Share
言語処理学会第26回年次大会(NLP2020) テーマセッション: 言語教育と言語処理の接点 での発表スライド 原稿: https://www.anlp.jp/proceedings/annual_meeting/2020/pdf_dir/F2-3.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
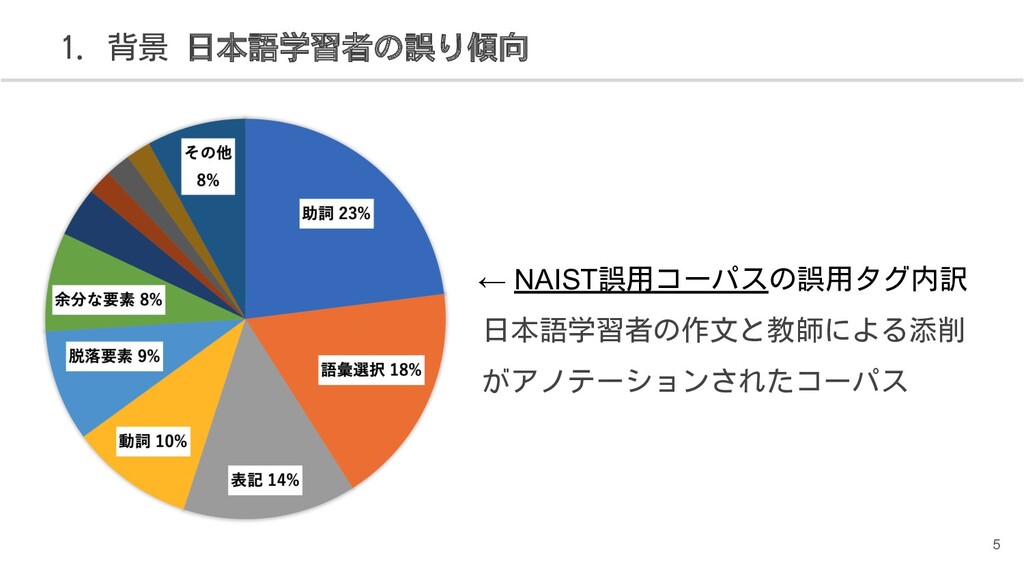
![6 1. 背景 日本語学習者の誤り傾向 日本語学習者は助詞が最も間違えやすい → 助詞誤りに限定した研究が多い [今枝ら2003]日本語学習者の作文における格助詞の誤り検出と訂正 [Suzukiら2006]Learning to](https://files.speakerdeck.com/presentations/ad418b9a9fd7461da92a33f03cbd533e/slide_5.jpg){kind=link}
![誤りの種類を限定しない手法 [水本ら2013]日本語学習者の作文自動誤り訂正のた めの語学学習SNSの添削ログからの知識獲得 → これ以来、研究が行われていない 7 1. 背景 日本語学習者の誤り傾向](https://files.speakerdeck.com/presentations/ad418b9a9fd7461da92a33f03cbd533e/slide_6.jpg){kind=link}
![1. 背景 先行研究 8 [水本ら2013] • 統計的機械翻訳(SMT)を用いて日本語文法誤り訂正 • 学習者コーパスLang-8を訓練データに使用 言語学習者の作文とネイティブによる添削が付与](https://files.speakerdeck.com/presentations/ad418b9a9fd7461da92a33f03cbd533e/slide_7.jpg){kind=link}
![[水本ら2013] • 統計的機械翻訳(SMT)を用いて日本語文法誤り訂正 • 学習者コーパスLang-8を訓練データに使用 1. 背景 先行研究 9 本研究では](https://files.speakerdeck.com/presentations/ad418b9a9fd7461da92a33f03cbd533e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
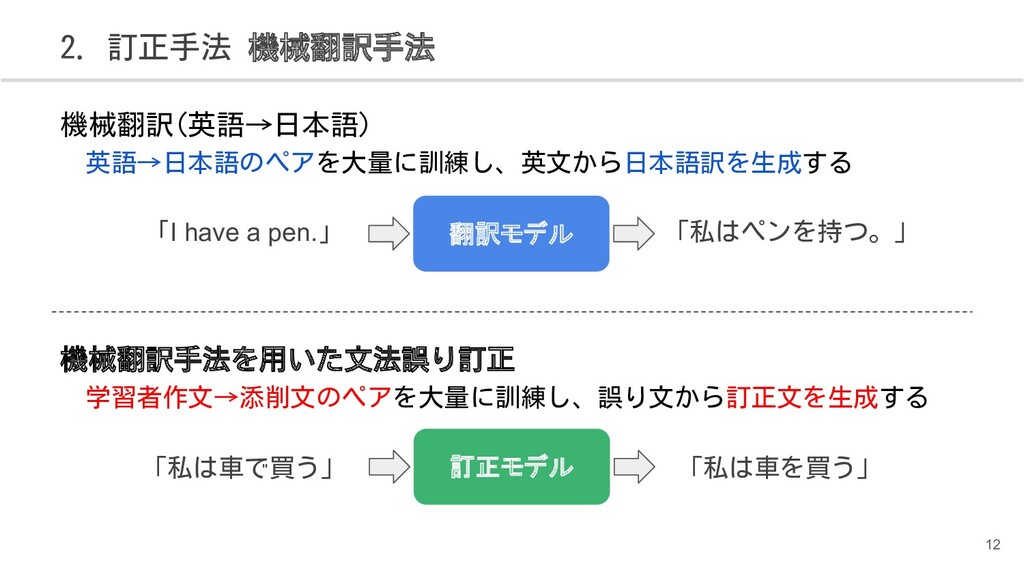{kind=link}
{kind=link}
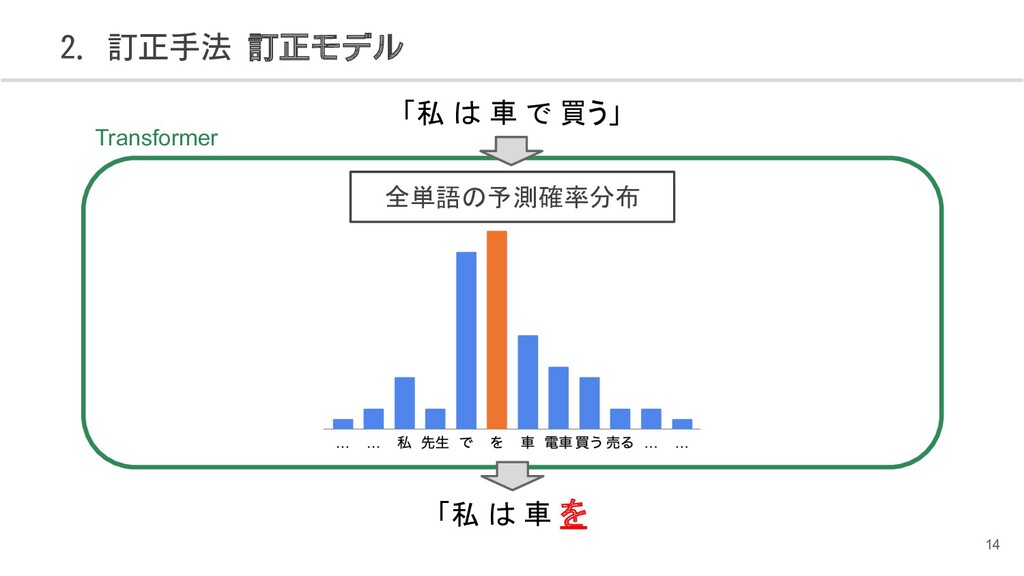{kind=link}
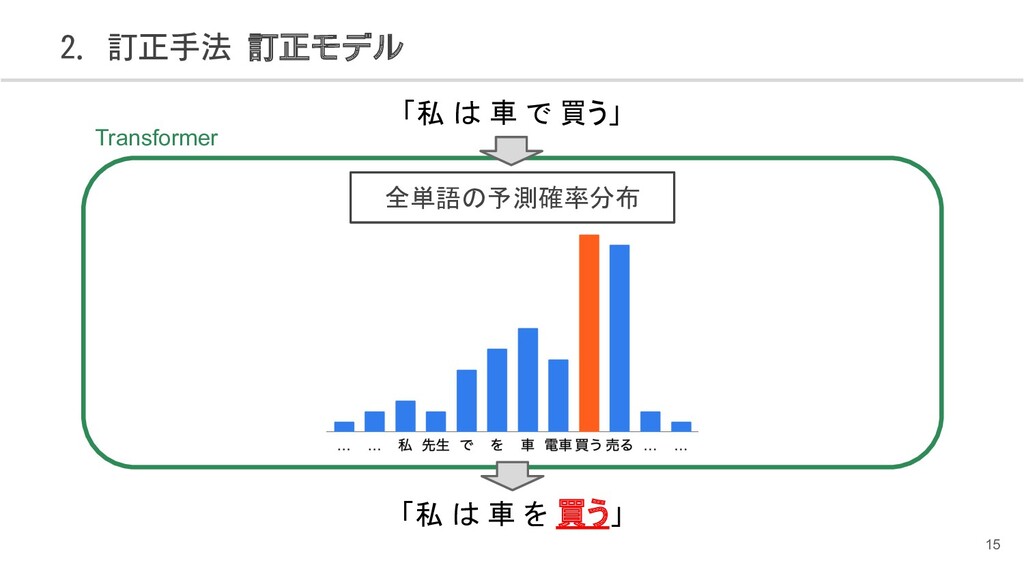{kind=link}
{kind=link}
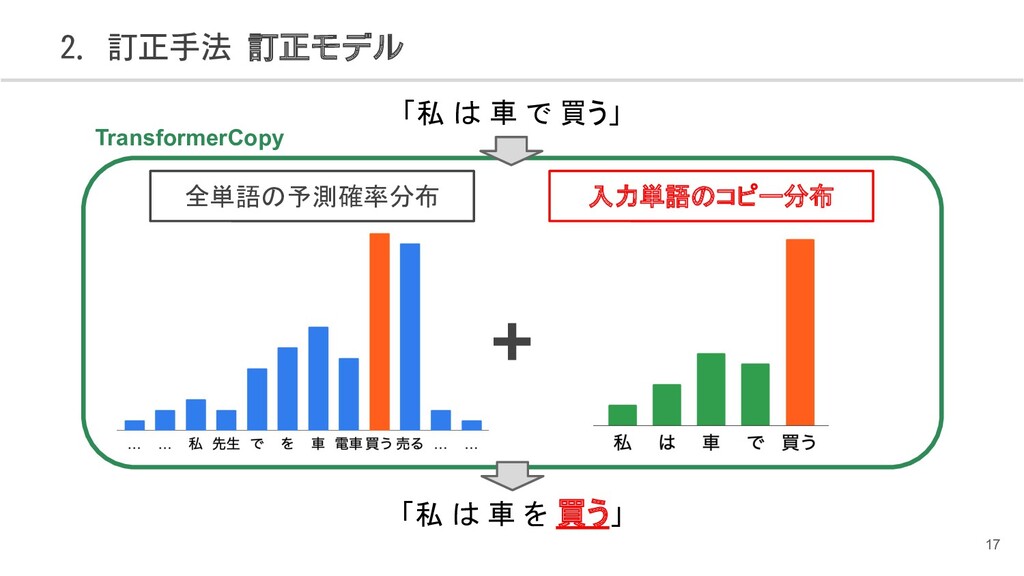{kind=link}
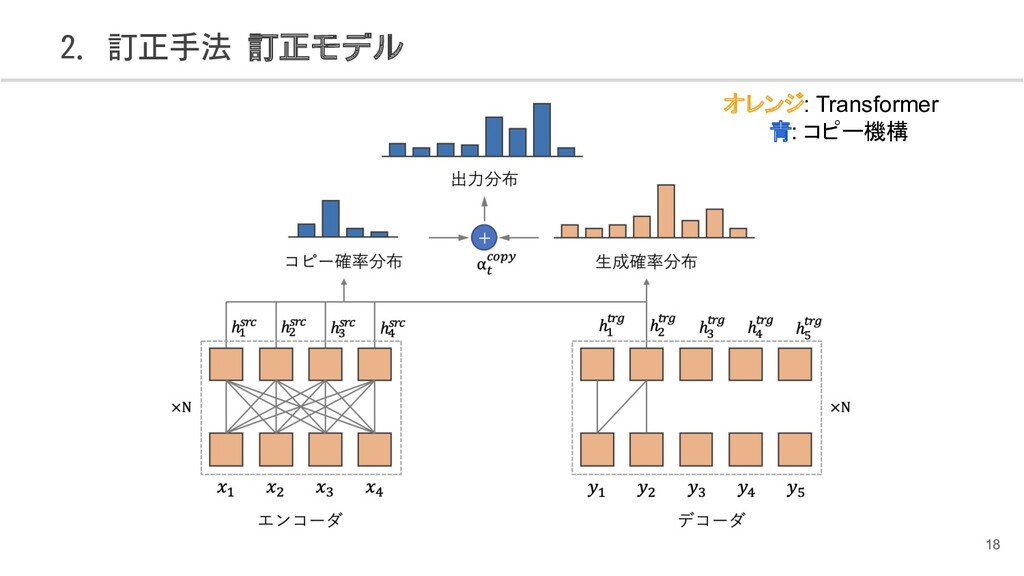{kind=link}
{kind=link}
{kind=link}
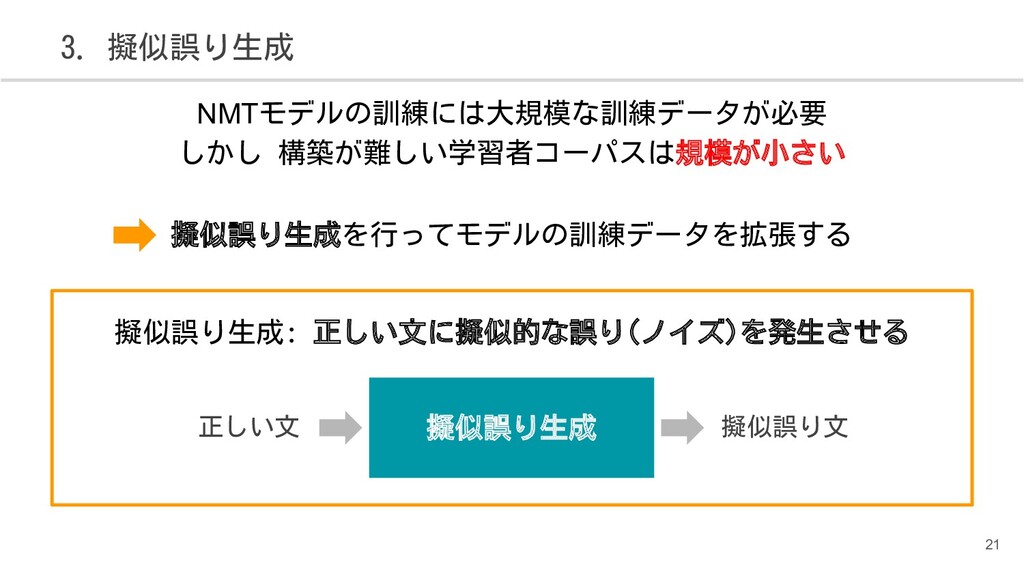{kind=link}
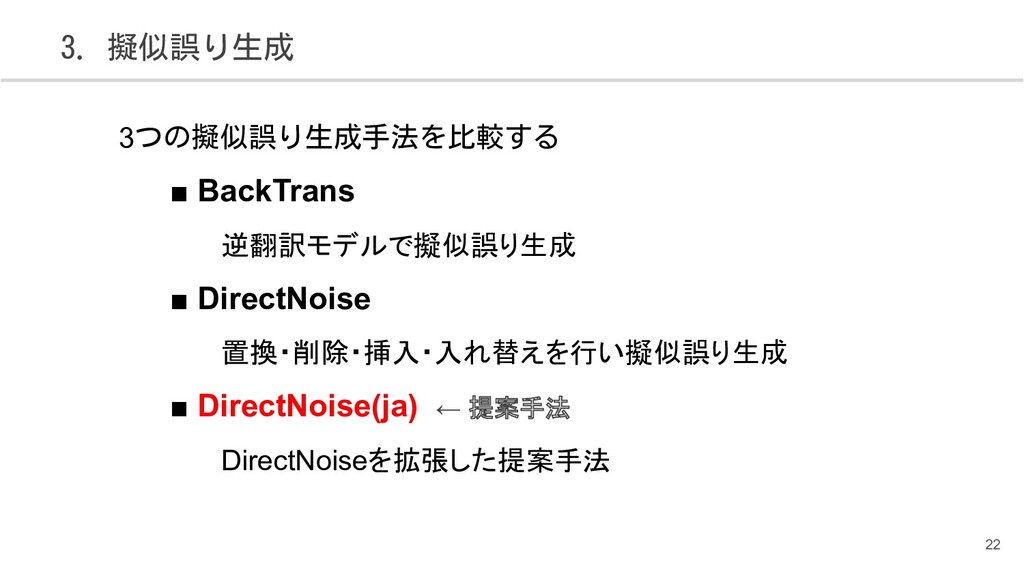{kind=link}
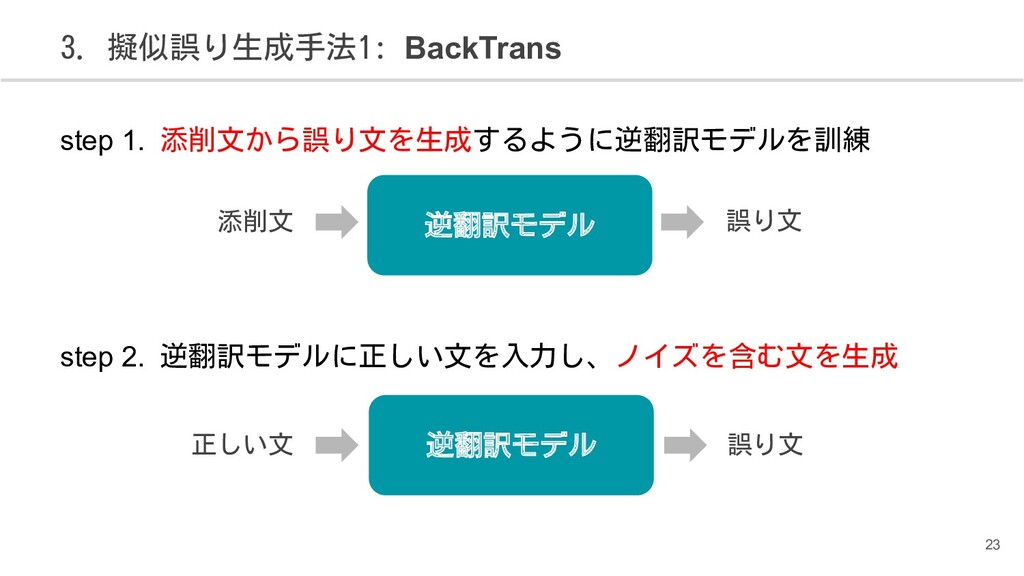{kind=link}
{kind=link}
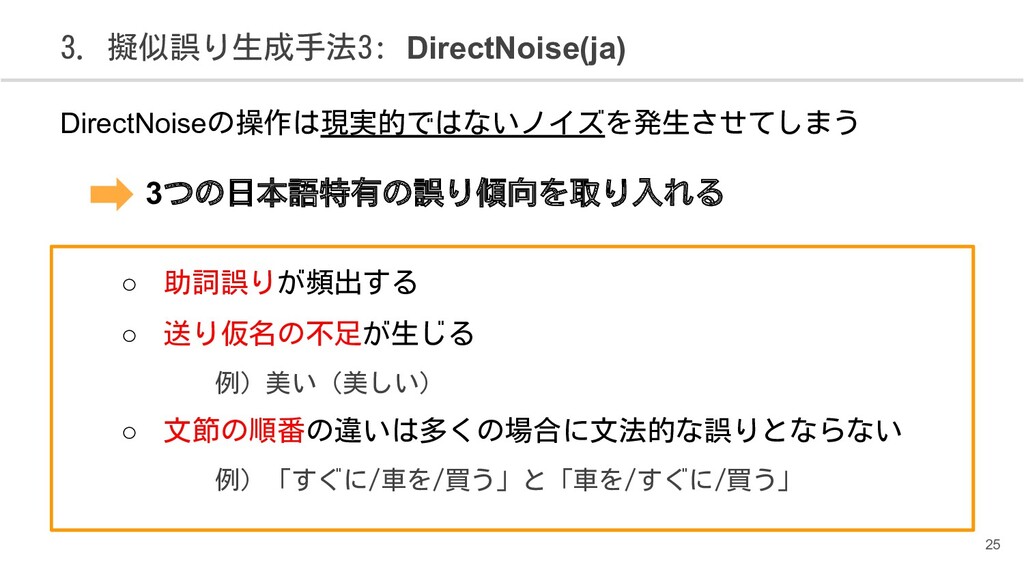{kind=link}
{kind=link}
{kind=link}
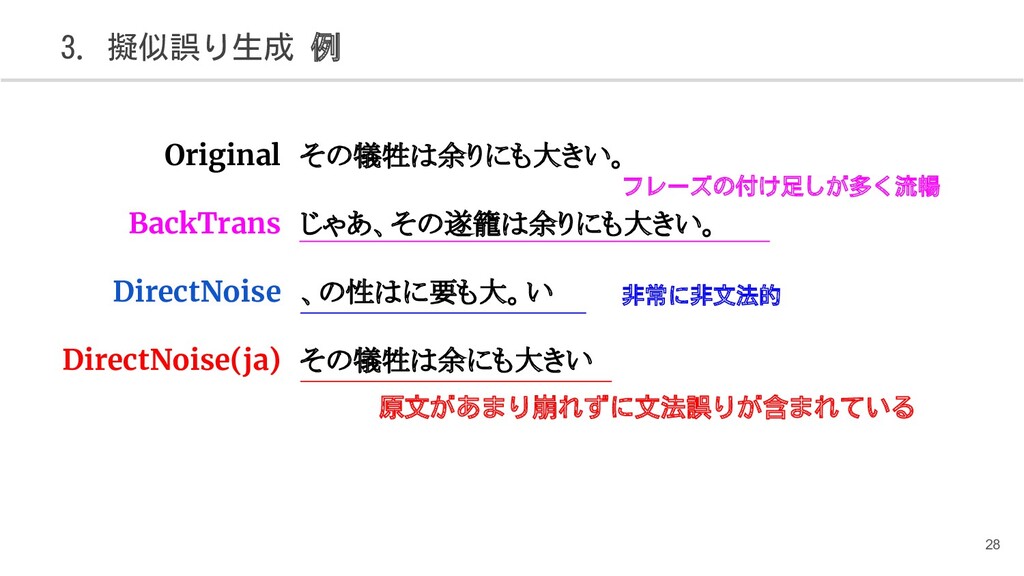{kind=link}
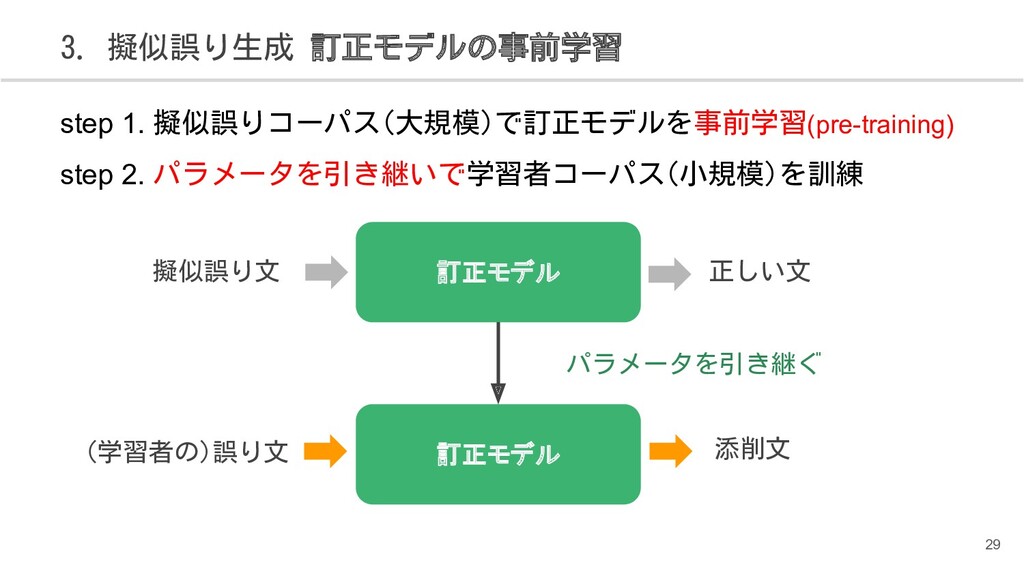{kind=link}
{kind=link}
{kind=link}
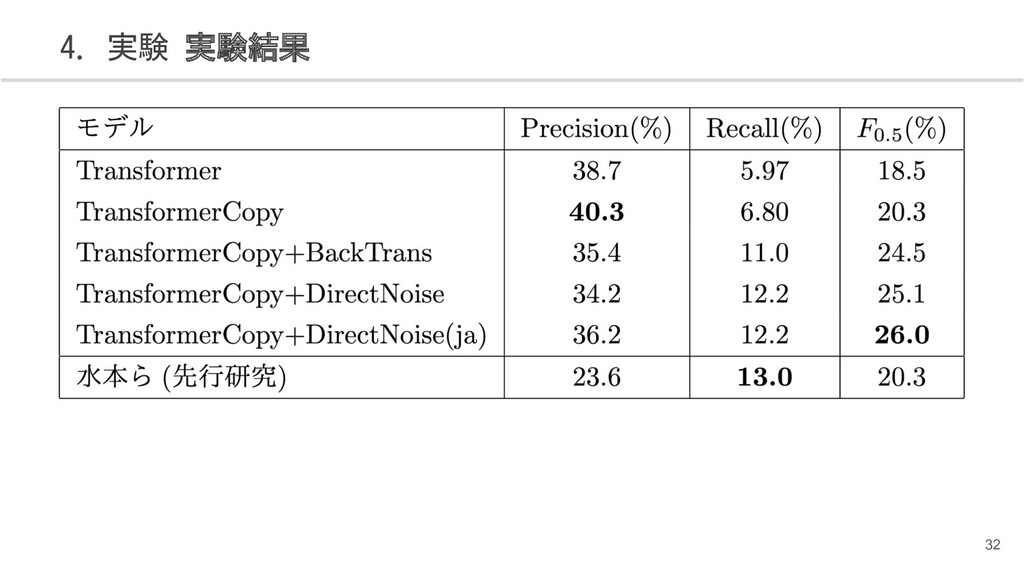{kind=link}
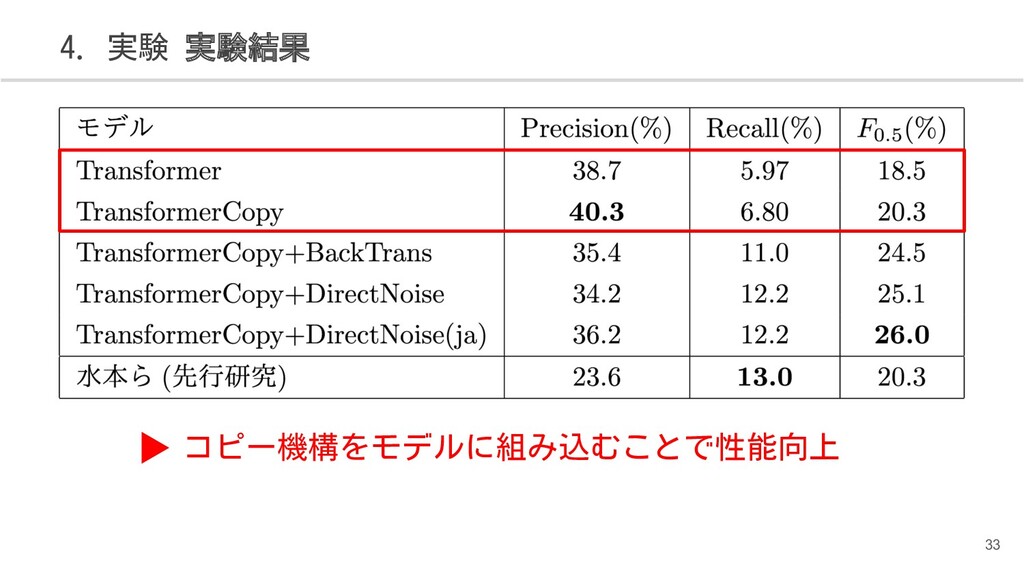{kind=link}
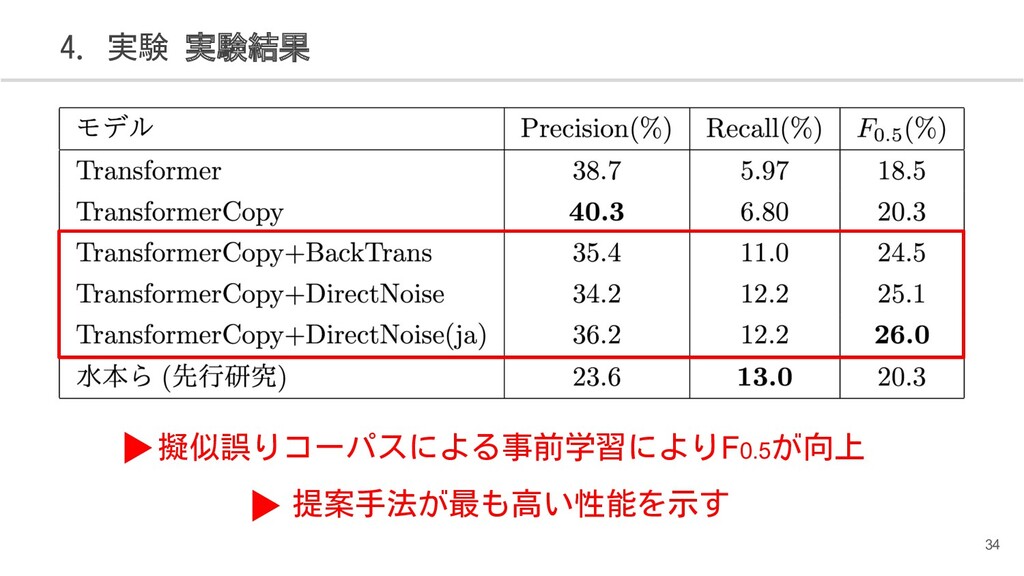{kind=link}
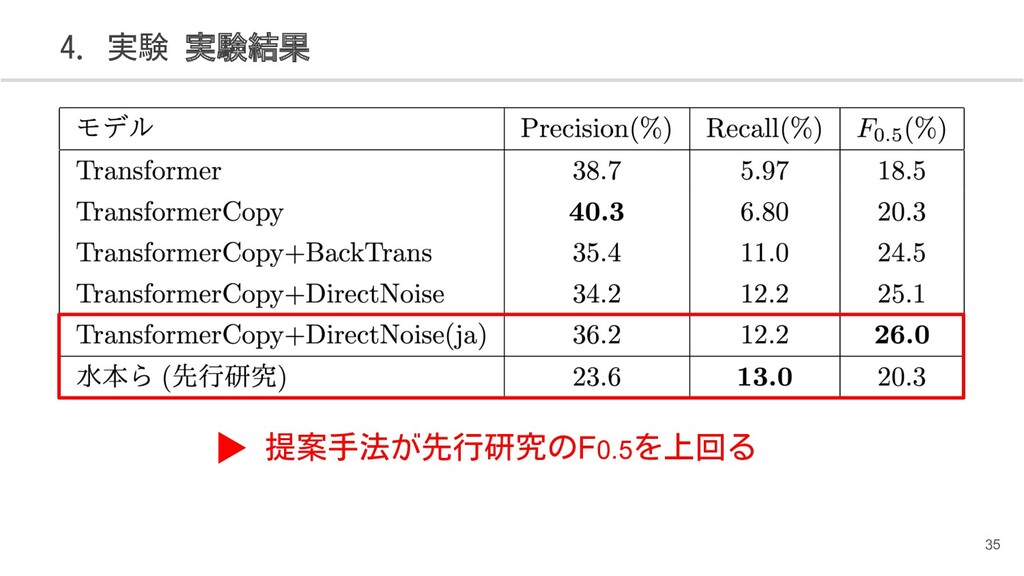{kind=link}
{kind=link}
{kind=link}
{kind=link}
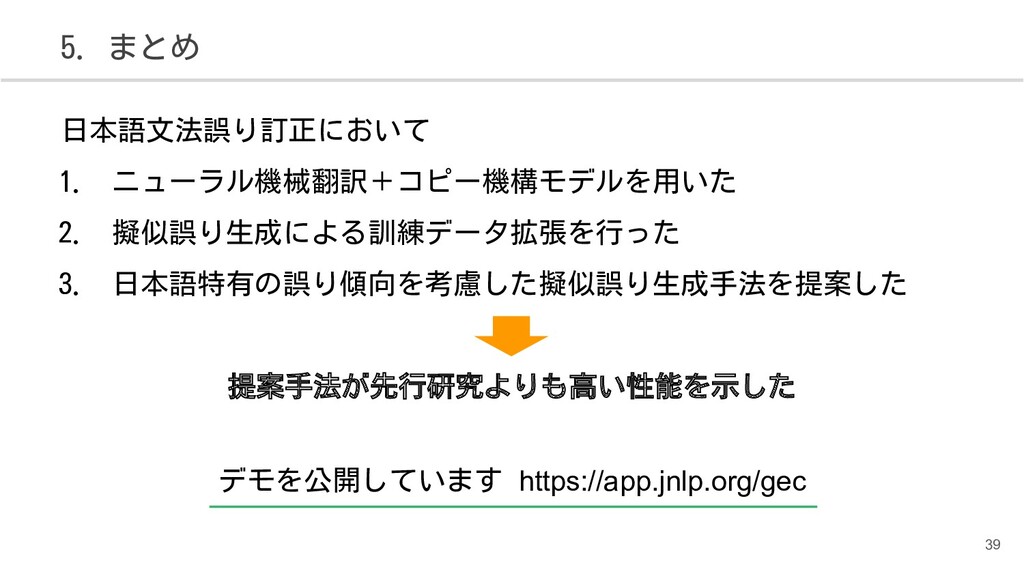{kind=link}
{kind=link}
{kind=link}
{kind=link}