Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWS Data Pipeline VS AWS Glue : 어떻게 다를까요?
Search
yjsong
November 08, 2021
Programming
2.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWS Data Pipeline VS AWS Glue : 어떻게 다를까요?
yjsong
November 08, 2021
More Decks by yjsong
See All by yjsong
210727
yjsong
0
960
Other Decks in Programming
See All in Programming
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
270
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1k
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
15
2.9k
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.7k
Mujeres en SEO Summit 2026 - Greatest Disaster Hits en Web Performance
guaca
0
240
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
380
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
120
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
2.5k
Performance Engineering for Everyone
elenatanasoiu
0
260
Contextとはなにか
chiroruxx
1
390
symfony/aiとlaravel/boost
77web
0
120
Featured
See All Featured
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
560
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
KATA
mclloyd
PRO
35
15k
We Are The Robots
honzajavorek
0
270
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Transcript
AWS Data Pipeline VS AWS Glue 어떻게 다를까요? 송영진
발표자 소개 • 신입엔지니어, Classmethod(2020/04) • AWS를 이용한 데이터 분석,
기계학습에 관심
오늘의 이야기 • 다룰 내용 • ETL에 관한 이야기 •
AWS Data Pipeline과 AWS Glue의 개념과 특징 • 예시 아키텍처 • 다루지 않는 내용 • 데이터 분석에 대한 자세한 이야기 • 실제 코드 • 모든 기능의 설명
목차 • 배경지식 • AWS Data Pipeline이란? • AWS Glue란?
• 요약
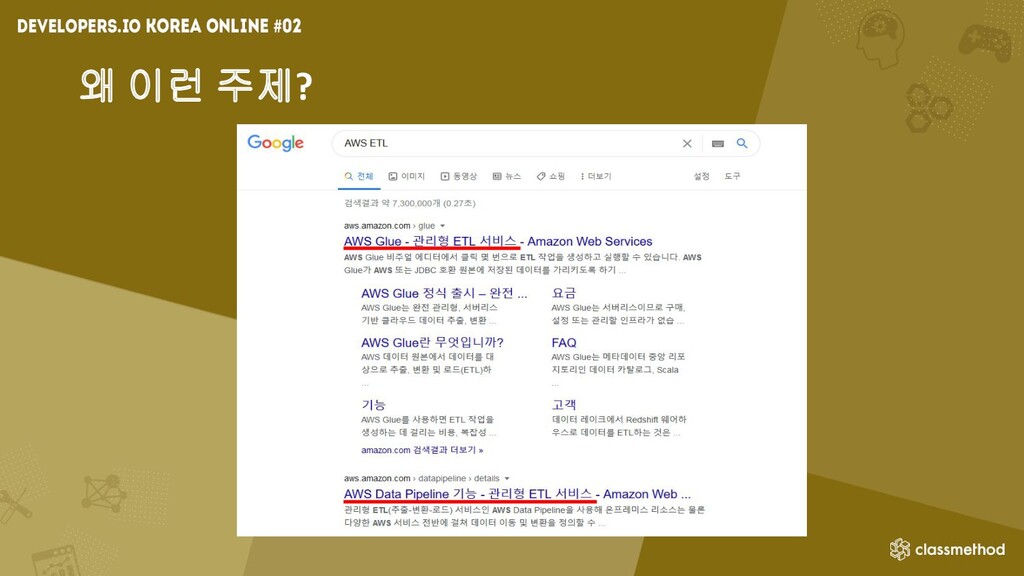
왜 이런 주제?
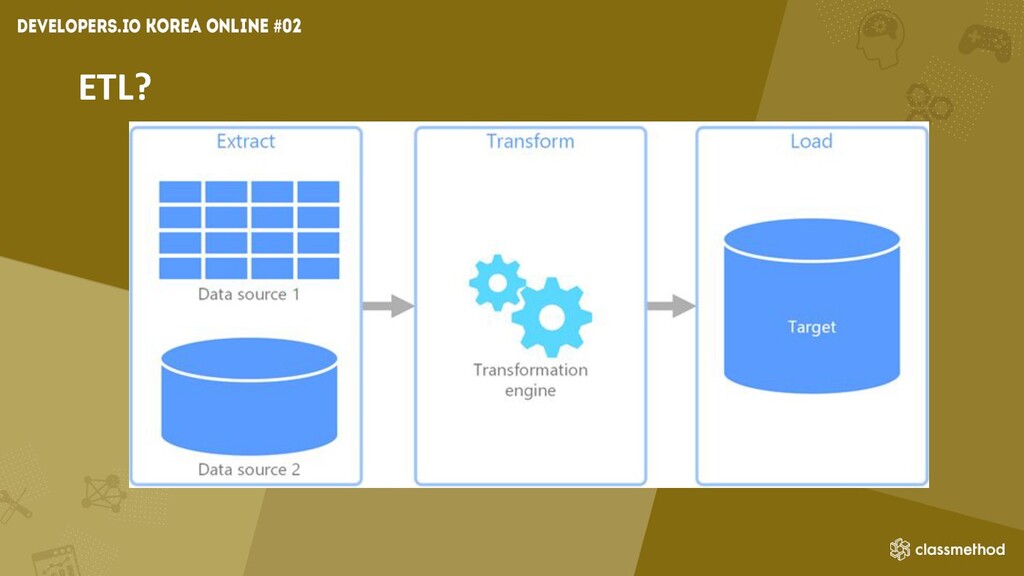
ETL?
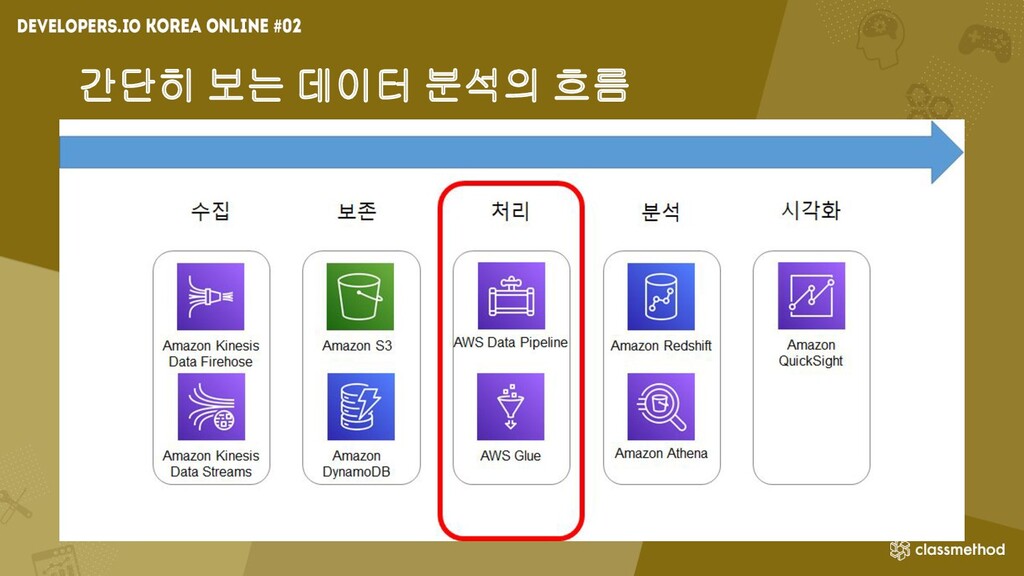
간단히 보는 데이터 분석의 흐름 •
ETL 난잡한 원시데이터에서 데이터 분석이 원활하게 할 수 있도록 분석하기
쉬운 데이터로 추출, 변환 시켜서 불러오는 작업
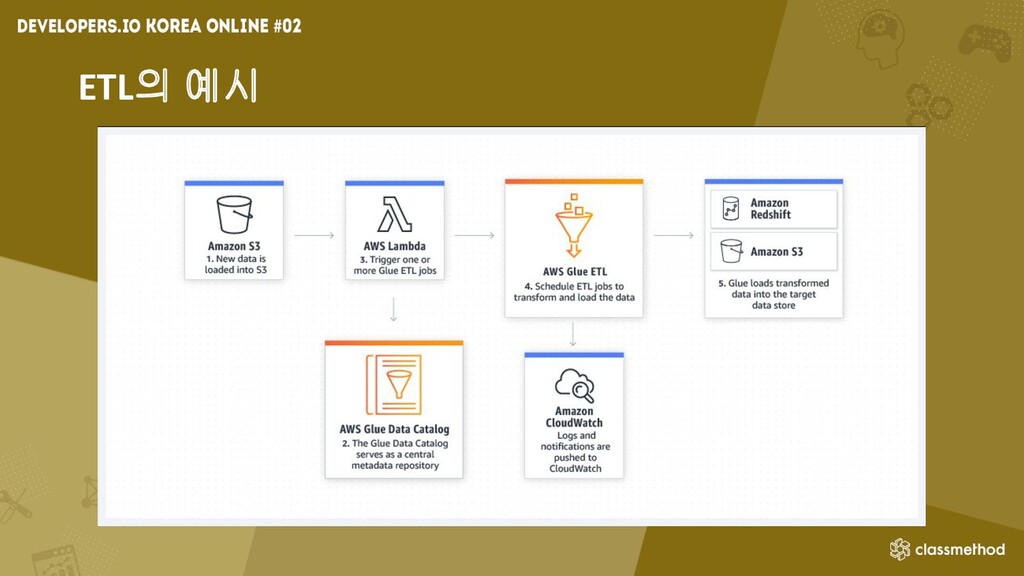
ETL 예시
그래서 같은 ETL 서비스인데 어떻게 다른가요?
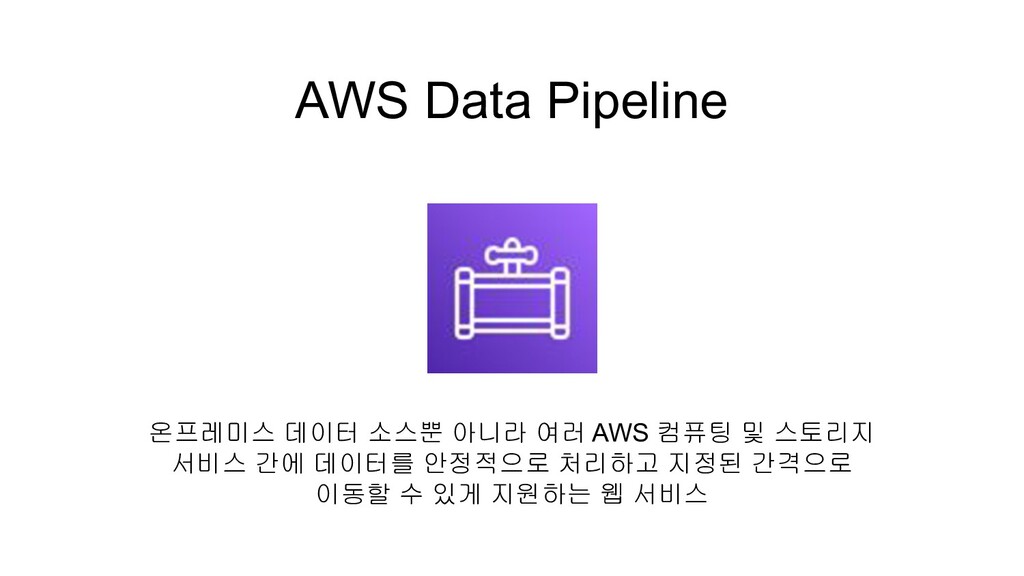
AWS Data Pipeline 온프레미스 데이터 소스뿐 아니라 여러 AWS 컴퓨팅
및 스토리지 서비스 간에 데이터를 안정적으로 처리하고 지정된 간격으로 이동할 수 있게 지원하는 웹 서비스
Data Pipeline의 포인트 • AWS의 관리 서비스 • EC2 인스턴스
위에서 실행 • 노드 사이에서 데이터 마이그레이션 및 ETL 작업 수행 • 스케쥴러 기능(시간지정 및 사이클링 의존성 지정 등) • 온프레미스에서 AWS로 데이터 이동 가능
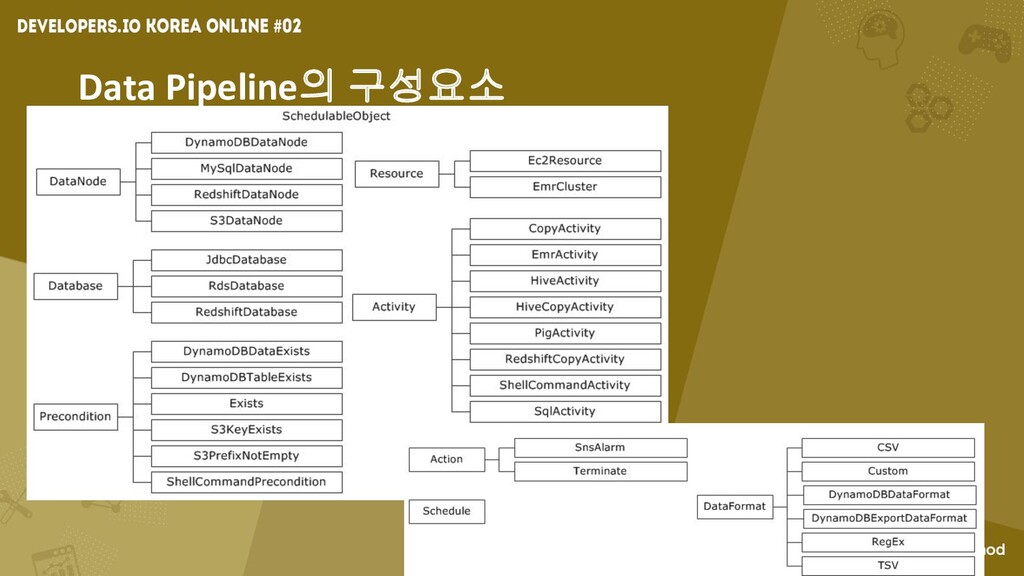
Data Pipeline의 구성요소
AWS의 관리 서비스 • 어려운 작업은 아니지만 직접 만들려면 귀찮음
• 작업을 수행하기 위한 환경 • 컴퓨팅 리소스 • 소프트웨어 • 스케쥴러(시계열 방식, 크론 방식) • 관리 및 유지보수
데이터 마이그레이션 및 ETL • 개발용 GUI 지원 • 대표적인
모델 템플릿 지원 • 자신이 사용하던 코드로 실행 시킬 수 있음 • EC2 인스턴스 또는 EMR 클러스터 위에서 수행됨 • 실패한 작업 자동으로 재실행
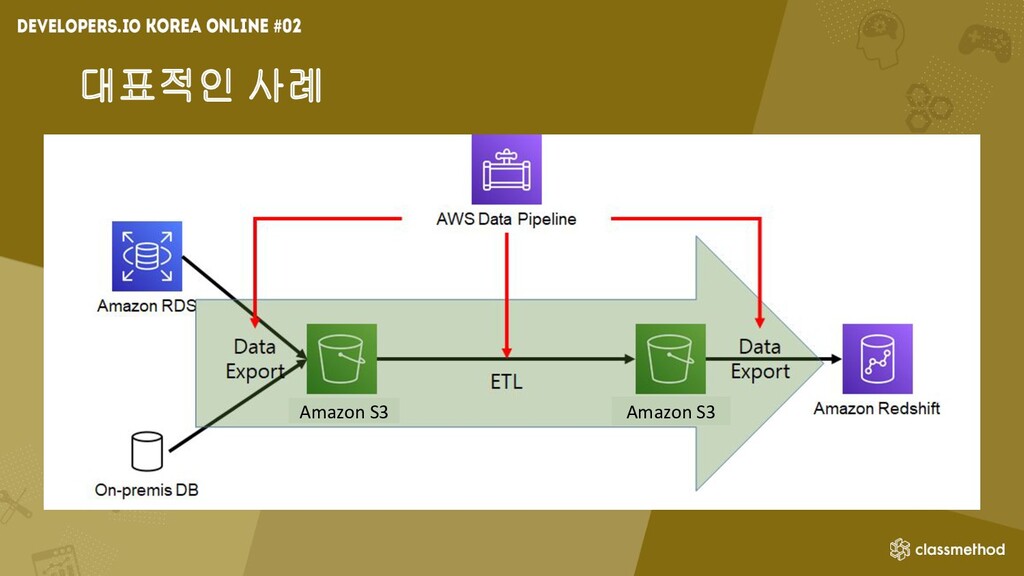
대표적인 사례 Amazon S3 Amazon S3
AWS Glue 완전 관리형 ETL 서비스로, 효율적인 비용으로 간단하게 여러
데이터 스토어 및 데이터 스트림 간에 원하는 데이터를 분류, 정리, 보강, 이동할 수 있게 지원하는 웹 서비스
Glue의 핵심 기능 • 테이블 • 데이터 카탈로그 • 데이터의
스키마 정보(칼럼, 데이터 형식)를 저장 • DB마다 관리 • 작업 • ETL처리의 실행기반 • 3종류 선택가능(Python Shell, Spark, Spark Streaming)
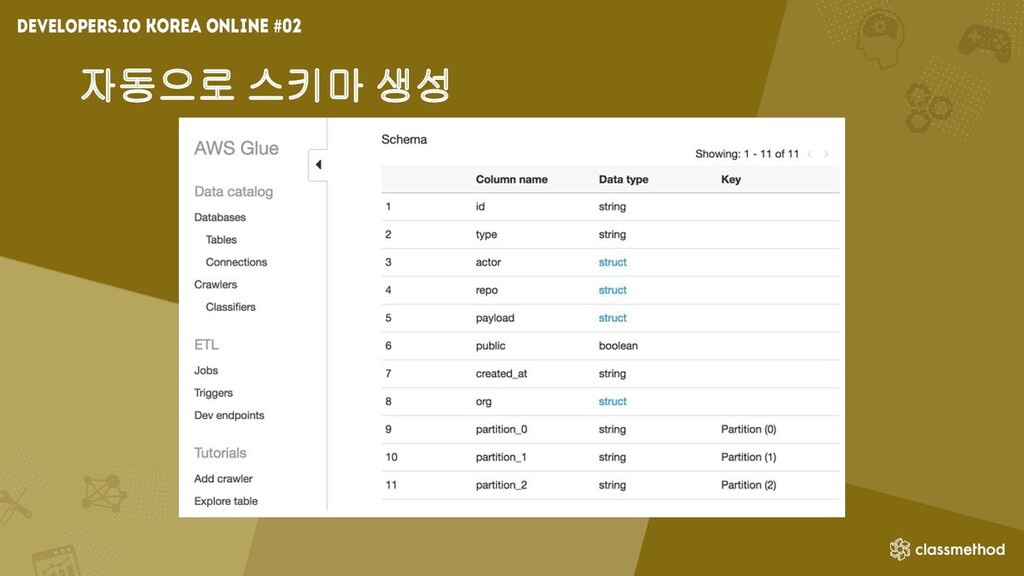
Glue의 특징 • 서버리스로 관리할 인프라가 없음 • 크롤러를 통해서
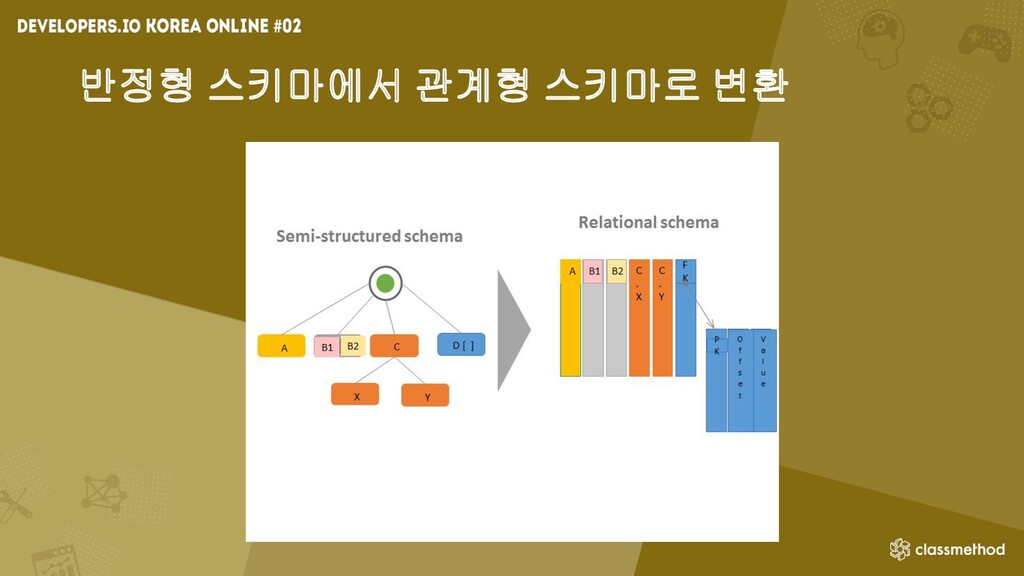
자동으로 스키마 생성 • GUI 클릭으로 자동으로 ETL 코드 자동 생성 및 수정 • 반정형 데이터를 관계형 데이터로 변환 가능 • 반복 일정과 이벤트에 따른 작업 실행 • Workflow, Step Functions를 통한 작업관리
자동으로 스키마 생성
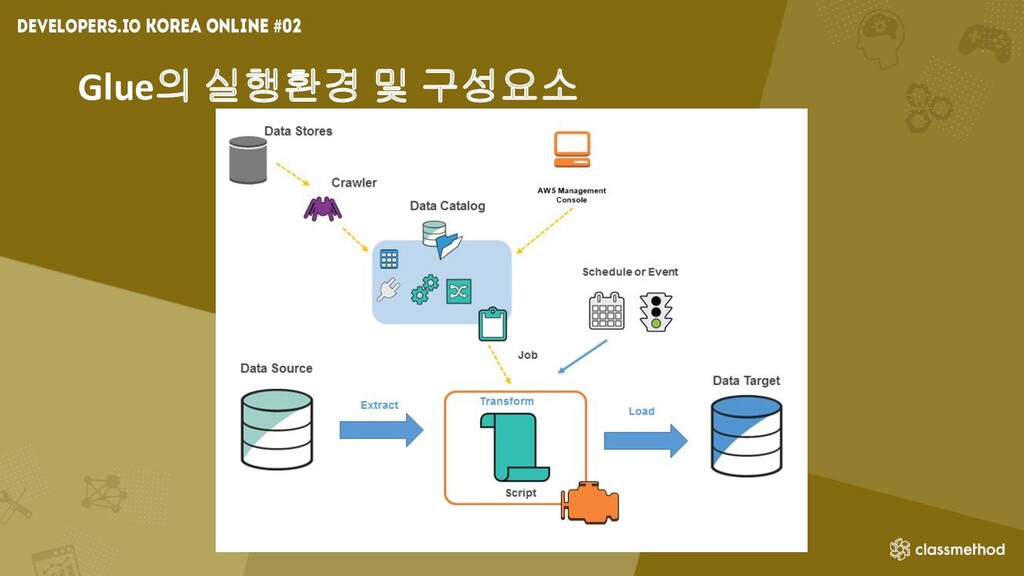
Glue의 ETL 작업 수행과정 • 데이터의 원본을 크롤링하여 데이터 카탈로그에
메타데이터 생성 • 데이터 카탈로그의 정보를 바탕으로 작업 정의 • 정의된 작업에 따라서 ETL의 코드가 자동으로 생성 • 작업 실행으로 소스 데이터에서 추출, 변환하여 타겟으로 로드
Glue의 실행환경 및 구성요소
ETL의 예시
반정형 스키마에서 관계형 스키마로 변환
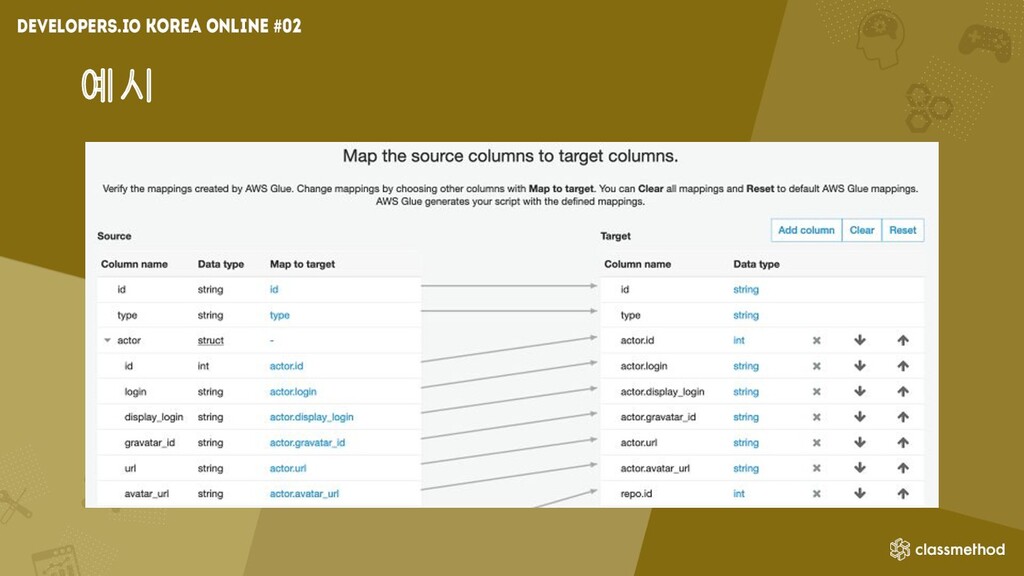
예시
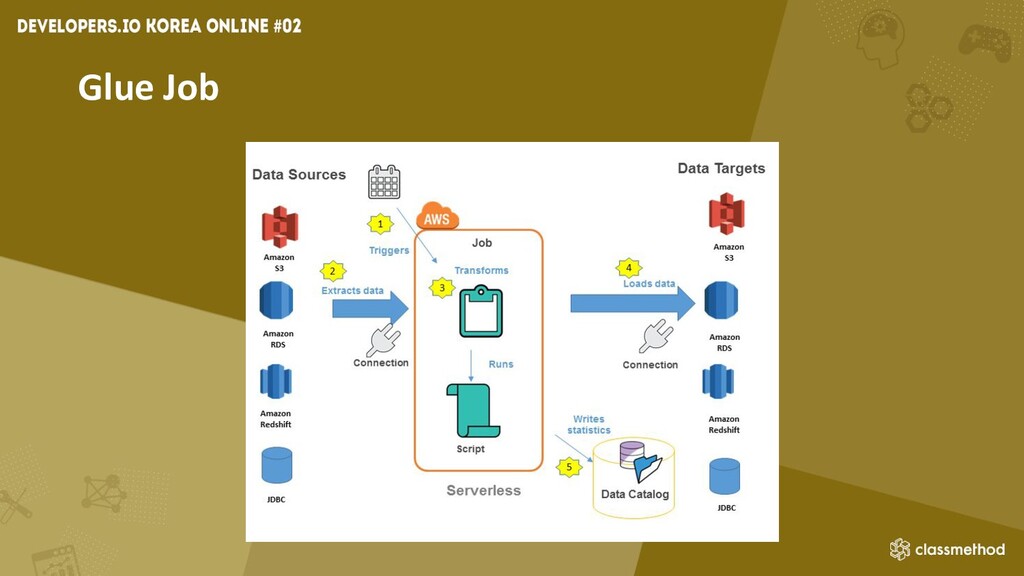
Glue Job • 규모와 유형에 따라서 Python Shell, Spark, 스트리밍
ETL 선택 • 작업 제한시간 기본값 2880분 • 트리거를 사용하여 자동으로 작업 시작 가능 • 다양한 형식의 출력파일 : JSON, CSV, ORC, Apache Parquet 등 • 오류시 자동으로 재시도 • 엔드포인트를 사용하여 스크립트 개발 및 테스트 가능
Glue Job
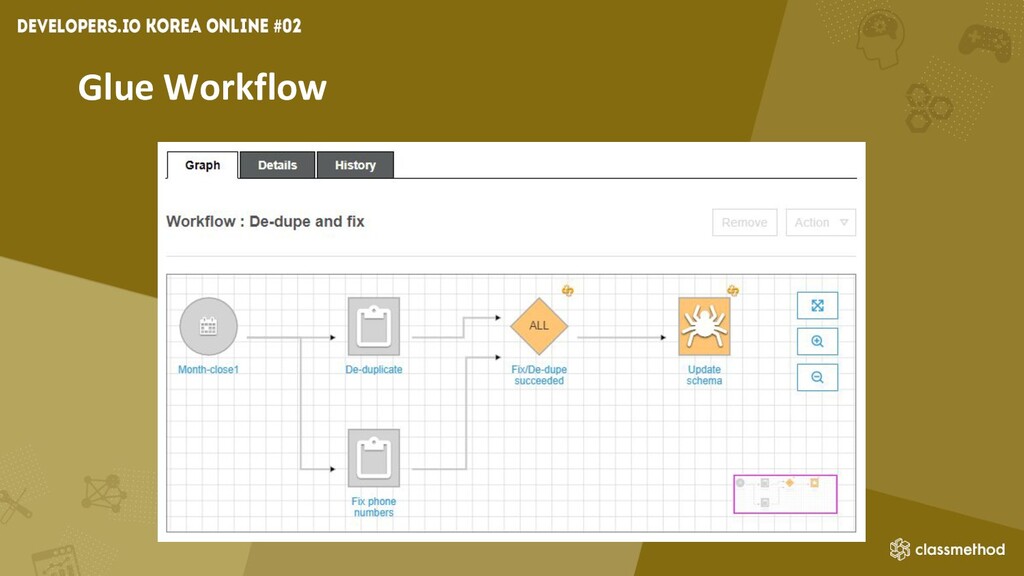
Glue Workflow
요약 • AWS Data Pipeline • EC2 인스턴스 사용 •
데이터의 이동 및 변환 자동화 • 미리 작성된 템플릿 제공 • 온프레미스에서도 가능 • AWS Glue • 서버리스 • 데이터 카탈로그 수집 • 규모와 목적에 따른 작업 실행환경 선택 • ETL 코드 자동으로 생성 • 대부분의 Data Pipeline 기능 할 수 있음
감사합니다!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}