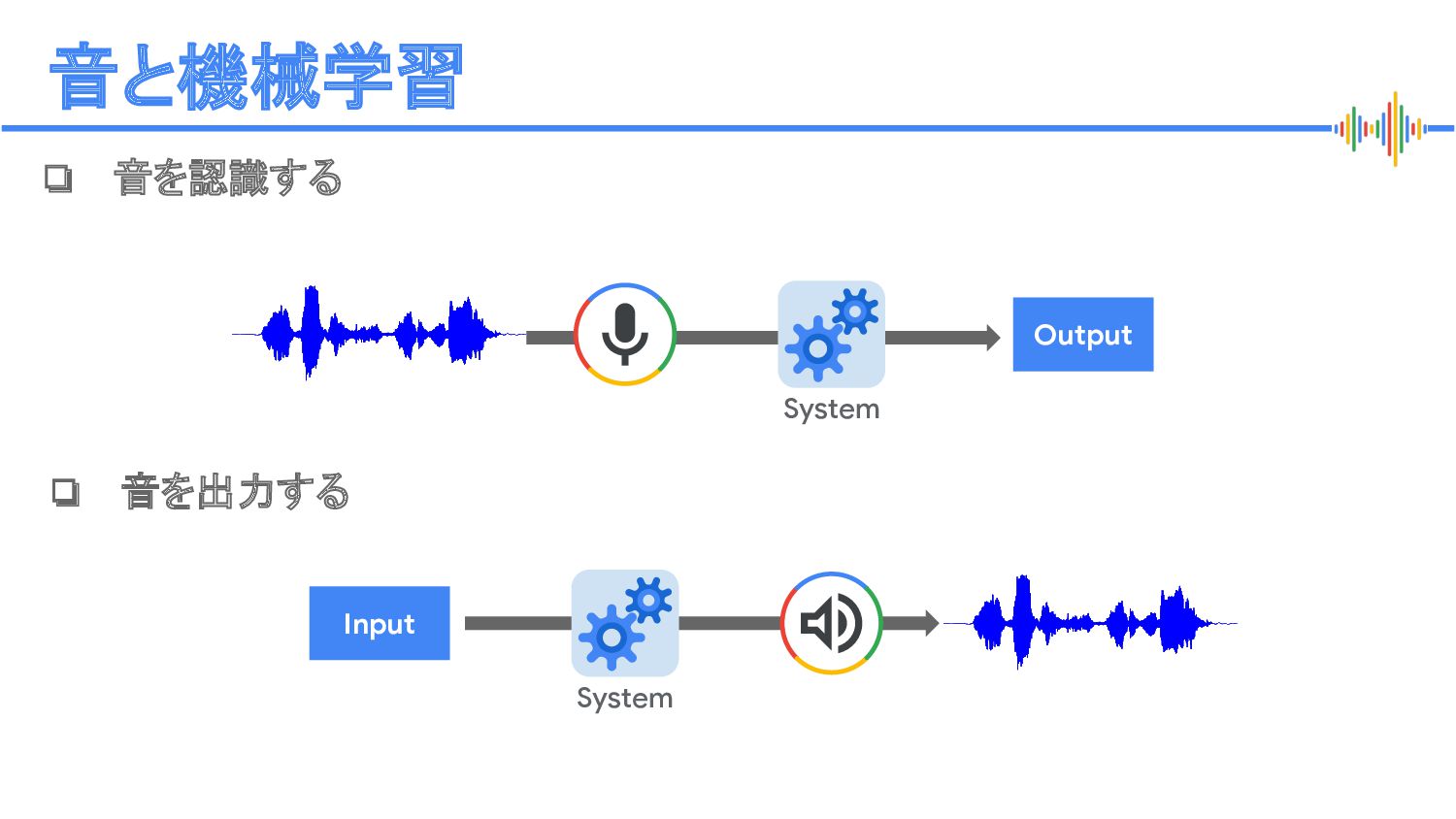
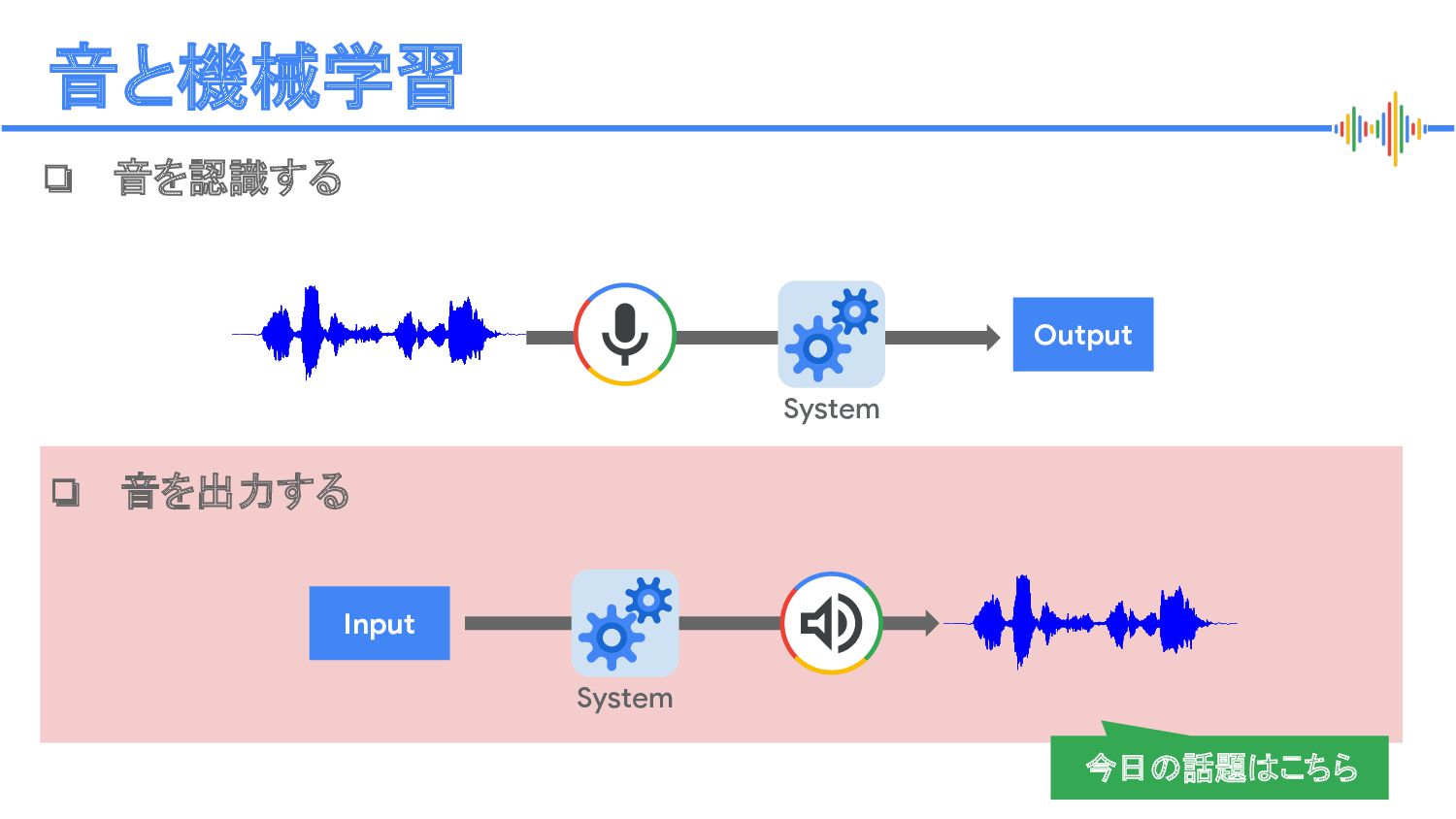
Speech-to-Speech Translation) System System Translatotron 2: High-quality direct speech-to-speech translation with voice preservation: https://google-research.github.io/lingvo-lab/translatotron2/
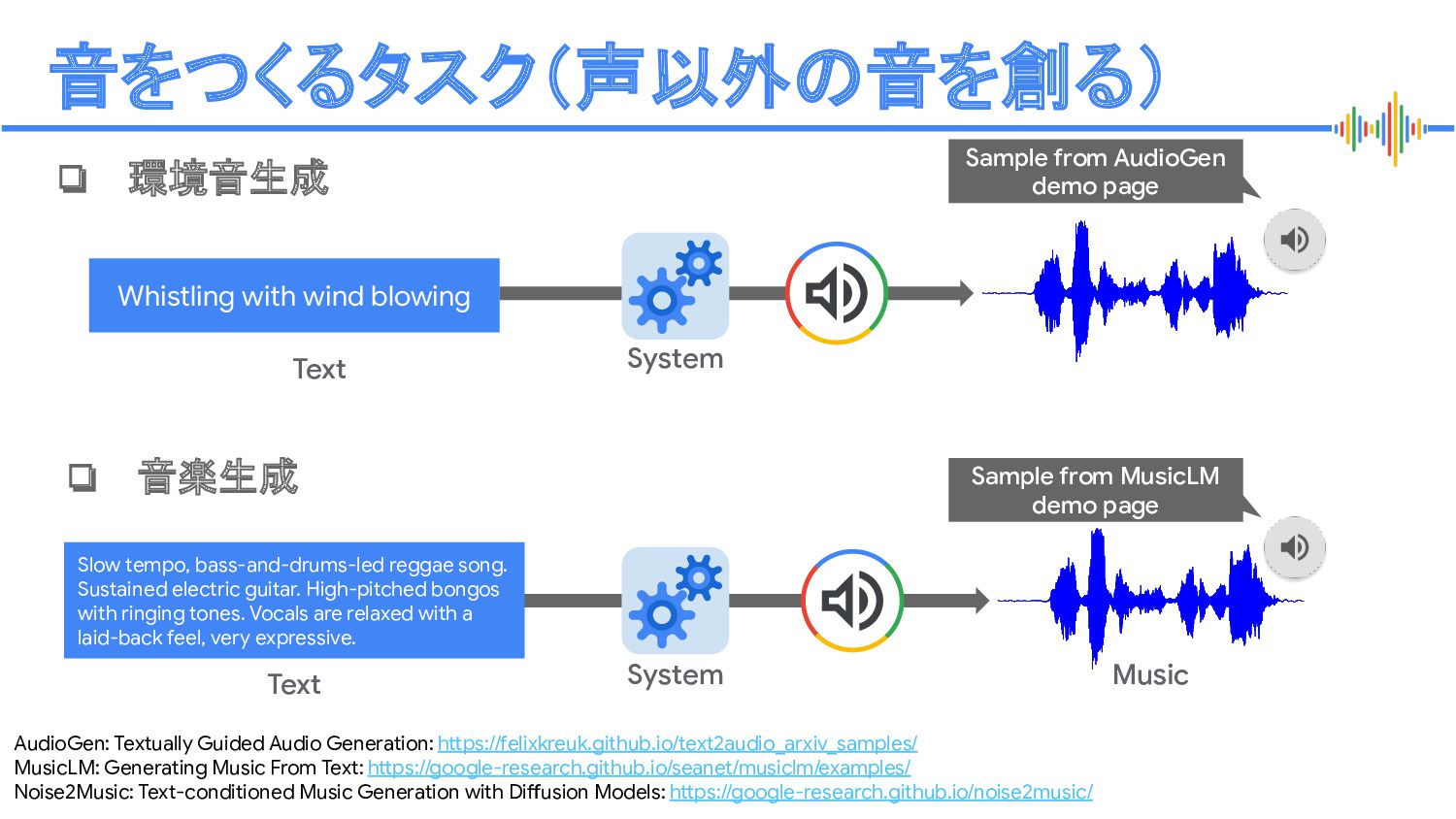
MusicLM: Generating Music From Text: https://google-research.github.io/seanet/musiclm/examples/ Noise2Music: Text-conditioned Music Generation with Diffusion Models: https://google-research.github.io/noise2music/ Whistling with wind blowing Text System Sample from AudioGen demo page ❏ 環境音生成 ❏ 音楽生成 System Music Slow tempo, bass-and-drums-led reggae song. Sustained electric guitar. High-pitched bongos with ringing tones. Vocals are relaxed with a laid-back feel, very expressive. Text Sample from MusicLM demo page
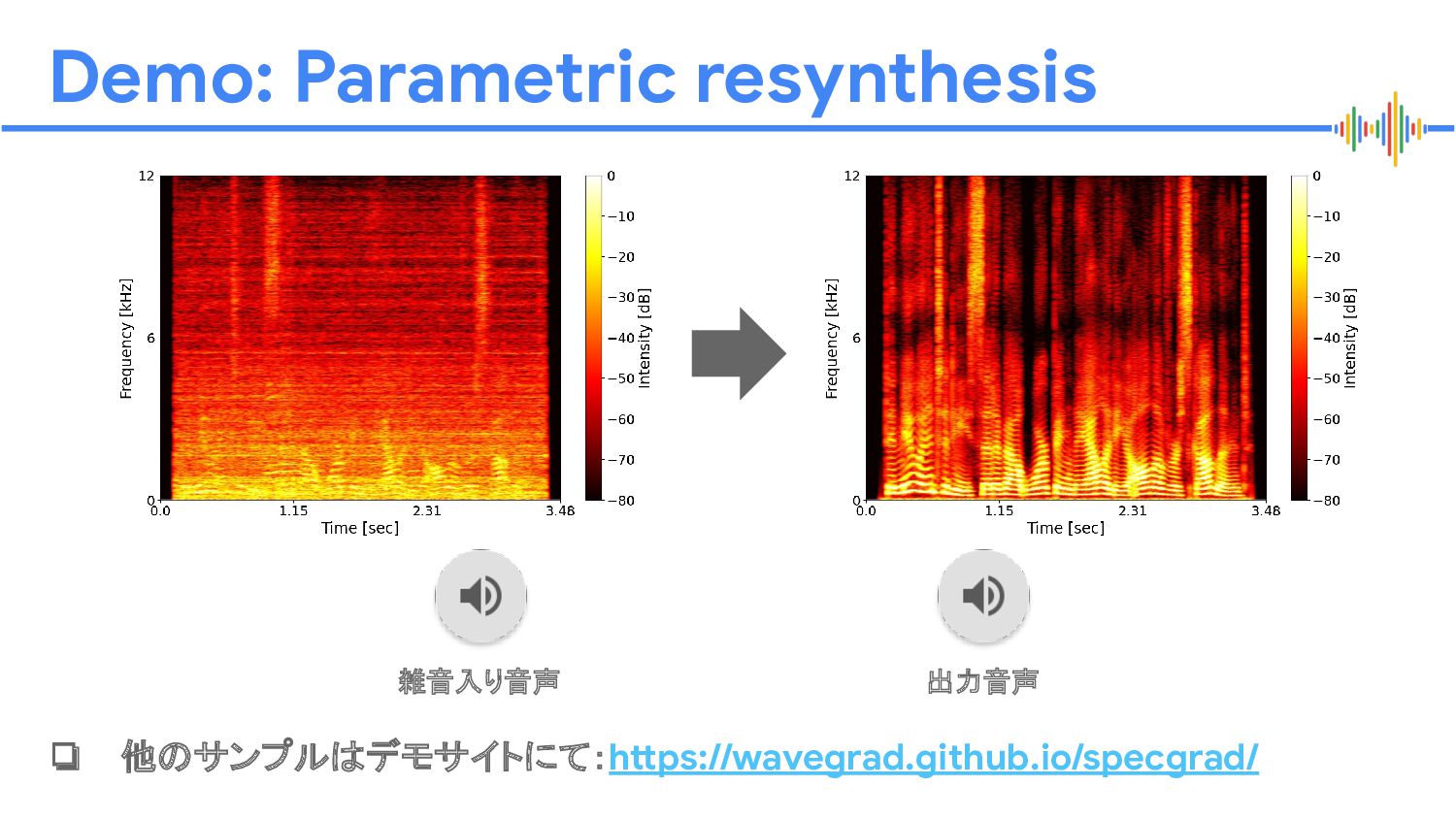
メルスペクトログラムク リーニング DNN 時間 メルスケール周波数 時間 メルスケール周波数 雑音混じりの音声の メルスペクトログラム 雑音のない音声の メルスペクトログラム S. Maiti and M. I. Mandel, “Parametric resynthesis with neural vocoders,” WASPAA, 2019
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Proprietary + Confidential DNN音響モデル [Zen+, 2013] ❏ Vocoder(波形生成信号処理)のパラメータ推定にDNNを利用 Text 波形生成](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_18.jpg){kind=link}
![Proprietary + Confidential WaveNet [Oord+, 2016] ❏ 波形生成を自己回帰型の CNN で実行する](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_19.jpg){kind=link}
![Proprietary + Confidential Tacotron2 [Shen+, 2018] ❏ テキスト解析を介さず、all neural network](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_20.jpg){kind=link}
![Proprietary + Confidential 例:音声強調 [Maiti+, 2019] 波形生成 DNN (neural vocoder)](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_21.jpg){kind=link}
![Proprietary + Confidential 例:音声翻訳 [Jia+, 2019/2022]など... 波形生成 DNN (neural vocoder)](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Proprietary + Confidential WaveGrad [Chen+, 2021] ❏ 拡散モデルを利用した最初の neural vocoder](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
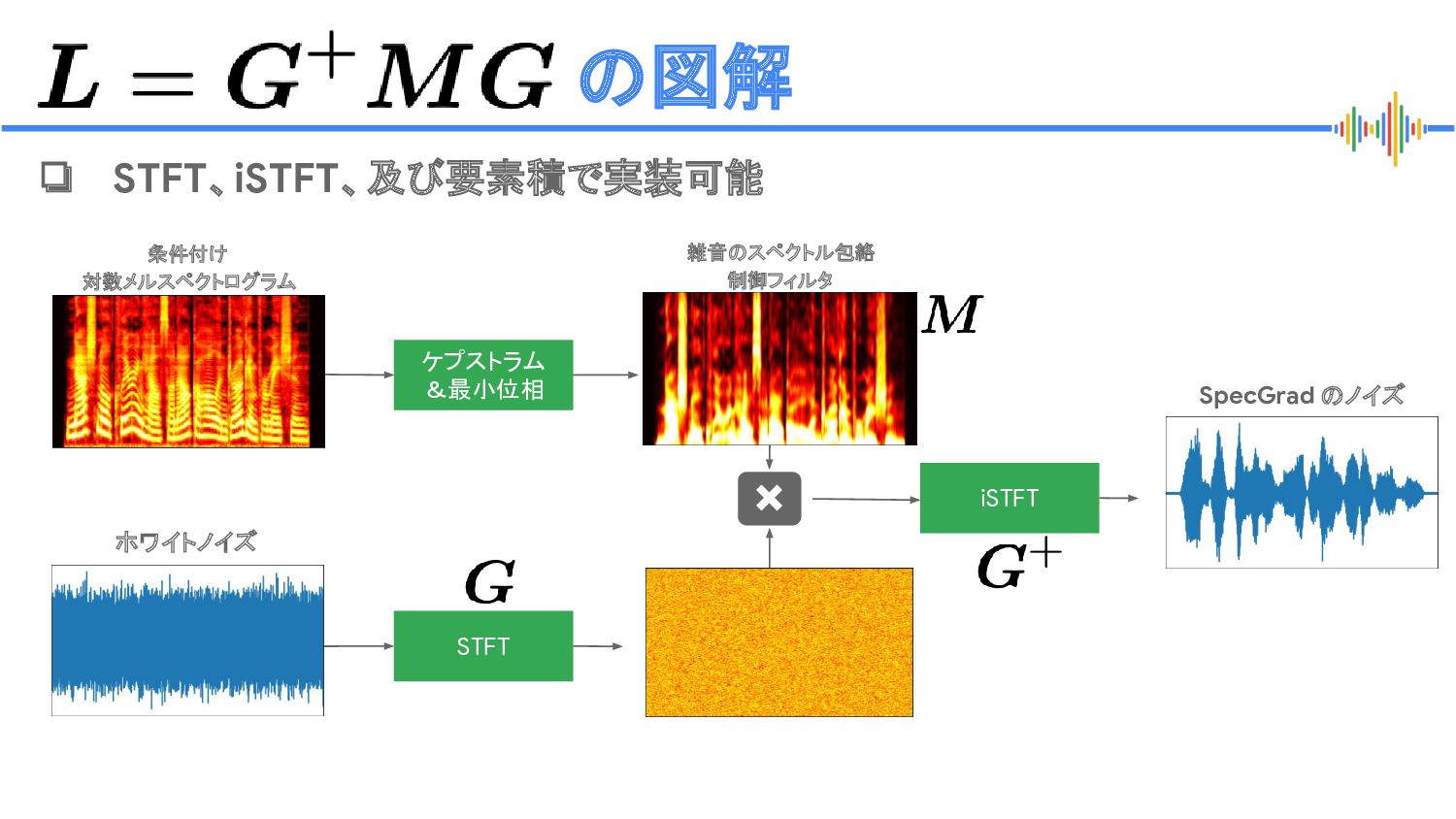
![Proprietary + Confidential SpecGrad [Koizumi+, 2022] ❏ 雑音のスペクトル包絡をログメルスペクトログラムから制御 N. Chen+,](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_32.jpg){kind=link}
![Proprietary + Confidential それはどういうことですか? ❏ 任意の共分散行列を持つ正規分布を利用することに相当 [†] N. Chen+, “WaveGrad:](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
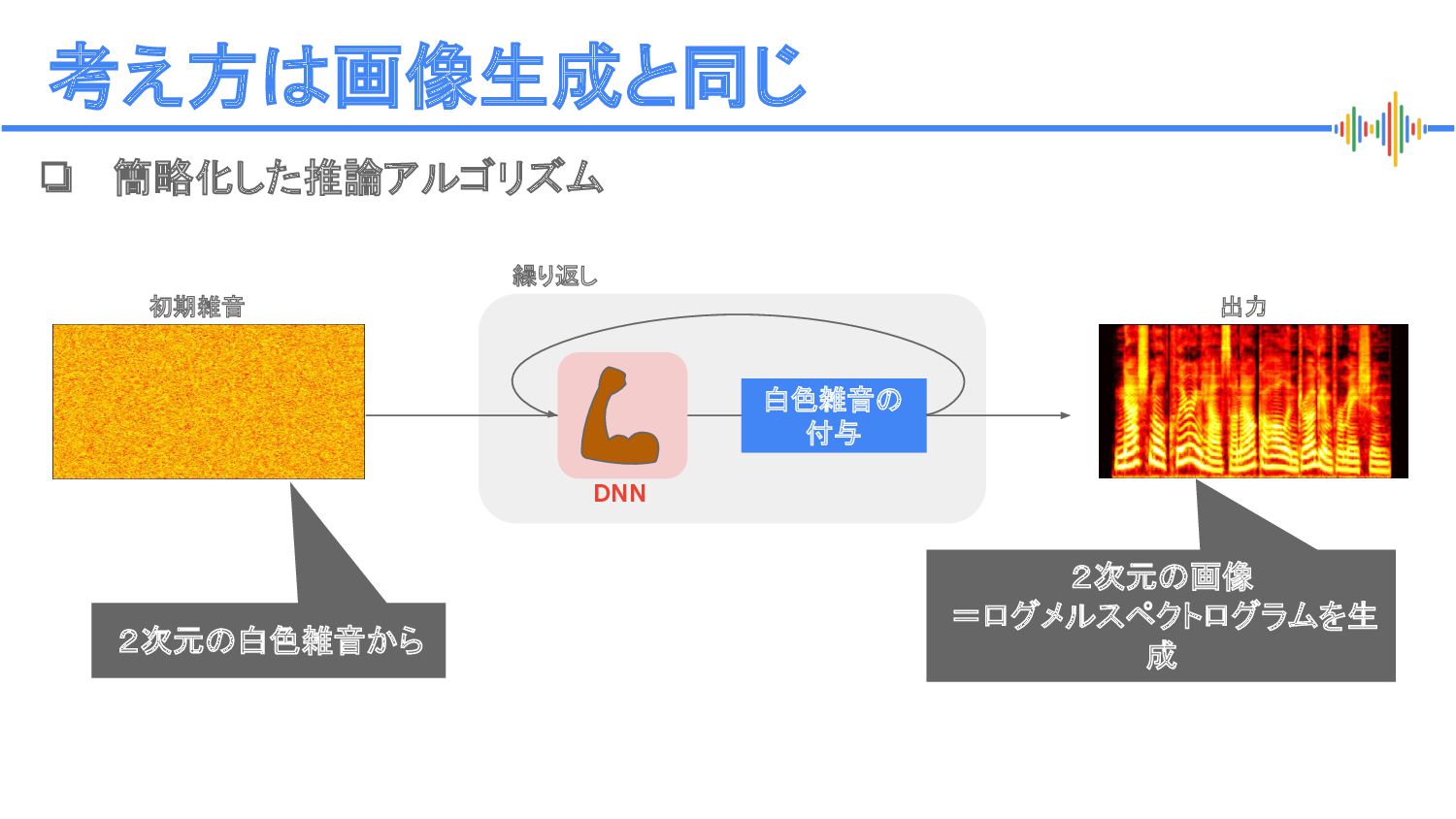{kind=link}
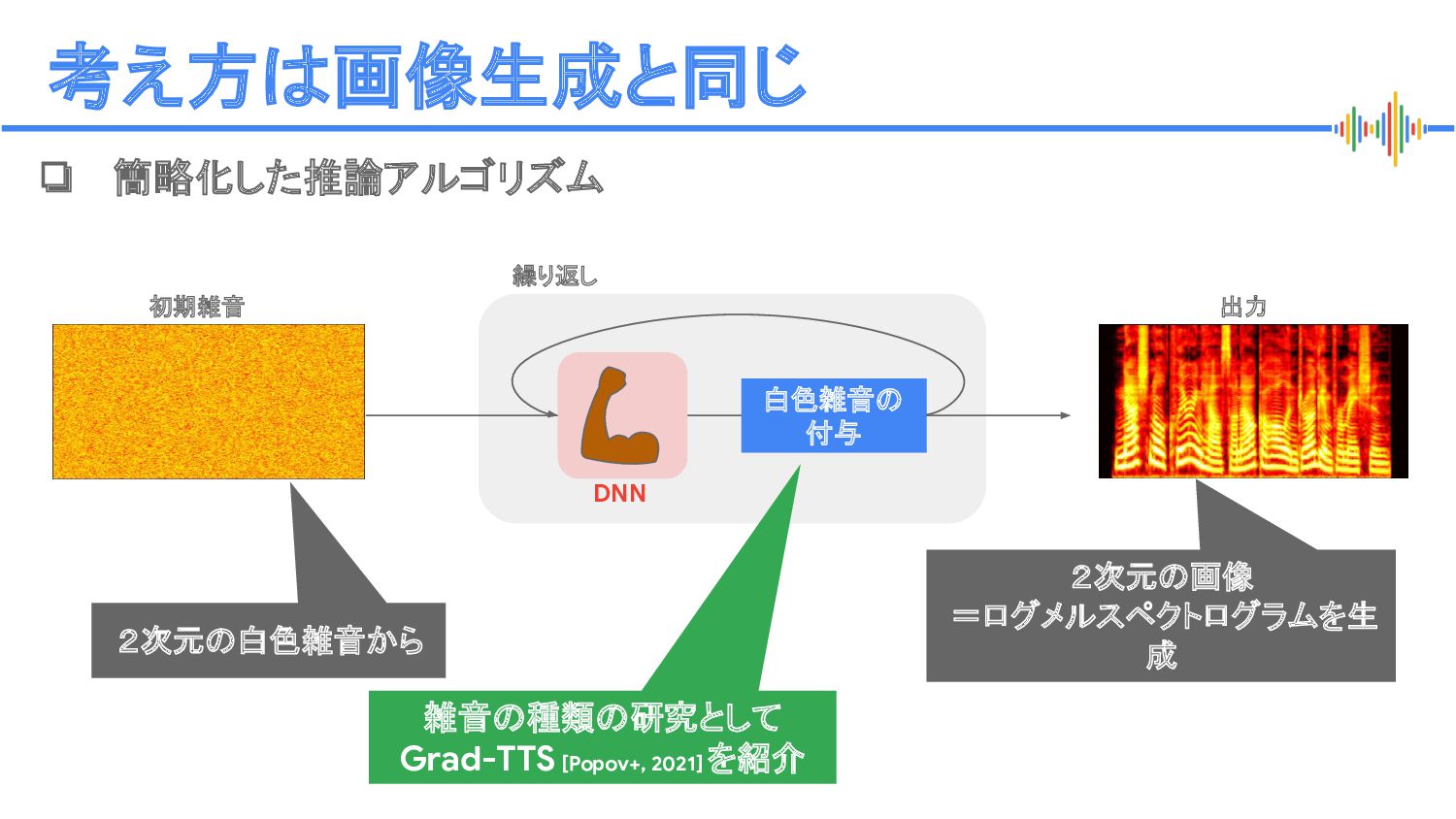{kind=link}
![Proprietary + Confidential GradTTS [Popov+, 2021] ❏ 拡散モデルを、ログメルスペクトログラムの精細化に利用 V. Popov+,](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_43.jpg){kind=link}
![Proprietary + Confidential GradTTS [Popov+, 2021] ❏ 拡散モデルを、ログメルスペクトログラムの精細化に利用 V. Popov+,](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_44.jpg){kind=link}
![Proprietary + Confidential GradTTS [Popov+, 2021] ❏ 拡散モデルを、ログメルスペクトログラムの精細化に利用 音声およびGIF アニメは](https://files.speakerdeck.com/presentations/9ded5d7b82fb48bdb2807649300184ac/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}