An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
長岡技術科学大学
自然言語処理研究室
文献紹介(2019-09-30)
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
https://arxiv.org/pdf/1909.00502.pdf
Diverse Backtranslation for Grammar Correction (2018) • BACKTRANS(SAMPLE) ◦ Understanding Back-Translation at Scale (2018) • DIRECT NOISE ◦ Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data (2019) • Synthetic Spelling Error(SSE) ◦ Corpora Generation for Grammatical Error Correction (2019) • Right-to-left Re-ranking(R2L) ◦ Neural grammatical error correction systems with unsupervised pre-training on synthetic data (2019) • Sentence-level Error Detection(SED) ◦ The AIP-Tohoku System at the BEA-2019 Shared Task (2019)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
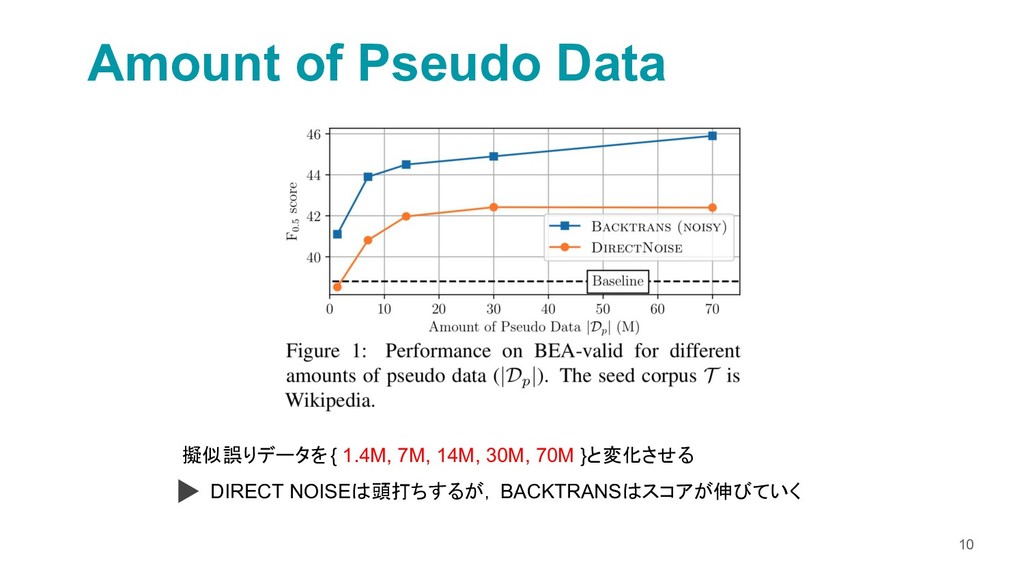{kind=link}
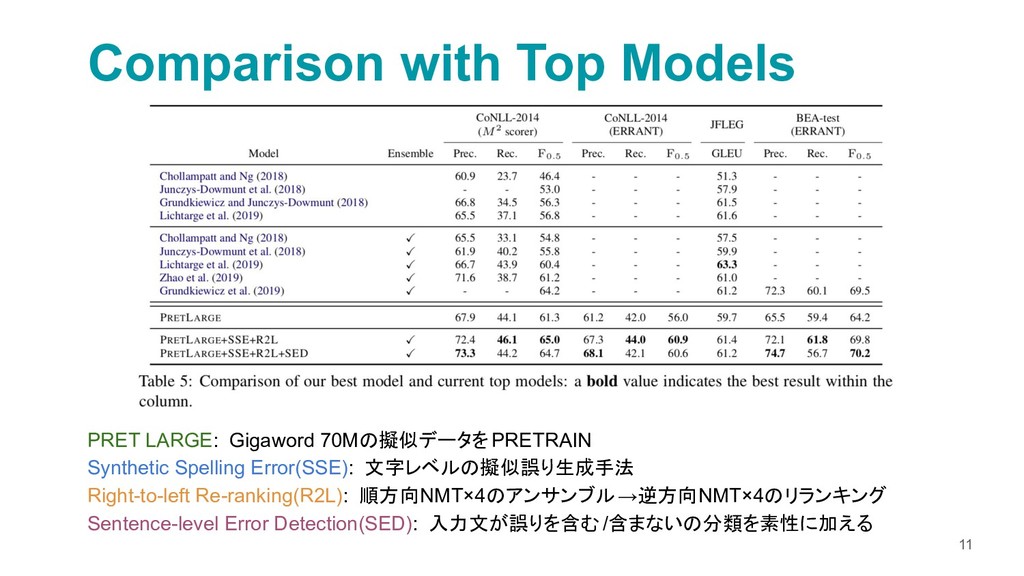{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
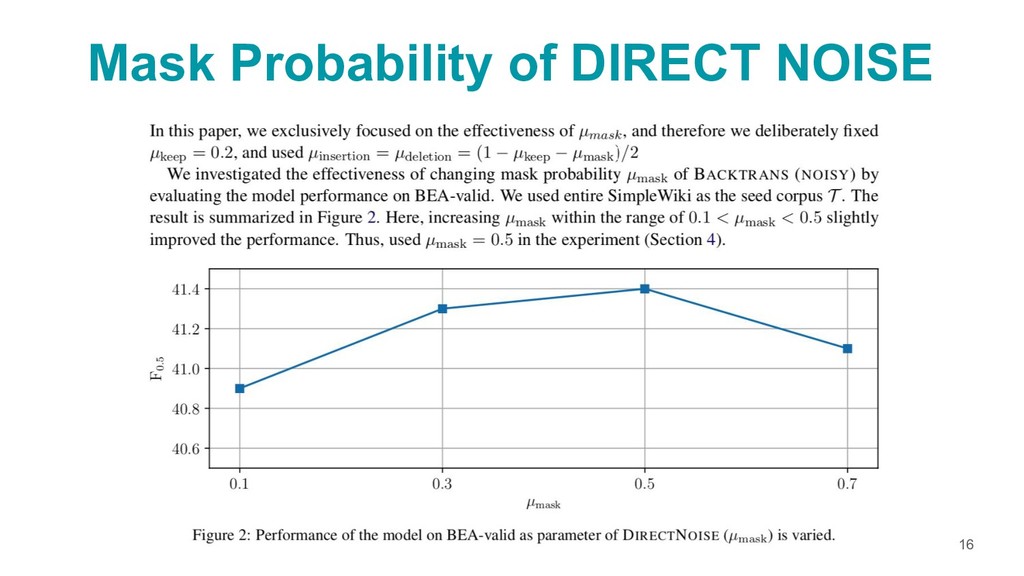{kind=link}
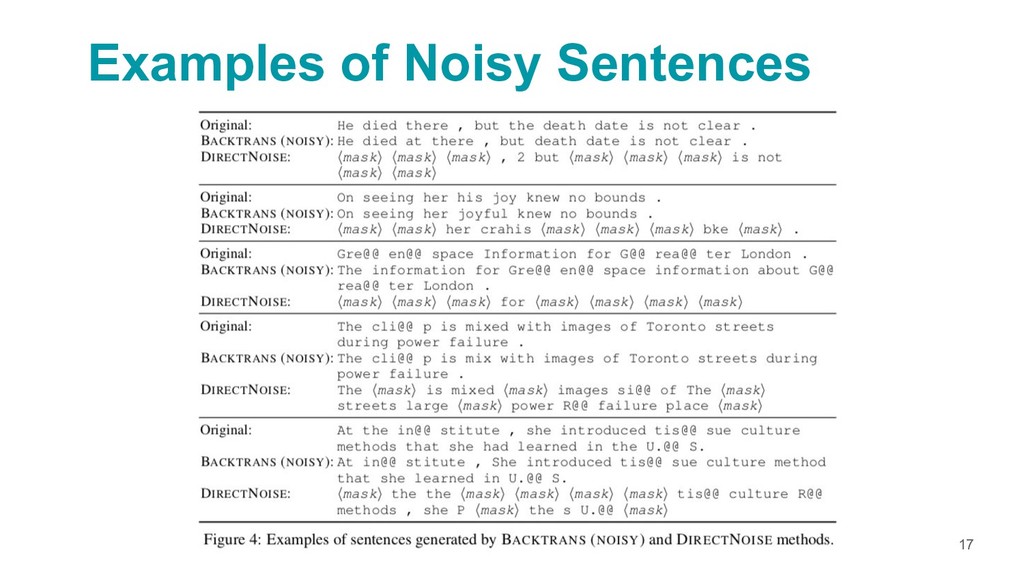{kind=link}