Share
長岡技術科学大学 自然言語処理研究室 文献紹介(2019-12-16) Context is Key- Grammatical Error Detection with Contextual Word Representations https://www.aclweb.org/anthology/W19-4410/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
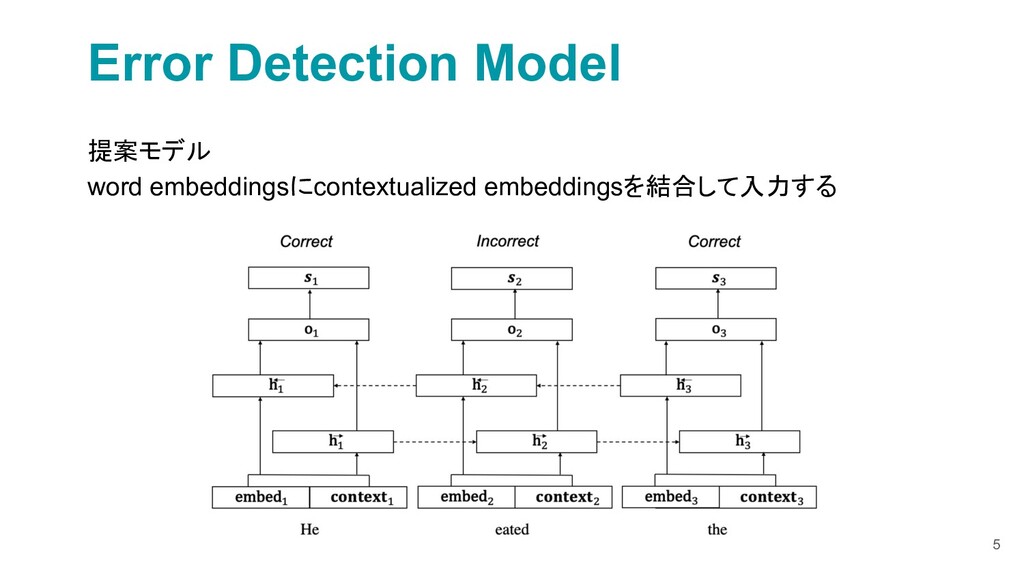{kind=link}
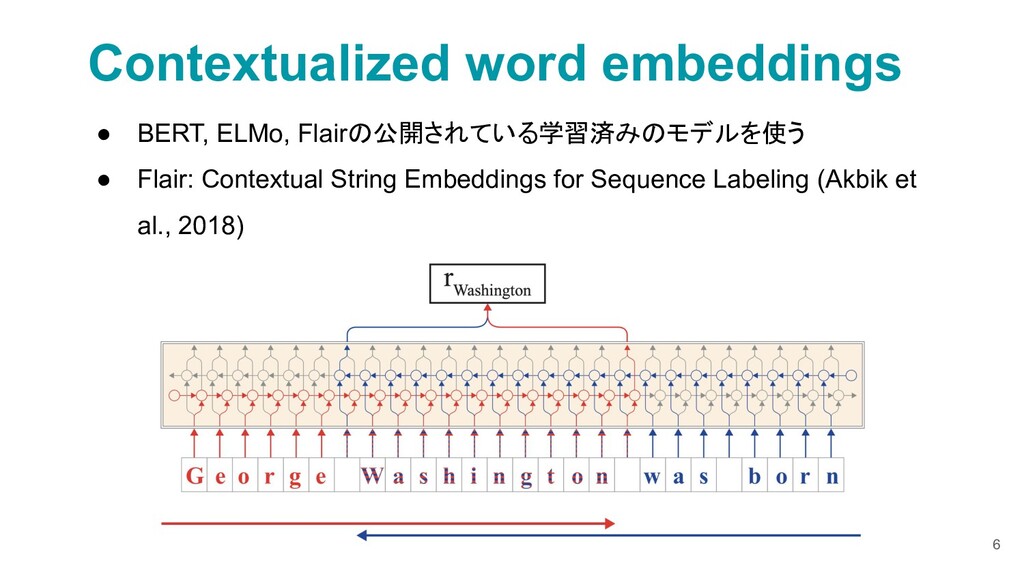{kind=link}
{kind=link}
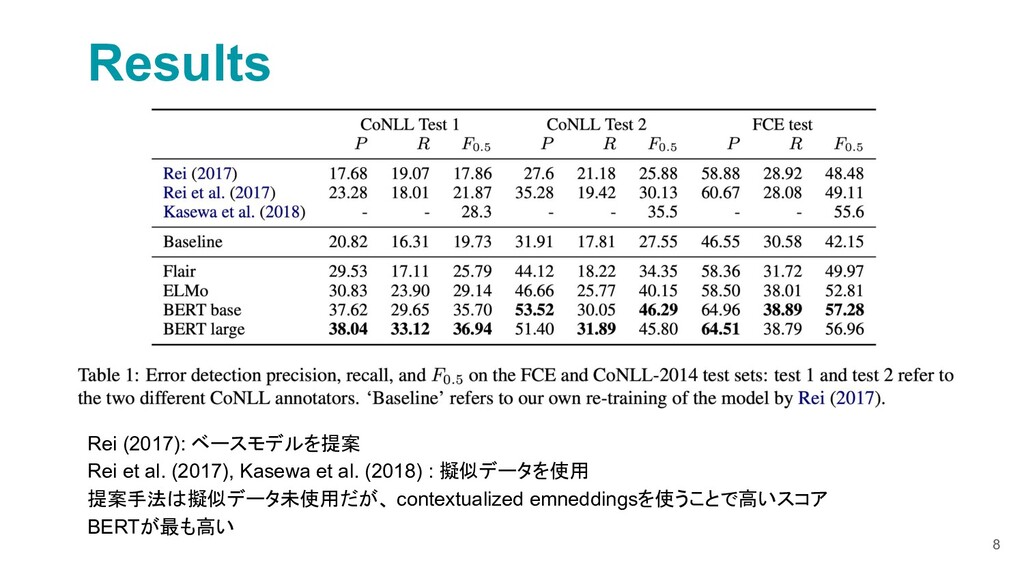{kind=link}
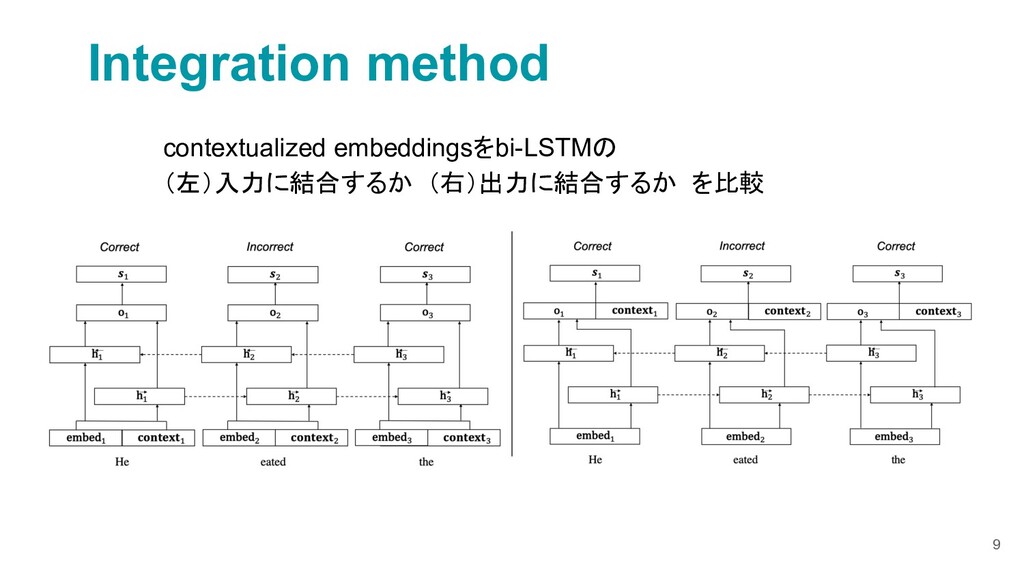{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}