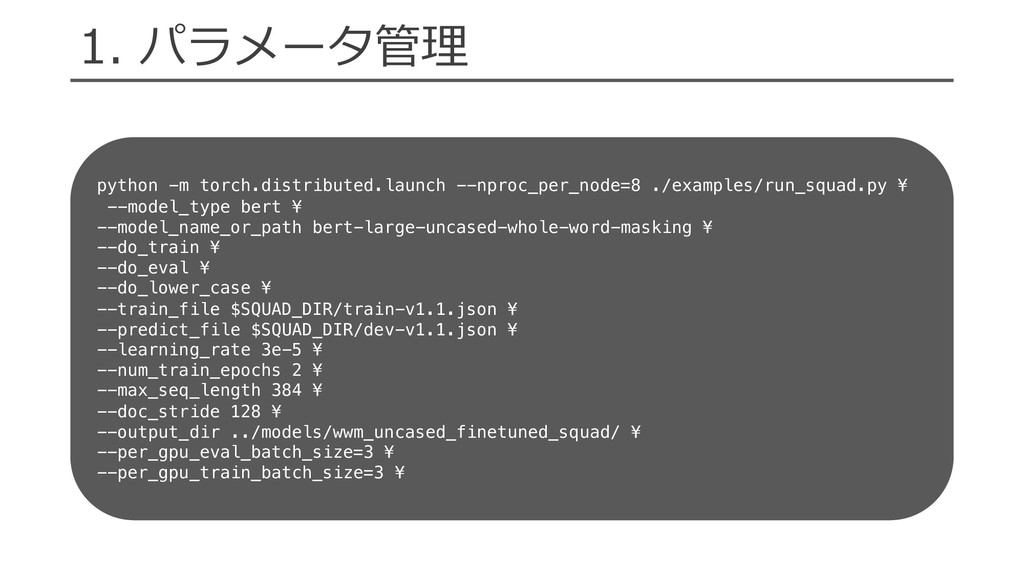
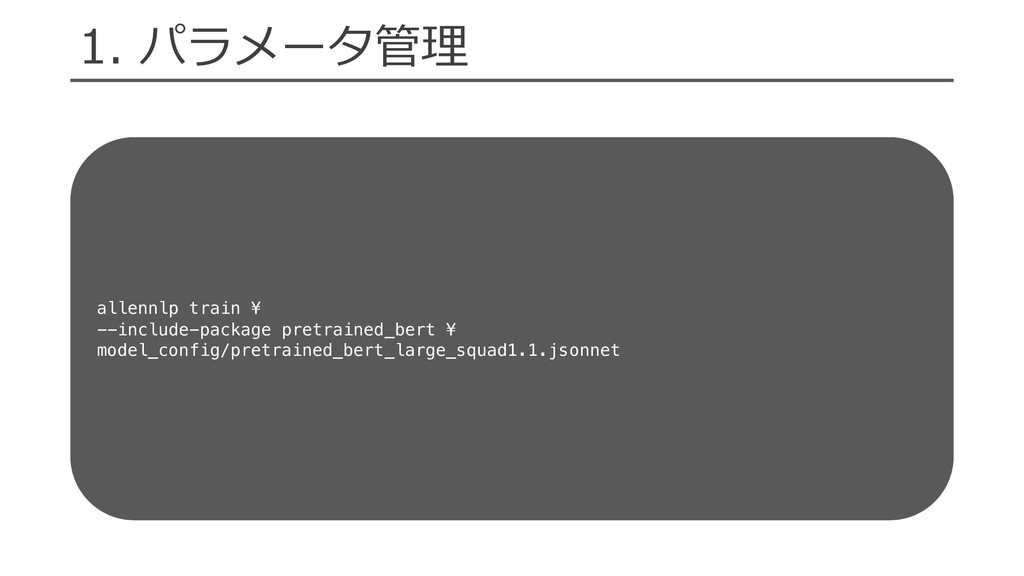
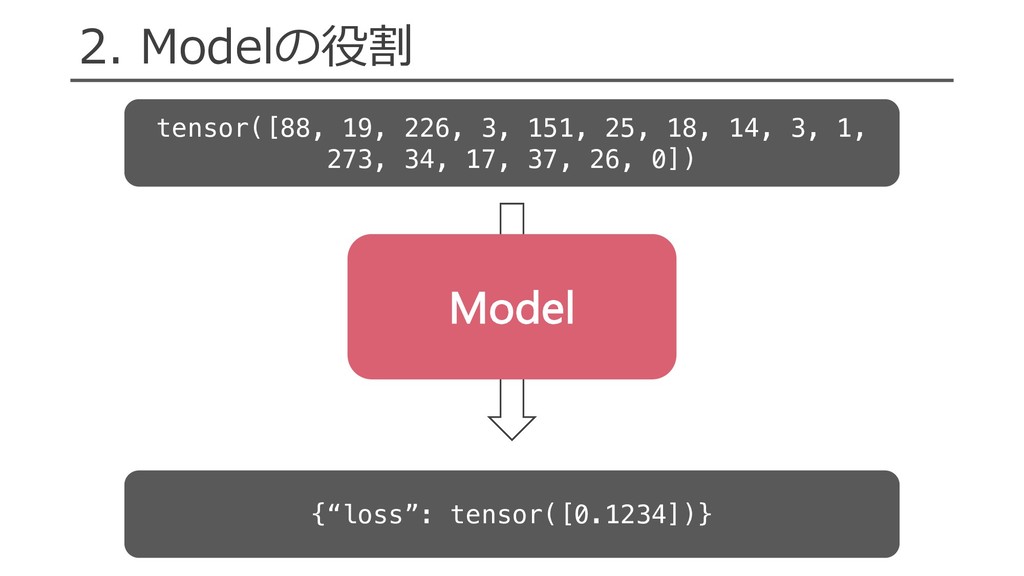
= get_text_field_mask(tokens).float() encoded_text = self._dropout( self._seq2vec_encoder(embedded_text, mask=mask) ) logits = self._classification_layer(encoded_text) probs = F.softmax(logits, dim=1) loss = self._loss(logits, label.long().view(-1)) return {“loss”: loss} • ⼊⼒からロスを計算 • dict形式で値を返却
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}