computers, but not everyone agrees that this benefits society. … Write a letter to your local newspaper in which you state your opinion on the effects computers have on people. Essay Dear local newspaper, I think effects computers have on people are great learning skills/affects because they give us time to chat with friends/new people, helps us learn about the globe(astronomy) and keeps us out of troble! … Thank you for listening. score: 4 (1~6) 自動小論文採点: 小論文に自動でスコア付けを行うタスク
the State of the Art - https://www.ijcai.org/Proceedings/2019/0879.pdf - https://qiita.com/r-takahama/items/8f87aa1425cabb5d9a26 Kaggle - https://www.kaggle.com/c/asap-aes 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
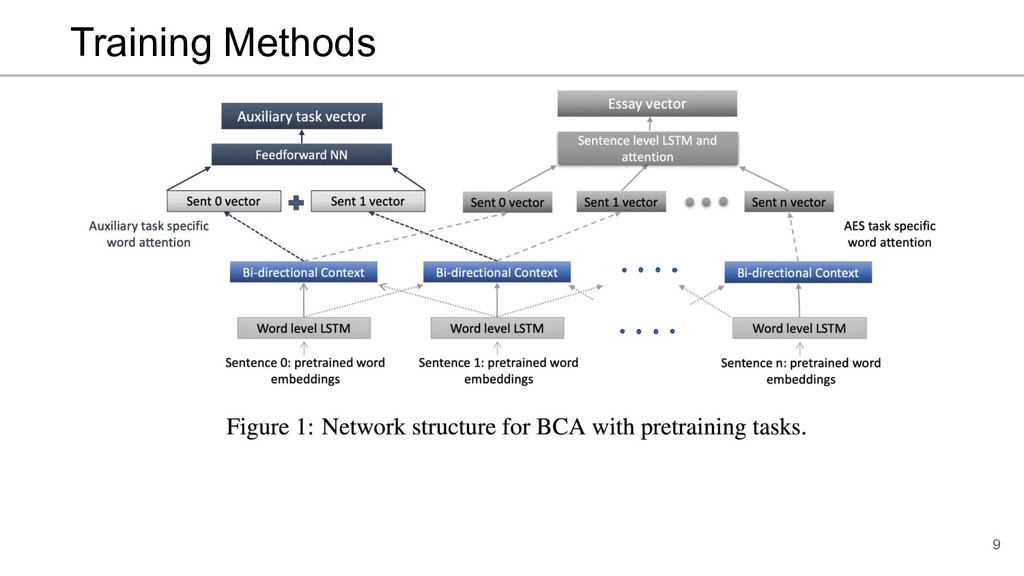
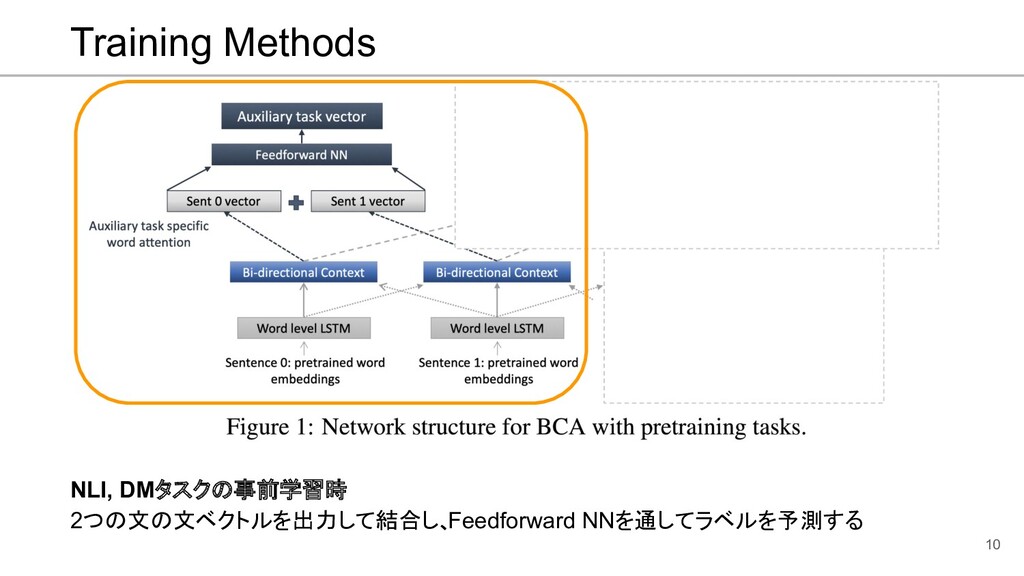
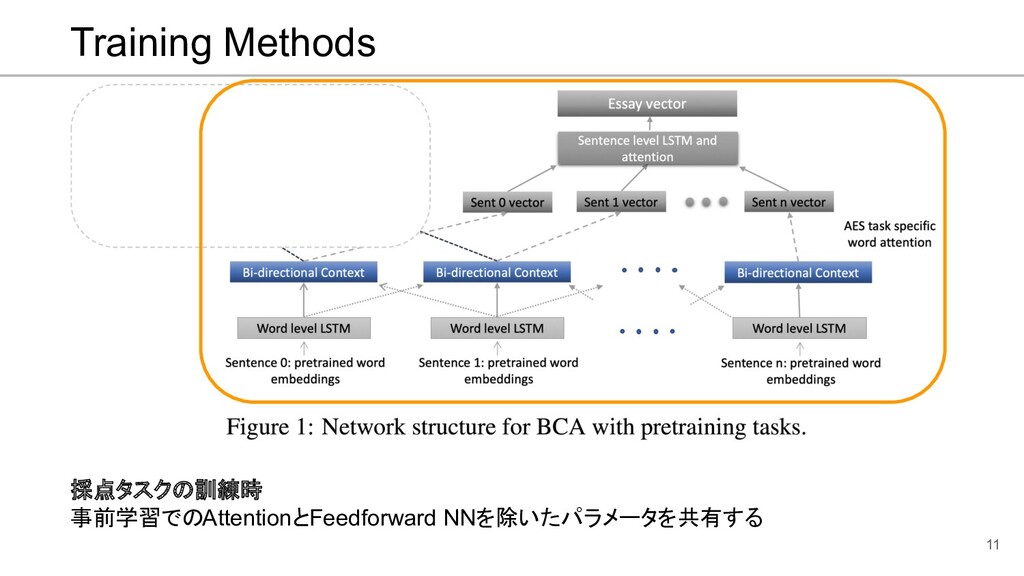
![Bidirectional context with attention (BCA) 7 [Nadeem and Ostendorf, 2018]](https://files.speakerdeck.com/presentations/1ff134e392cb4f22bb4a19ac0da1637d/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
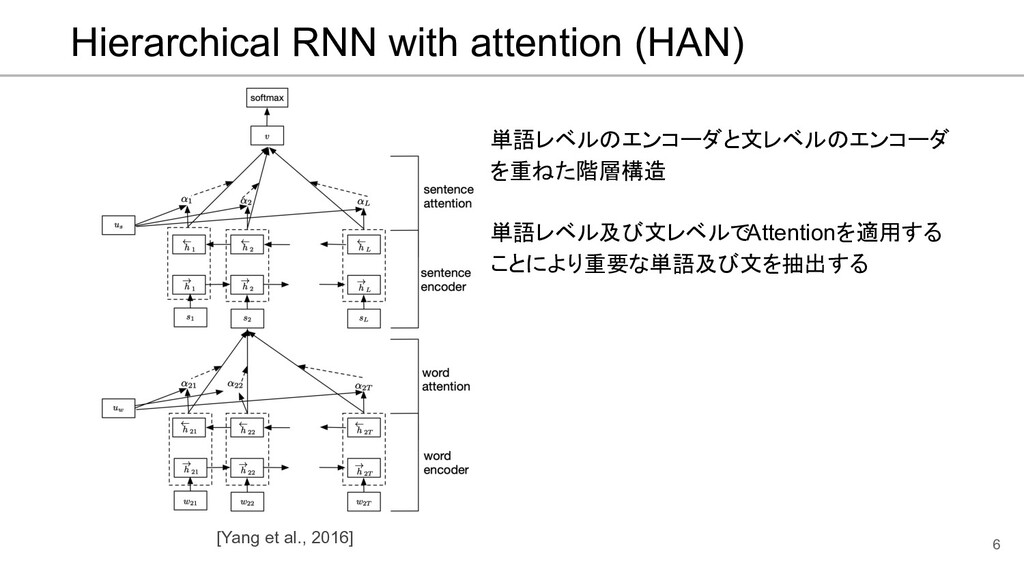
![References • [Yang et al., 2016] ◦ Hierarchical Attention Networks](https://files.speakerdeck.com/presentations/1ff134e392cb4f22bb4a19ac0da1637d/slide_15.jpg){kind=link}
{kind=link}