Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:∞-former: Infinite Memory Transformer
Search
yuri
September 20, 2022
Research
440
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介:∞-former: Infinite Memory Transformer
第14回最先端NLP勉強会(2022年9月26日、27日)@お茶大 発表用資料
yuri
September 20, 2022
More Decks by yuri
See All by yuri
データ指向モデリング「テキストマイニングの基礎」
yuri00
0
34
論文紹介:What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
yuri00
0
650
論文紹介:Learning Dependency-Based Compositional Semantics
yuri00
0
170
論文紹介:What Context Features Can Transformer Language Models Use?
yuri00
0
470
Other Decks in Research
See All in Research
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
280
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.5k
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
310
Language and AI
ayaniwa
0
180
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
130
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
470
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
400
「AIとWhyを深堀る」をAIと深堀る
iflection
0
530
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.7k
Featured
See All Featured
Being A Developer After 40
akosma
91
590k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Building Adaptive Systems
keathley
44
3.1k
The Cult of Friendly URLs
andyhume
79
7k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
550
The World Runs on Bad Software
bkeepers
PRO
72
12k
Visualization
eitanlees
152
17k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Between Models and Reality
mayunak
4
380
Transcript
∞-former: Infinite Memory Transformer Pedro Henrique Martins, Zita Marinho, André
F. T. Martins ACL 2022 お茶大 村山友理
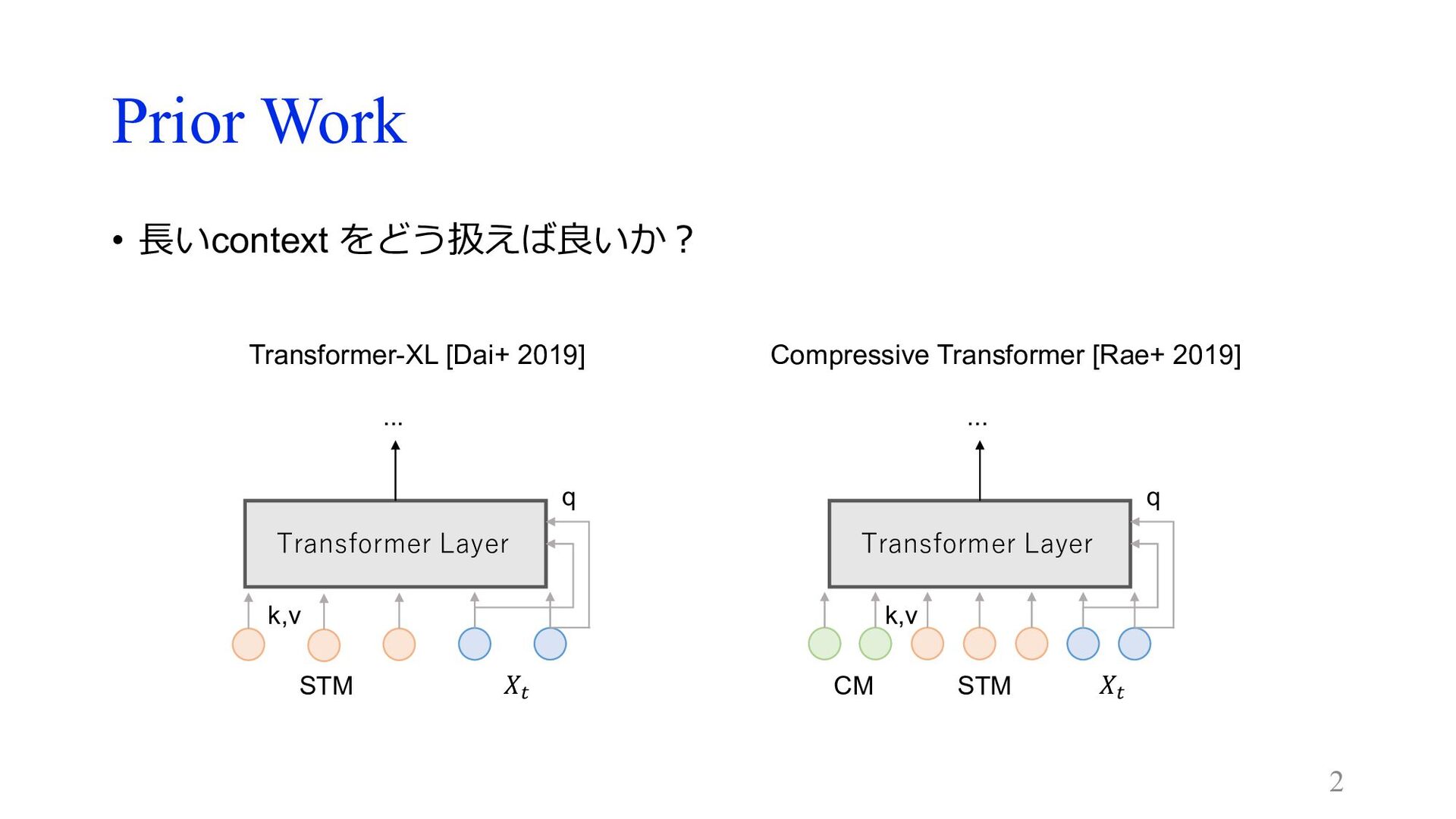
Prior Work • ⻑いcontext をどう扱えば良いか︖ 2 Transformer Layer 𝑋! STM
q k,v ... Transformer Layer 𝑋! STM CM q k,v ... Compressive Transformer [Rae+ 2019] Transformer-XL [Dai+ 2019]
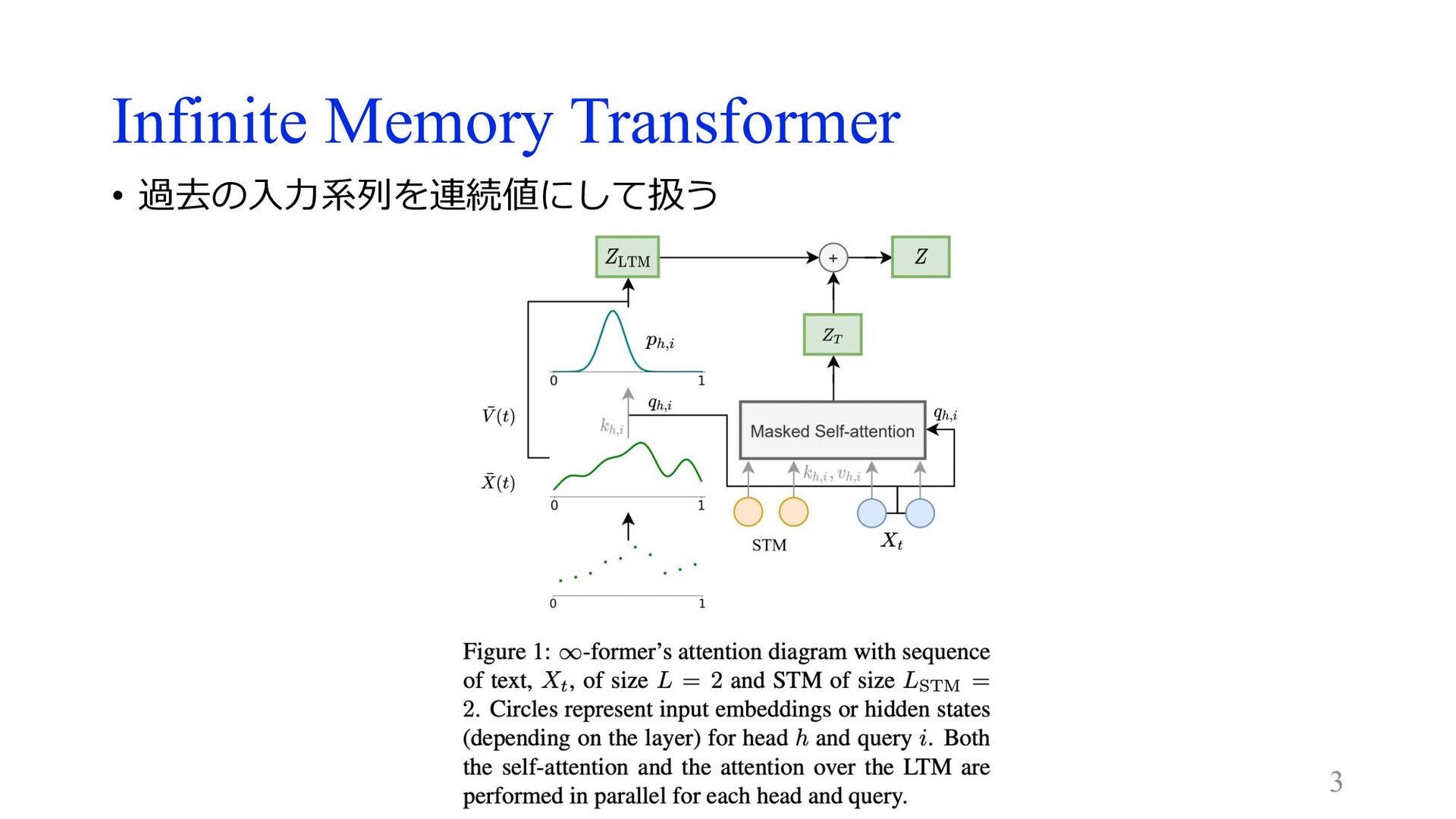
Infinite Memory Transformer • 過去の⼊⼒系列を連続値にして扱う 3
Long-term Memory • ⼊⼒Xに畳み込み(stride=1, width=3)をし、スムージングを⾏う Lはinput size, eはembedding size •
Xを連続値 ! 𝑋(𝑡)に変換 𝑡 ∈ 0, 1 : 𝑡! = 𝑖/𝐿 𝜓 𝑡 ∈ ℝ"はN個のRBF (radial basis function) のベクトル B ∈ ℝ"×$は多変量リッジ回帰によって得られる係数⾏列 4
Long-term Memory 𝑄 = 𝑋𝑊" ∈ ℝ#×% 𝐾 = 𝐵𝑊&
∈ ℝ'×% 𝑉 = 𝐵𝑊( ∈ ℝ'×% • attention mechanism としてガウス分布を⽤いる 5
Long-term Memory • 𝑧),+ は𝑍#,-,) ∈ ℝ#×.の⾏を成す • Transformerのcontext vector
𝑍, と⾜し合わせて最終的なcontext vector 𝑍を得る 6 ← attention × value
Unbounded Memory 7 • ! 𝑋(𝑡)を圧縮 • ! 𝑋(𝑡)から𝑀個のベクトルを等間隔にサンプリング
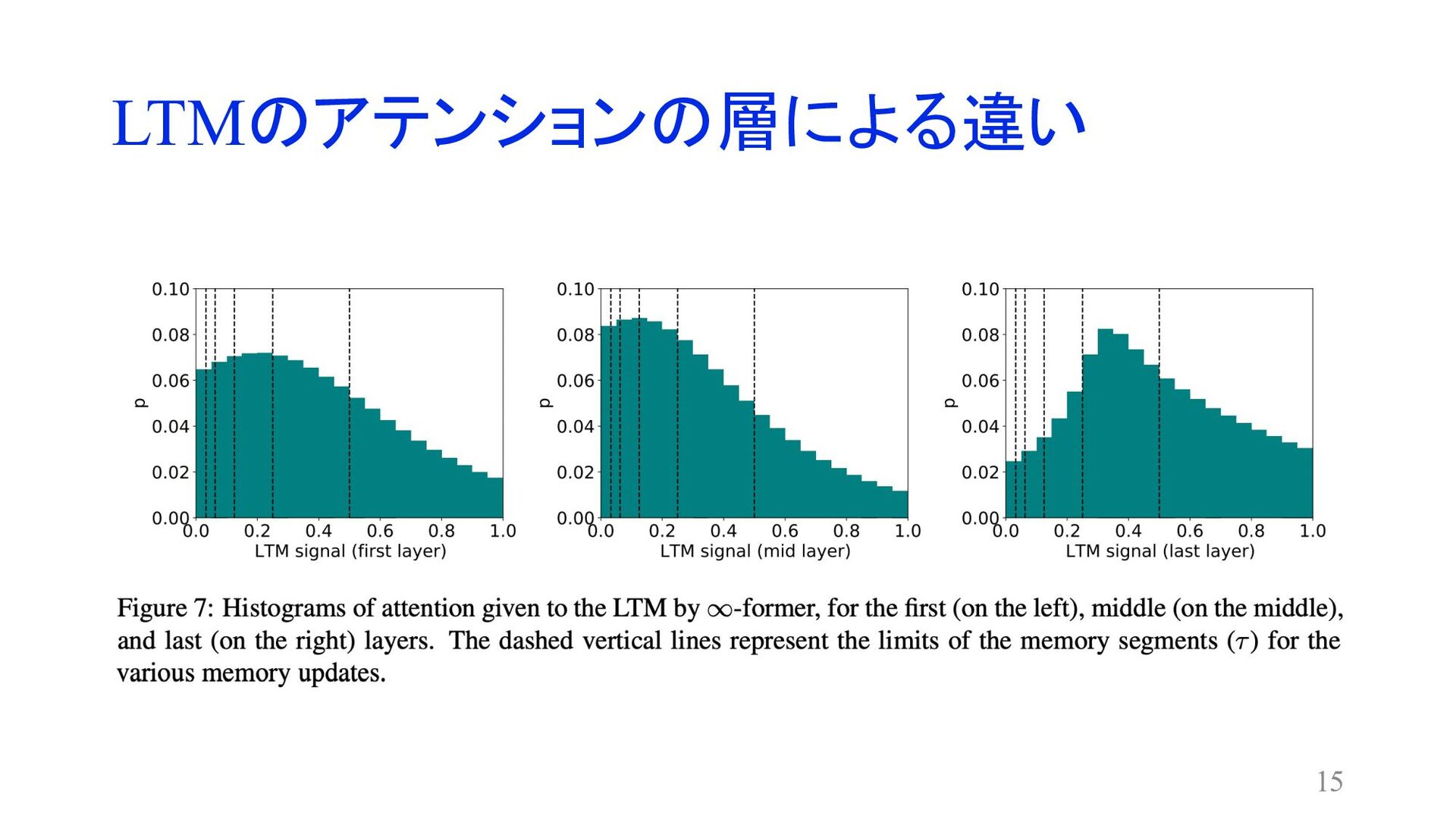
Sticky Memories • 重要な部分のメモリを積極的に保存したほうが良いのでは︖ • 前ステップのattentionからヒストグラムを作成し、D個の等間隔なbinに分割 {𝑑/, … , 𝑑0}
• 各binについてattention probability 𝑝(𝑑1 )を計算 • 𝑝に従ってM個をサンプリング 8
Complexity • Key matrix 𝐾 は基底関数の数𝑁 だけに依存し、contextの⻑さとは無関係 • Complexityもcontextの⻑さとは独⽴ •
short-term memory も使う場合︓ • LTMのみの場合︓ • どちらもvanilla transformer より⼩さい 9
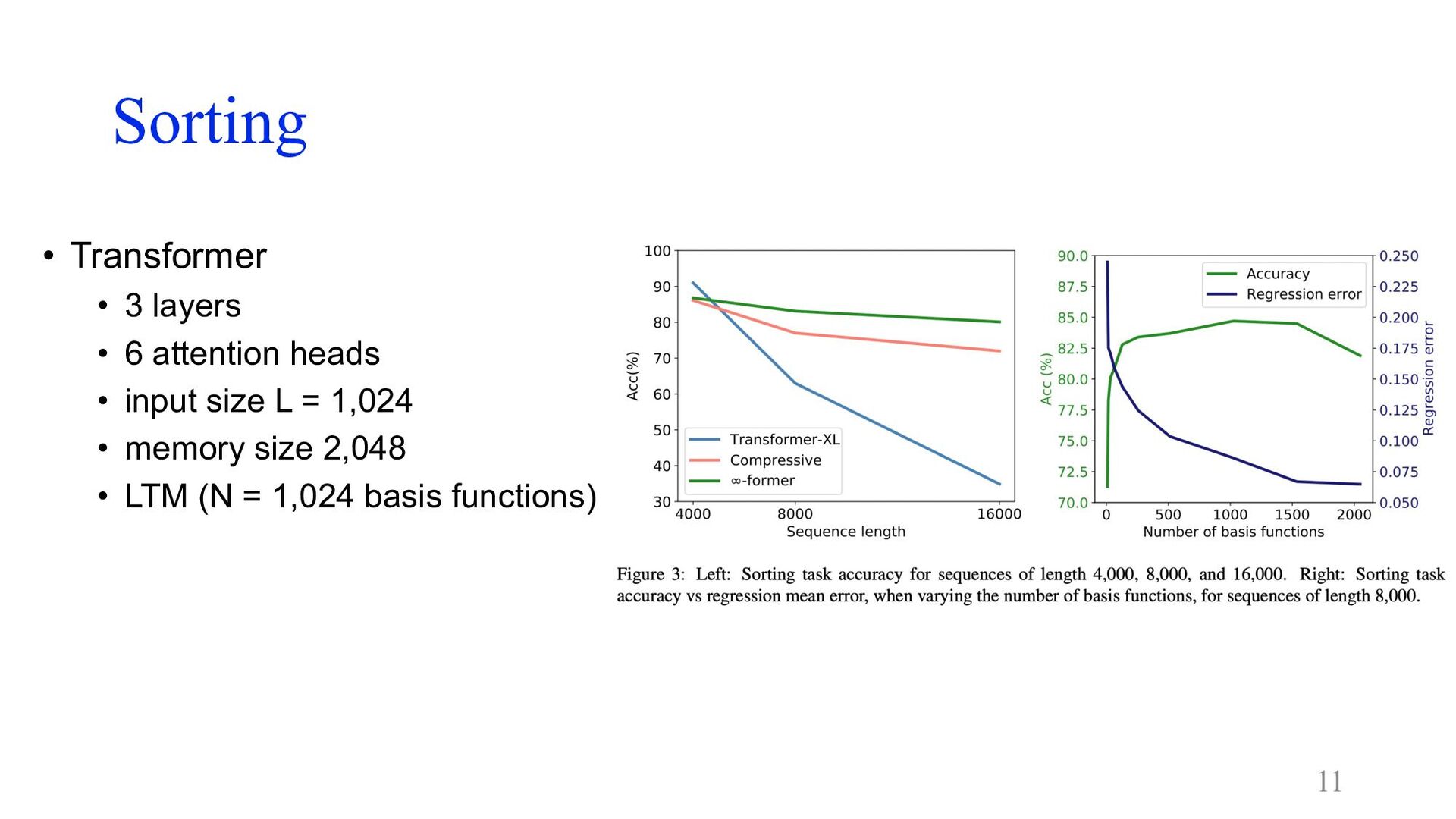
Sorting • 系列のトークンを頻度順に並べる • モデルが直近のトークンだけでなく⻑期記憶も⾒ているか調べるために、 トークンの確率分布を変化させていく • 系列が⻑くなるほど𝛼 ∈ [0,1]は0から1に徐々に増加
• vocabulary size 20 • 4,000, 8,000, 16,000トークンで実験 10
Sorting • Transformer • 3 layers • 6 attention heads
• input size L = 1,024 • memory size 2,048 • LTM (N = 1,024 basis functions) 11
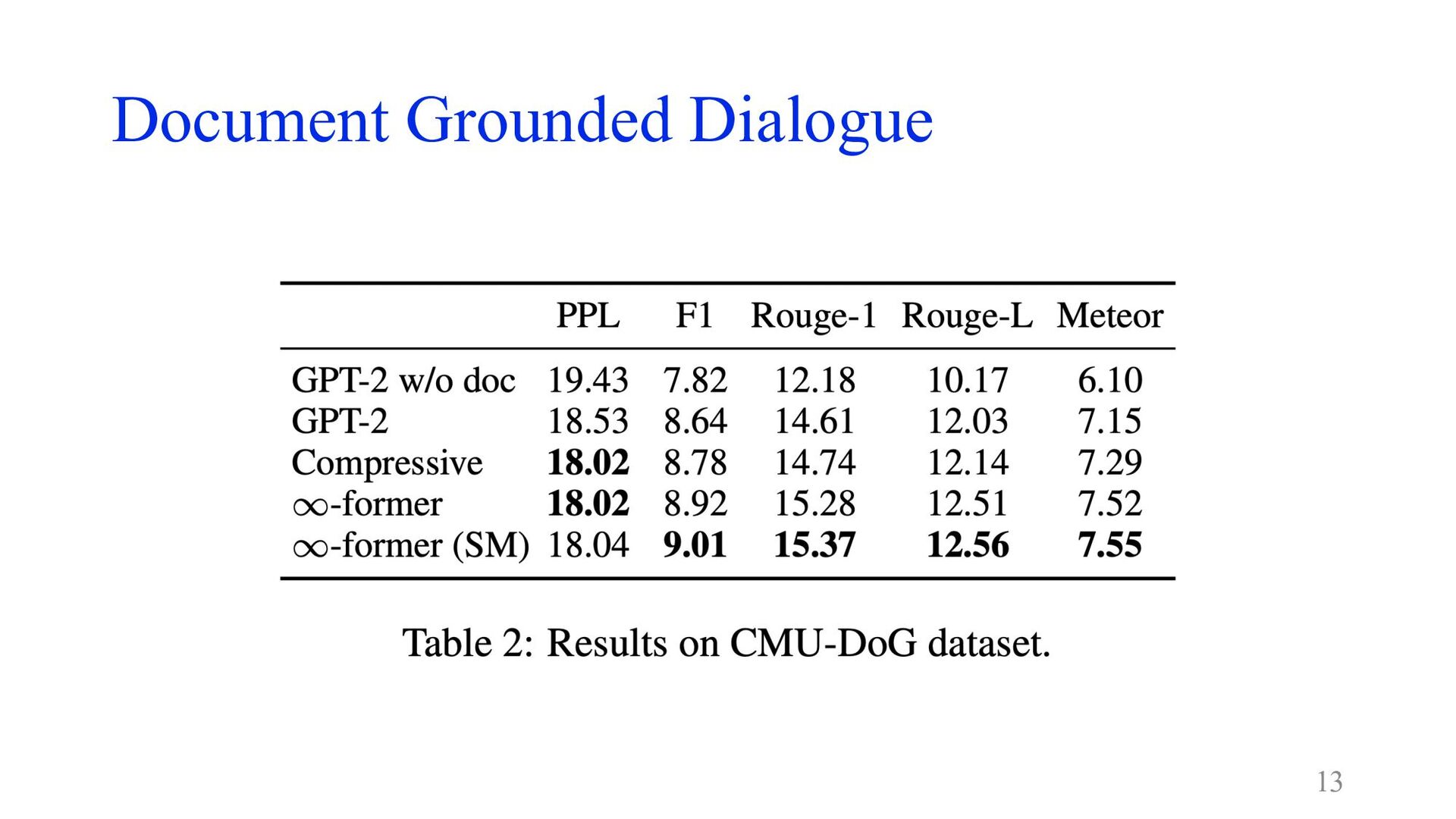
Document Grounded Dialogue • CMU Document Grounded Conversation dataset (CMU-DoG)
[Zhou+ 2018] • より難しくするために、会話が始まる前にしかdocumentにアクセスできなくする • GPT-2 small + continuous LTM (N = 512 basis functions) 12
Document Grounded Dialogue 13
Document Grounded Dialogue 14
LTMのアテンションの層による違い 15
16
17
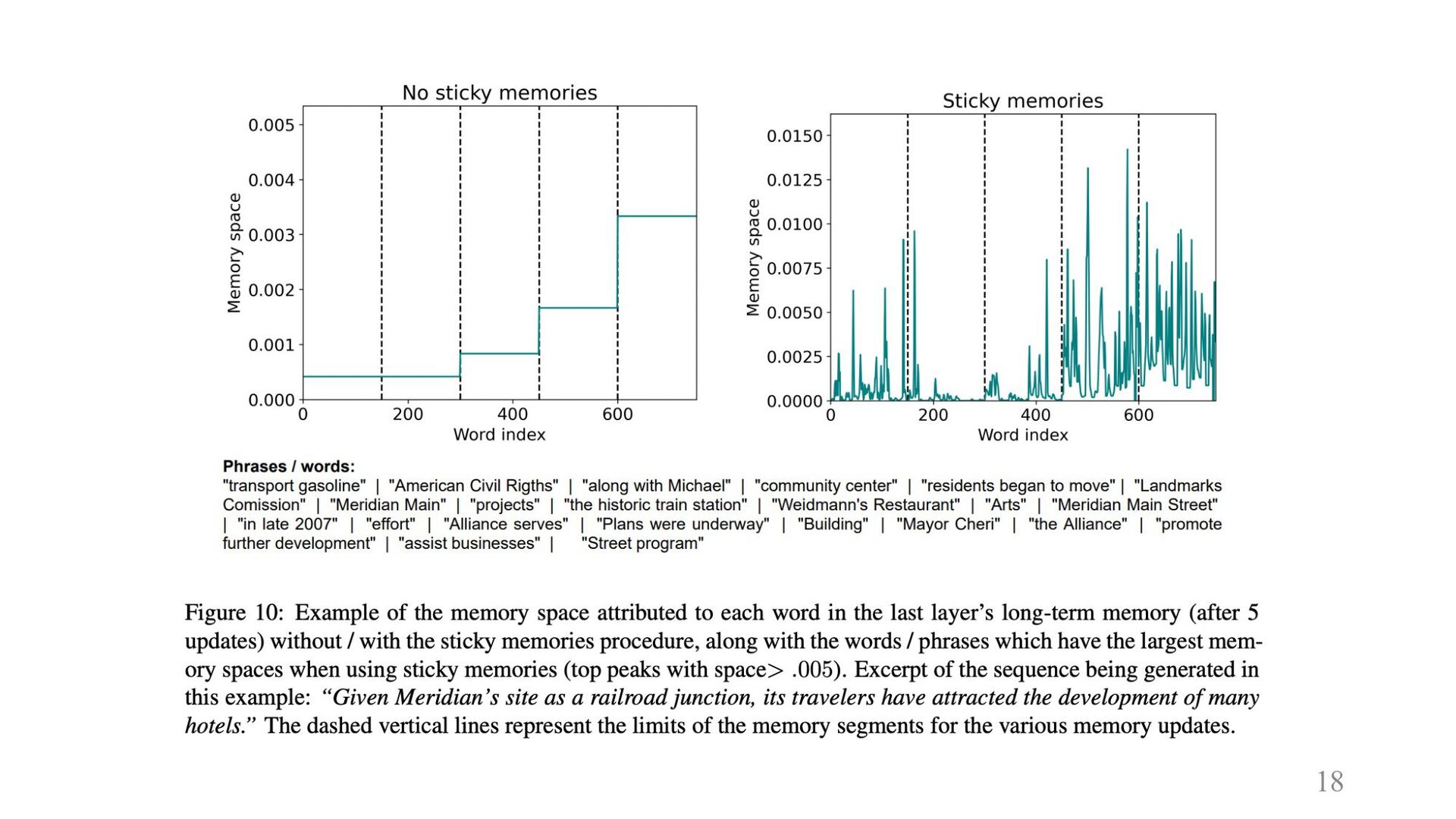
18
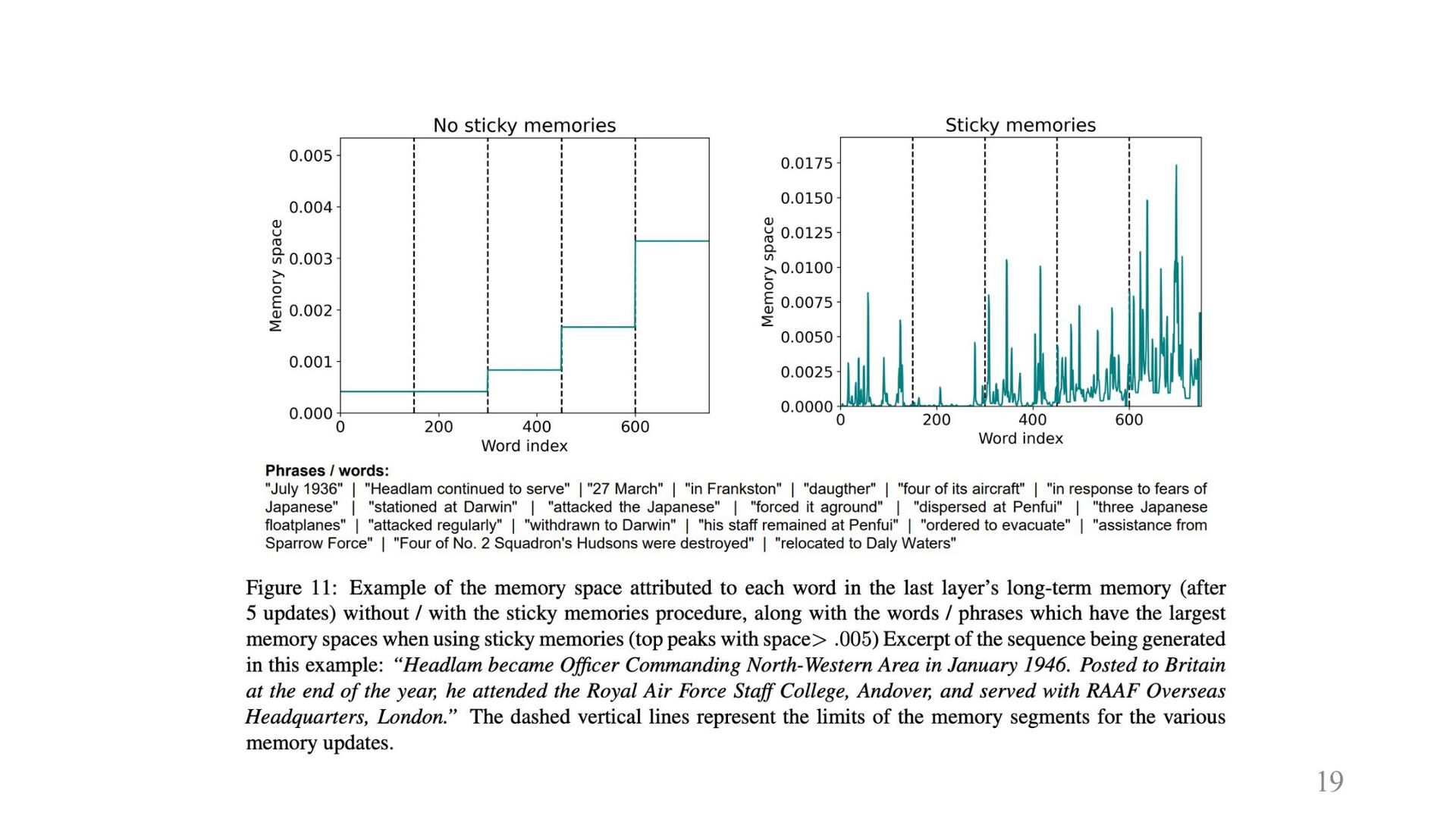
19
まとめ • Infinite Memory Transformer を提案 • Unbounded context •
計算量はcontextの⻑さと独⽴ • Sorting, Language modeling, Document grounded dialogue で実験 • ⻑期記憶の有⽤性を⽰した 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sorting • 系列のトークンを頻度順に並べる • モデルが直近のトークンだけでなく⻑期記憶も⾒ているか調べるために、 トークンの確率分布を変化させていく • 系列が⻑くなるほど𝛼 ∈ [0,1]は0から1に徐々に増加](https://files.speakerdeck.com/presentations/f290c7a292524520a803a7e1eb035490/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}