以下の講演やセミナーで選択+更新して使用してきました!
・東北大学 乾・鈴木研究室 みちのく情報伝達学セミナー, 2019/01/25.
・人工知能学会 言語・音声理解と対話処理研究会(SLUD)第84回研究会, 2018/11/21.
・中部大学 藤吉弘亘教授 総監修 深層学習の基礎と最新動向~画像認識・音声認識・自然言語処理による深層学習とその融合、生成、強化学習, 2018/10/30.
・NLP若手の会 (YANS) 第13回シンポジウム, 2018/8/28.
・精密工学会 画像応用技術専門委員会(IAIP), 2018/7/13.
・情報処理学会 IPSJ-ONE, 2018/3/15.
・情報処理学会 コンピュータビジョンとイメージメディア研究会(CVIM), 2018/3/2.
・映像情報メディア学会 冬季大会, 2017/12/13.
・画像符号化シンポジウム(PCSJ) / 映像メディア処理シンポジウム(IMPS), 2017/11/22.
・中部大学 藤吉弘亘教授 総監修 深層学習の基礎と最新動向~画像認識・音声認識・自然言語処理による深層学習とその融合、生成、強化学習, 2017/11/21.
・ABEJA Technopreneur College, 2017/06/30.
・電子情報通信学会総合大会 企画講演セッション「もっと知りたい! Deep Learning 〜基礎から活用ノウハウ,応用まで〜」, 2017/03/22.
SlideShare(https://www.slideshare.net/YoshitakaUshiku/deep-learning-73499744)上にあった資料をお引越し+更新させました。
画像キャプション生成については (https://www.slideshare.net/YoshitakaUshiku/ss-57148161) により詳細な説明を譲りますが、画像×言語の研究に関する日本語資料としての網羅的をより高めるように試みた資料です。
{kind=link}
{kind=link}
{kind=link}
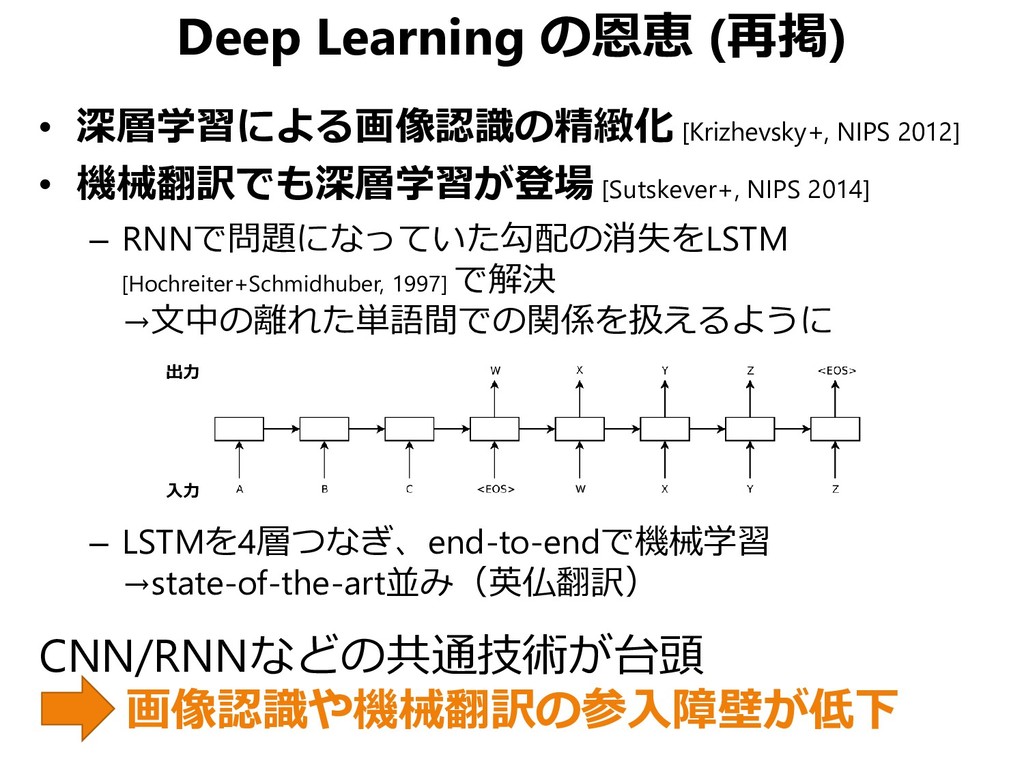
![2011 2012 2014 電話音声認識のエラー率が 30%程度→20%以下に [Seide+, InterSpeech 2011] 大規模画像分類のエラー率が 25%程度→15%程度に](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![入力 出力 Deep Learning の影響 • 機械翻訳でも深層学習が登場 [Sutskever+, NIPS 2014]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_7.jpg){kind=link}
{kind=link}
![Vision and Language の萌芽的な研究 記事付き画像へのキャプション生成 [Feng+Lapata, ACL 2010] • Input:](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ビジュアル質問応答 [Fukui+, EMNLP 2016]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![再利用アプローチもいまだに健在 その後も継続して新規手法が提案されている • 正準相関分析の利用[Hodosh+, JAIR 2013][Gong+, ECCV 2014] • 文章要約技術の応用[Mason+Charniak,](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_25.jpg){kind=link}
![マルチキーフレーズ推定アプローチ 当時の問題=使用候補であるフレーズの精度が悪い キーフレーズを独立なラベルとして扱うと… マルチキーフレーズの推定=一般画像認識 文生成は[Ushiku+, ACM MM 2011]と同じ [Ushiku+, ACM](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_26.jpg){kind=link}
{kind=link}
![深層学習登場以前の動画×言語 • 言語と動画内の物体とのグラウンディング [Yu+Siskind, ACL 2013] – 動画とその動画を説明する文のみから学習 – 対象物体が少なく、コントロールされた小規模デー](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
![Google NIC [Vinyals+, CVPR 2015] Googleで開発された • GoogLeNet [Szegedy+, CVPR](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_31.jpg){kind=link}
![生成された説明文の例 [https://github.com/tensorflow/models/tree/master/im2txt]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_32.jpg){kind=link}
![[Ushiku+, ACM MM 2012]と比べると 入力画像 [Ushiku+, ACM MM 2012]では: Fisher](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_33.jpg){kind=link}
{kind=link}
![ところが最近では… • CNNで事物の認識まで済ませてRNNで文生 成[Wu+, CVPR 2016][You+, CVPR 2016] →画像特徴量の段階でRNNに渡すより高性能! •](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_35.jpg){kind=link}
![Deep Learning による動画キャプション生成 • LRCN [Donahue+, CVPR 2015] – CNN+RNN](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_36.jpg){kind=link}
{kind=link}
![どれがどれくらい良いキャプションなのか? CoSMoS [Ushiku et al., ICCV 2015] Group of people](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_38.jpg){kind=link}
{kind=link}
![データセット Webからクロールしてきたもの • SBU Captioned Image [Ordonez+, NIPS 2011] 100万枚のFlickr画像、1キャプション/画像](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![精度の発展:「行って帰ってくる損失」 • 機械学習 出力キャプション→入力画像を再推定 cf. CycleGAN[Zhu+, ICCV 2017] 変分自己符号化器 [Pu+,](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_46.jpg){kind=link}
![精度の発展:アテンションモデル • 2分野が融合して新たに生まれたものの例: – アテンションモデルの利用 [Xu+, ICML 2015] – 画像+キャプションデータのみからの学習!](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![問題の発展:より細かいキャプション生成 [Lin+, BMVC 2015] [Johnson+, CVPR 2016]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![問題の発展:主観的な表現 感性語Sentiment Termを重視したキャプション生成 ニュートラルな文 ポジティブな文 (生成した例) [Mathews+, AAAI 2016][Shin+, BMVC](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![他言語への展開 データセット • IAPR TC12 [Grubinger+, 2006] 20,000画像+英独 • Multi30K](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_59.jpg){kind=link}
{kind=link}
![英語でない画像キャプション生成 多くは英語のキャプションを生成するが… • 日本語 [Miyazaki+Shimizu, ACL 2016] • 中国語 [Li+,](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_61.jpg){kind=link}
![単にデータ集めを頑張るだけ? 他言語での知識を流用 [Miyazaki+Shimizu, ACL 2016] • 他言語の視覚-言語グラウンディングの転移 • 少数のキャプション付き画像でも効率よく学習 an](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_62.jpg){kind=link}
{kind=link}
![言語横断型の研究 画像は機械翻訳の精度に寄与[Calixto+,2012] • 英語でsealとあるけど、 ・stampに近いsealなのか? ・sea animalのsealなのか? がわからず誤ったポルトガル語に翻訳 • (実験してないけど)画像があれば防げるはず!](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_64.jpg){kind=link}
![入力:言語Aのキャプション+画像 • 画像を介した言語横断キャプション翻訳 [Elliott+, 2015] [Hitschler+, ACL 2016] – 最初に候補翻訳を複数生成(画像には非依存)](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_65.jpg){kind=link}
![入力:言語Aのキャプション • 画像を介した言語横断関連文書検索 [Funaki+Nakayama, EMNLP 2015] • ゼロ対訳コーパスでのマルチモーダル翻訳 [Nakayama+Nishida, 2017]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_66.jpg){kind=link}
{kind=link}
![Visual Question Answering (VQA) 最初はユーザインタフェース分野で注目 • VizWiz [Bigham+, UIST 2010]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![その後の展開:統合方法 「統合された表現ベクトル+ 」の工夫 • VQA [Antol+, ICCV 2015] :そのまま直列に並べる •](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_73.jpg){kind=link}
![その後の展開:アテンション • 2017年SOTA [Anderson+, CVPR 2018] – これまで:Top-down領域の 画像にアテンション –](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![EmbodiedQA 質問応答のために探索が必要な問題 著者自らがその後、階層的な方策を獲得するA3C ベースの強化学習を提案 [Das+, CoRL 2018] [Das+, CVPR 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_79.jpg){kind=link}
{kind=link}
![その他にも… • QuAC [Choi+, EMNLP 2018] – Question Answering in](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
![その他にも… • Visual Discriminative Question Generation [Li+, ICCV 2017] ペアになっている画像に](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_84.jpg){kind=link}
{kind=link}
![キャプションを入力して画像を生成 文から鮮明な画像の生成を実現 ↑難しいタスク (下は[Mansimov+, ICLR 2016]の例) ※ 画像の切り貼りは以前から [Hays+Efros, SIGGRAPH](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_86.jpg){kind=link}
![文からの画像生成=条件つき生成 まずは…Generative Adversarial Networks (GAN) [Goodfellow+, NIPS 2014] • 条件を持たない生成学習手法](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_87.jpg){kind=link}
![文からの画像生成=条件つき生成 まずは…Generative Adversarial Networks (GAN) [Goodfellow+, NIPS 2014] • 条件を持たない生成学習手法](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_88.jpg){kind=link}
![文からの画像生成=条件つき生成 まずは…Generative Adversarial Networks (GAN) [Goodfellow+, NIPS 2014] • 条件を持たない生成学習手法](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_89.jpg){kind=link}
![文からの画像生成=条件つき生成 まずは…Generative Adversarial Networks (GAN) [Goodfellow+, NIPS 2014] • 条件を持たない生成学習手法](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_90.jpg){kind=link}
![文からの画像生成=条件つき生成 まずは…Generative Adversarial Networks (GAN) [Goodfellow+, NIPS 2014] • 条件を持たない生成学習手法](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_91.jpg){kind=link}
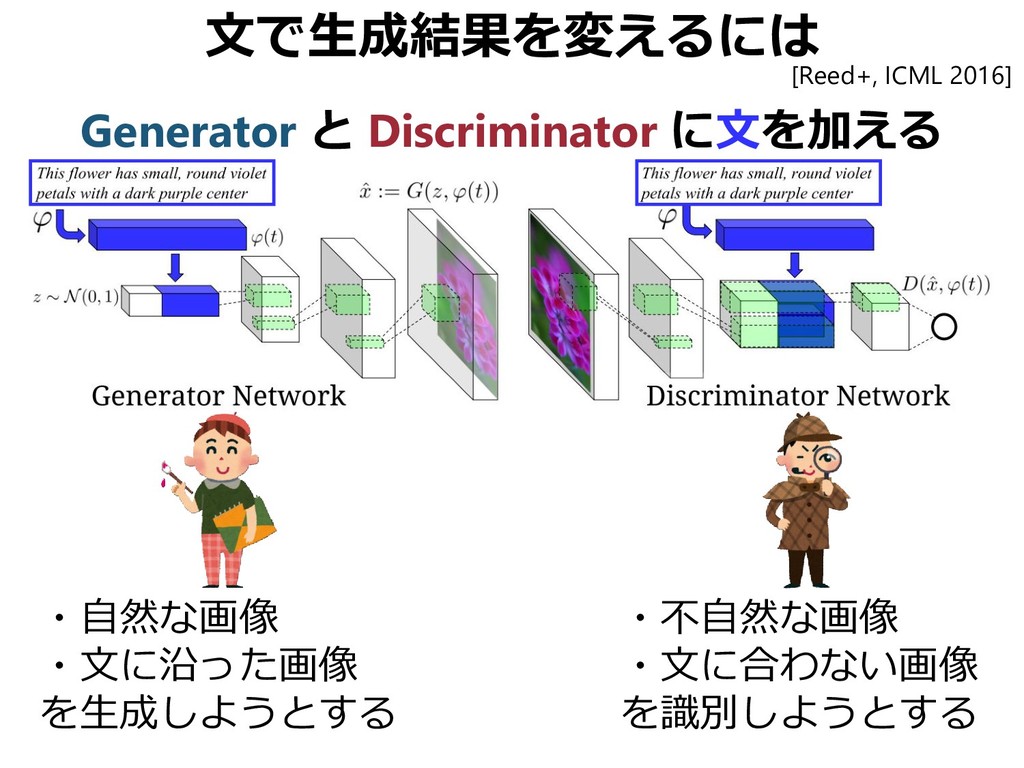{kind=link}
{kind=link}
![その後の展開 StackGAN [Zhang+, ICCV 2017] • 2段階のGANからなるモデル • 1段目でぼやっとした画像を生成、2段目で高解像+詳細化](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_94.jpg){kind=link}
{kind=link}
{kind=link}
![キャプションからの動画生成 [Marwah+, ICCV 2017] digit 6 is moving up and](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_97.jpg){kind=link}
{kind=link}
![Vision-Aware Dialog エージェントとユーザー以外に視覚的な情報が存在 研究を大別すると… • データセットの提供 VisDial [Das+, CVPR 2017]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_99.jpg){kind=link}
{kind=link}
{kind=link}
![紹介するデータセット一覧 • GuessWhat?! [de Vries+, CVPR 2017] • Visual Dialog](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_102.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Vision-and-Language Navigation (VNL) 対話行為が移動とナビゲーション [Anderson+, ICCV 2017]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_108.jpg){kind=link}
![R2R データセット 実世界3次元データ [Chang+, 3DV 2017] を利用 • 90の建造物で総計10,800点のパノラマRGBD画像を収集 •](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_109.jpg){kind=link}
{kind=link}
{kind=link}
![Multimodal Dialog (MMD) 商品推薦を伴うマルチモーダル対話 [Saha+, AAAI 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_112.jpg){kind=link}
![Multimodal Dialog (MMD) の概要 [Saha+, AAAI 2018] • Shopper –](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_113.jpg){kind=link}
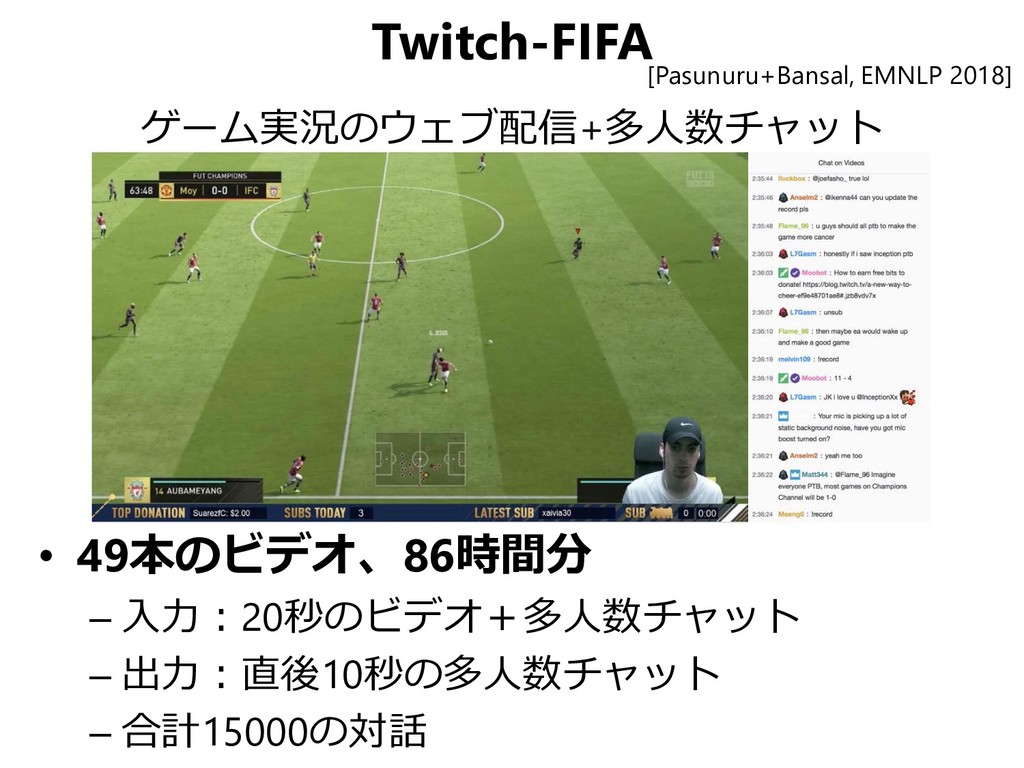{kind=link}
{kind=link}
![その他にも… • Image-Grounded Conversation [Mostafazadeh+, IJCNLP 2017] – VisDialはVQAベース No](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_116.jpg){kind=link}
![その他にも… • Image-Grounded Conversation [Mostafazadeh+, IJCNLP 2017] – VisDialはVQAベース –](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_117.jpg){kind=link}
![その他にも… • DialEdit [Ramesh+, 2018] • Video Scene-Aware Dialog Data](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_118.jpg){kind=link}
{kind=link}
![目的の一覧 • Vision-Awareな対話をモデル化したい →VisDial [Das+, CVPR 2017]など • CVの既存/新規な問題を対話的に解きたい –](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_120.jpg){kind=link}
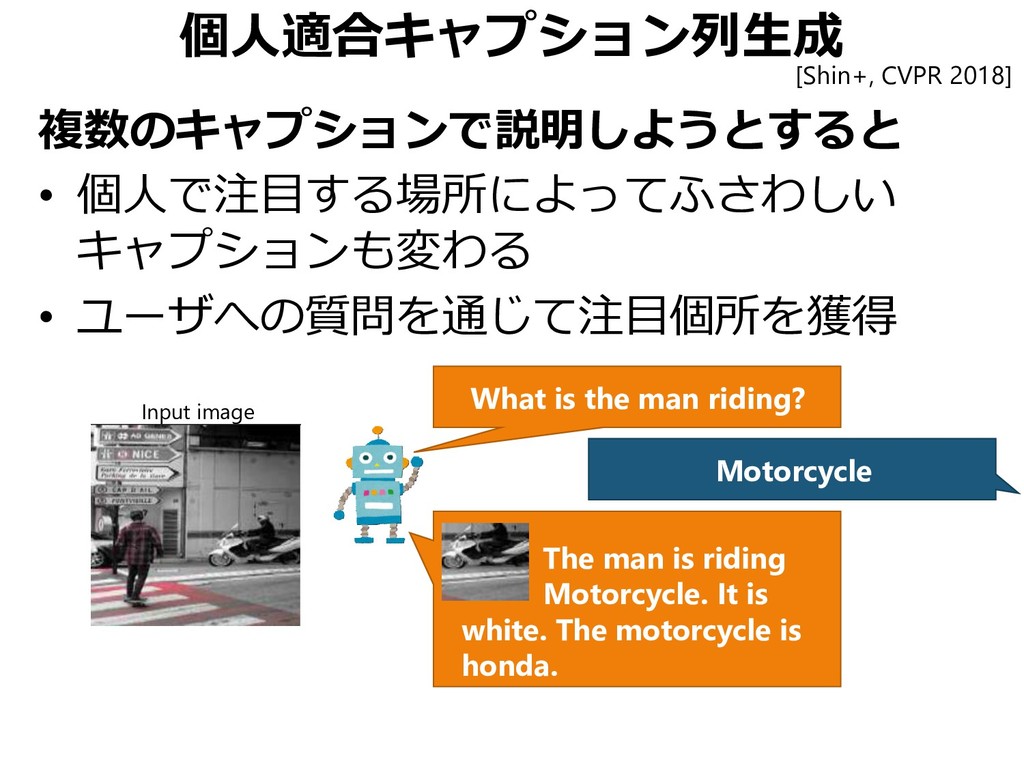{kind=link}
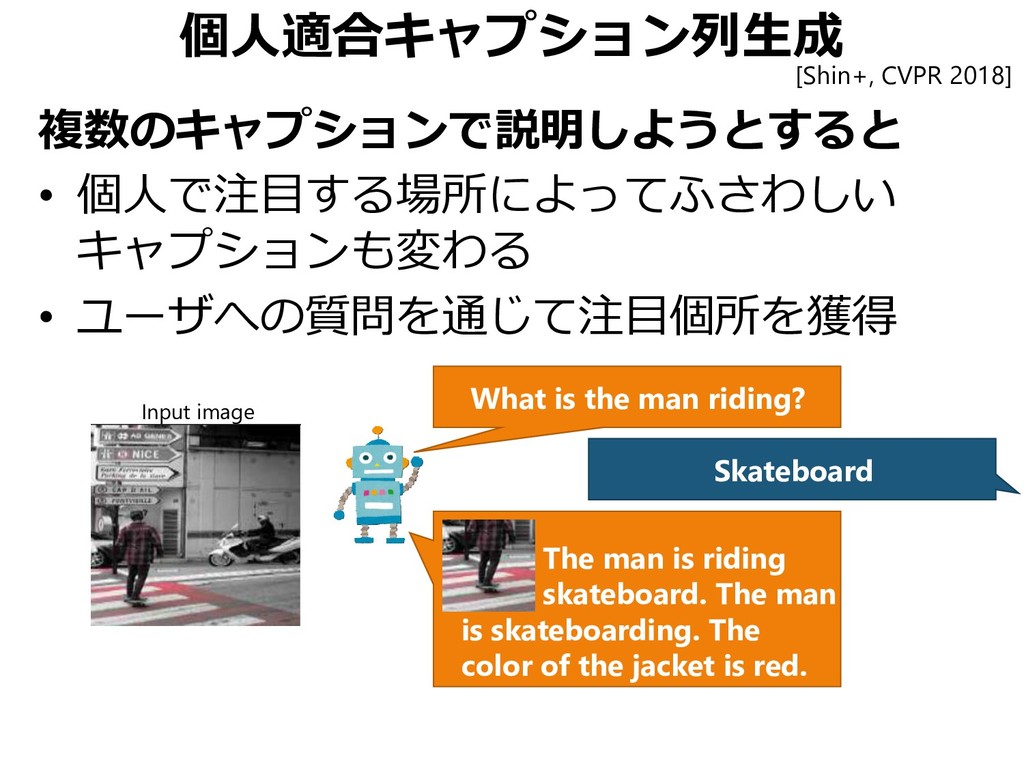{kind=link}
![ロボットのPick&Place [Hatori+, ICRA 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_123.jpg){kind=link}
![ロボットのPick&Place 実はComprehensionモデル+α [Hatori+, ICRA 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_124.jpg){kind=link}
![精度の発展:「行って帰ってくる損失」 • 機械学習 出力キャプション→入力画像を再推定 cf. CycleGAN[Zhu+, ICCV 2017] 変分自己符号化器 [Pu+,](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_125.jpg){kind=link}
![ロボットのPick&Place 実はComprehensionモデル+α [Hatori+, ICRA 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_126.jpg){kind=link}
![ロボットのPick&Place 実はComprehensionモデル+α [Hatori+, ICRA 2018] Comprehensionに相当する部分 (何をPickするか)](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_127.jpg){kind=link}
![ロボットのPick&Place 実はComprehensionモデル+α [Hatori+, ICRA 2018] +αに相当する部分 (どこにPlaceするか)](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_128.jpg){kind=link}
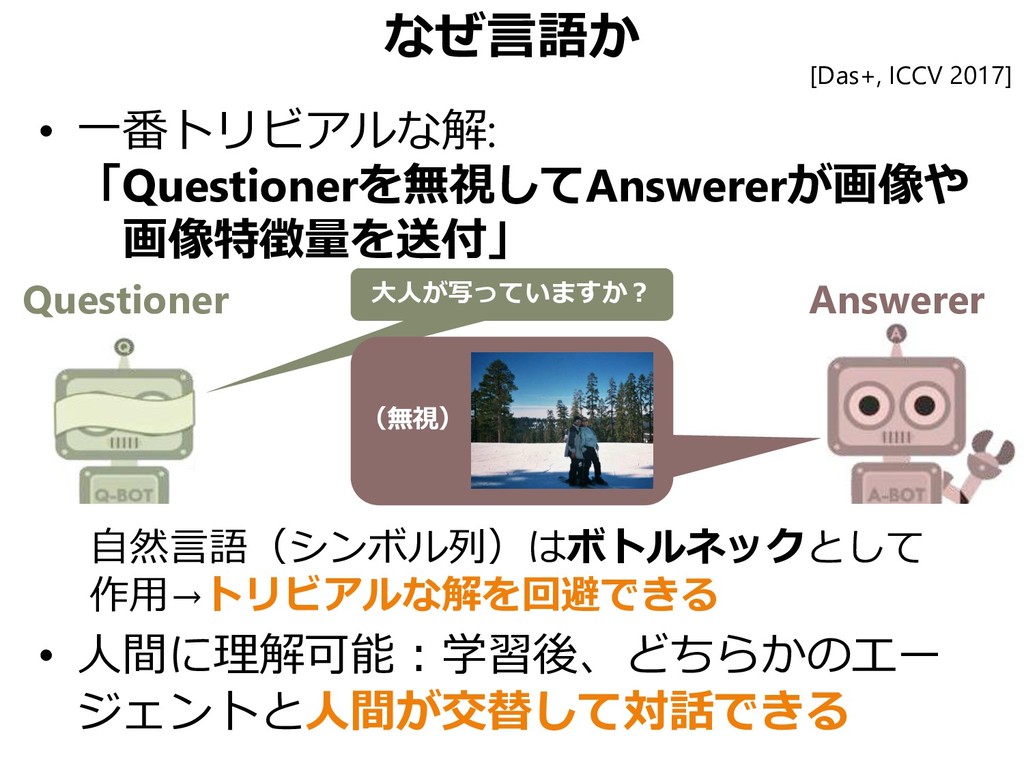
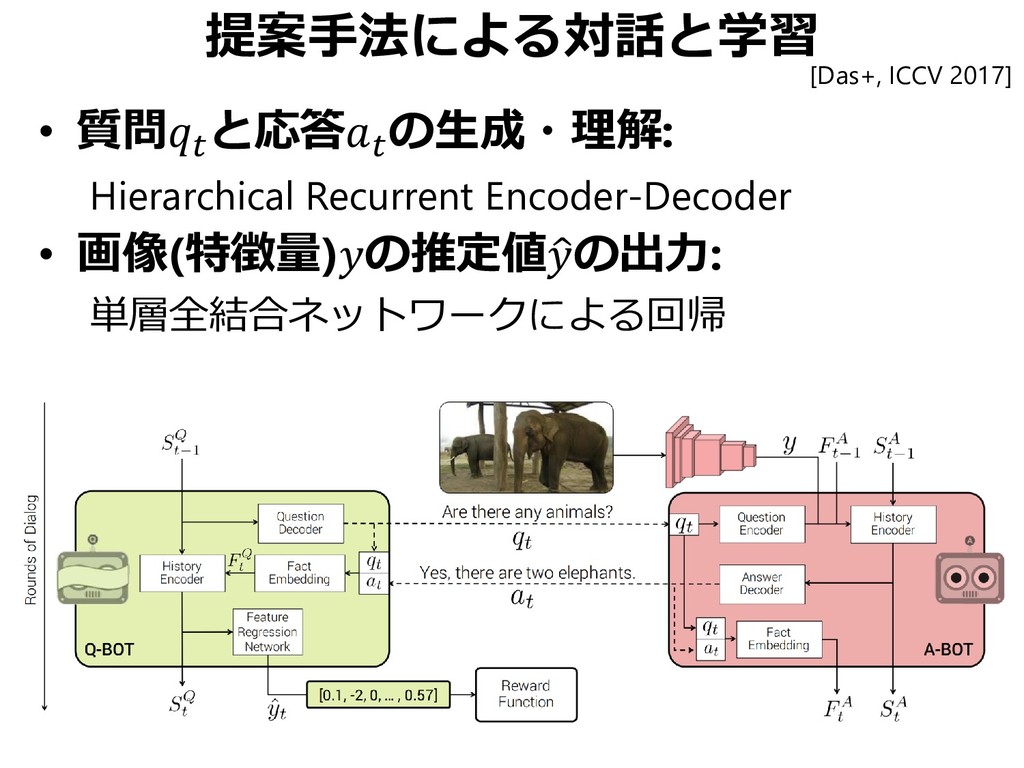
![どの画像を見ているかを共有したい 10 Round のQA後Questionerが画像を当てる 当たれば2エージェント共に勝利(協調) 10 Rounds [Das+, ICCV 2017]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_129.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![会話データ集めるの大変だよね? MMD:対話に基づく画像検索(商品推薦) • 従来:対話データで訓練 • 本研究:2枚の画像を比較した キャプションを集めて事前学習 [Guo+, NeurIPS 2018]](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_136.jpg){kind=link}
![会話データ集めるの大変だよね? • 従来 [Anderson+, CVPR 2018] : – 道順を聞いて動くエージェント (Follower)](https://files.speakerdeck.com/presentations/bd149f17b2ba4fb3a193e6f6c3340572/slide_137.jpg){kind=link}
{kind=link}