) • Researcher • Data Science & Infrastructure Technologies • System Research & Development Center • Technology Bureau @Y_oHr_N @Y-oHr-N #SemiSupervisedLearning #AnomalyDetection #DataOps
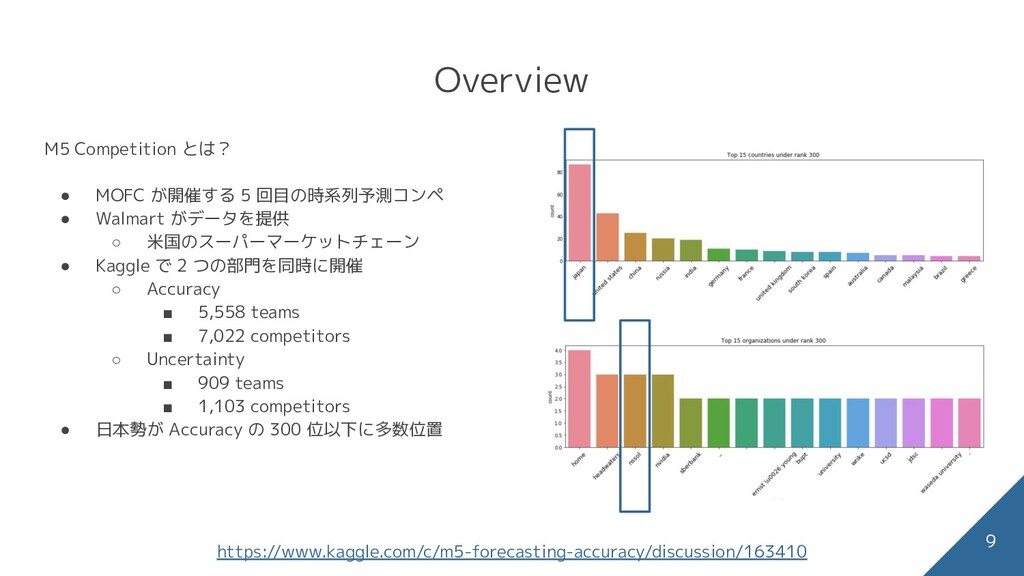
のベンチマークとして公開 • 4 つの統計モデルが銅圏に位置 ◦ Exponential Smoothing - bottom-up(ES_bu) ◦ Exponential Smoothing with eXplanatory variables (ESX) ◦ Average of the two ES methods, the first computed using the top-down approach and the second using the bottom-up approach (Com_tb) ◦ AutoRegressive Integrated Moving Average with eXplanatory variables (ARIMAX) 50 位以下の参加者は 1 つか 2 つを除いて全て機械学習モデルを利用 37
On impact of num_threads to LGBM training time | Kaggle • 大規模なマシンを用いて学習する際,全スレッドを使用すると却って学習時間が悪化する LightGBM reproducibility issue | Kaggle • 列の順番を並び替えると学習結果を再現できなくなる LightGBMError: Do not support special JSON characters in feature name. | Kaggle • 特徴名にカンマのような特殊文字が含まれていると例外を送出する 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Difficulties - zero-inflated data Croston 法 [Croston, '72] • 最も古い断続的需要予測手法](https://files.speakerdeck.com/presentations/c860a2de85374c8a884e52fd05a57850/slide_17.jpg){kind=link}
![Difficulties - zero-inflated data TSB 法 [Teunter+, '11] • Croston](https://files.speakerdeck.com/presentations/c860a2de85374c8a884e52fd05a57850/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}