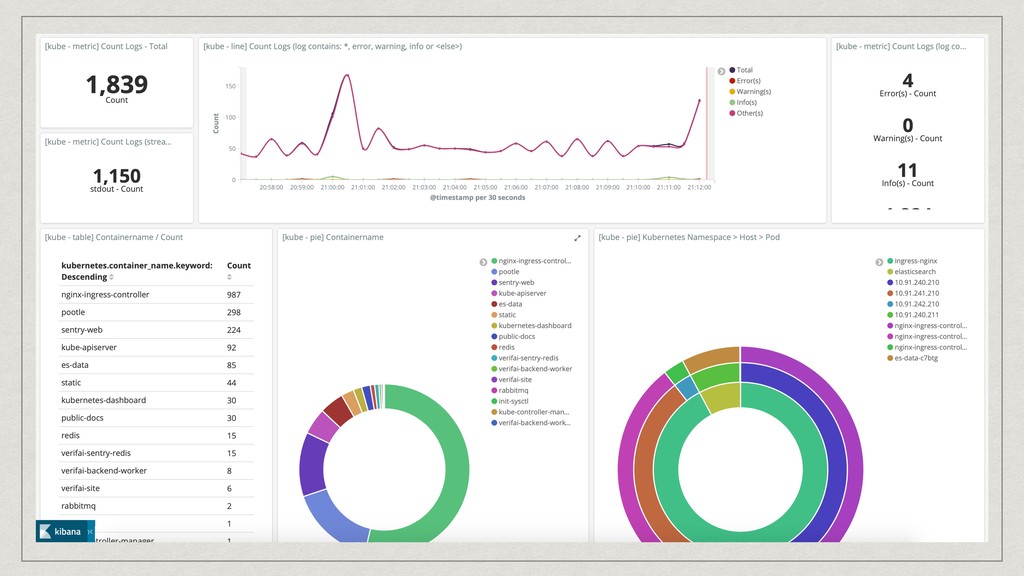
all the data required to train neural networks Lots of IO Lots of DB queries A lot of calculations 100k loops, and memory leaks It literally has taken down our entire cluster a dozen times
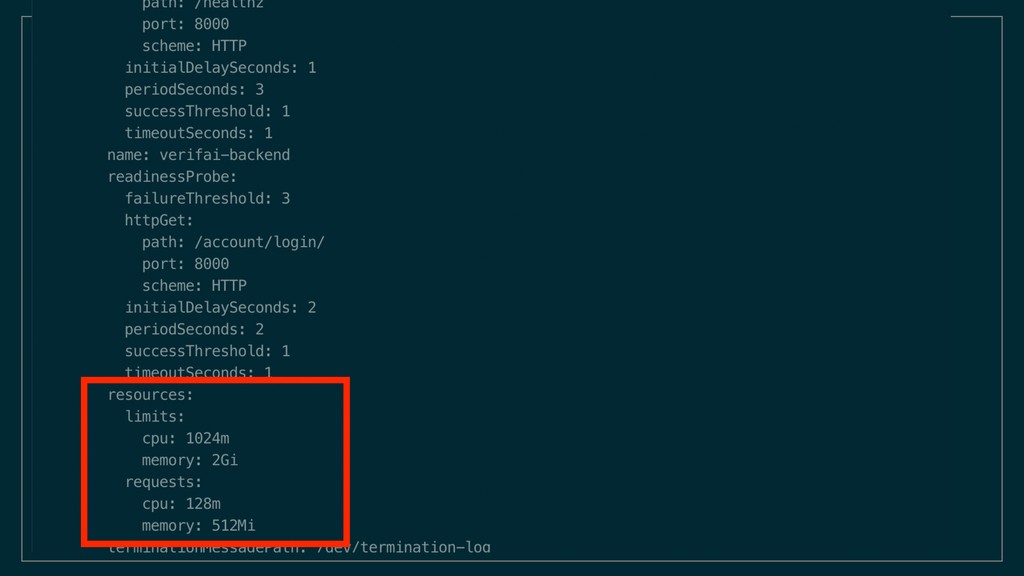
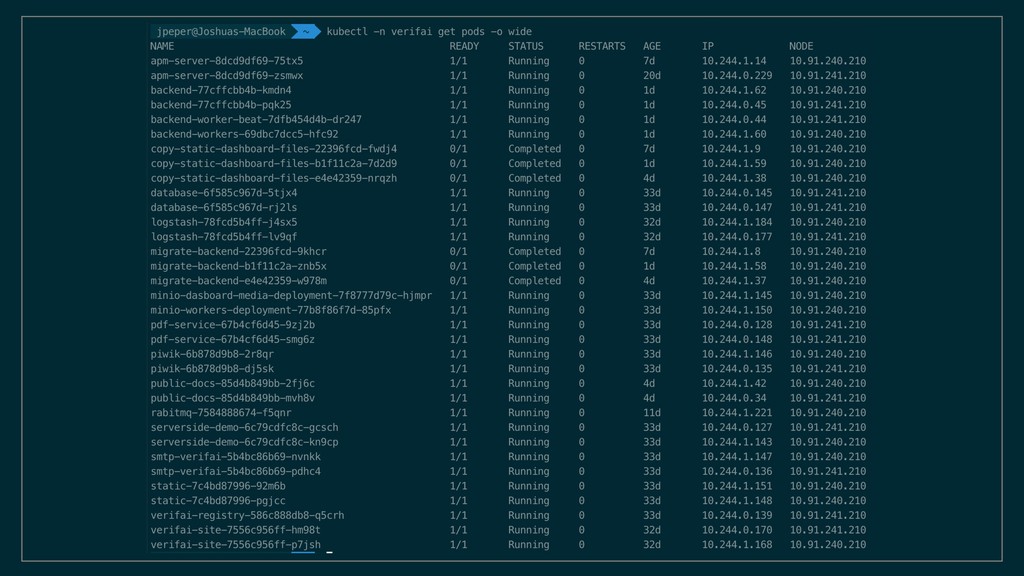
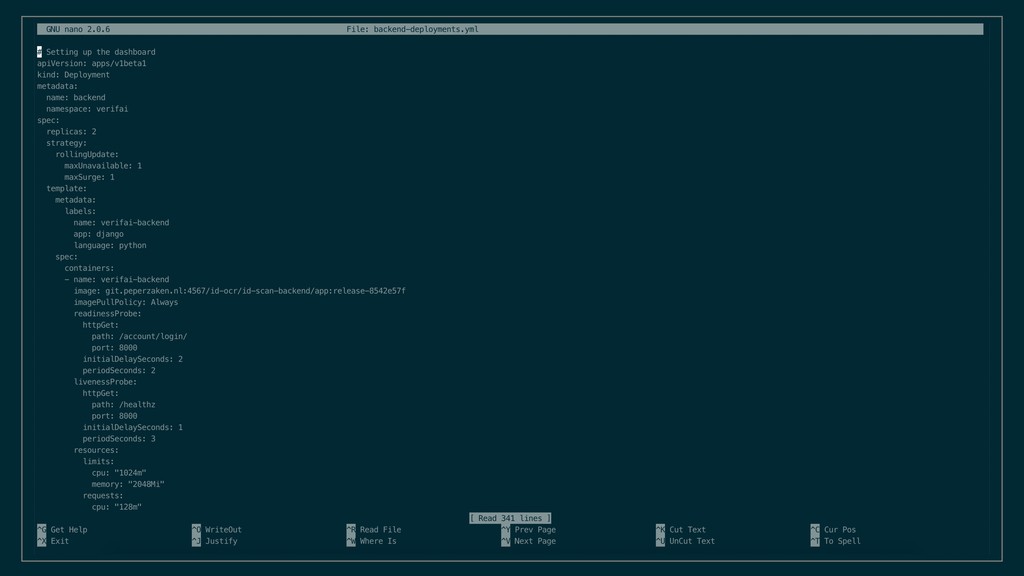
spare resources Can be that all your backend pods run on 1 node Gets redistributed when node goes down Takes 2-5 seconds (for our backend) Also prevents all pods on one node issue
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}