nouvelle arˆ ete (u, v) telle que A′ ∪ {(u, v)} est toujours un sous-ensemble d’un ACM pour G (on dit alors que (u, v) est compatible avec A′). Les deux algorithmes se distinguent sur la mani` ere de choisir la nouvelle arˆ ete compatible ` a ajouter ` a A′. L’algorithme 14 pr´ esente un algorithme g´ en´ erique pour la recherche d’ACM. Proc´ edure Recherche-ACM(G) //G = (S, A, w) : un graphe non-orient´ e, valu´ e et connexe. begin A′ := ∅ tant que A′ n’est pas un arbre couvrant faire Choisir (u, v) ∈ A t.q. (u, v) est compatible avec A′ A′ := A′ ∪ {(u, v)} retourner A’ end Algorithme 14 : algorithme g´ en´ erique de recherche d’un arbre couvrant minimal Un tel algorithme est correct car : la propri´ et´ e “A′ est un sous-ensemble d’un ACM” est vraie au d´ ebut de l’algorithme et elle est maintenue ` a chaque ´ etape. Apr` es la |S| − 1-` eme ´ etape, A′ est un arbre couvrant et c’est un ACM (et donc l’algorithme termine). Tout le probl` eme r´ eside dans la mani` ere de trouver des arˆ etes (u, v) compatibles. . . Une partition de G = (S, A, w) est une partition (S1, S2) de S, c’est-` a-dire deux sous- ensembles de S tels que : S1 ∪S2 = S et S1 ∩S2 = ∅ (on a bien sˆ ur S2 = S\S1). ´ Etant donn´ ee une partition (S1, S2) de G, on introduit les d´ efinitions suivantes : – une arˆ ete (u, v) traverse la partition (S1, S2) ssi on a u ∈ S1 ∧ v ∈ S2 ou u ∈ S2 ∧ v ∈ S1 (on dit que (u, v) est une arˆ ete traversante de (S1, S2)) ; – (S1, S2) respecte A′ ⊆ A ssi aucune arˆ ete de A′ ne traverse (S1, S2) ; – une arˆ ete traversante est dite minimale si elle est de poids minimal parmi les arˆ etes traversantes. On a le th´ eor` eme suivant : Th´ eor` eme 5 ´ Etant donn´ es : – G = (S, A, w) un graphe non-orient´ e, valu´ e et connexe, – A′ ⊆ A tel qu’il existe un ACM de G contenant A′, – (S1, S2) une partition qui respecte A′, et – (u, v) une arˆ ete traversante minimale de (S1, S2), alors (u, v) est compatible avec A′ ( i.e. il existe un ACM contenant A′ ∪ {(u, v)}). Preuve : Soit T ⊆ A un ACM contenant A′ : A′ ⊆ T. Si T contient (u, v), on a le r´ esultat. Supposons que (u, v) ∈ T. Supposons u ∈ S1 et v ∈ S2 (NB : (u, v) est traversante). Comme T est un ACM, il est connexe : il existe donc un chemin ρ allant de u ` a v. Comme u et v ne sont pas dans le mˆ eme Si, le long de ρ, il existe au moins une arˆ ete (x, y) ∈ T traversante pour (S1, S2). Supposons x ∈ S1 et y ∈ S2. Le chemin ρ peut donc se d´ ecomposer de la mani` ere suivante : u →ρ1 x → y →ρ2 v. L’arˆ ete (x, y) n’appartient pas ` a A′ car (S1, S2) respecte A′. Soit T′ = (T\{(x, y)}) ∪ {(u, v)}. Clairement A′ ∪ {(u, v)} ⊆ T′. Nous allons montrer que T′ est aussi un ACM de G : 62
{kind=link}
{kind=link}
![Notes de cours d’algorithmique – L3 Fran¸ cois Laroussinie [email protected]](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Figure 5 – a[p] avec p = {3, 4, 2,](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Proc´ edure PP-Visiter(G, s) //G = (S, A) begin Couleur[s]](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
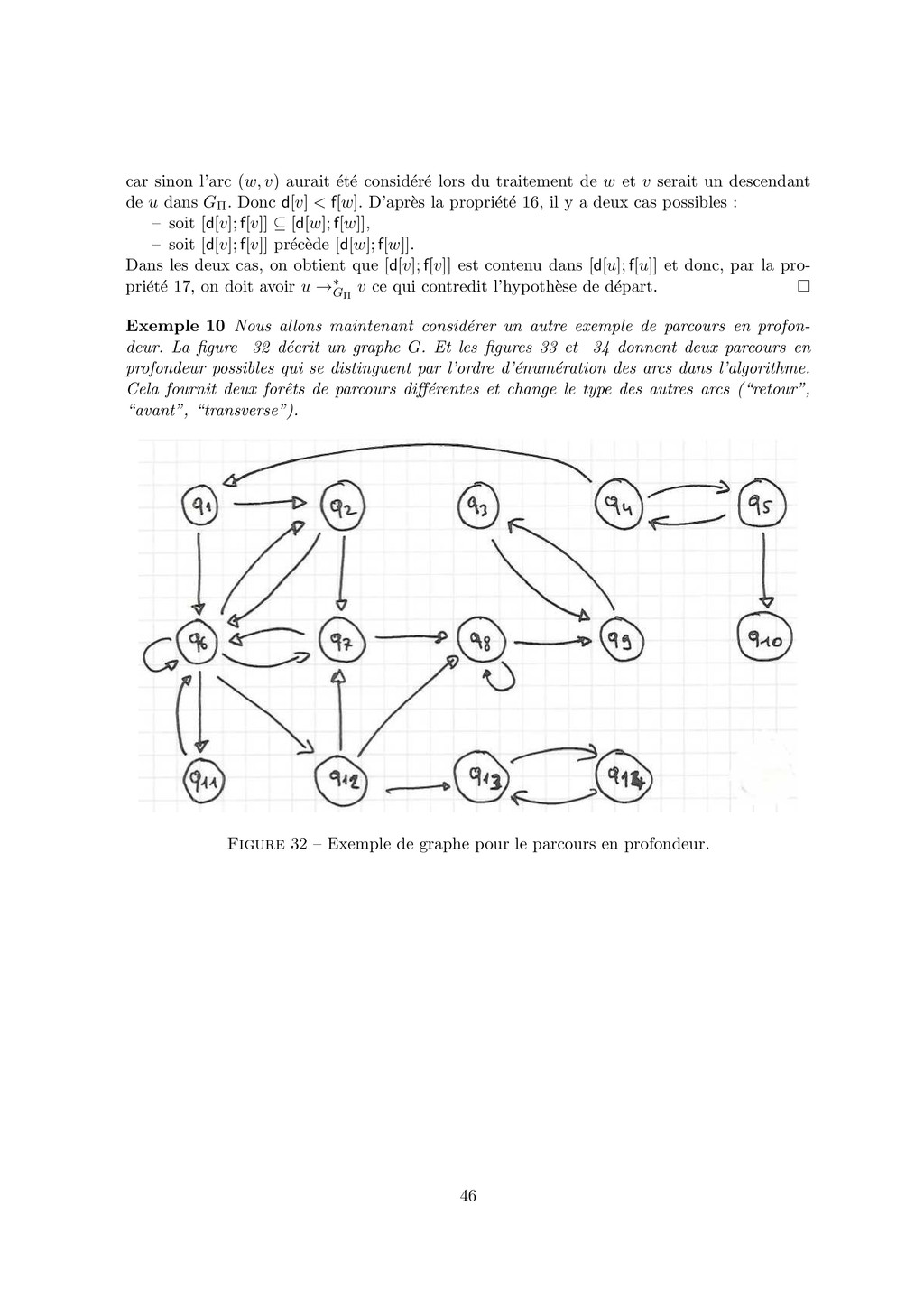{kind=link}
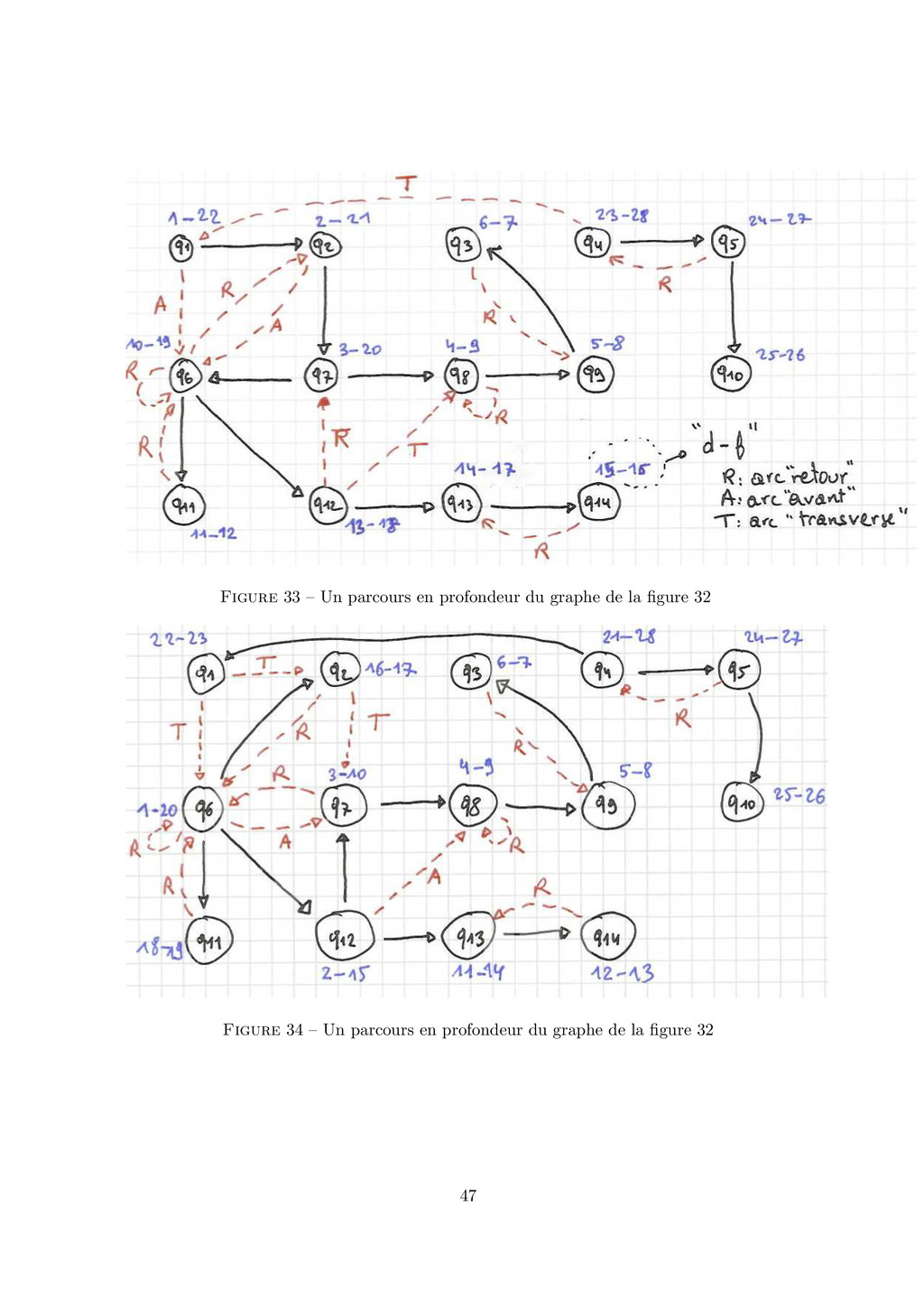{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
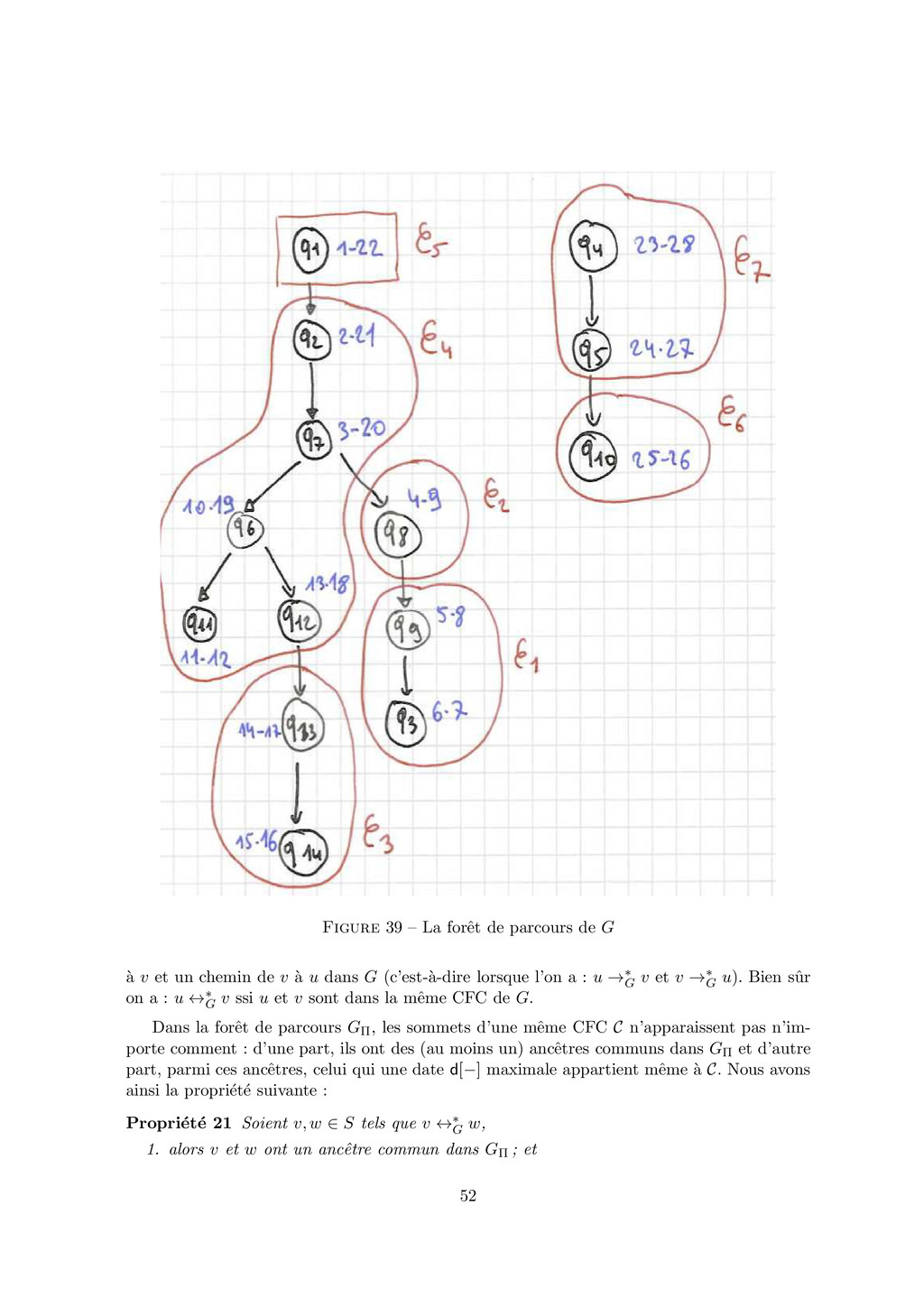{kind=link}
{kind=link}
{kind=link}
![que c’est le minimum entre d[x] et les d[w] tel](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_56.jpg){kind=link}
![valeur r[x] : Propri´ et´ e 22 Pour tout sommet](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_57.jpg){kind=link}
{kind=link}
![Proc´ edure CFC(x) 1 temps++; d[x] := temps; Couleur[x] :=](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_59.jpg){kind=link}
{kind=link}
![On en conclut que rA[x] = r[x] = d[x]. Et](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Preuve : – On montre que l’on a di[vi] ≤](https://files.speakerdeck.com/presentations/4edecdc5ad0da600500074f2/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}