Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
検索の仕組みを知ってみよう~入門編~
Search
yuki
January 28, 2023
Technology
0
200
検索の仕組みを知ってみよう~入門編~
yuki
January 28, 2023
Tweet
Share
Other Decks in Technology
See All in Technology
「コントロールの三分法」で考える「コト」への向き合い方 / phperkaigi2026
blue_goheimochi
0
150
【AWS】CloudTrail LakeとCloudWatch Logs Insightsの使い分け方針
tsurunosd
0
120
20260323_データ分析基盤でGeminiを使う話
1210yuichi0
0
180
テストプロセスにおけるAI活用 :人間とAIの共存
hacomono
PRO
0
160
Windows ファイル共有(SMB)を再確認する
murachiakira
PRO
0
270
AI時代のIssue駆動開発のススメ
moongift
PRO
0
210
AI時代のオンプレ-クラウドキャリアチェンジ考
yuu0w0yuu
0
230
形式手法特論:SMT ソルバで解く認可ポリシの静的解析 #kernelvm / Kernel VM Study Tsukuba No3
ytaka23
1
780
Phase02_AI座学_応用
overflowinc
0
2.7k
スピンアウト講座04_ルーティン処理
overflowinc
0
1.2k
スケールアップ企業でQA組織が機能し続けるための組織設計と仕組み〜ボトムアップとトップダウンを両輪としたアプローチ〜
qa
0
260
FastMCP OAuth Proxy with Cognito
hironobuiga
3
190
Featured
See All Featured
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
94
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
78
Site-Speed That Sticks
csswizardry
13
1.1k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
The Curse of the Amulet
leimatthew05
1
10k
Navigating Team Friction
lara
192
16k
Abbi's Birthday
coloredviolet
2
5.6k
Agile that works and the tools we love
rasmusluckow
331
21k
Fireside Chat
paigeccino
42
3.8k
Code Reviewing Like a Champion
maltzj
528
40k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
[SF Ruby Conf 2025] Rails X
palkan
2
850
Transcript
検索の仕組みを知ってみよう ~入門編~ 2020
自己紹介 名前: yuki (twitter: @yuki_pnn) しがないエンジニア 趣味: たまに同人漫画のシナリオ書き バドミントン
検索使ってますか?
ブログ記事の一覧から 「特定の単語」が含まれているものを検索したい SNSで過去の投稿一覧から 「特定の単語」が含まれている投稿を検索したい 例えば… などなど
検索ってどう実装されているか知っていますか?
注意点 ・ここから先の話は説明のために簡略化をしています ・知っている人は生暖かく見守っていてください ・間違った説明をしているかもしれません 何か指摘があれば登壇終了後に指摘をお願いします💦
検索ってどんなロジックで動いているの? 知りたいですよね…? というわけで検索のアルゴリズムやデータ構造のお話です 全文検索のお話をします
検索でよく使うOSS elasticsearch ・多分検索エンジンの中で一番有名 ・いろんなところで使われている ・分散型の検索エンジンで大規模サービスにも耐えれる solrなんかも検索エンジンとして有名
実はコア部分に同じOSSが使われています 「Apache Lucene」(アパッチ ルシーン) ・OSSの全文検索エンジン/ライブラリ(Java) ・検索に必要な機能が色々詰まっているやつ ・大体これを使って検索エンジン/サーバを実装している Apache Projectの守備範囲広い…
今日は以下の機能について話していきます ・全文検索を支えるデータ構造 ・全文検索でのスコアリング方法 ・「もしかして◦◦?」のサジェストを実現するには?
シンプルな検索を考えてみる クエリ:「晴れ」 文書1:「今日の天気は雨」 文書2:「明日の天気は晴れ」 文書3:「明後日の天気は曇り」 これくらいなら文書全てを総当たりしてもよさそう
じゃあ文書の数が100万件あった場合は?
高速に単語を検索するアルゴリズムを使う? いい感じに検索しやすいデータ構造に変える?
「明日の天気は晴れ」 「明日」「天気」「晴れ」 単語分割(形態素解析 + ストップワード除去) ① 全文検索を支えるデータ構造: 転置インデックス 単語から文書を引けるようにする 今日 :文書1
明日 :文書2 明後日 :文書3 天気 :文書1, 文書2, 文書3 晴れ :文書2 曇り :文書3 雨 :文書1 ② これで単語から文章を探すのが簡単になる
文書は探せるけど表示する順番はどう決めるか? いい感じのスコアを決めたい
単純に考えると 長い文章の一部だとあんまり重要じゃなさそう? たまに出現する単語だとそこまで嬉しくないかも? 文章の主題に調べたい単語があれば嬉しいかも
計算式 tf-idf(単語i, 文章j) = tf(単語i, 文章j) ・idf(単語i) 全文検索でのスコアリング方法: TF-IDF 特定の文章内の単語がどれくらい重要か示す値
文章j内での単語iの出現回数 文章jのすべての単語の出現回数の和 tf(単語i, 文章j) = idf(単語i, 文章j) = 全ての文章数 単語iが出現する文章数 log ( )
転置インデックス (調べたい対象の文章) tf-idf Query 転置インデックス(データ構造)と tf-idf(スコアリング)を組み合わせて高速な検索を実現 実際はtf-idfを拡張したBM25を使ったりクエリをもう少し解析したりする
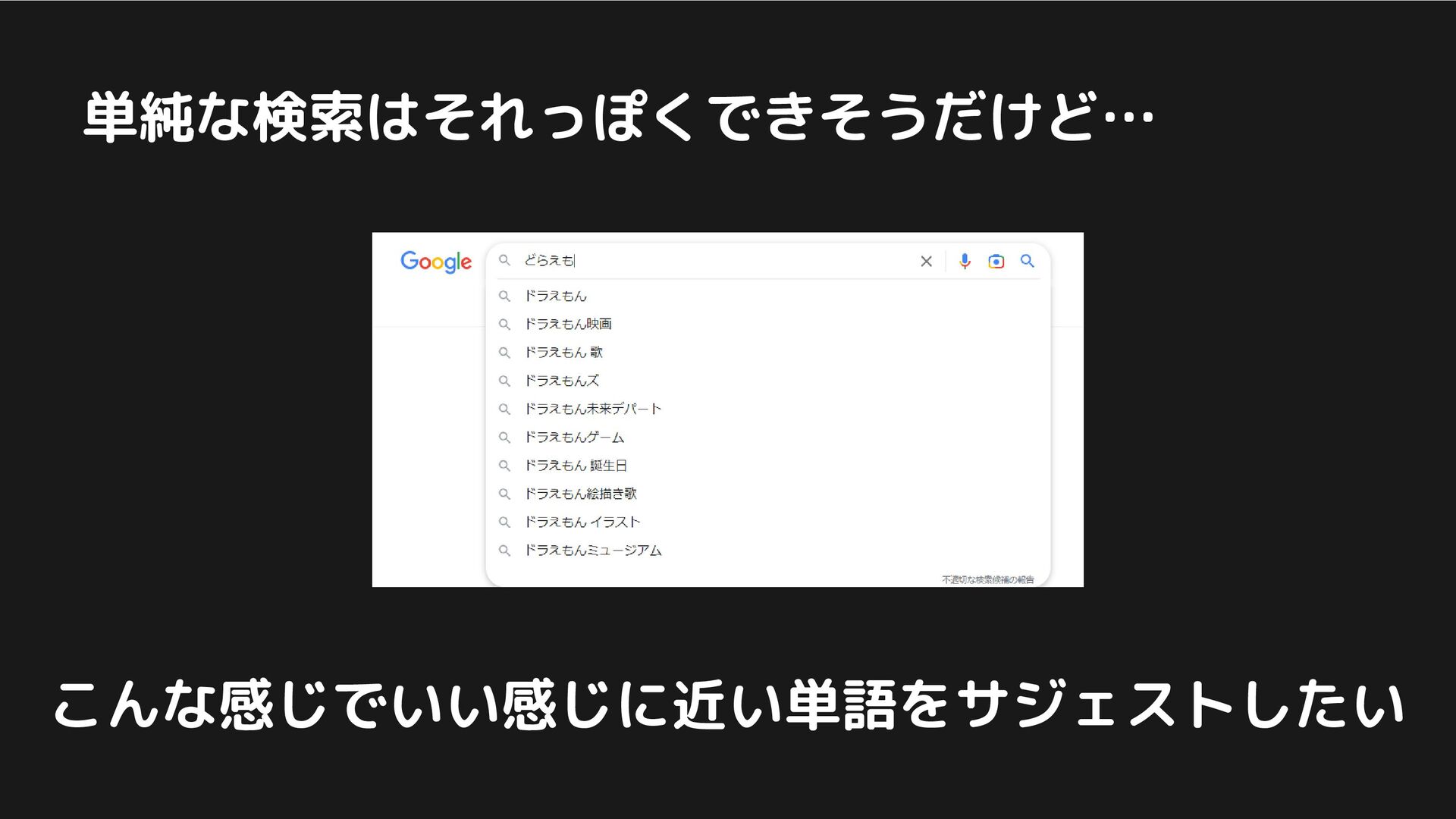
単純な検索はそれっぽくできそうだけど… こんな感じでいい感じに近い単語をサジェストしたい
その前に一つ重要な考え方(技術?)を紹介 nGram bi-gram tri-gram 等…
例えば「国土交通省」のような単語があった場合 bi-gram 「国土」「土交」「交通」「通省」 tri-gram 「国土交」「土交通」「交通省」 のように文字数で分割する
すごくざっくりな「もしかして検索」の実装方針 n-gramでクエリを分割する 転置インデックスに対してn-gramが含まれる単語を検索する ヒットした単語とクエリの文字列編集距離を計算しスコアとする スコアが最も高い単語を「もしかして?」と表示する 1. 2. 3. 4. 他にも細かいところはあるけど大体こんな感じ(なはず)
編集距離って? 単語iを別の単語jに変形するのに必要な最小手順数 例 「ハックバー」 「テックバー」 編集距離: 2 「スコップ」 「コップ」 編集距離:
1 Levenshtein Distanceなんかが有名 実際はjaro-winkler Distanceなんかが使われる
普段よく使う検索機能 実際に中の処理を見てみると奥が深い! 今回説明をしたのもかなり簡略化したもの…
興味があればいろいろと調べてみてください! 検索だけでなく身近にある機能も仕組みを 調べると面白いものが多いはず
まとめ ・(全文)検索を実現するために「転置インデックス」なる構造がある ・検索のスコアを決めるために「tf-idf(BM25)」などのアルゴリズムがある ・n-gramや編集距離を使って「もしかして検索」を実現d
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}