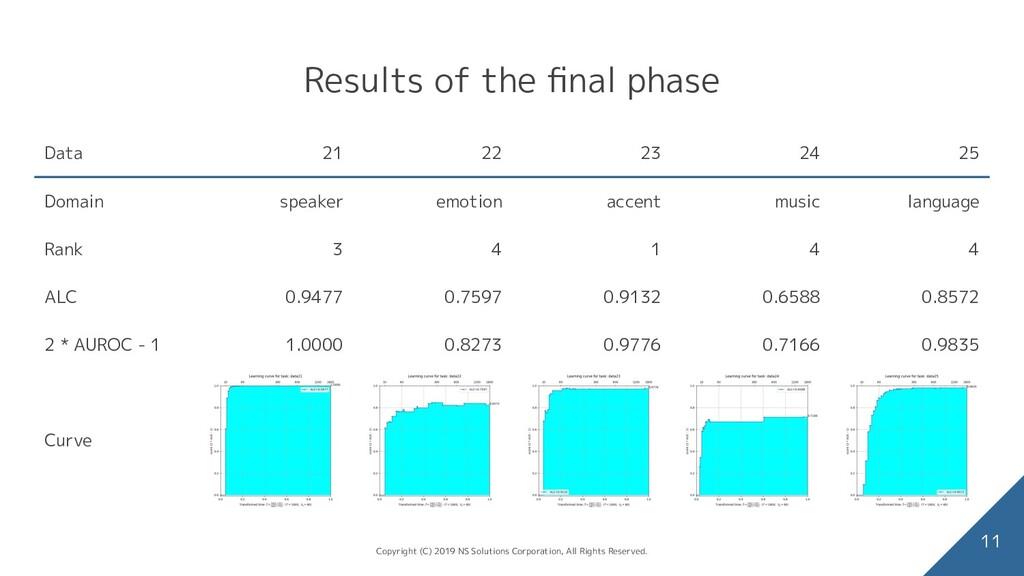
speaker identification ◦ emotion classification ◦ accent recognition ◦ music genre classification ◦ language identification • single channel • 16 kHz sampling rate Meta data • number of classes (is greater than 2 and less than 100) • number of training instances (varies from hundreds to thousands) • time budget (is 1800 seconds for all the datasets) 2 Copyright (C) 2019 NS Solutions Corporation, All Rights Reserved.
How to get a high ALC • speed up feature extraction • converge the loss quickly • keep a high AUROC Copyright (C) 2019 NS Solutions Corporation, All Rights Reserved. transformed time 2 * AUROC - 1
2019 NS Solutions Corporation, All Rights Reserved. n_dft=1024, n_hop=512, n_mels=64, fmin=20, fmax=8000 standardize Use kapre [Choi+, '17] for fast transformation preprocessed speech data
from pretrained model trained on data01 • optimizer: SGD ◦ lr: 0.01 ◦ momentum: 0.9 ◦ decay: 1e-06 • batch size: 32 Compute the validation score every 5 epochs and resume training if it is not the highest • the ratio of training and validation data is 9:1 Stop training when the remaining time is less than 0.125 * time_budget 8 Copyright (C) 2019 NS Solutions Corporation, All Rights Reserved.
pretrained model • data augmentation Unsuccessful work • complex network architecture like EfficientNet [Tan & Le, '19] Future work • automated data augmentation Copyright (C) 2019 NS Solutions Corporation, All Rights Reserved.
On-GPU Audio Preprocessing Layers for a Quick Implementation of Deep Neural Network Models with Keras." In arXiv, 2017. DeVries, T., and Taylor G. W., "Improved Regularization of Convolutional Neural Networks with Cutout." In arXiv, 2017. Tan, M., and Le, Q. V., "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." In Proceedings of ICML, pp. 6105-6114, 2019. Zhang, H., Cisse, M., Dauphin, Y. N., and Lopez-Paz, D., "mixup: Beyond Empirical Risk Minimization." In Proceedings of ICLR, 2018. Copyright (C) 2019 NS Solutions Corporation, All Rights Reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data augmentation 6 random crop mixup [Zhang+, '17] cutout [DeVries](https://files.speakerdeck.com/presentations/45fdf55491984f899189602d00164671/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}