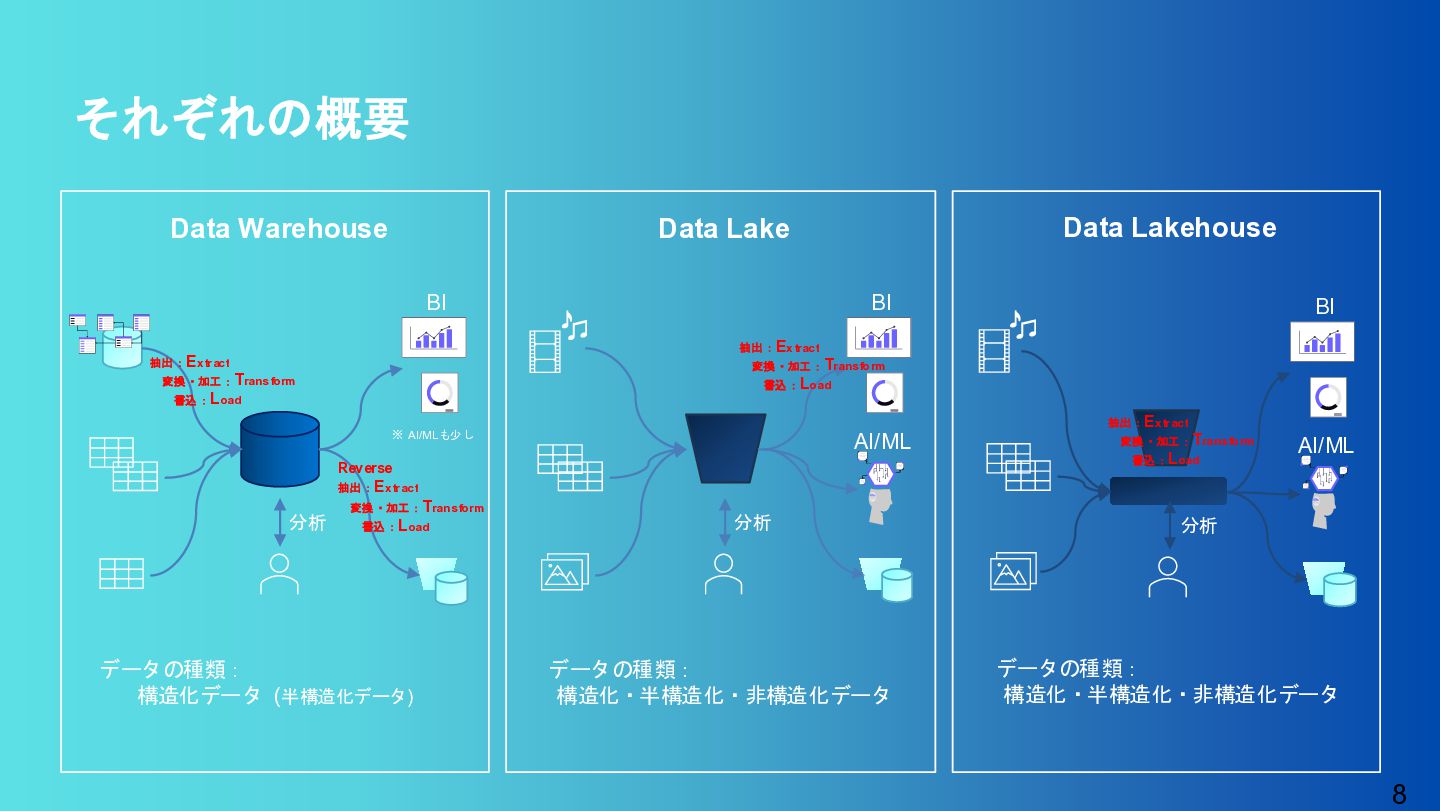
分析 ※ AI/MLも少し Data Warehouse データの種類: 構造化データ (半構造化データ) BI 分析 Data Lake データの種類: 構造化・半構造化・非構造化データ 抽出:Extract 変換・加工:Transform 書込:Load AI/ML 抽出:Extract 変換・加工:Transform 書込:Load BI AI/ML データの種類: 構造化・半構造化・非構造化データ Data Lakehouse 分析
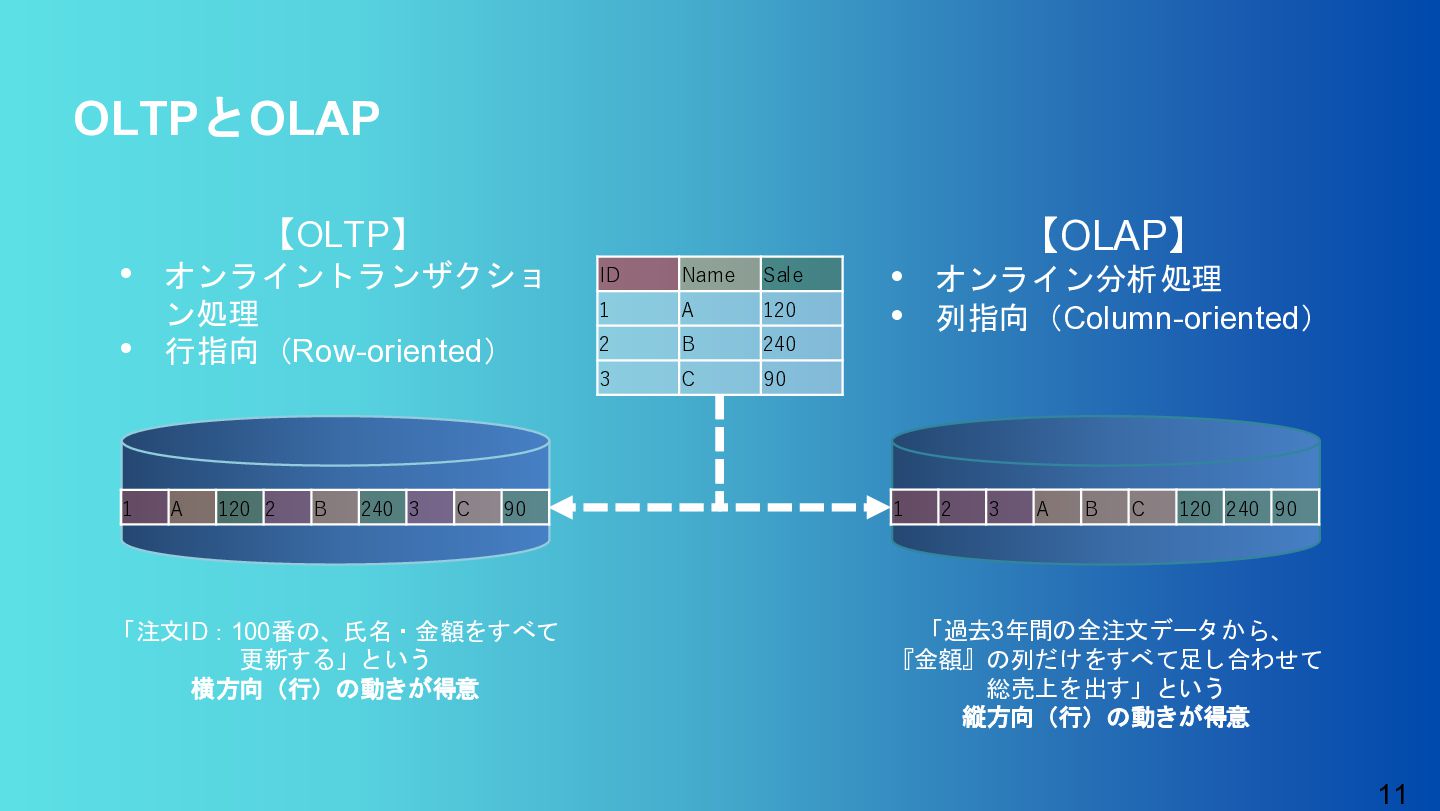
オンライン分析処理 • 列指向(Column-oriented) 「注文ID:100番の、氏名・金額をすべて 更新する」という 横方向(行)の動きが得意 1 A 120 2 B 240 3 C 90 ID Name Sale 1 A 120 2 B 240 3 C 90 1 2 3 A B C 120 240 90 「過去3年間の全注文データから、 『金額』の列だけをすべて足し合わせて 総売上を出す」という 縦方向(行)の動きが得意
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
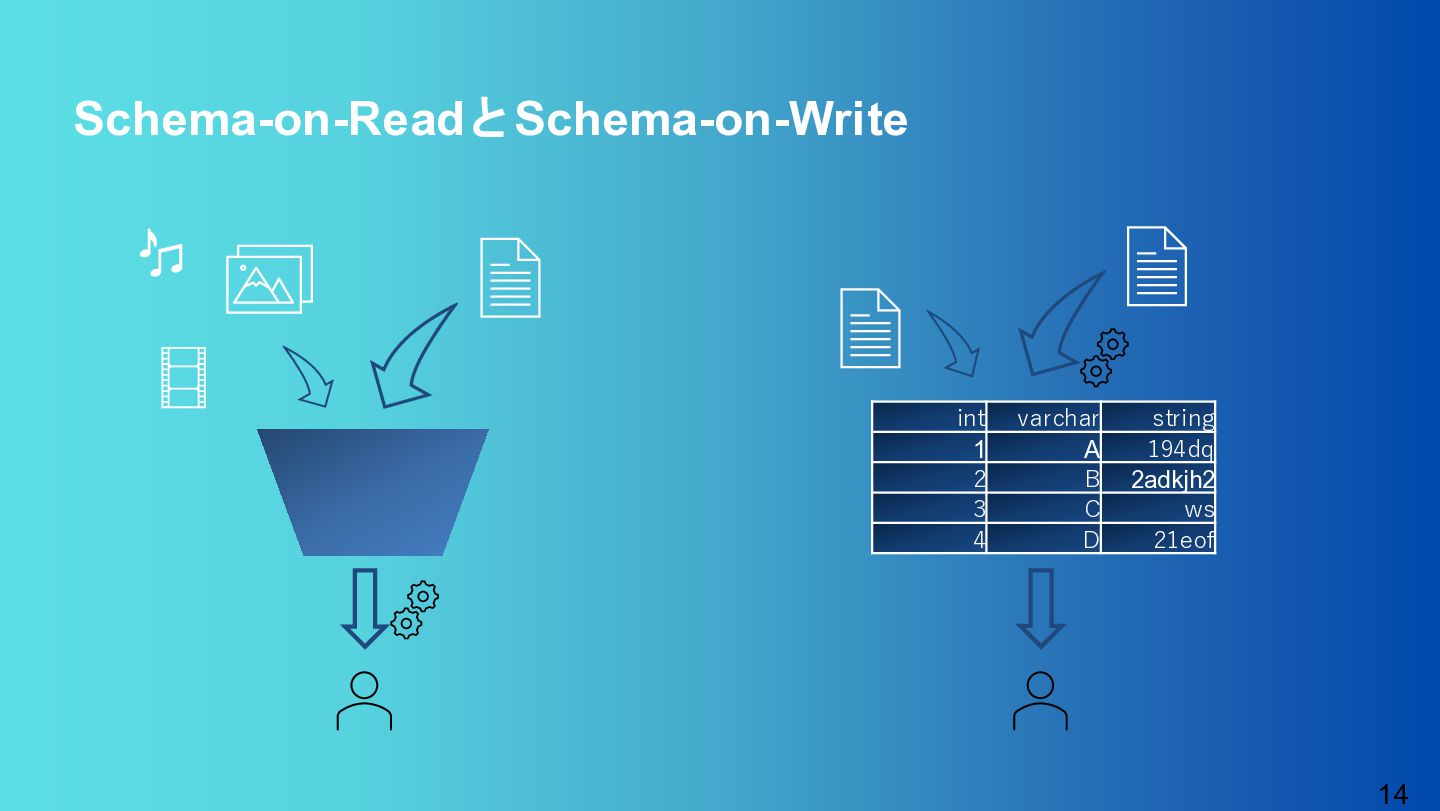{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
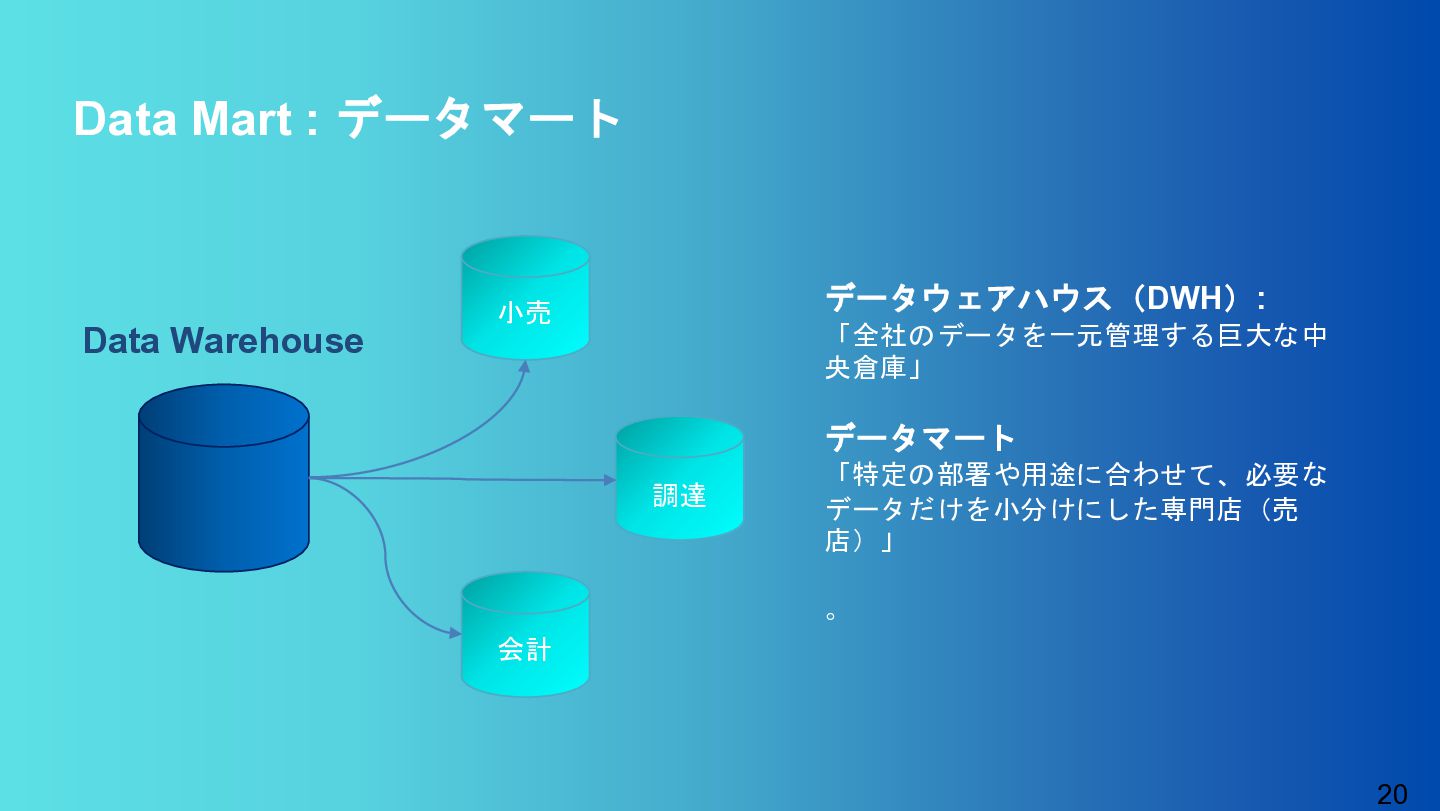{kind=link}
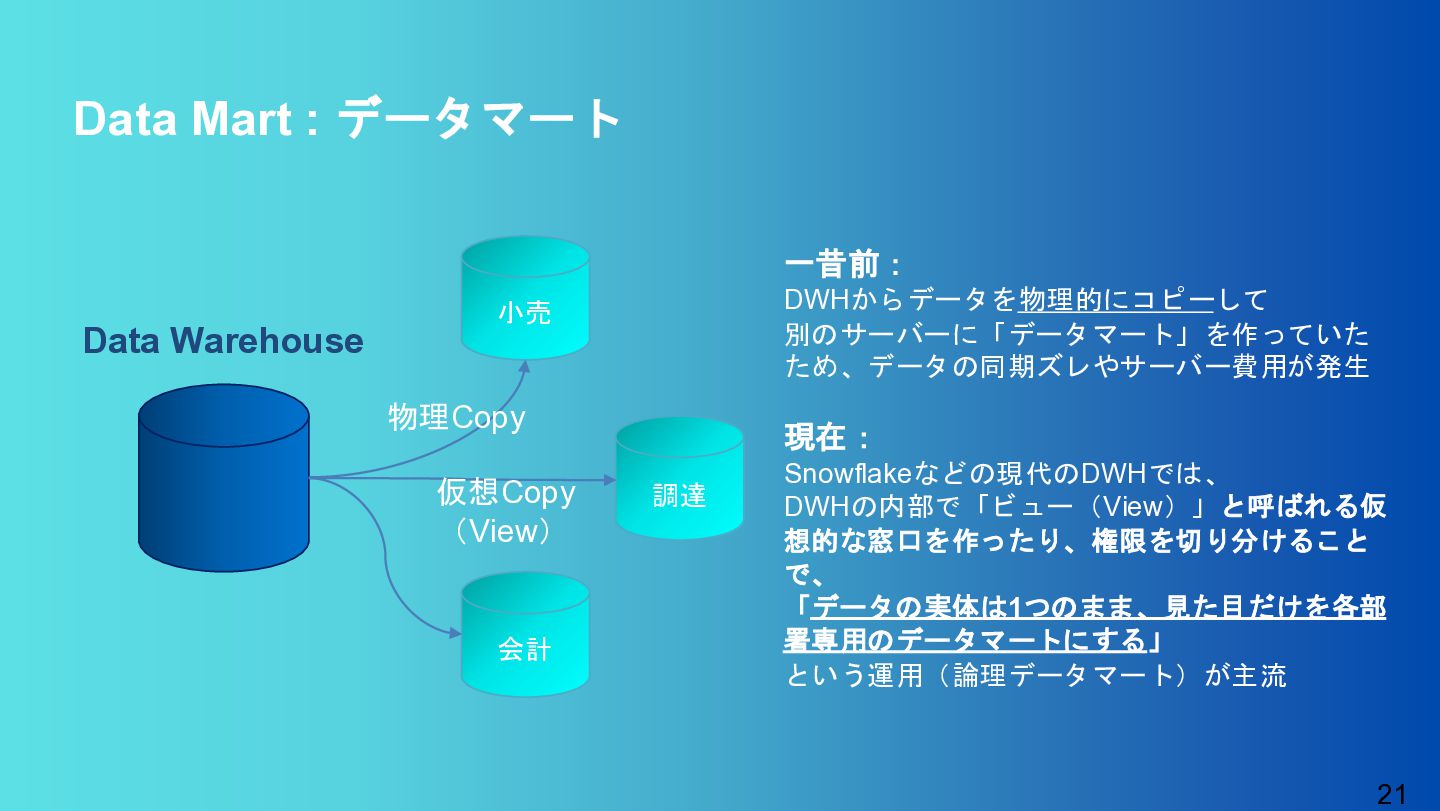{kind=link}
{kind=link}
{kind=link}
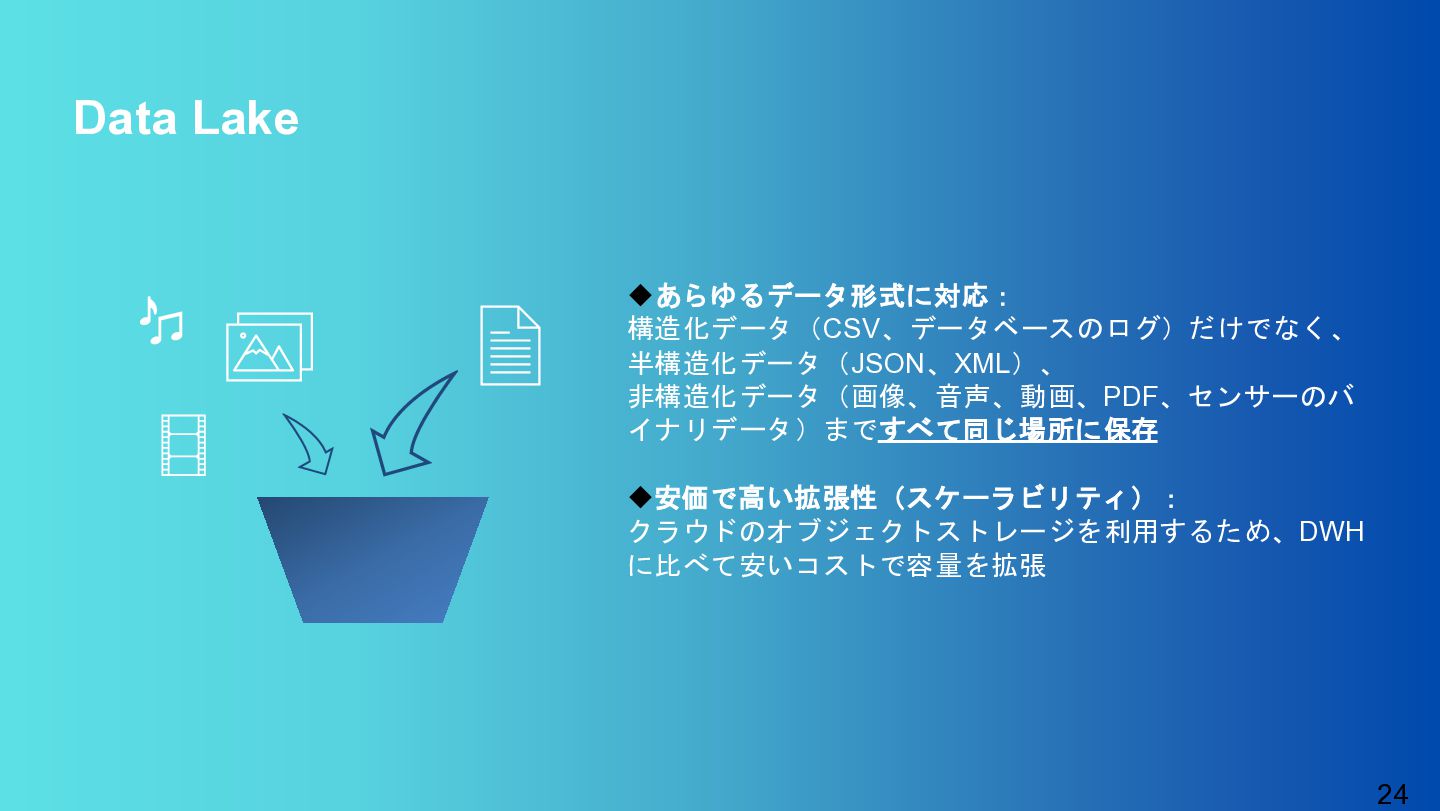{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
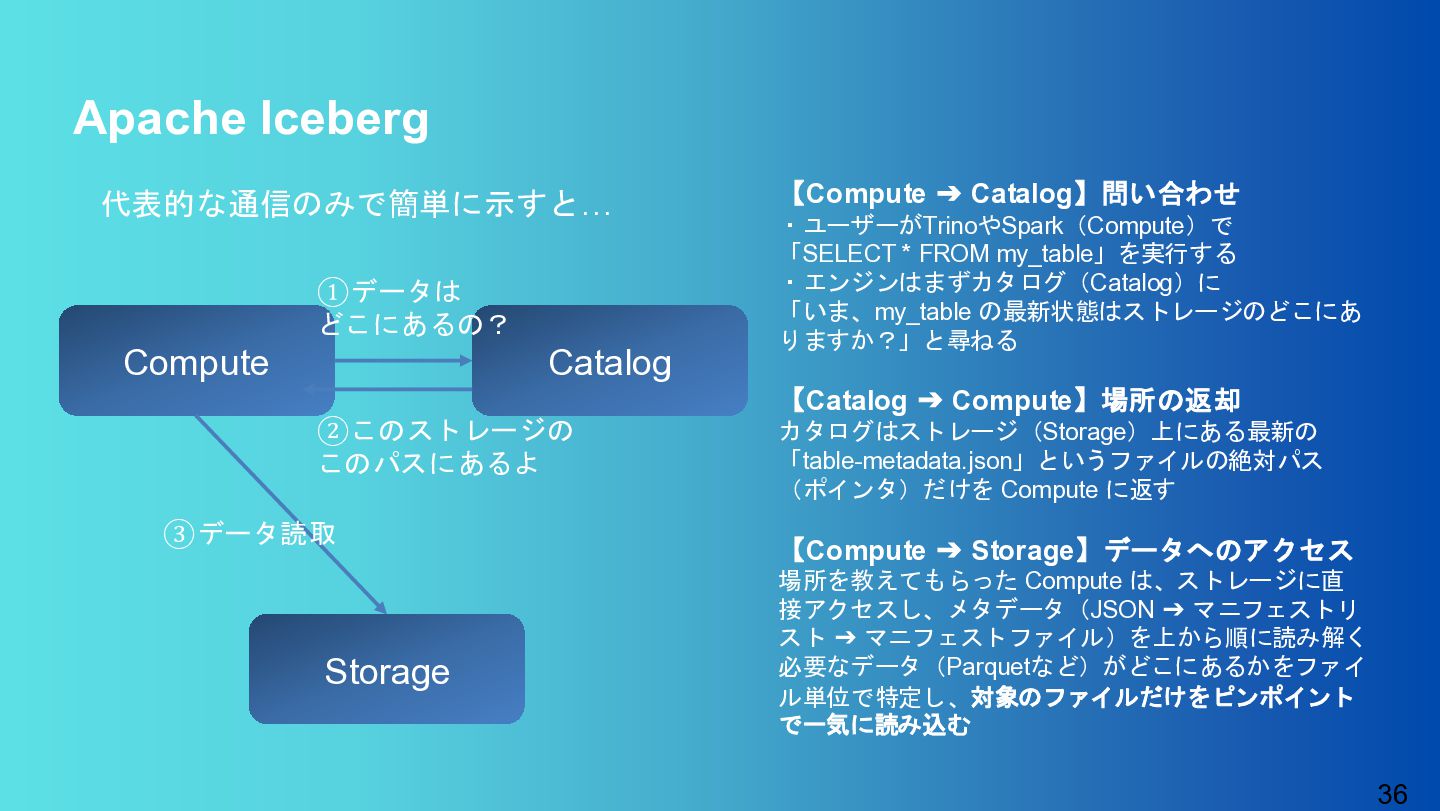{kind=link}
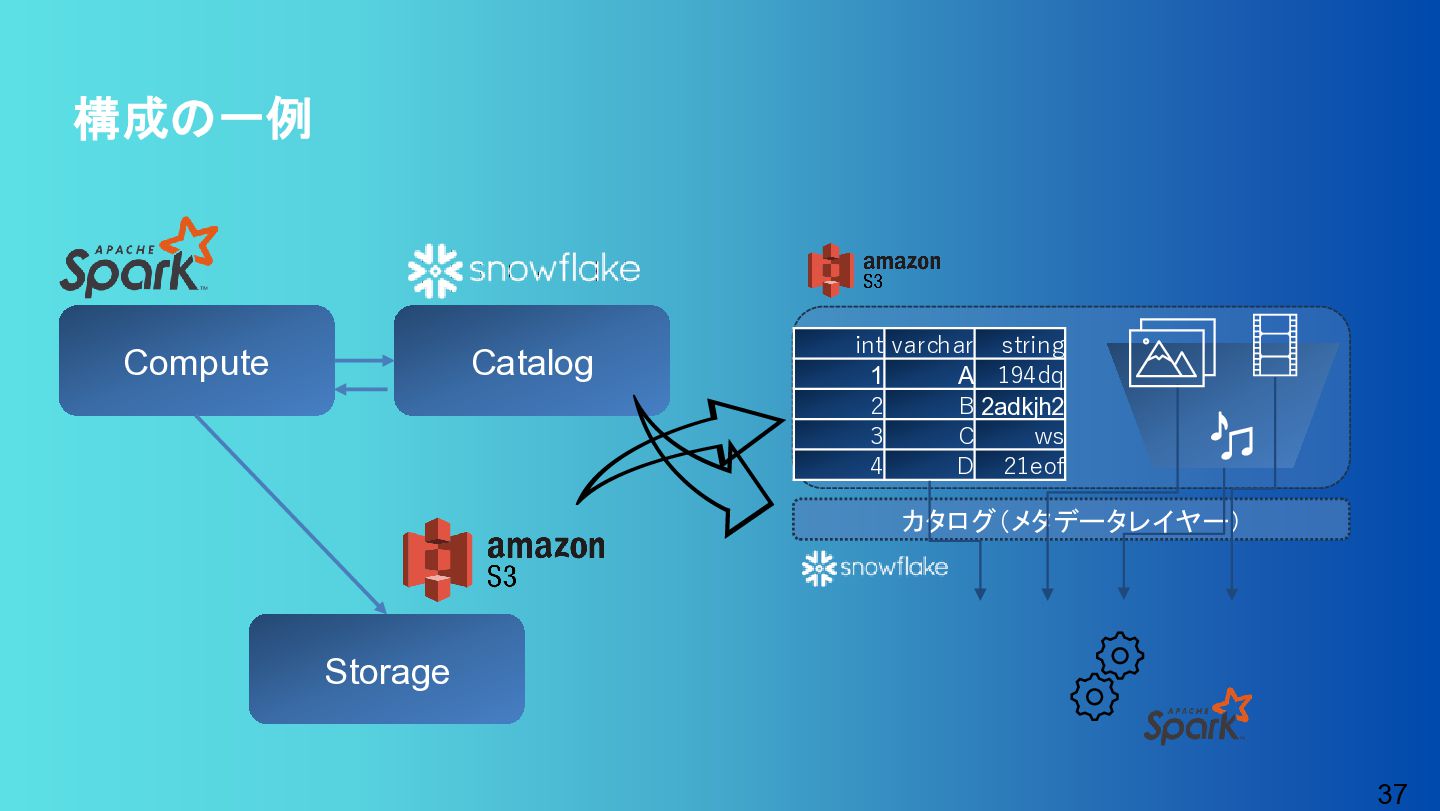{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}