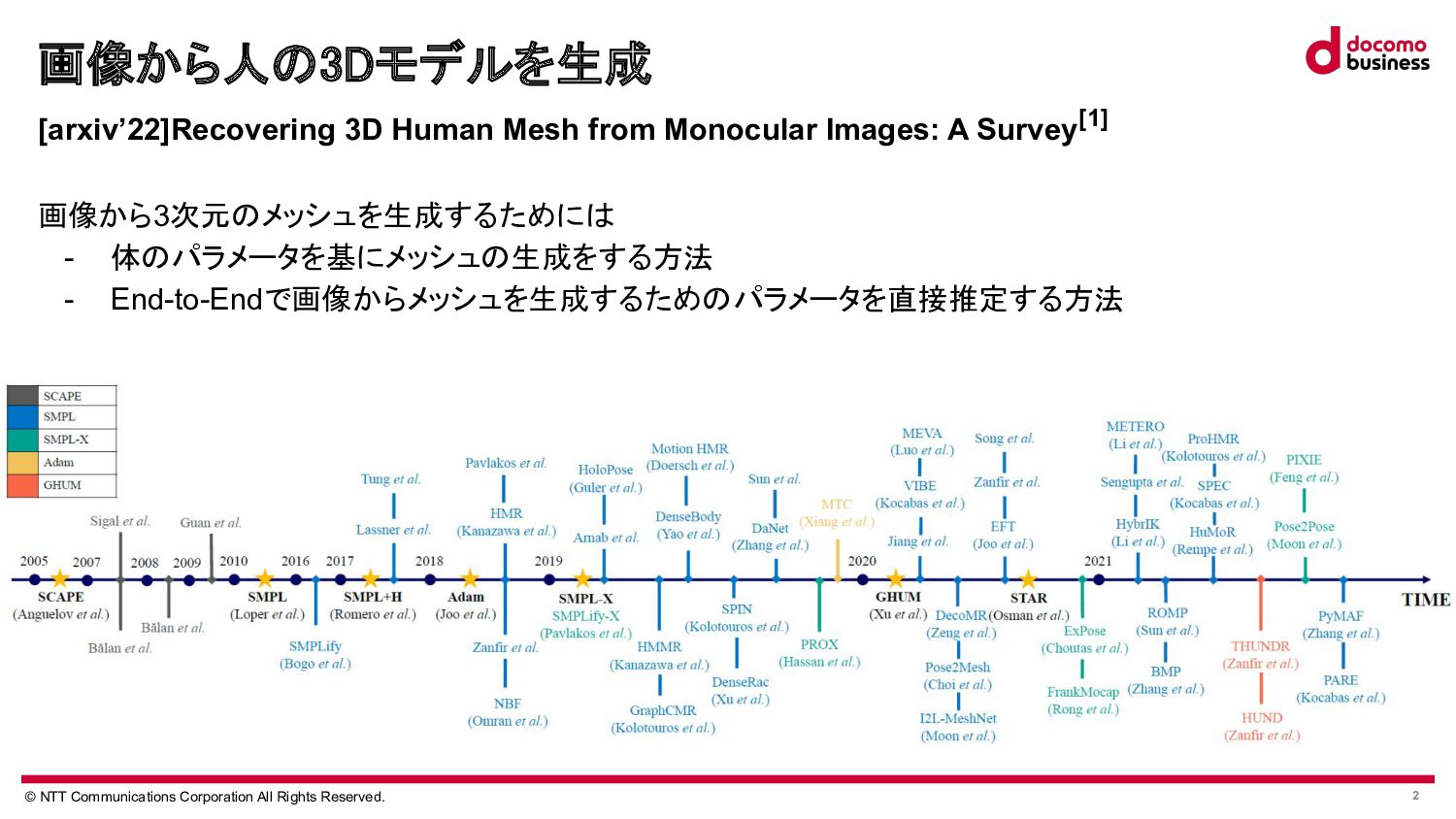
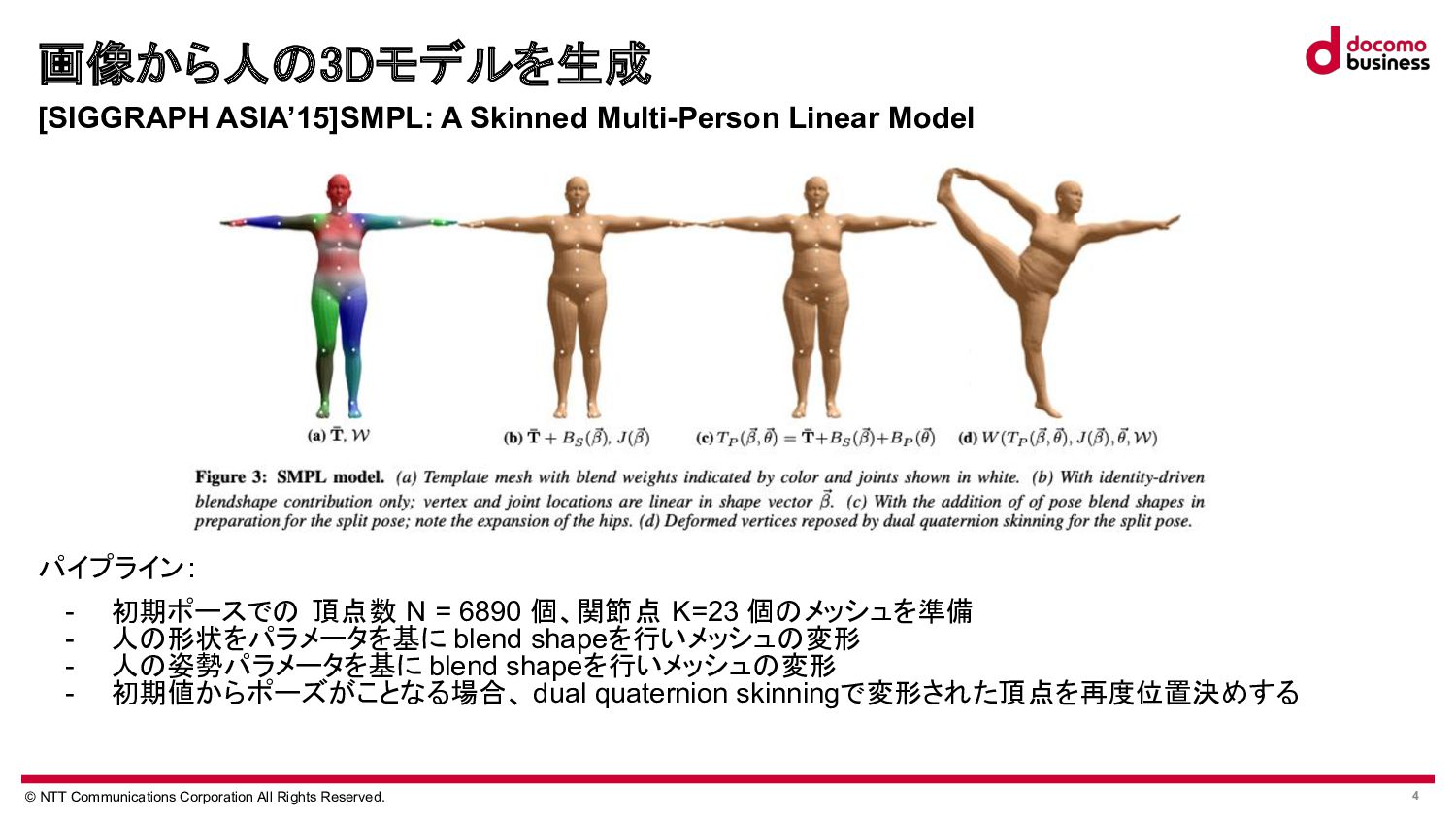
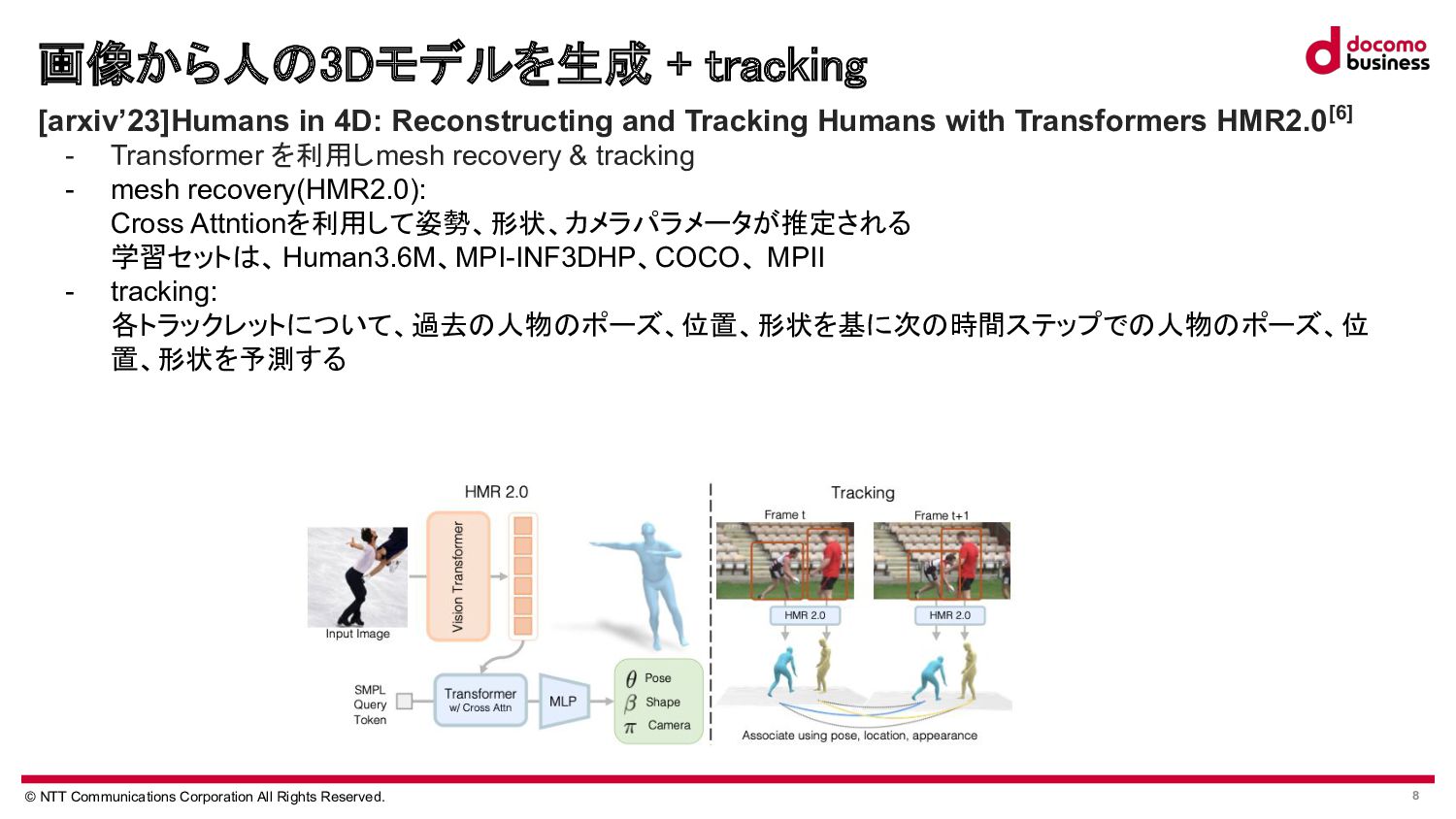
Tian, Hongwen Zhang, Yebin Liu, Limin Wang,Recovering 3D Human Mesh from Monocular Images: A Survey. https://arxiv.org/abs/2203.01923 [2]Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, Michael J. Black, SMPL: A Skinned Multi-Person Linear Model.https://files.is.tue.mpg.de/black/papers/SMPL2015.pdf [3]Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, Michael J. Black, Expressive Body Capture: 3D Hands, Face, and Body from a Single Image.https://openaccess.thecvf.com/content_CVPR_2019/papers/Pavlakos_Expressive_Body_Capture_3D_Hands_Face_and _Body_From_a_CVPR_2019_paper.pdf [4]Angjoo Kanazawa, Michael J. Black, David W. Jacobs, Jitendra Malik, End-to-end Recovery of Human Shape and Pose .https://openaccess.thecvf.com/content_cvpr_2018/papers/Kanazawa_End-to-End_Recovery_of_CVPR_2018_paper.pdf [5]Junhyeong Cho, Kim Youwang, Tae-Hyun Oh, Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers. https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136610336.pdf [6]Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, Jitendra Malik, Humans in 4D: Reconstructing and Tracking Humans with Transformers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© NTT Communications Corporation All Rights Reserved. 9 参考文献 [1]Yating](https://files.speakerdeck.com/presentations/deab1c2fd55b4b1db6f7de865f366525/slide_8.jpg){kind=link}