When you build an application you will undoubtedly need to integrate it with other applications and systems, and transform data from one format to another. The Apache Camel project’s goal is to simplify the way we do these kinds of integration, using the book “Enterprise Integration Patterns” as the gold standard.
Apache Camel has been around for a while, but it is more relevant now than it has ever been. In this session we’ll show you how Camel can leverage Quarkus’ fast startup time and developer experience to build modern, distributed and cloud native integration workloads. As a bonus it can make use of technologies like serverless computing (eg. Knative) and data streaming (eg. Kafka) to remove bottlenecks, integrate faster and better than ever before, and save resources and money on top of it.
Note: Camels were not hurt in the process of making this talk.
Attendees should come away from this talk with the following:
- Why you would want to use Apache Camel to create easy to understand, reusable and distributed integration components.
- How the next iteration of Apache Camel (based on Quarkus) can leverage Kubernetes and/or Serverless computing and event driven architectures to deploy early and often.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
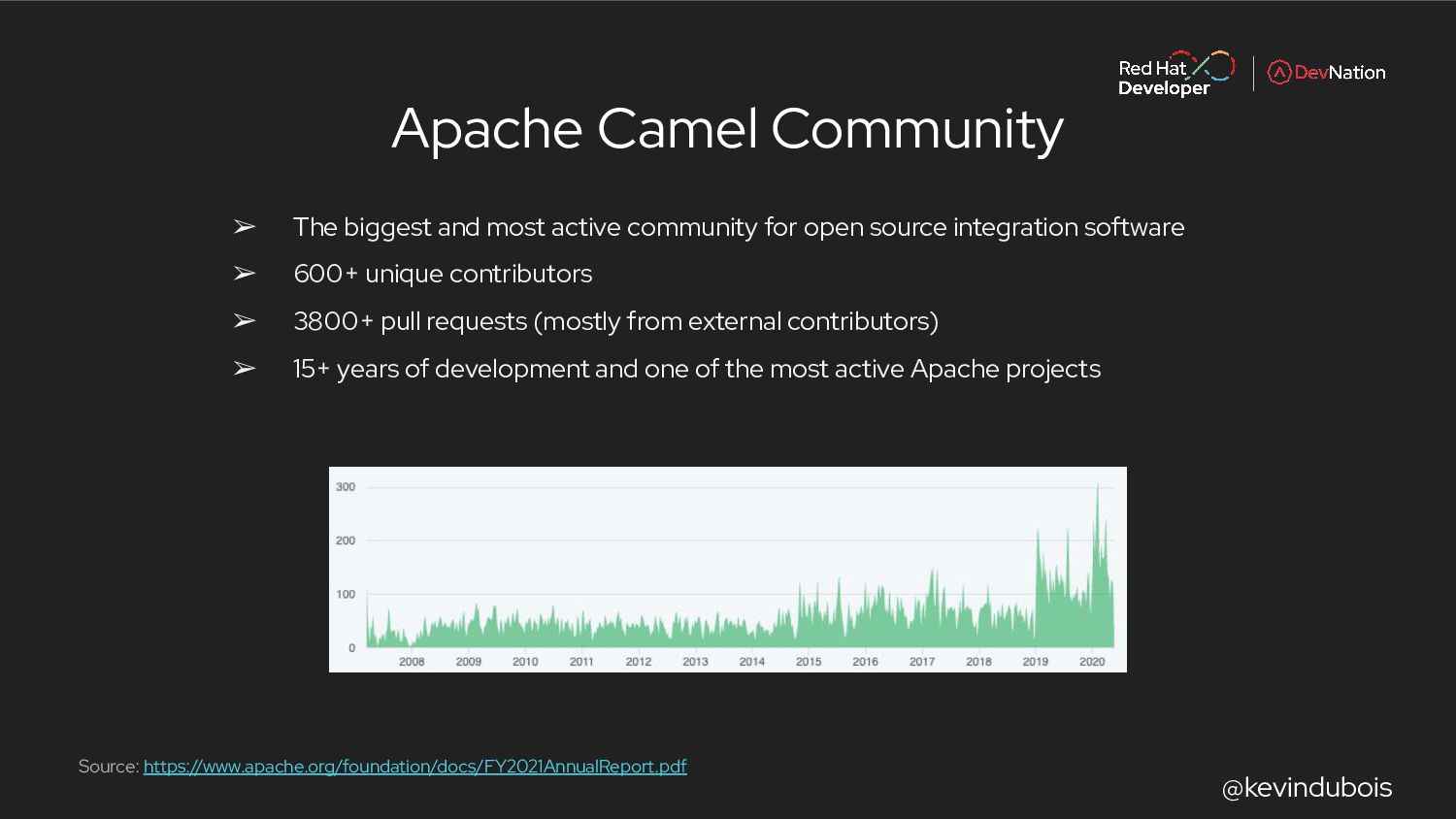{kind=link}
{kind=link}
{kind=link}
{kind=link}
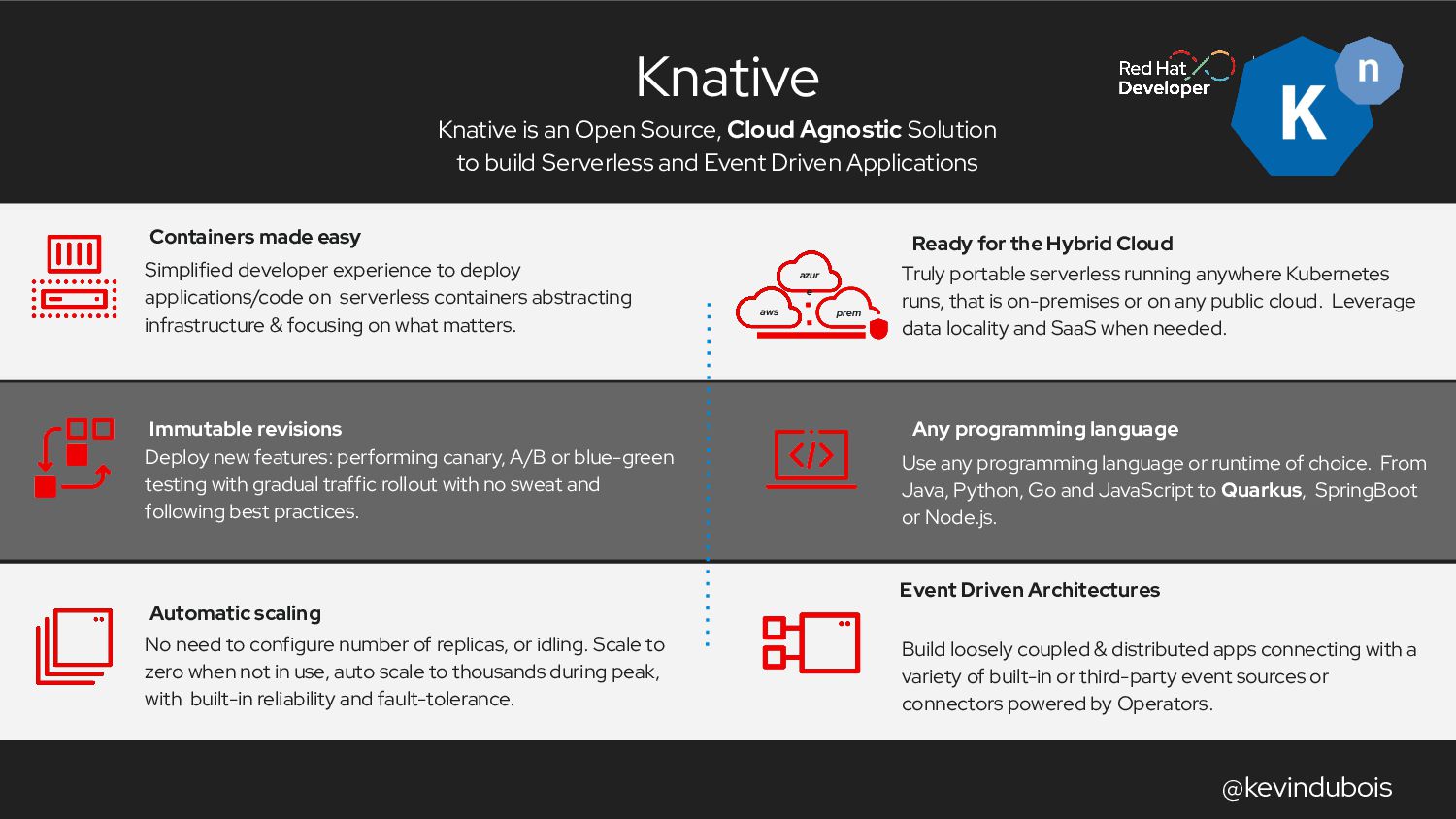{kind=link}
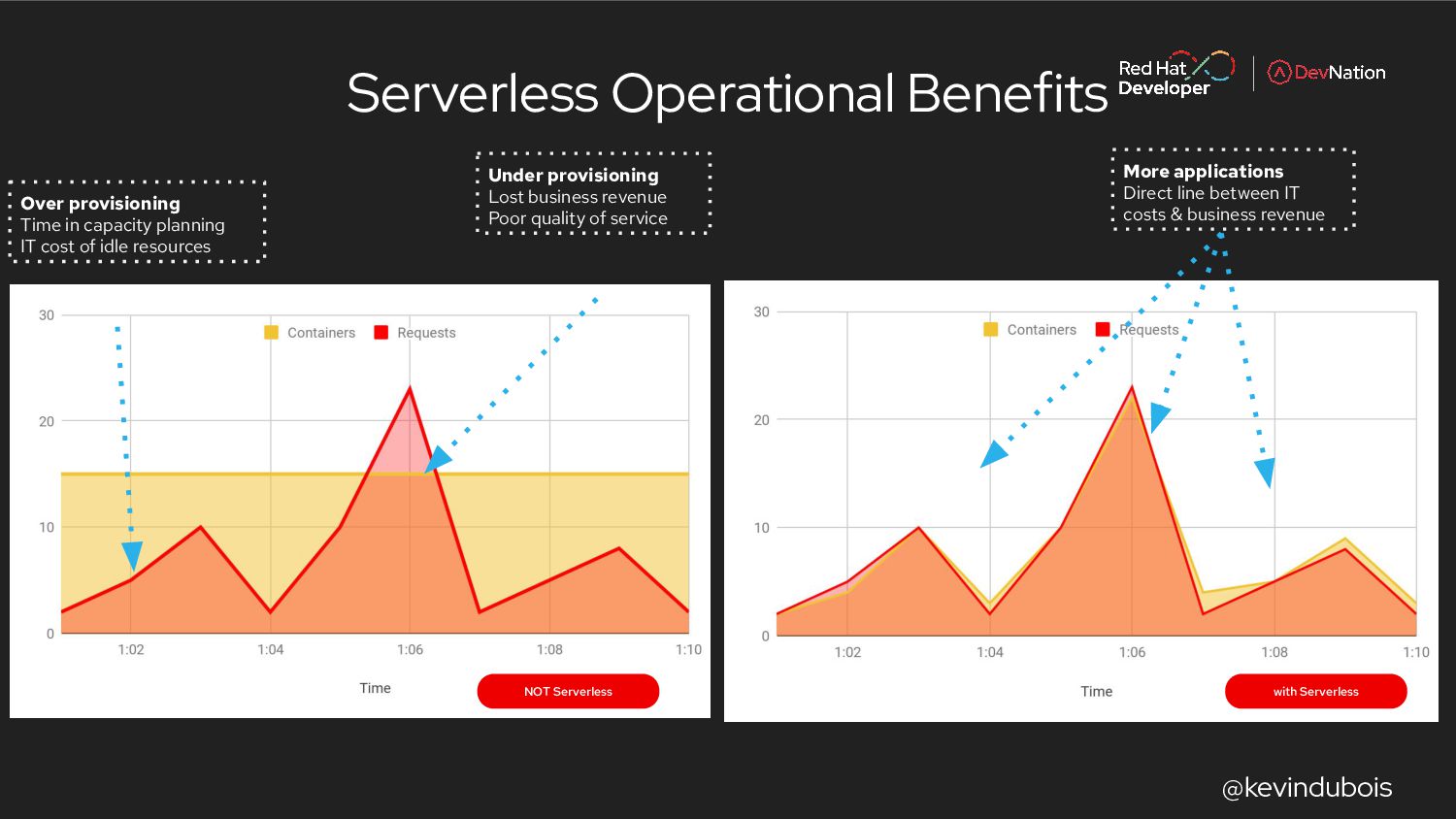{kind=link}
{kind=link}
{kind=link}
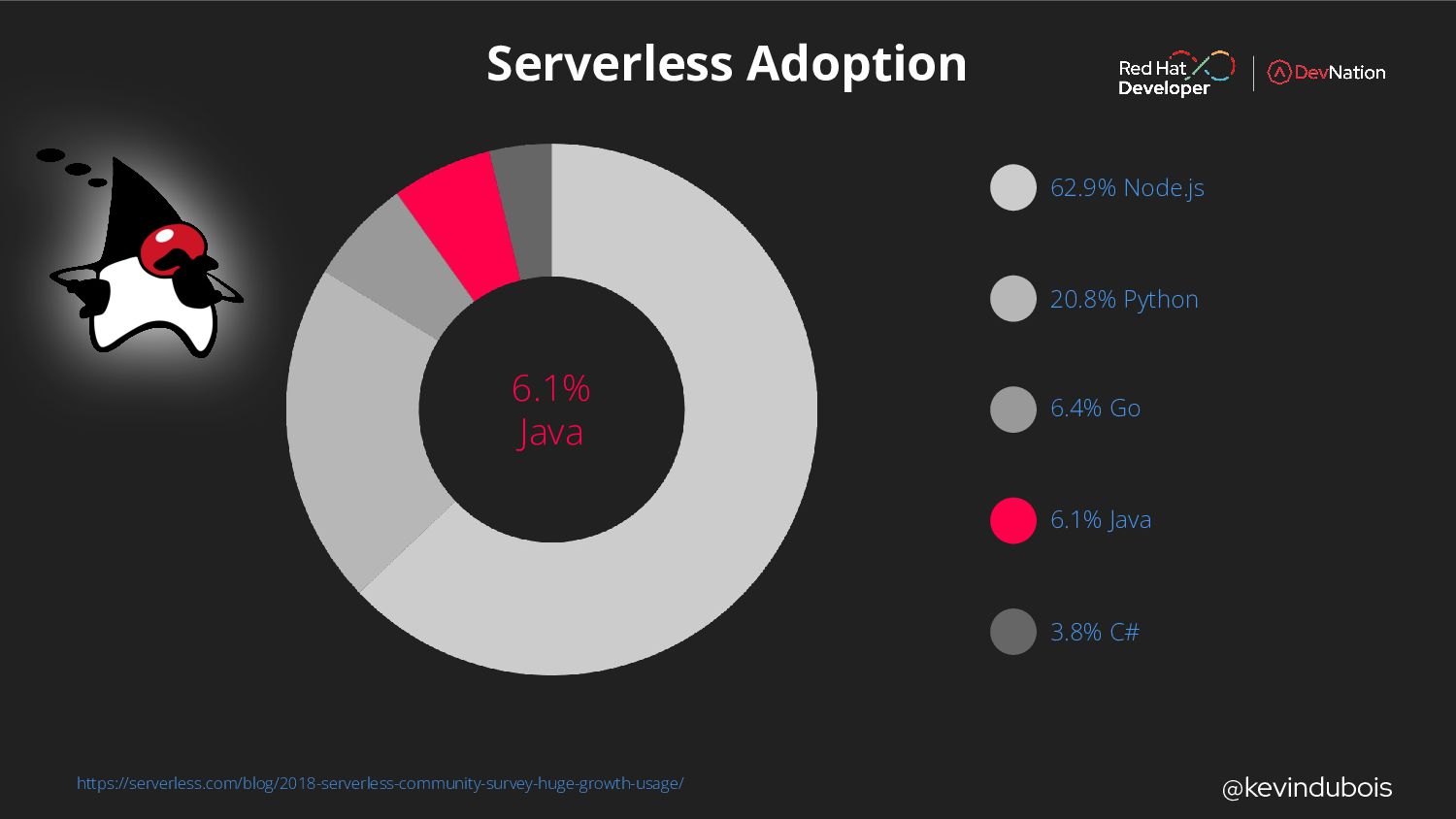{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
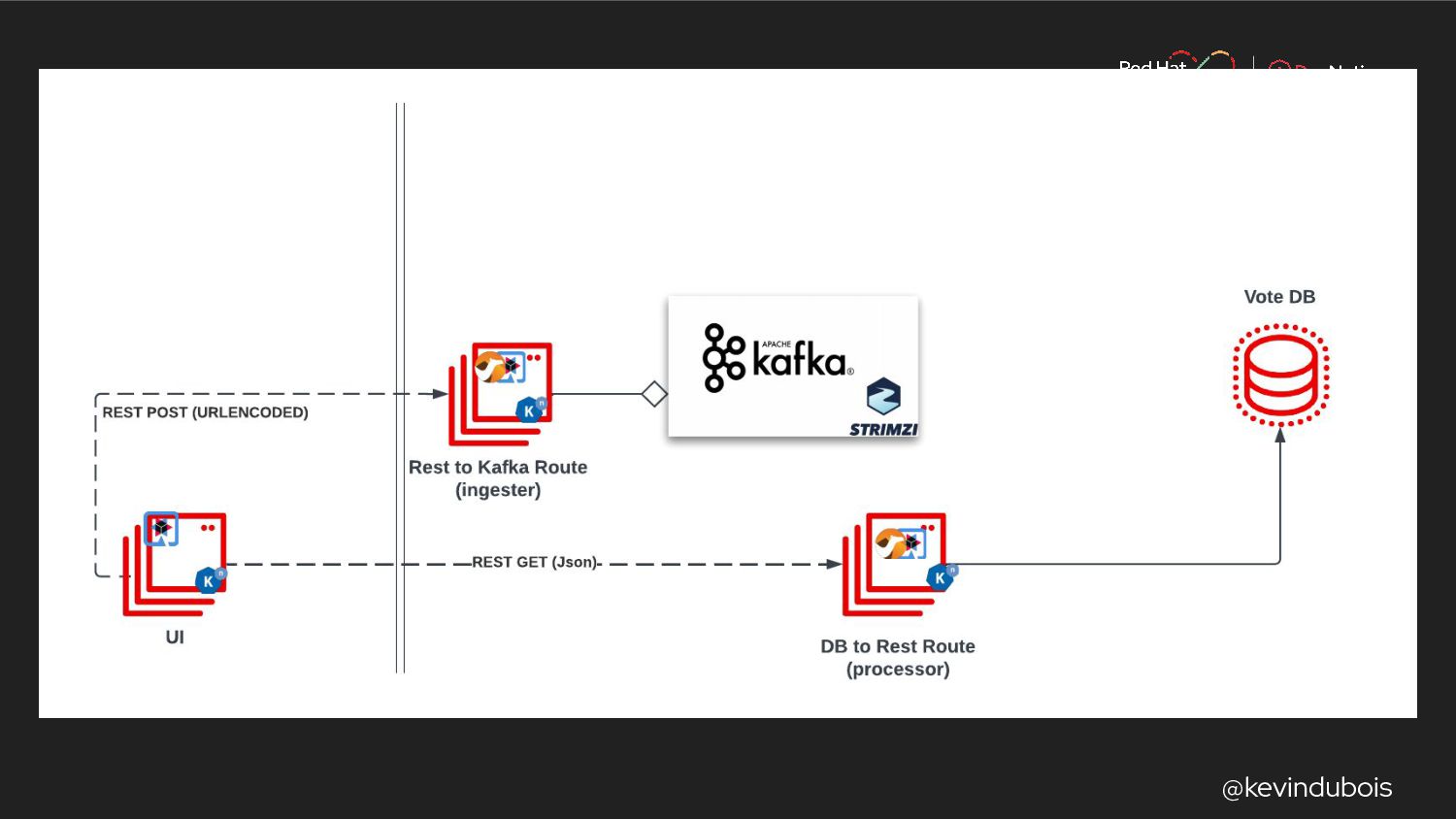{kind=link}
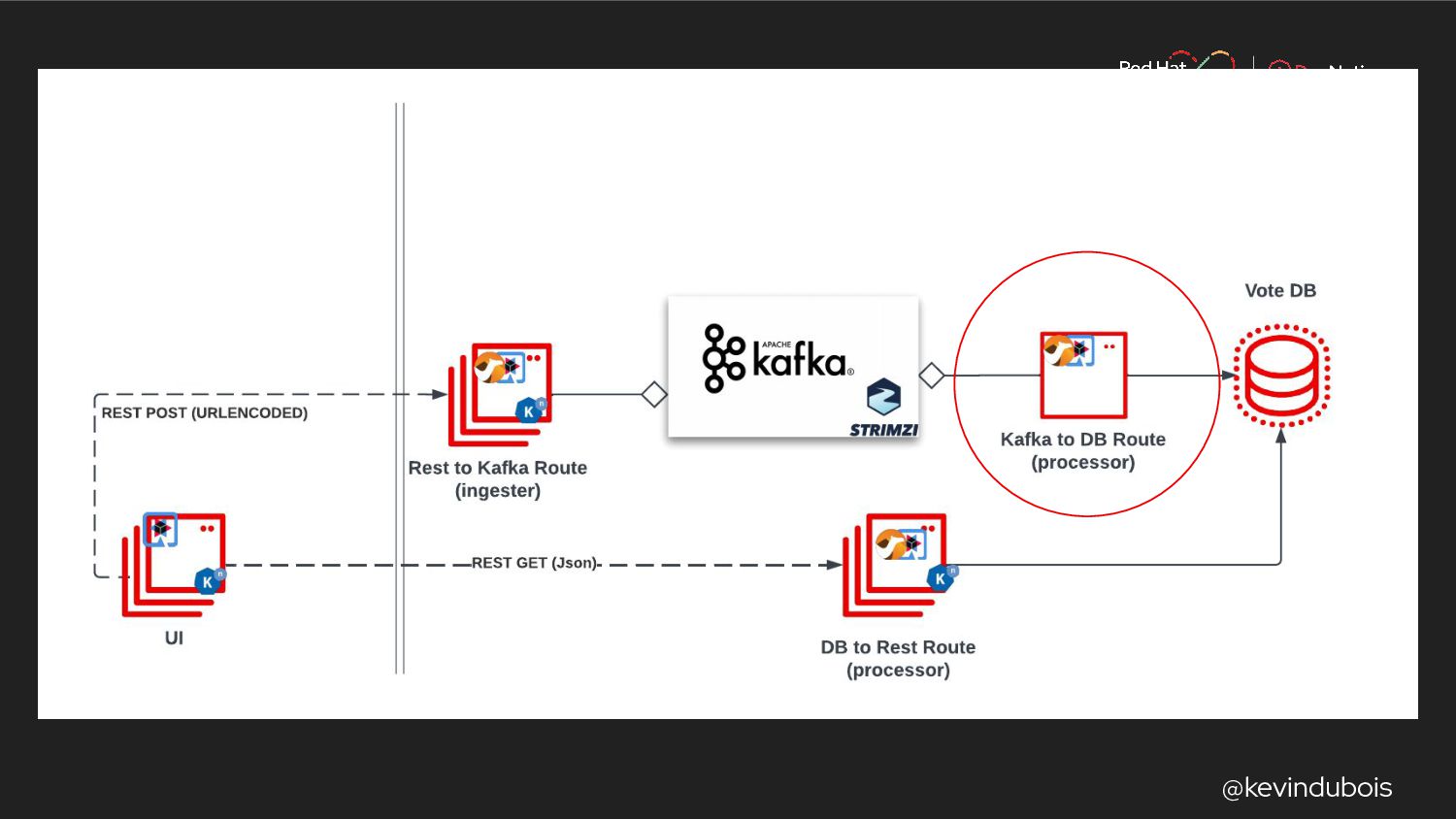{kind=link}
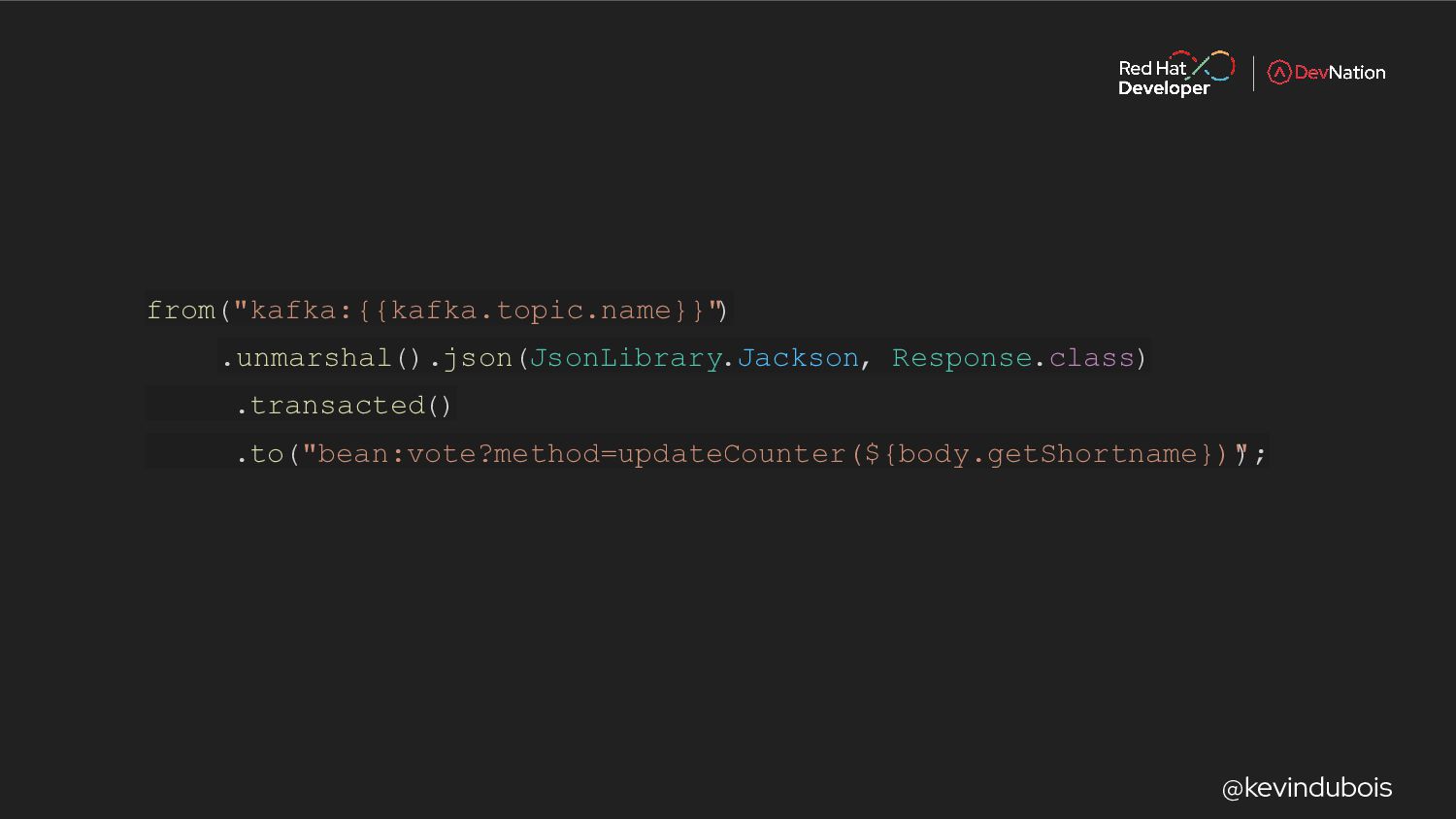{kind=link}
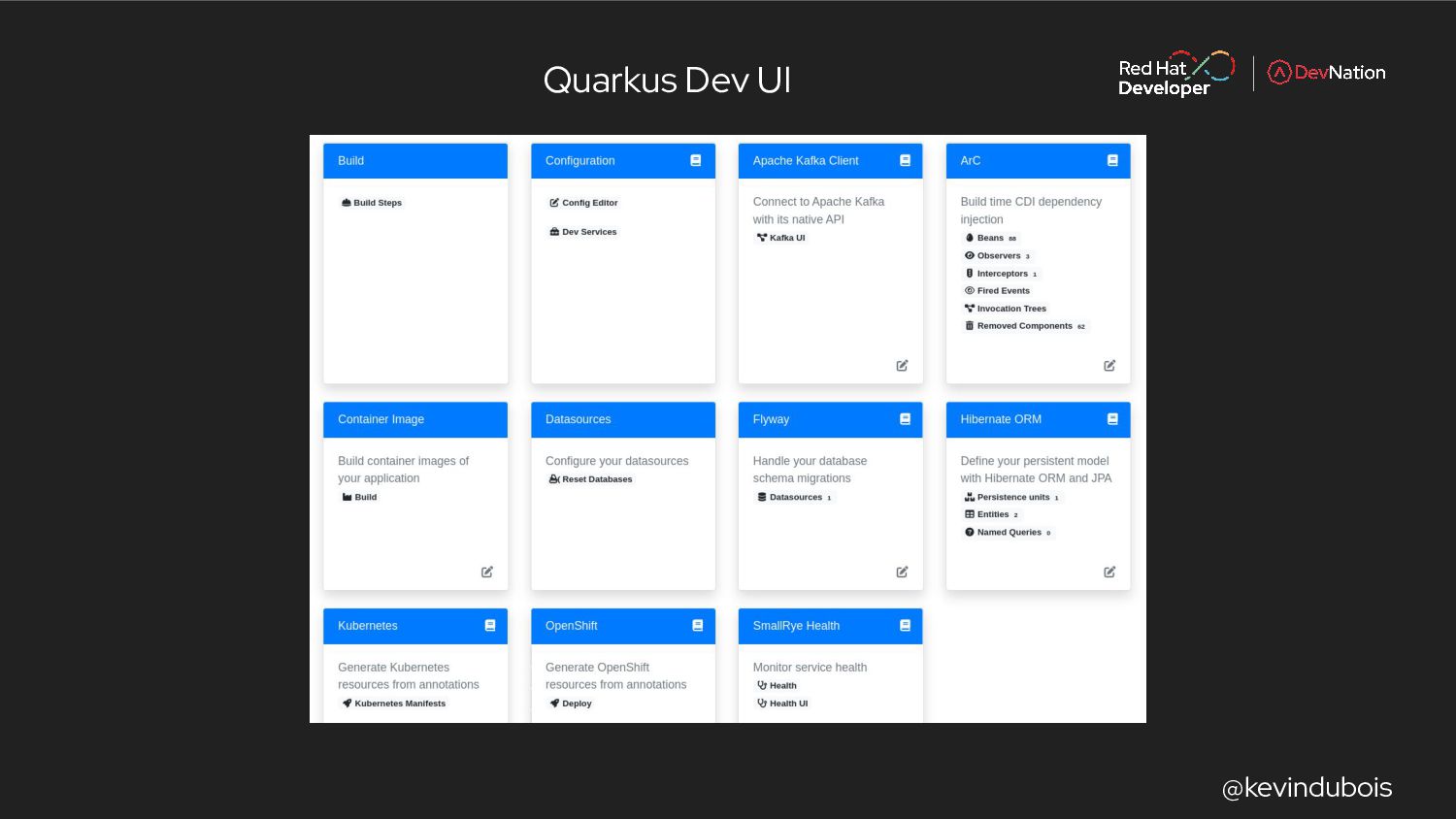{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}