Failures in microservice architectures are inevitable—but resilience is a choice. In this session, you’ll learn how to design systems that not only survive when things go wrong but continue to deliver value. We’ll walk through real-world examples and practical patterns to:
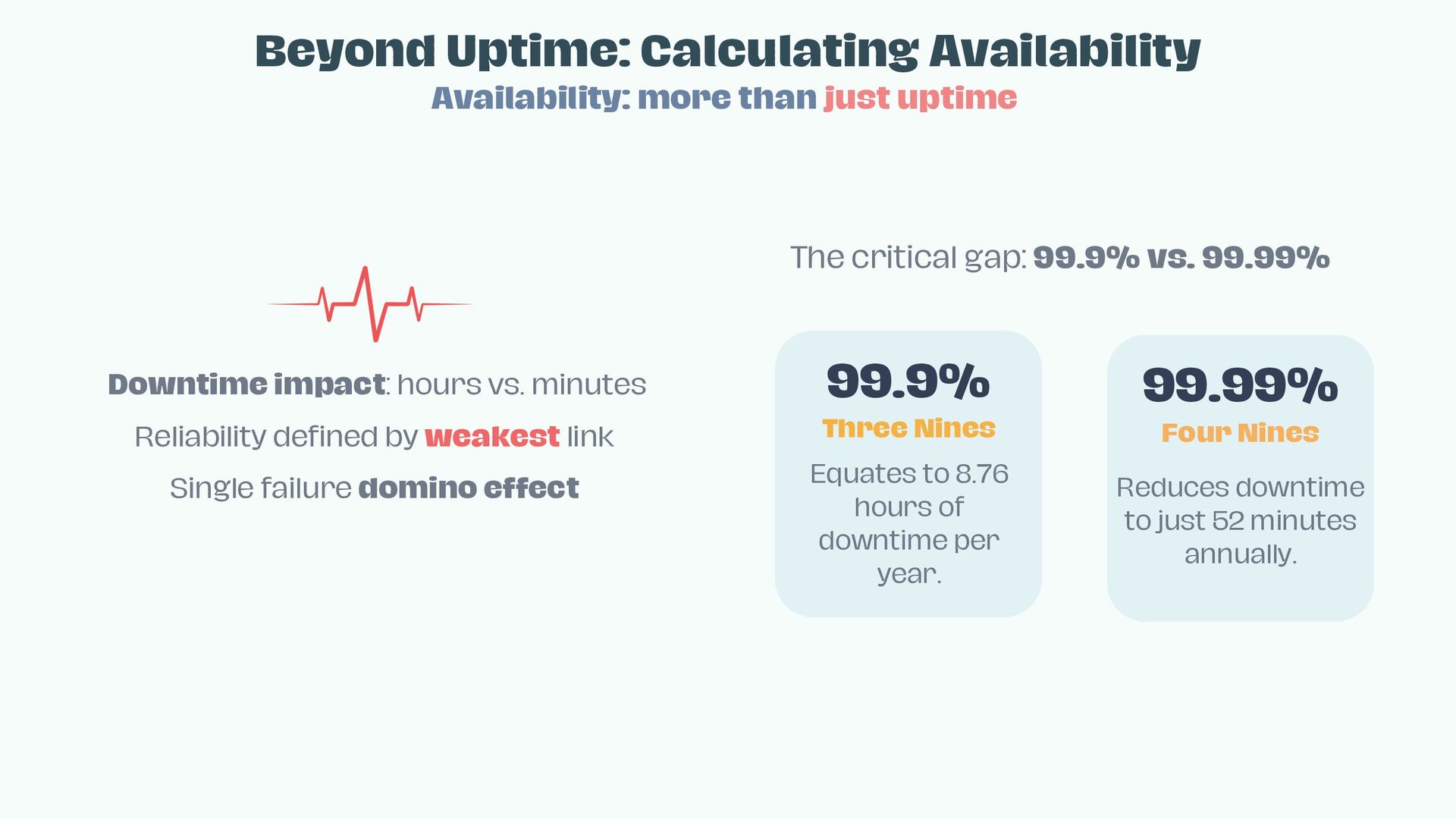
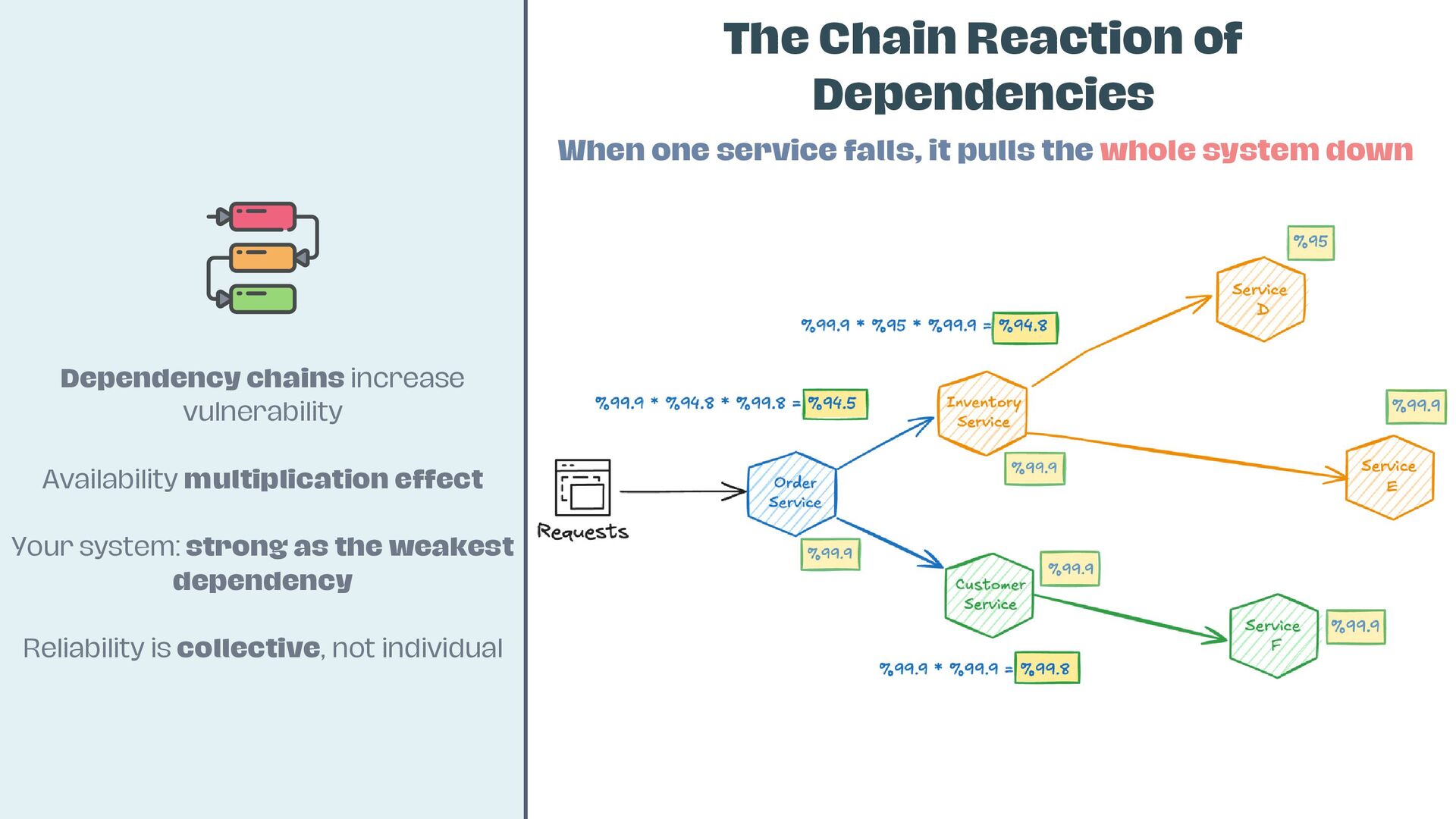
• Measure and multiply availability—why “three nines” vs. “four nines” matters
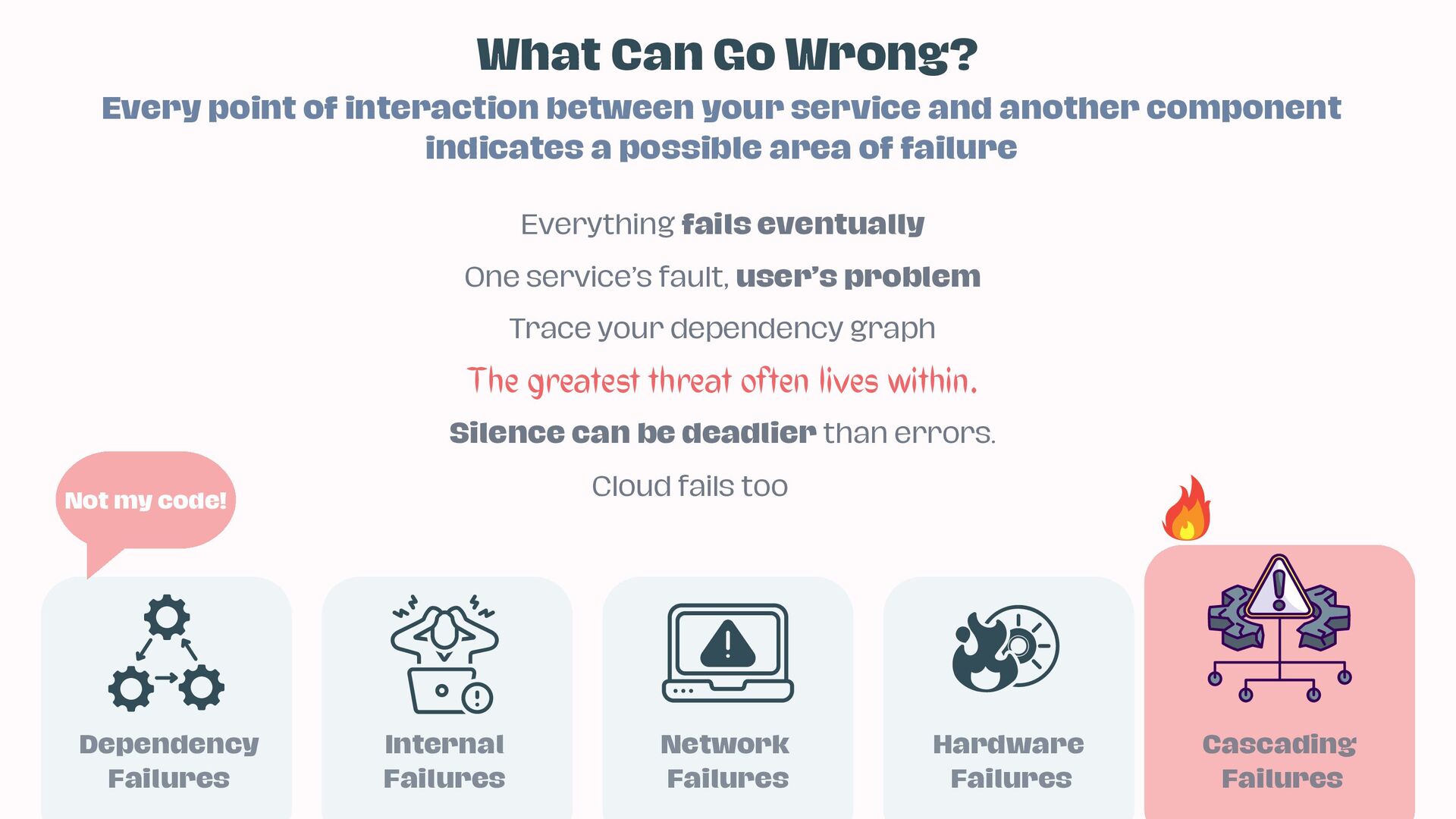
• Identify key failure modes: dependencies, internal bugs, network glitches, hardware faults, and cascading breakdowns
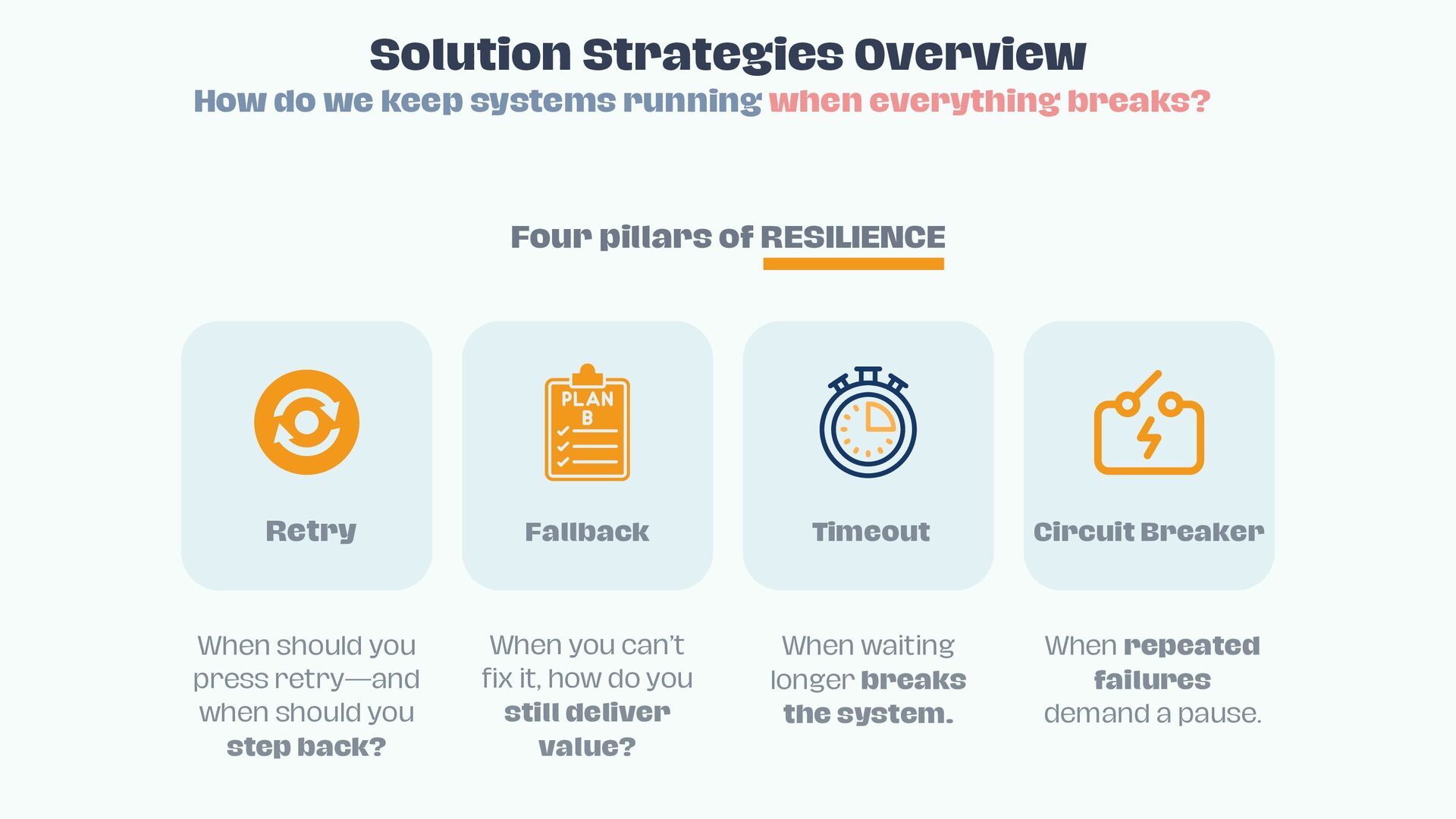
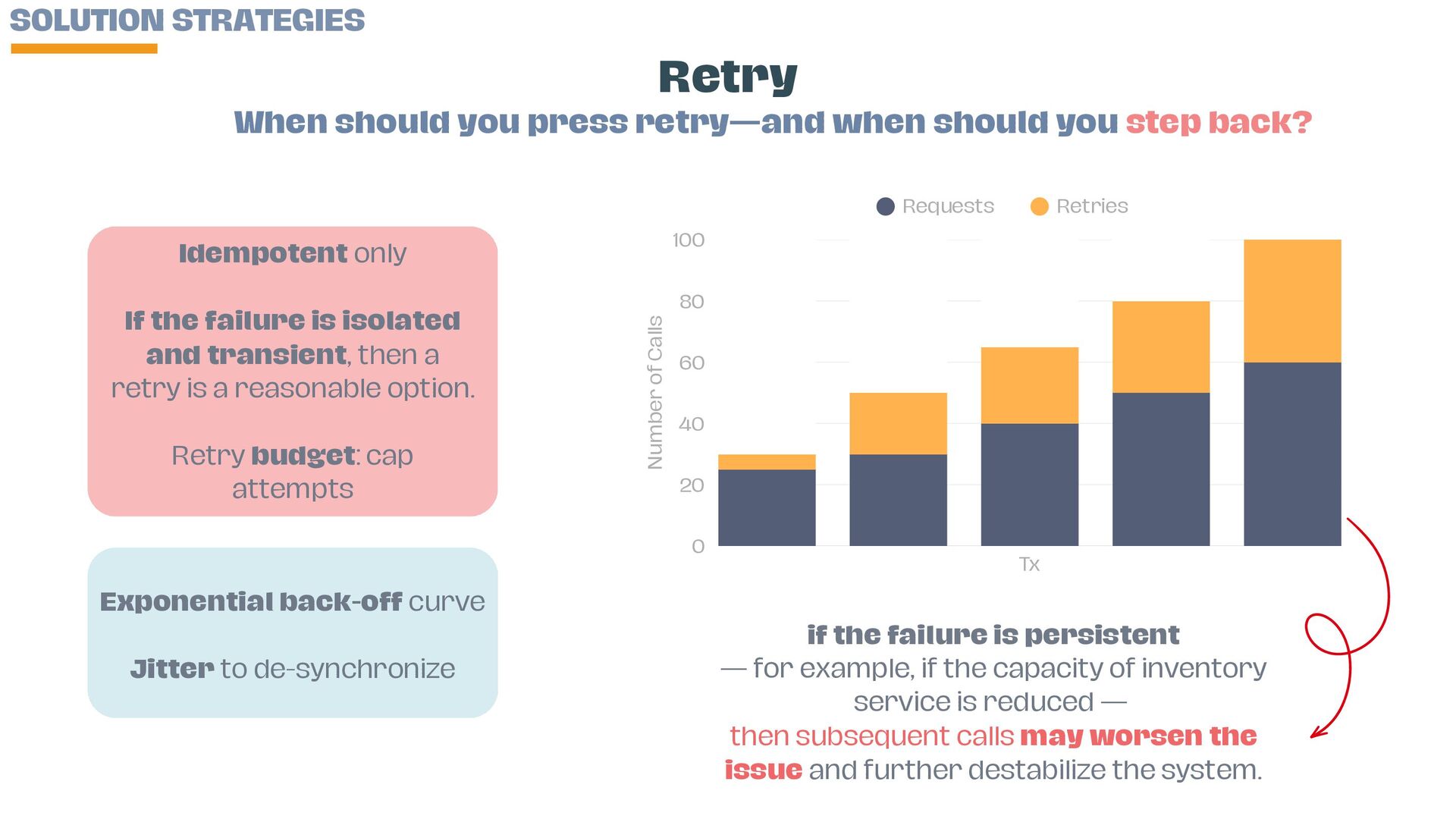
• Implement retries safely with back-off and jitter
• Apply fallback strategies: graceful degradation, caching, functional redundancy, and stubbed data
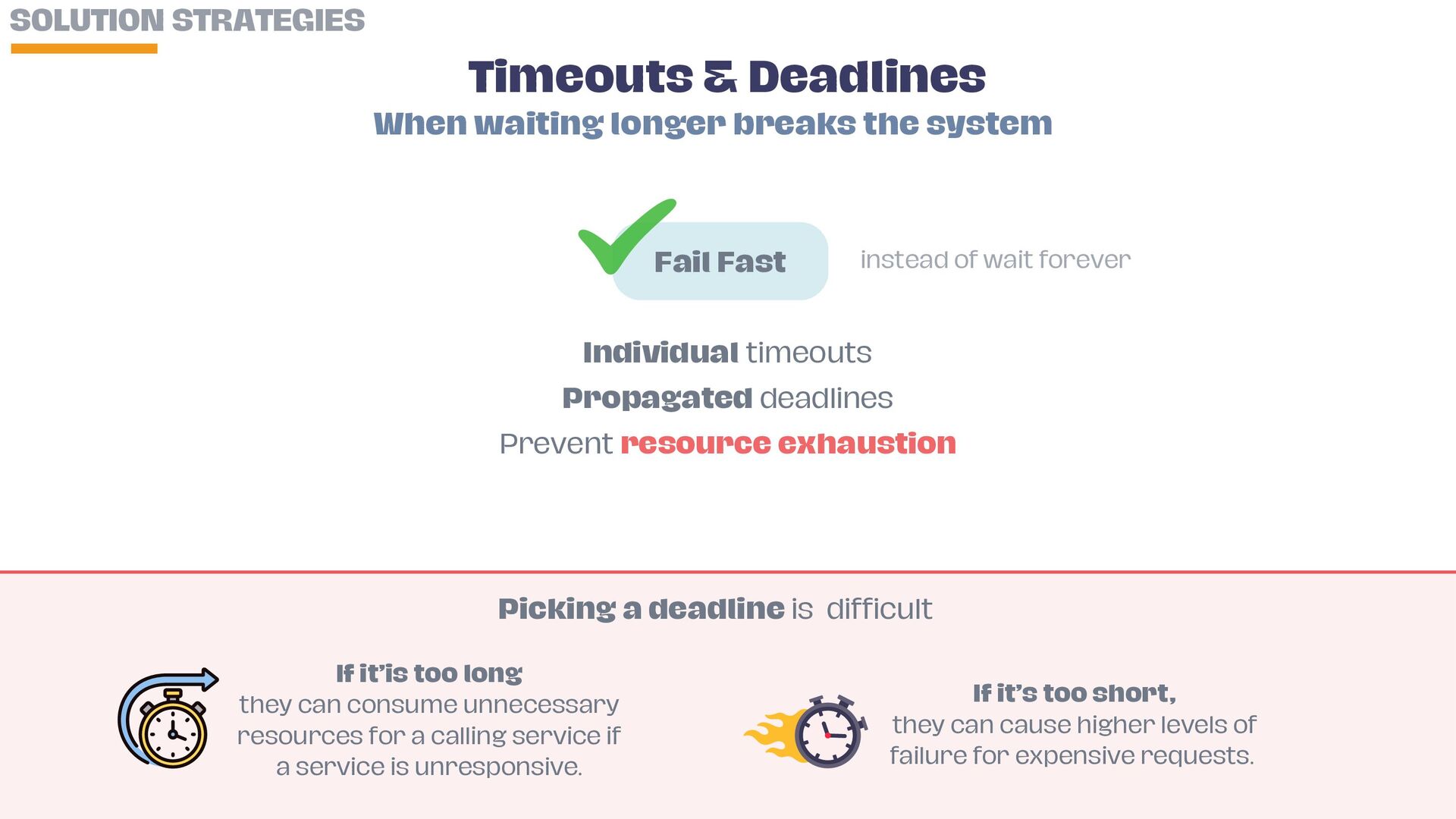
• Enforce timeouts and propagated deadlines to prevent resource exhaustion
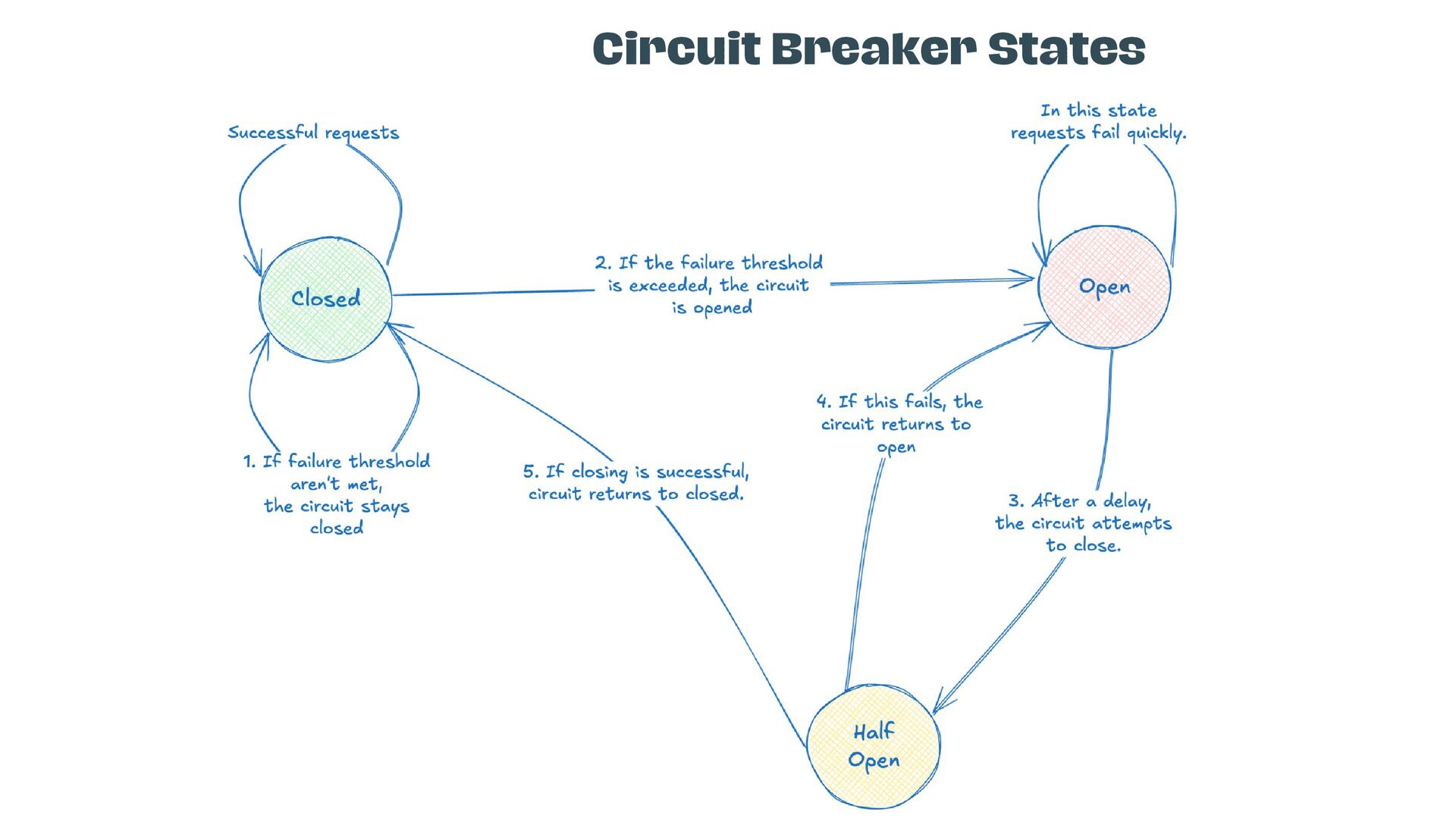
• Leverage circuit breakers to isolate and contain repeated failures
By the end, you’ll have a developer’s toolbox for building microservices that stay calm under pressure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}