such as load balancing, DNS, map reduce, and more... • New instances ready in seconds When to move to a datacenter? • Once you’re consistently hi ing issues beyond your control Thursday, April 25, 13
Well known and well liked • Rarely catastrophic loss of data • Response time to request rate increases linearly • Very good soware support - XtraBackup, Innotop, Maatkit • Solid active community • Free Thursday, April 25, 13
• Consistently good performance • Free • Variety of convenient and efficient data structures • Insert into queue in O(1) • 3 Flavors of Persistence: Now, Snapshot, Never • For HIGH write:read ratio, snapshot saves a lot I/O bandwidth • Snapshot increases reliability in noisy environments Thursday, April 25, 13
• Efficient storage • Can handle large write thoughput • Solid Hadoop interface • Maturing quickly, used heavily by Facebook • Built on HDFS • Free • When? Use it to optimize your already mature system Thursday, April 25, 13
Employee Growth • Major bugs and performance issues stall deploys • Performance issues creep in under radar • 7+ development teams, 1 ops team • Workload changing more rapidly and less predictably • Want developers to not fear moving fast Thursday, April 25, 13
Employee Growth • Major bugs and performance issues stall deploys • Performance issues creep in under radar • 7+ development teams, 1 ops team • Workload changing more rapidly and less predictably • Want developers to not fear moving fast Challenge: Maintain Fast Flexible Experimentation • Want to empower engineers and PMs to try new things Thursday, April 25, 13
(careful! don’t erase your DB!) • Rings of deployment • Canary, employees only, 5% of user base, etc. • Continuous deployment • Production integration tests Thursday, April 25, 13
code base and topology • When? 50 engineers or too many connections • Empower each team • Service architecture with metrics and alerts • Configurable deployment • Ability to add capacity • Convenient and consistent data storage and caching • Provide Reliable Business and Ops Data • Win: Protect your database from accidents (e.g., unit test dropping DB tables) Thursday, April 25, 13
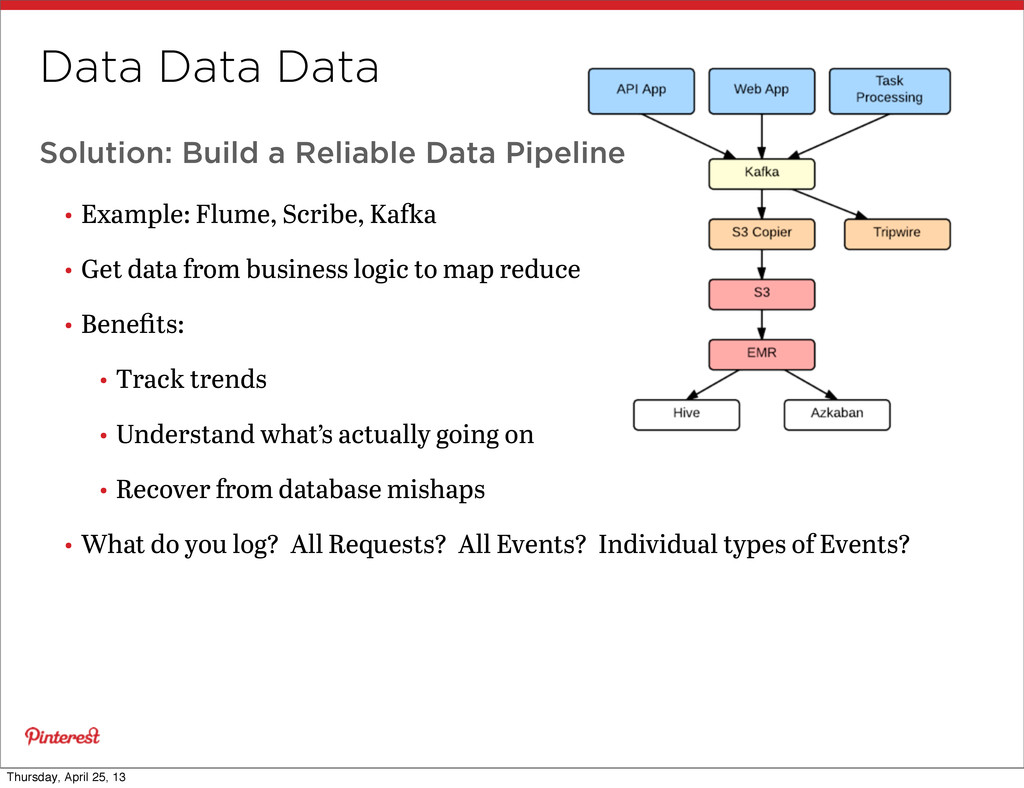
Example: Flume, Scribe, Kaa • Get data from business logic to map reduce • Benefits: • Track trends • Understand what’s actually going on • Recover from database mishaps • What do you log? All Requests? All Events? Individual types of Events? Thursday, April 25, 13
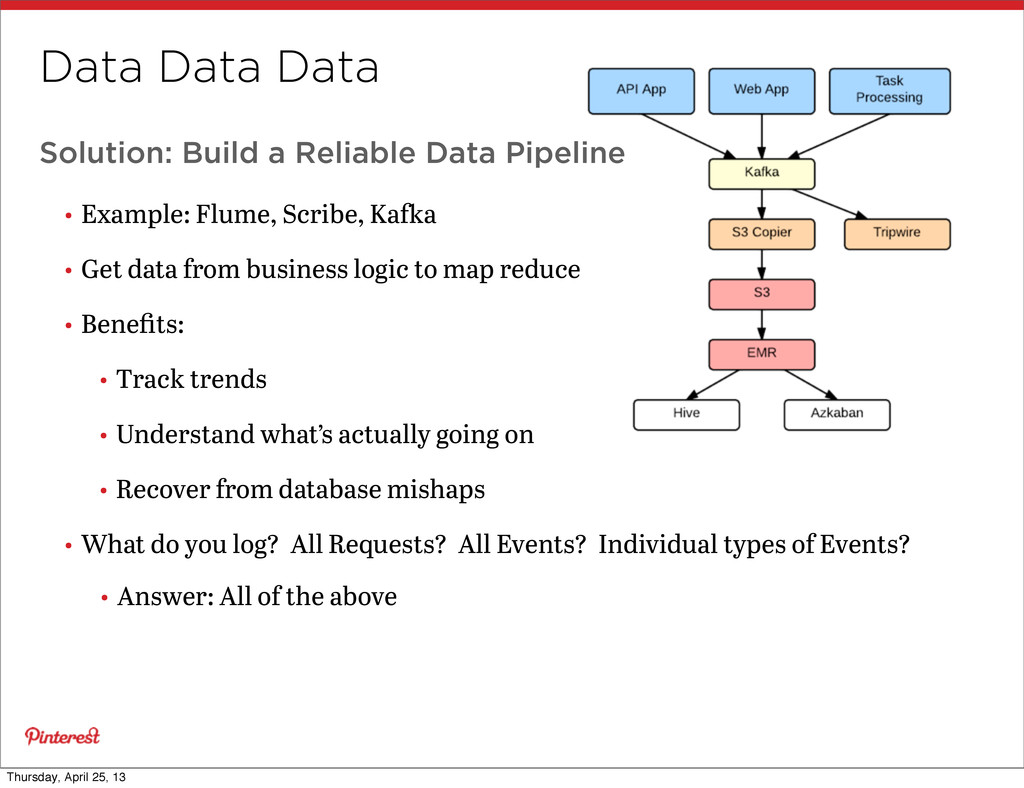
Example: Flume, Scribe, Kaa • Get data from business logic to map reduce • Benefits: • Track trends • Understand what’s actually going on • Recover from database mishaps • What do you log? All Requests? All Events? Individual types of Events? • Answer: All of the above Thursday, April 25, 13
Hijacking • Application Security • DDOS / Scraping • Spam • Each flavor has a different set of actors with unique motives and behavior Thursday, April 25, 13
are human • know your product and demographics as well as you do • know your defenses very well • are generally more tech savvy than your users • will grow with you • want to make money • If spammers are not making a good ROI, they’ll go away • Always communicate blocks as if the receiver is a good user Thursday, April 25, 13
for be er uptime and lower latency • Initially, most uptime and latency issues due to DB + caching • Fewer Instances => Few, but big failures • More Instances => More smaller failures + more complexity • How a gressively can you retry without hurting the system? Thursday, April 25, 13
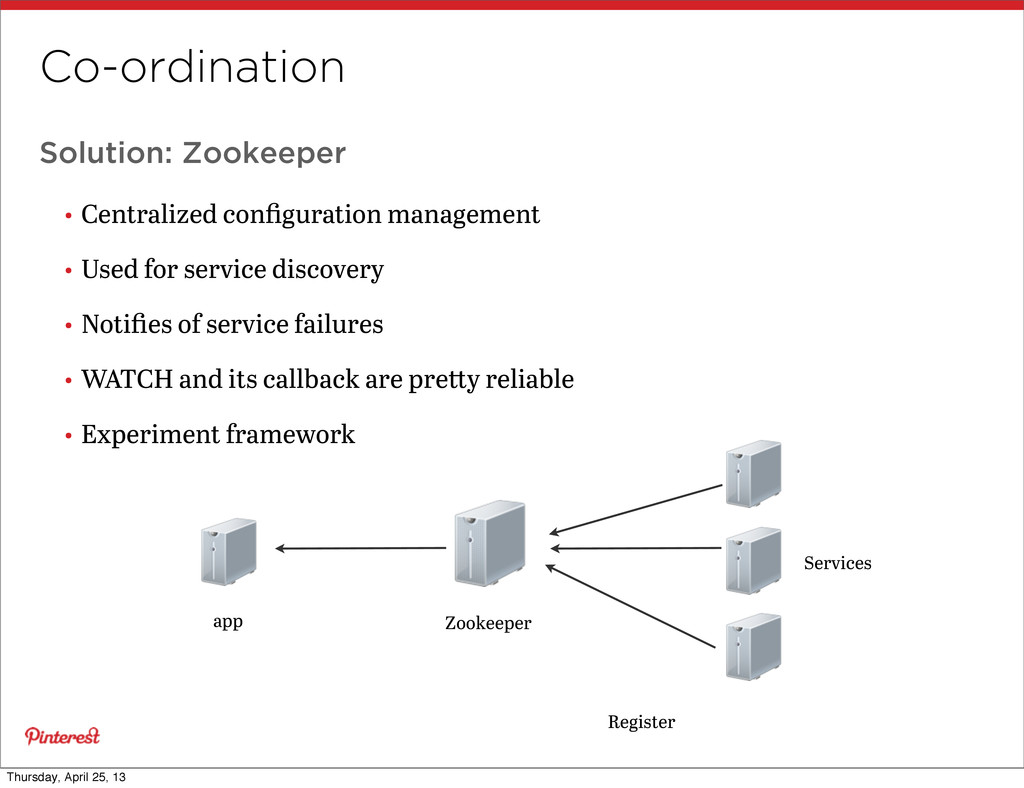
service discovery • Notifies of service failures • WATCH and its callback are pre y reliable • Experiment framework Zookeeper Services app Register Thursday, April 25, 13
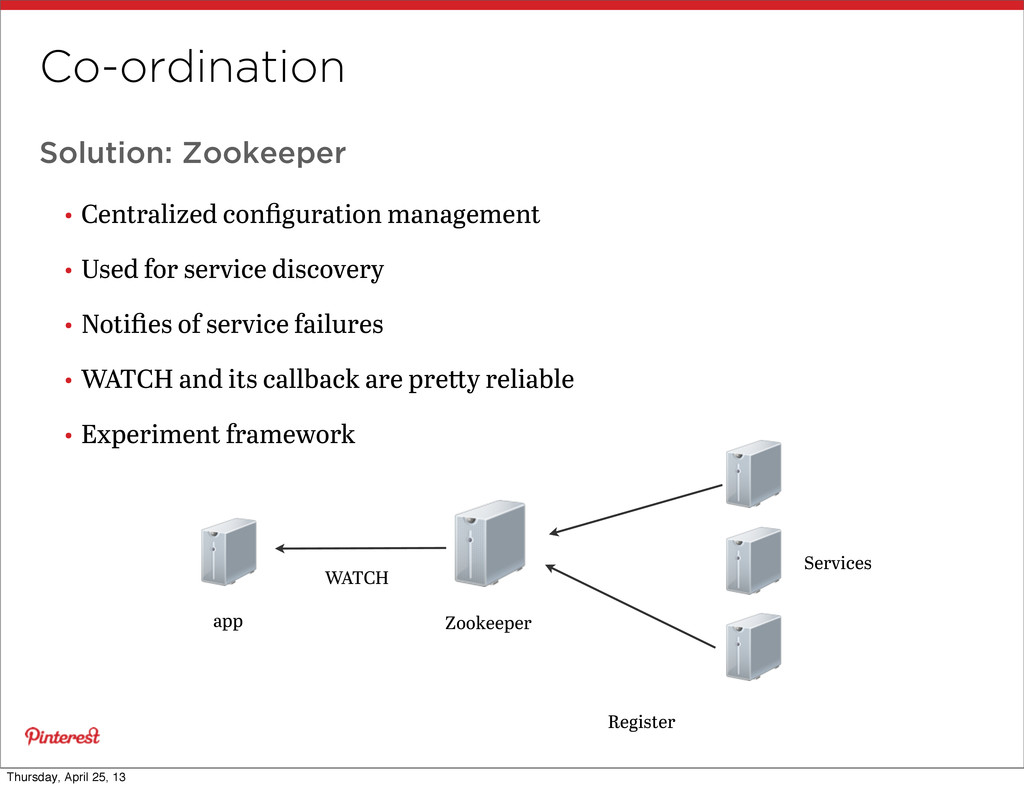
service discovery • Notifies of service failures • WATCH and its callback are pre y reliable • Experiment framework Zookeeper Services app Register WATCH Thursday, April 25, 13
Systems to auto- and re- configure your instances • Makes it easier to spin up more capacity or replacements • When to use? • Once you begin to have clear server instance segmentation • ~15+ instances • Earlier is be er -- you’ll want all your instances Puppet-ified Thursday, April 25, 13
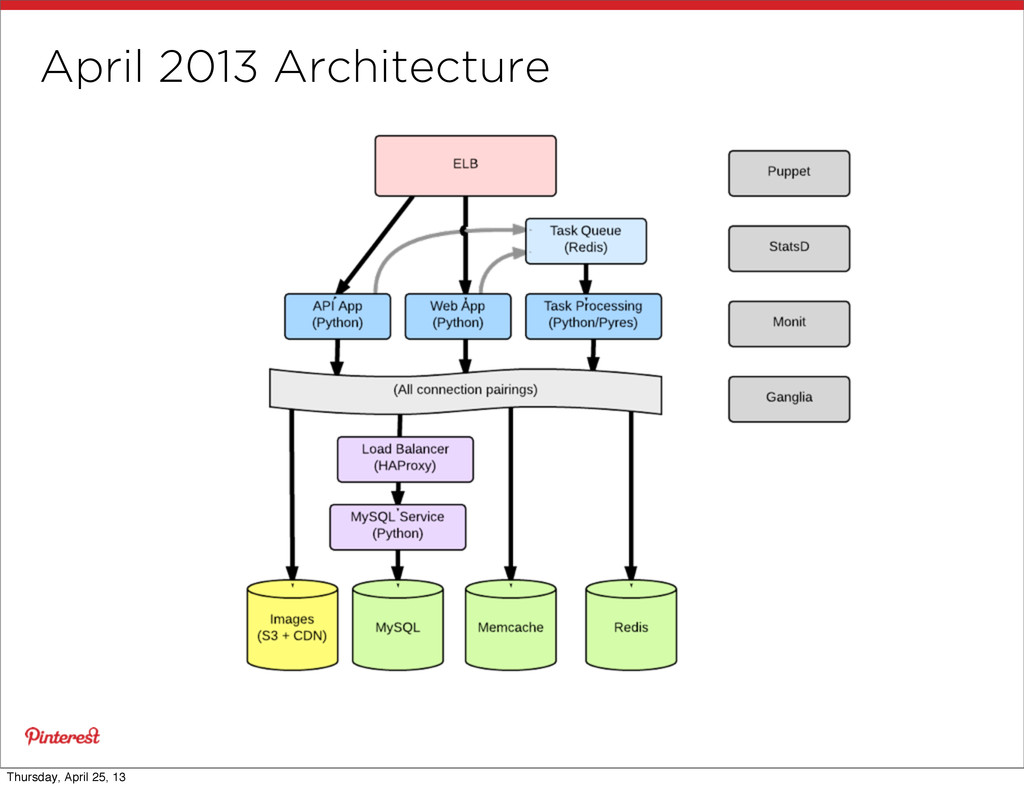
tier connected to all Memcache, Redis, MySQL • On Memcache... • 20k connections * 10kB / connection = 195MB / Memcache • 40 Memcaches means 7.6 GB used on connections • Connection space is not allocated from slab memory! • Can eventually cause Memcache process to leak into swap • On MySQL • At least 256 kB / connection Thursday, April 25, 13
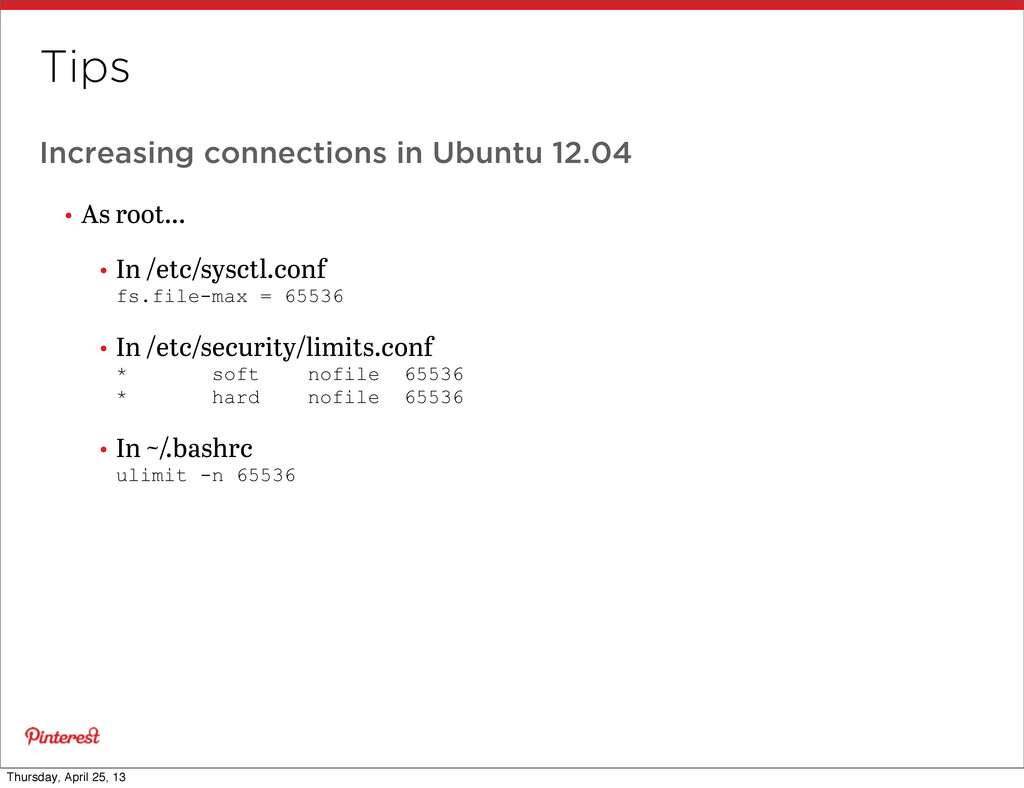
Max number of connections allowed is 10240 (weird...) • Exceeding max connections will make Redis CPU peg at 100% • On Ubuntu 12.04, default max connections is 1024 (!!) • (Go change to 65536 now) Thursday, April 25, 13
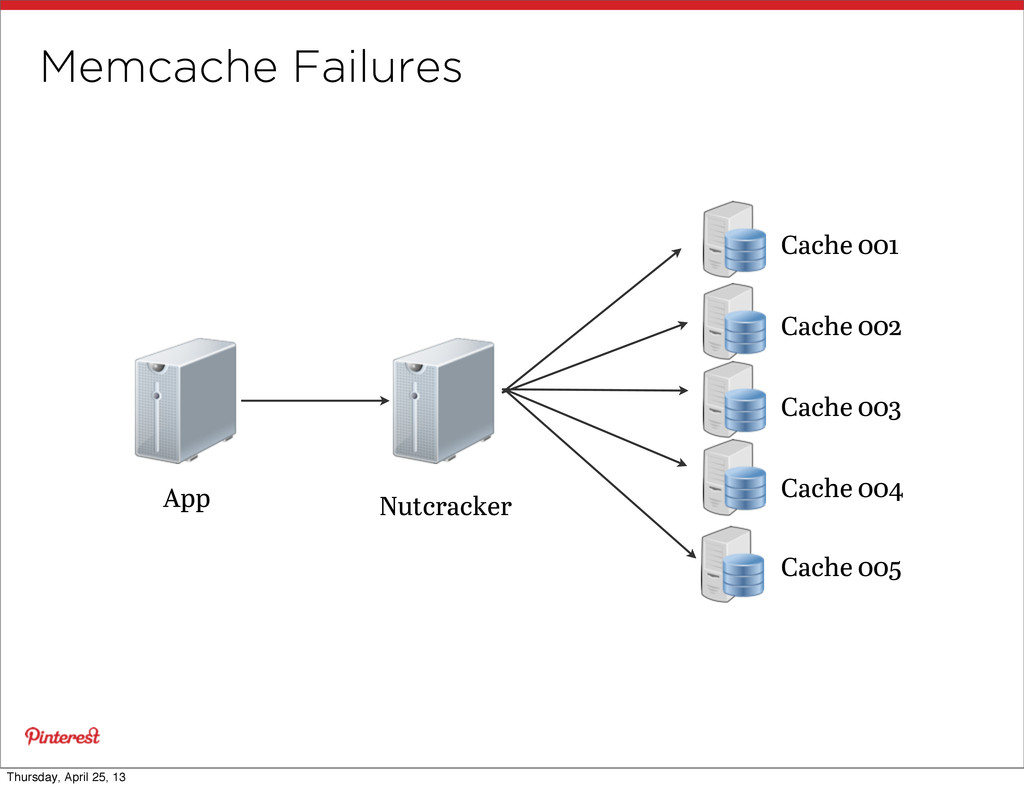
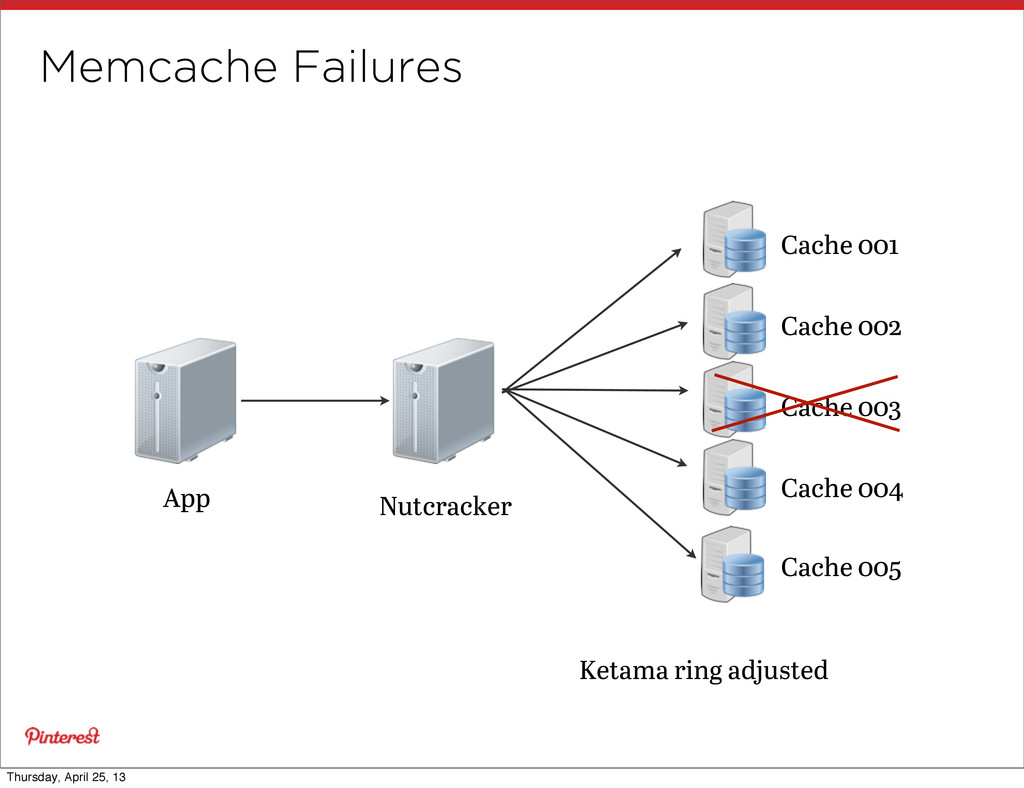
• When? Once any service gets close to 10k connections • Success: Memcache • Once was >20k connections • Now 1.3k connections • But, a gressive fan-out causes... • Network contention • Incast congestion Thursday, April 25, 13
• Twi er • Completely asynchronous • Previous experience with Finagle • Lots of compatible libraries • JVM • Lots of bells and whistles - Ostrich, Zipkin, lago Thursday, April 25, 13
• More a gressively push toward services maintained by teams • Growing beyond 130 Pinployees • Build products faster • MySQL 5.6 • Aer that? I don’t know... Thursday, April 25, 13
Redis process, potentially doubling RAM usage • If one Redis instance is using > 70% of RAM, you’re in danger • Redis is single threaded • Solution • Run 32 Redis instances on a single host (port 6379, 6380, ...) • Can move some of those instances to new host to add capacity • If you configure each instance with multiple databases, you can split even more times. • Utilizes more cores Thursday, April 25, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected] [email protected] Thursday, April 25, 13](https://files.speakerdeck.com/presentations/a681117090060130b23622000a1c4609/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}