Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:What In-Context Learning “Learns” In-Conte...
Search
yuri
August 21, 2023
Research
650
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介:What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
yuri
August 21, 2023
More Decks by yuri
See All by yuri
データ指向モデリング「テキストマイニングの基礎」
yuri00
0
34
論文紹介:∞-former: Infinite Memory Transformer
yuri00
0
440
論文紹介:Learning Dependency-Based Compositional Semantics
yuri00
0
170
論文紹介:What Context Features Can Transformer Language Models Use?
yuri00
0
470
Other Decks in Research
See All in Research
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
Data Visualization Tools in the Age of AI
flekschas
0
170
Language and AI
ayaniwa
0
180
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
300
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
470
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
710
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
580
MM-OVSeg: Multimodal Optical–SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
satai
3
100
Harness Engineering and Al Agent
kzinmr
3
1.8k
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.3k
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
260624_NLP-colloquium: Hubness
de9uch1
1
150
Featured
See All Featured
Designing for humans not robots
tammielis
254
26k
Odyssey Design
rkendrick25
PRO
2
740
Google's AI Overviews - The New Search
badams
0
1.1k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Chasing Engaging Ingredients in Design
codingconduct
0
250
WCS-LA-2024
lcolladotor
0
770
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
Transcript
What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task
Learning Jane Pan, Tianyu Gao, Howard Chen, Danqi Chen ACL2023 Findings 村山 友理 東大和泉研 2023/08/27 第15回最先端NLP勉強会
事前学習したものを思い出してい るだけ? In-context learning は何をしているのか? 2 デモ(正しい入出力ペア)から学習 している?
• 事前学習時にダウンストリームで必要なタスクを暗黙的に学習していて、in-context のデモはどのタスクを解くべきかモデルに認識させるための情報を与えるだけ (Xie+ 22) • ICL性能は正解ラベルの使用に対してinsensitive (Min+ 22) 事前学習したものを思い出しているだけ?
3
• Transformer-based モデルは「内部モデル」を更新するために暗黙的に勾配降下 法を行っている可能性 (Akyürek+ 23), (vonOswald+ 22) • 実データセットの指標を用いると、ICLとファインチューニングには類似点がある
(Dai+ 23) デモから学習している? 4
ICLの能力を「タスク認識」と「タスク学習」に分解 5 事前学習したものを思い出してい るだけ? タスク認識 デモ(正しい入出力ペア)から学習 している? タスク学習 • それぞれの能力を評価するために、プロンプトのラベルを操作
• いろいろなモデルサイズとデモ数で実験
Random (= タスク認識) • ラベルは一様にランダムにサンプリングされる ラベル操作 1. Random 6
Abstract (=タスク学習) • プロンプトからタスク指示文を取り除き、ラベルを抽象的な記号に置換 ◦ 数字 (0, 1, 2,...) /
文字 (A, B, C,...) / 記号 (@, #, $, %, *, ∧,...) • 抽象的なラベルであっても事前学習のバイアスがある可能性 ◦ 例えば、“0”は負例っぽい ◦ バイアスを避けるために、プロンプト毎にラベルから抽象記号にランダムに写像 ラベル操作 2. Abstract 7
Gold (= タスク認識 + タスク学習) • 正解の入力・ラベルペアが与えられる従来のプロンプト ラベル操作 3. Gold
8
• データセット ◦ 4タイプのタスクに関する16の分類データセットを使用: ▪ 感情分析 ▪ 毒性検出 ▪ 自然言語推論
/ 言い換え検出 ▪ トピック / スタンス分類 • モデル ◦ GPT-3 (Brown+ 20) ▪ ada (350M), babbage (1.3B), curie (6.7B), davinci (175B) (OpenAI API) ◦ LLaMA (Touvron+ 23) ▪ 7B, 13B, 33B, 65B ◦ OPT (Zhang+ 22) ▪ 350M, 2.7B, 6.7B, 13B, 30B, 66B (Transformers library) 実験設定 9
• タスク設定 ◦ テスト用に訓練セットからデモをサンプリング ▪ GPT-3: 150 対(予算の都合により) ▪ OPT,
LLaMA: 1,350 対 ◦ 分類タスクのタイプ毎に3種類のプロンプト雛形を用意 ◦ データセットとプロンプト全体の平均を報告 実験設定 10
• Gold (= タスク認識 + タスク学習) ◦ 全体的に一番良い • Random
(= タスク認識) ◦ 性能はスケールに依らずほぼ 横ばい • Abstract (= タスク学習) ◦ モデルサイズとデモ数に応じて 増加 ◦ 小さなモデル、少ないデモ数で はRandomより低いが、パラ メータ数・デモ数が増えると逆転 ◦ LLaMA-65B以外のOPT-66Bと davinciはGOLDに匹敵 結果 11 ※ Abstractについては数字ラベルの結果
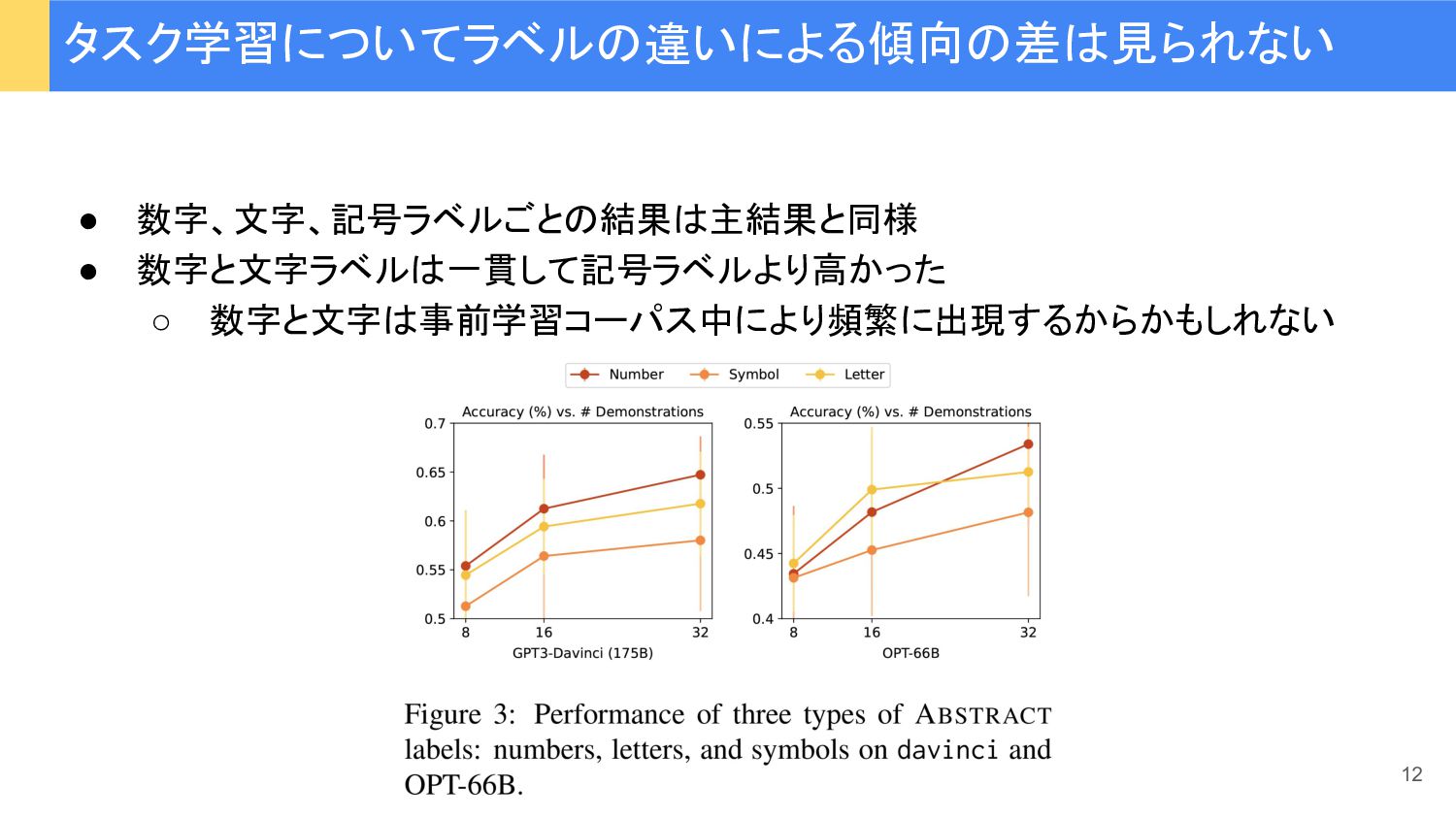
• 数字、文字、記号ラベルごとの結果は主結果と同様 • 数字と文字ラベルは一貫して記号ラベルより高かった ◦ 数字と文字は事前学習コーパス中により頻繁に出現するからかもしれない タスク学習についてラベルの違いによる傾向の差は見られない 12
• 感情分析とNLIを比較 • NLIのAbstract曲線がより平らなので、プロンプトと事前学習の質が重要 タスク学習ではタスクが単純な方がサイズとデモ数にスケールする 13
タスクのタイプ別の結果 14 感情分析 トピック / スタンス分類 毒性検出 NLI / 言い換え検出
GPT-3 LLaMA OPT
• ICLを2つの能力「タスク認識」と「タスク学習」に分解し、それぞれ異なる条件下で 発現することを示した • 小さなモデルでもタスク認識の能力はあるが、スケールしない • タスク学習の能力は大きなモデルで現れる ◦ 小さなモデルではデモを増やしても性能が上がらない ◦
大きなモデルはデモが増えると性能も向上 • Limitations ◦ 「タスク認識」と「タスク学習」に分けたが、タスク学習がデモで示されたパター ンを事前学習で学習した概念に代替しているとすれば、タスク認識の進化形と 捉えることもできるかもしれない まとめ 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}