Rei, Øistein E. Andersen and Zheng Yuan Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2795–2806, 2017 ⽂献紹介(2018/04/19) ⻑岡技術科学⼤学 ⾃然⾔語処理研究室 ⼩川 耀⼀朗 1
to automatically detect and correct errors. l Given an ungrammatical input sentence, the task is formulated as “translating“ it to its grammatical sentence. 3
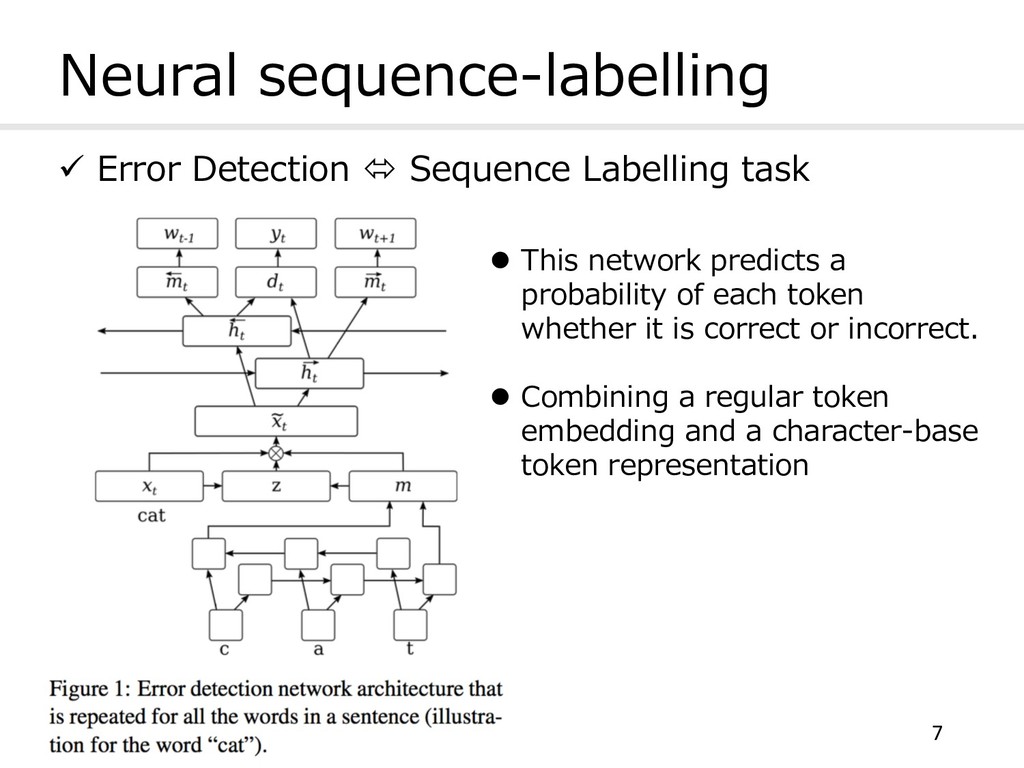
l This network predicts a probability of each token whether it is correct or incorrect. l Combining a regular token embedding and a character-base token representation
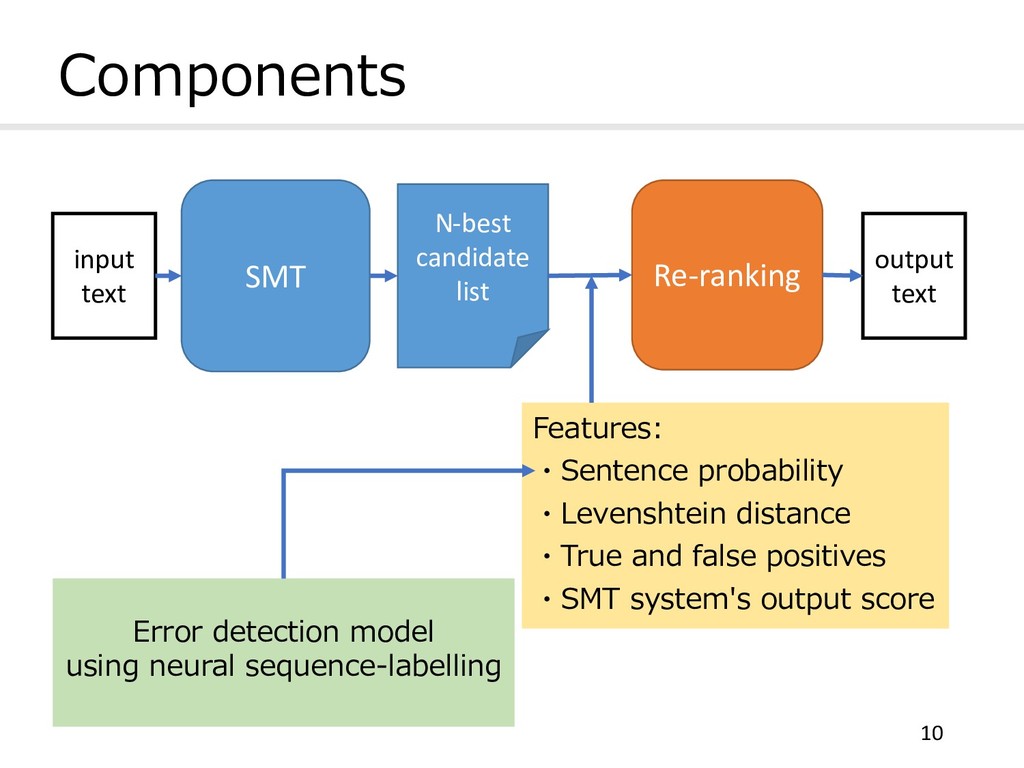
score to each candidate n Sentence probability the overall sentence probability of error detection model outputs (∑ () * ) n Levenshtein distance (LD) a candidate with the smallest LD would like to be selected (+ ,- ⁄ ) n True and false positives how many times the candidate hypothesis agree or not with the detection model on the tokens identified as incorrect (01 21 ⁄ ) 11
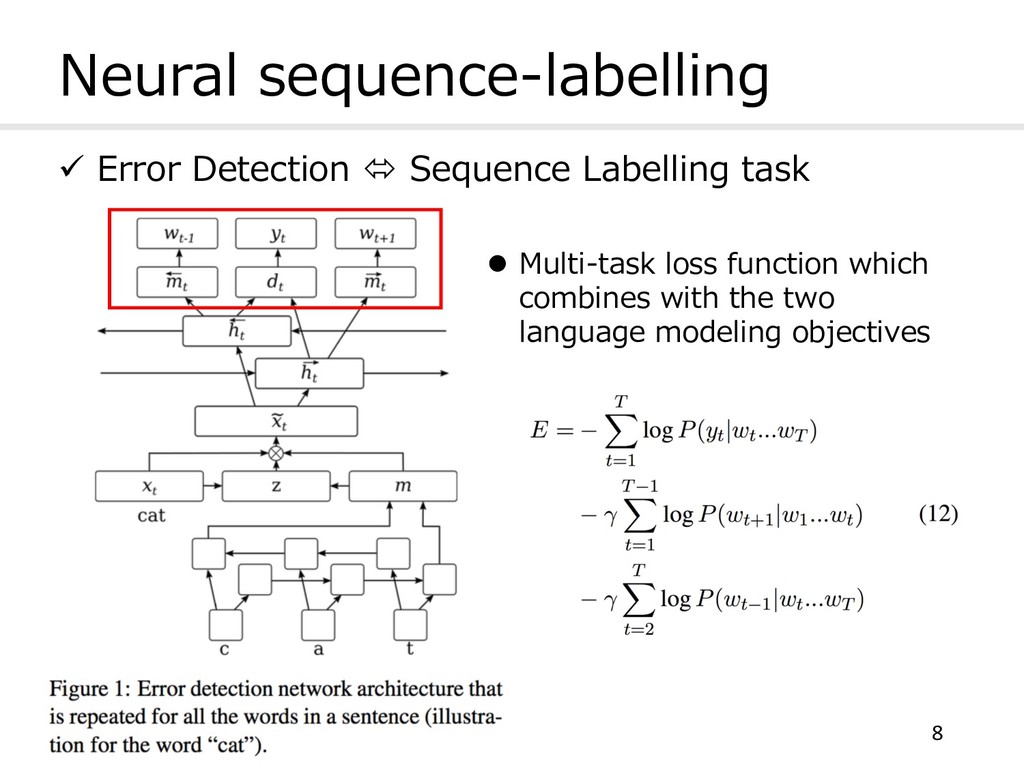
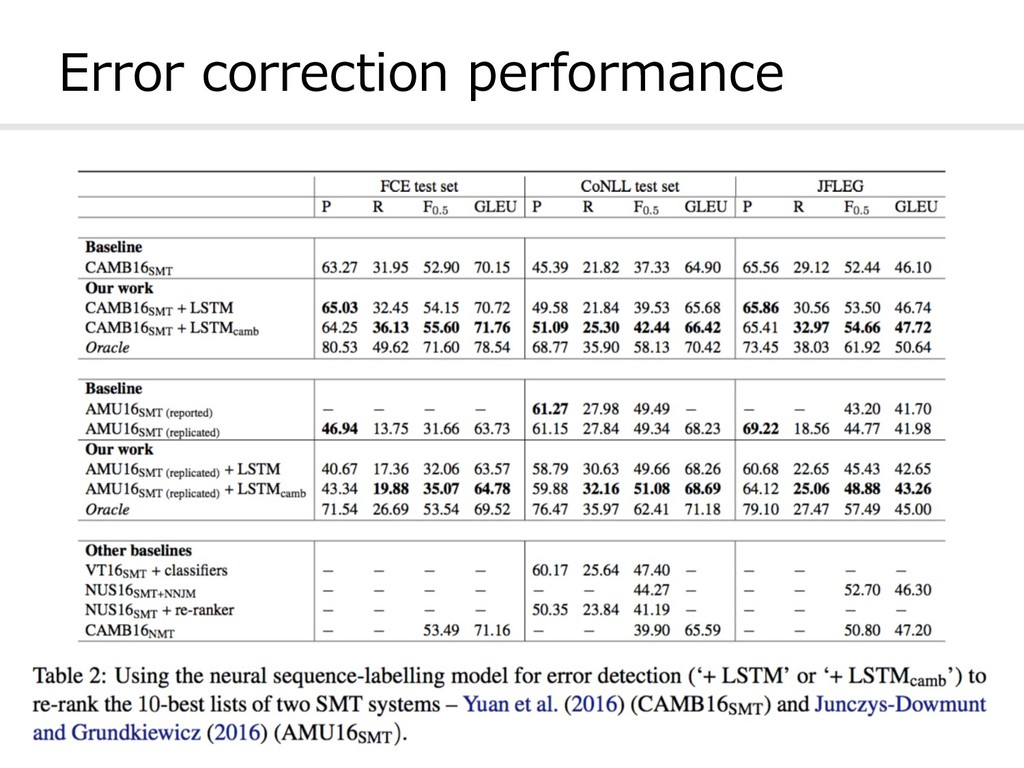
sequence-labelling model that calculates the probability of each token in a sentence being correct or incorrect in context. l Results achieved state-of-the-art on GEC l This approach can be applied to any GEC system that produces multiple alternative hypotheses. 13
Candidate re- ranking for SMT-based grammatical error correction. In Proceedings of the 11th Workshop on Innovative Use of NLP for building Educational Applications, pages 256-266. 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}